
Stable Diffusionはとても自由度が高く、様々な設定を利用して画像生成ができるツールです。
だからこそ、どんな機能があるのか把握しきれていない方も多いのではないでしょうか?
今回は初心者の方に向けて、Stable Diffusionのおすすめの設定と基本の設定項目をまとめてみました。
これを読めばStable Diffusionの設定の基本については理解できるようになりますので、最後までぜひ読んでいって下さい!
※Stable Diffusionの立ち上げ方法や使い方については、以下の記事で詳しく解説しています。

内容をまとめると…
Stable Diffusionの基本設定項目(モデル・Sampling method・CFG Scale・Seed・Batch設定など)を20項目一覧で解説
VAE導入・拡張機能・xformers有効化・低VRAM対策(–medvram)などでクオリティと速度を両立できる
Settingsタブの画像保存先カスタマイズ、ファイル名パターン変更、CLIP Skipなど細かい設定も押さえている
拡張機能は40種類以上をリスト化しており、ControlNet・ADetailer・Dynamic Promptsなど用途別に探せる
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Stable Diffusionでおすすめの設定
Stable Diffusionでは、画像生成の基本となるモデルに加えて、拡張機能やVAE、Loraなど本当に様々な設定項目があります。
そのため基本的には生成したい画像に合わせ、使うモデルやLoraを決め、またそのモデルに合った拡張機能を選んでいく…ということになります。
今回は多様な設定の中でも、比較的汎用性のあるものについて解説していきます!
幅広い画像に使える設定のため導入方法を覚えておくと役立ちます。
①「VAE」を利用するとクオリティが上がる
『VAE』とは、簡単に言うと「Stable Diffusionで画像生成する際に、お手伝いをしてくれるツール」です。
VAEありとなしでは、生成画像のクオリティに差が出ます。
左がVAEなし、右がVAEありで生成した画像です。


必要なVAEはモデルごとに異なりますが、『vae-ft-mse-840000-ema-pruned』が汎用性が高くおすすめです。
詳しい導入方法については、次の記事をご覧ください。

人物を生成する場合は「拡張機能」の導入がおすすめ
人物を生成する場合、
- ポーズや表情だけ変えたい…
- 他はすごくいいのに手だけおかしなことになってしまった…
ということが起こりがちです。
そんなケースに備えて設定しておきたいのが拡張機能です。
ポーズ変更については『ControlNet』と『OpenPose』、表情や細部の修正には『ADetailer』を使うと便利です。
Stable Diffusionには数えきれないほどの拡張機能があります。便利な拡張機能をざっとまとめますので、気になるものがあれば以下で紹介している記事を参考にして導入してみましょう!
| 拡張機能 | 内容 |
|---|---|
| Booru tag autocomletion | プロンプトの入力候補を表示できる (特にアニメ系イラスト向け) |
| Dynamic prompts | プロンプトでワイルドカードが使えるようになる ※詳細は以下の記事 https://romptn.com/article/13486 |
| NSFW checker | 生成画像がNSFWだった場合、黒い画像に変換してくれる |
| Dreambooth | オリジナルモデルを作成できる ※詳細は以下の記事 https://romptn.com/article/9685 |
| Image browser | 今までに生成した画像がサムネイル形式で一覧表示される |
| Letent Mirroring | 対照性を持った構図の画像を生成できる |
| Smart Process | 自動で1:1にトリミングしてくれる |
| Dream Artist | 1枚の画像だけでスタイルとLoRAを学習する |
| WD 1.4 Tagger | プロンプトの入力候補を表示できる |
| multi-subject-render | 1枚の画像に複数の人物・キャラクターを位置を指定して生成できる ※詳細は以下の記事 https://romptn.com/article/4782 |
| depthmap2mask | 深度を推定し、img2img用マスクを生成できる |
| Depth Maps | 3Dペイントが可能 |
| DAAM | プロンプトが生成画像のどの部分に効果が出ているのか、ヒートマップで表示される |
| embedding-inspector | プロンプトを入力すると、似た効果を持つ単語を挙げてくれる |
| Infinity Grid Generator | 評価軸を増やしたグリッドを作成できる |
| Config-Presets | 設定値を保存して、次回以降設定を呼び出せるようにする |
| openOutpaint extension | Outpaintingをさらに便利に利用できるようになる |
| model-keyword | モデルやLoRAで必須のプロンプトを自動で入力してくれる |
| Prompt Generator / Promptgen / text2prompt | 短いプロンプトを、より詳細な長いプロンプトに変換してくれる |
| Model Converter | .ckpt形式から「.safetensors形式」に変換できる ※詳細は以下の記事 https://romptn.com/article/8106 |
| Kohya-ss Additional Networks | LoRAで便利な機能を追加してくれる |
| Ultimate SD Upscale | アップスケールを行ってくれる |
| Batch Face Swap | 画像の顔を認識して、別の顔に置き換えてくれる |
| System Info | システムタブを追加し、Web UIのシステム情報を閲覧できる |
| Steps Animation | 画像生成の過程を動画化できる |
| Pixelization / Pixel | 画像をドット絵にできる |
| Aspect Ratio selector / Aspect Ratio Helper | 画像生成画面にアスペクト比を指定できるボタンが追加される |
| gif2gif | アニメGIFをimg2imgできる |
| Prompt Translator | プロンプトを日本語で入力すると、自動で英語に翻訳してくれる |
| Latent Couple / Regional Prompter | 1つの画像に複数の要素を指定できる ※詳細は以下の記事 https://romptn.com/article/4782 |
| SuperMerger | 容量を気にすることなく、モデルをマージできる |
| Composable LoRA | 複数LoRAを利用する際に、各LoRAの影響範囲を特定のプロンプトに限定できる |
| Bilingual Localization | 各項目を英語・日本語両方で表示できる |
| LLuL | 画像の1部だけ指定して、Latentでアップスケールできる |
| MultiDiffusion with Tiled VAE | 少ないVRAM消費で、アップスケールできる ※詳細は以下の記事 https://romptn.com/article/4702 |
| 3D Model&Pose Loader | ControlNetで使える3Dモデルを作成できる |
| stable-diffusion-webui-rembg | 写真・イラストから背景を除去した画像を生成できる |
| text2video | プロンプトから動画を生成できる |
| stable-diffusion-webui-state | Stable Diffusionを再起動しても、前に入力したプロンプトや設定がリセットされないようにする |
| Canvas Zoom | 画像をズームできるようになる ※詳細は以下の記事 https://romptn.com/article/5123 |
| PBRemTools | 画像から背景を綺麗に削除できる |
| a1111-sd-webui-lycoris | LyCORISをAUTOMATIC版で利用できるようになる ※詳細は以下の記事 https://romptn.com/article/9744 |
| sd-canvas-editor | いろいろなキャンバスエディターを追加できる |
| Infinite image browsing | 高機能な画像ビューワーを表示できる |
| SD-CN-Animation | テキストから動画、動画から動画を生成できる |
| !After-Detailer | 画像から特定の要素をinpaintなどに送れる |
| Model Preset Manager | 各モデルの推奨プロンプト・トリガーワード・設定をモデル別に保存できる |
| Stable Diffusion Webui Civitai Helper | Civitaiからモデル情報とプレビューを自動で取得できる ※詳細は以下の記事 https://romptn.com/article/6279 |
※詳しい導入方法やおすすめの拡張機能については、こちらの記事で詳しく解説しています!

低スペック・VRAM(メモリ)不足向けおすすめ設定
Stable Diffusionをローカルで起動している場合、低スペック・vram不足だと快適に画像生成ができなかったり、エラーが発生したりすることがあります。
そんな時に試していただきたいのが「webui-user.bat」を編集する方法です。
stable-diffusionの起動バッチファイル「webui-user.bat」を適当なテキストエディタで開き、
set COMMANDLINE_ARGS=
と書かれている項目を見つけたら
- -medvram
または
- -lowvram
と追記しましょう。
余程深刻なメモリ不足でない限り、medvramで動作が改善されるはずです!
また、Google colab上で動かしてしまうのも一つの方法です。
Googleドライブや仮想マシンを使ってブラウザ上で起動するので、PCのスペックに関係なく使用することができます。
Google ColabでのStable Diffusionを立ち上げる方法についてはこちらで解説しています!

④「xformers」を有効化して生成速度を上げる
「xformers」という機能を有効化すると、画像生成にかかる時間が速くなるだけでなく、VRAM(メモリ)使用量も減らすことができます!
導入して損はない機能になりますので、以下の記事を参考に「xformers」を有効化してみてください。

【初心者さん必見】Stable Diffusionの設定項目一覧
ここからは、Stable Diffusionの画像生成画面を通して、基本の設定についておさらいしていきます。
リンクのある項目については、後ほど詳しく説明します。
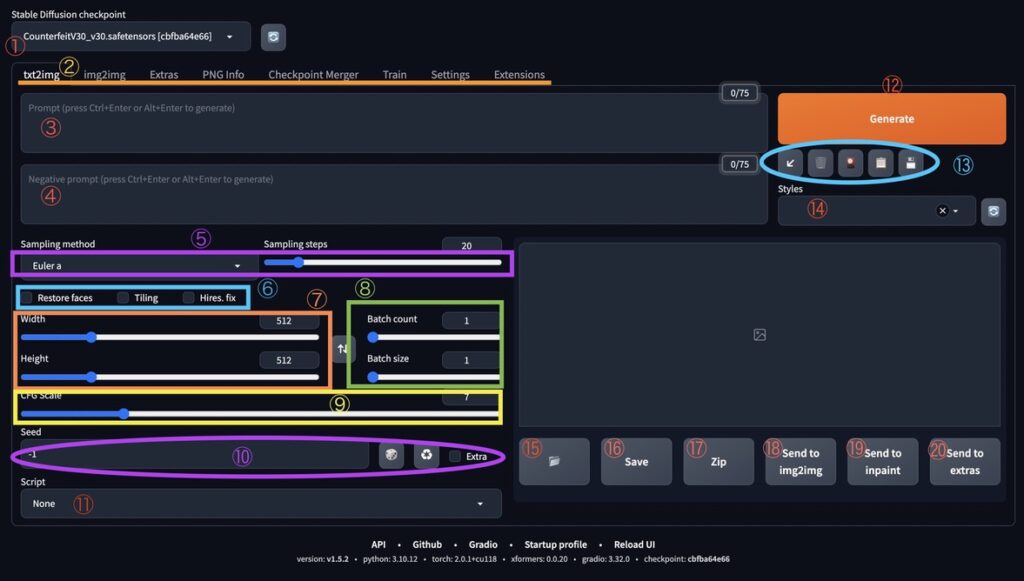
| 項目 | 設定内容 |
|---|---|
| ①モデル | 画像生成に使うモデルの選択 |
| ②各種機能タブ | 機能の選択 |
| ③呪文(プロンプト) | プロンプト(呪文)の入力 |
| ④ネガティブプロンプト | ネガティブプロンプトの入力 |
| ⑤Sampling method・Sampling steps | ノイズ除去アルコリズムの設定 |
| ⑥Restore faces・Tiling・Hires.fix | 顔崩れ防止・敷き詰め・高解像度化 |
| ⑦画像サイズ設定 | バーで画像のサイズ指定ができる |
| ⑧Batch count・Batch size | 画像生成数の調整 |
| ⑨CFG Scale | 呪文(プロンプト)への忠実度 |
| ⑩Seed関係 | Seed関係の調整 |
| ⑪Script | 比較画像の生成設定 |
| ⑫Generate(画像生成) | 画像生成 |
| ⑬各種呪文(プロンプト)操作・モデルカード | プ呪文(プロンプト)の操作・Lora等の選択 |
| ⑭Styles | 保存されたStylesの表示 |
| ⑮フォルダ | 画像保存フォルダを開く |
| ⑯Save | 画像を保存(⑮とは別フォルダ) |
| ⑰Zip | 画像をZipで圧縮して保存(⑮とは別フォルダ) |
| ⑱Send to img2img | 画像をimg2imgに送る |
| ⑲Send to inpaint | 画像をinpaintに送る |
| ⑳Send to extras | 画像をextrasに送る |
①モデル
画像生成に大きく影響する設定項目です。
モデルのダウンロード方法やおすすめモデルについては、こちらの記事で詳しく解説しているので、ぜひチェックしてみて下さい。

②各種機能タブ
Stable Diffusionにデフォルトで備わっている機能を選択することができます。
| 項目 | 設定内容 |
|---|---|
| text2img | テキストからの画像生成(デフォルト) |
| img2img | 既存の画像を元にした画像生成 |
| Extras | 画像の高解像度化など |
| PNG Info | 生成画像から呪文(プロンプト)を抽出 |
| Checkpoint Merger | 複数のモデルをマージ(融合) |
| Train | 画像の学習からオリジナルモデルの作成 |
| Settings | 詳細設定 |
| Extensions | 拡張機能のインストール、設定 |
Checkpoint Mergerについては、こちらの記事で詳しくご紹介しています。

⑤Sampling method・Sampling steps
『Sampling method』とはノイズを除去(サンプリング)する時に使われるアルコリズムのことです。
AIでの画像生成は、ノイズだらけの画像からノイズを除去していくという工程を繰り返して行われています。そのため、どのSampling methodにするかで生成結果が変わります。
『Sampling steps』はそのノイズを除去する工程の回数のことです。デフォルトでは20になっていますね。
①で紹介した、使用するモデルのページに推奨Sampling methodが記載されている場合はそちらを使いましょう。Sumplerと記載されていることもあります。
もし推奨Sampling methodが指定されていない場合は、DDIMでstepsを15〜25にするか、Eulerでstepsを20〜30あたりにするのがおすすめです。細部の描写を重要視する場合は、LMSもおすすめです。
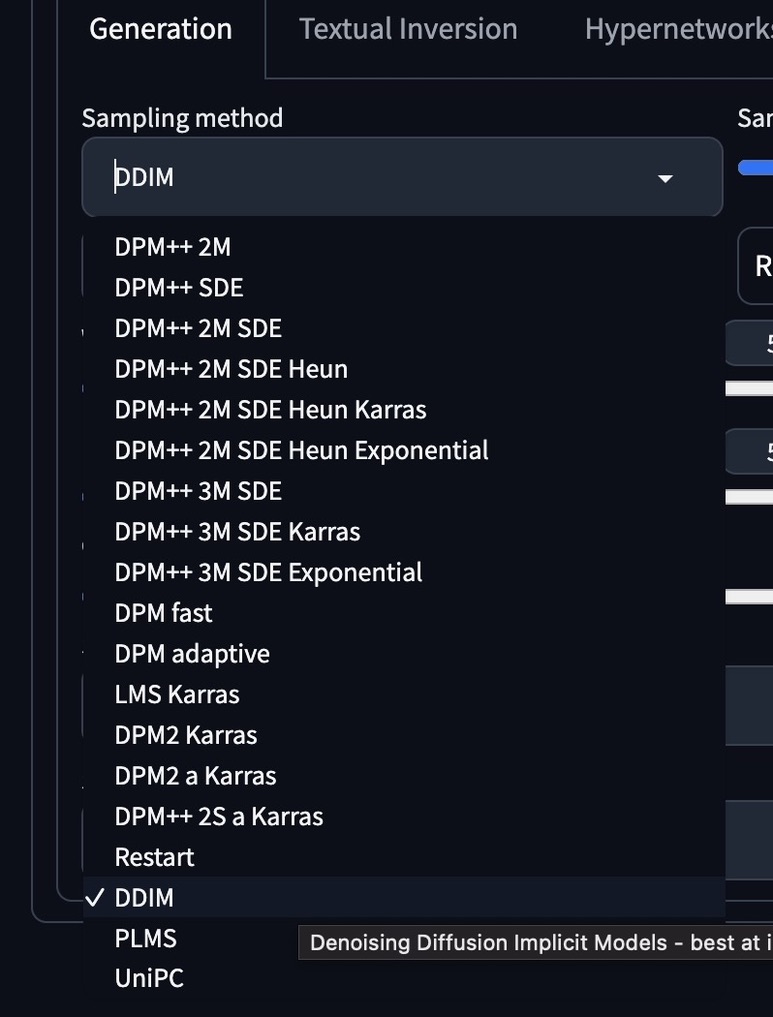
※Sampling methodの詳しい使い方については、以下の記事を参考にしてください。

⑥Restore faces・Tiling・Hires.fix
●『Restore faces』は顔が崩れるのを防止してくれる機能です。
最近のモデルでは顔崩れが起きにくくはなっていますが、人物の画像を生成する際にはチェックを入れておいて損はないでしょう。
●『Tiling』はプロンプトの内容を、生成する画像の全体に適用してくれる機能です。
タイル貼りという名前の通り、同じパターンの繰り返しの画像を作る際に役立ちます。
●『Hires.fix』は、高解像度の画像を生成してくれる機能です。
生成速度に影響する可能性はありますが、チェックを入れるだけで鮮明になるため、高画質の画像が欲しい時に便利です。
こちらの記事では実際に使ってみた例をご紹介しています。

⑧Batch count・Batch size
『Batch count』は画像を順番に生成する回数のことです。
一方、『Batch size』は画像を同時に生成する数のことです。
例えば、Batch countを2にして、Batch sizeを4にすると、一回Genelateボタンを押しただけで4枚の画像を同時に作る工程が2回行われ、計8枚の画像が生成されることになります。
画像生成数の調整についてはこちらの記事でも解説しています。

⑨CFG Scale
生成画像をどれだけ呪文(プロンプト)を忠実に再現させるか、を表す数値です。
この数字が大きいほど呪文(プロンプト)に忠実な画像が生成されます。デフォルト数値は「7」です。
※「CFG Scale」については、以下の記事で詳しく解説しています。

⑩Seed関係
Seed値とは、画像生成した際にランダムに割り振られる値です。
同じSeed値を入力すると似た画像が生成されるようになっています。
デフォルトのSeed値は「-1」に設定されていて、画像を生成するたびに値はランダムに変更されます。
画像生成後に♻️ボタンを押すと、生成した画像のSeedが自動的に入力されます。
🎲ボタンを押すと、Seed値がデフォルトの「-1」になり、ランダムな出力結果になります。
こちらの記事では、Seedについてさらに詳しく解説しています!

⑪Script
呪文(プロンプト)やモデル、サンプリング数を比較した画像が作れる機能です。
長くなるため詳しい説明は今回の記事では割愛しますが、比較画像を作りたいというような特別な用途がない限りは、「None」にしておきましょう。
⑬各種プロンプト操作・モデルカード
- ↙️ボタン:前回使っていた呪文(プロンプト)を呼び出すことができます。
- 🗑ボタン:呪文(プロンプト)・ネガティブプロンプトをワンクリックで消去できます。同時に消えてしまうので注意しましょう。
- 🎴(花札)ボタン:読み込まれているTextual Inversion・Hypernetworks・モデル・LoRAが一覧で表示されます。こちらから適用することもできます。
- 📋ボタン、💾ボタン:呪文(プロンプト)を保存できる『Styles』に関連するボタンです。
- 💾ボタン:今入力されている呪文(プロンプト)・ネガティブプロンプトをStylesとして保存できます。
- 📋ボタン:選択されたStylesを呪文(プロンプト)へ適用できます。
Stylesに関してはこちらの記事で詳しく説明しているので、気になった方はチェックしてみてください!

⑭Styles
上で説明した、💾ボタンで保存されたStyles(プロンプト)名がここにプルダウン形式で表示されます。
ここで選択しただけでは呪文(プロンプト)に適用されないので、必ず上の📋ボタンを押しましょう。
『Settings』タブのおすすめ設定項目
ここからはStable Diffusionの『Settings』タブの中にあるおすすめ設定をいくつか紹介していきます!こちらが一覧になります(和訳済み)

また、これから紹介していく設定は、変更したら必ずタブの上部にある『Apply for quit』(設定を適用)ボタンを押してください!

①画像/グリッド画像の保存
こちらでは、1つ目に、『Save init images when using img2img(img2img 使用時に初期イメージを保存する)』にチェックマーク✅を入れましょう。
そうすると、img2imgで生成した画像を自動で保存してくれるようになります。
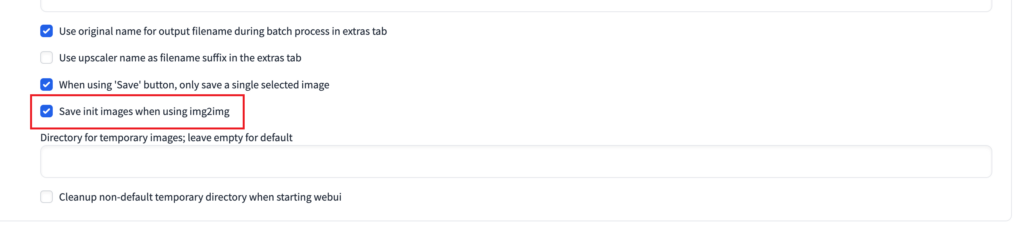
保存された画像は、「init-imges」というフォルダに保存されていきます。
2つ目として、「ファイル名のパターン」を変更できます。
デフォルトでは「00001-3759877012.png」など『連番‐Seed値』というファイル名になっていますが、これを自分の好きな名前にカスタマイズできます!
ファイル名のパターンは以下の項目を入力することができます。これらは、画像を生成する際に実際の数値に変更してくれます。
| ファイル名 | 内容 |
|---|---|
| [seed] | Seed(シード)値 |
| [steps] | ステップ数 |
| [cfg] | CFG Scaleの数値 |
| [width] | 画像の幅 |
| [height] | 画像の高さ |
| [styles] | 選択したスタイルの名称 |
| [sampler] | サンプラー |
| [model_hash] | モデルのハッシュ値 |
| [modelr_name] | モデルの名前 |
| 2026/07/18 | 生成した日(例:2023-01-01) |
| [datetime] | 生成した日と時間(例:20230101121200 年月日時分秒) |
| [job_timestamp] | タイムスタンプ |
| [prompt_hash] | プロンプトをハッシュ化した文字列 |
| [prompt] | プロンプト(空白は_に変換される) |
| [prompt_no_styles] | プロンプト、スタイルなし |
| [prompt_spaces] | プロンプト、スタイルあり |
| [prompt_words] | プロンプト、括弧やカンマは削除 |
| [batch_number] | バッチナンバー |
| [generation_number] | 生成番号 |
| [hasprompt] | プロンプトに特定の文字列があった時だけ変更する |
| [clip_skip] | Clip Skipの数値 |
その他おすすめ設定
- グリッド画像が必要ない場合は、「グリッド画像を常に保存する」のチェックマークを外す
- 修正前の画像も保存したい場合は、「高解像度補助を行う前に元画像のコピーを保存しておく」のチェックマークを外す
②保存するパス
こちらでおすすめの設定は、「お気に入りの画像だけ保存するフォルダを作る」設定です。
設定方法は、「保存ボタンで画像を保存するディレクトリ」をお好きな名前に変更します。
③ディレクトリへの保存
こちらでは「呪文(プロンプト)別に画像フォルダを分ける」設定ができます。
設定方法は、「ディレクトリ名のパターン」の名前を変更します。

おすすめの名前ですが、
- プロンプト:[prompt_spaces]
- モデル名_プロンプト:[model_name]_[prompt_spaces]
などが非常に便利です。
④顔の修復
こちらでは、「顔の修正に使うモデルを変更」できます。
『GFPGAN』の方が綺麗に顔を修正できますので、そちらを選択しておきましょう。

⑤Stable Diffusion
こちらでは、「モデルをRAMにキャッシュさせて高速化する」設定ができます。
「RAMにキャッシュするcheckpointの個数」と「RAMにキャッシュするVAEの個数」をご自身のRAMの容量にあった数値に増やしましょう。
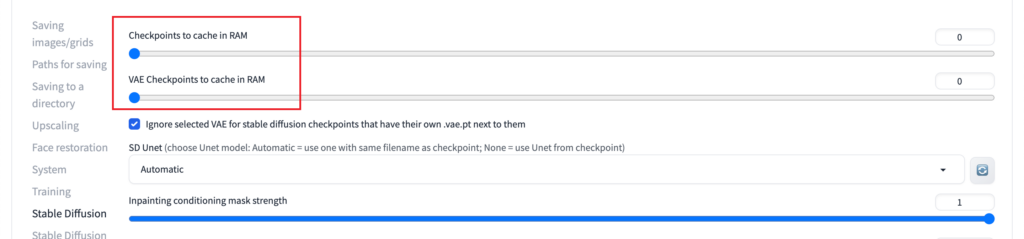
メモリの確認方法については、以下の記事で詳しく解説しています。

⑥ユーザーインターフェース
こちらでは、「よく使う設定をトップ画面の上部に表示する」設定ができます。
頻繁に使うものを毎回毎回設定する必要がなくなるので、非常に便利です。
トップ画面に表示させたい機能を「クイック設定」の欄に入力します。
例:sd_vae,CLIP_stop_at_last_layers,sd_model_checkpoint,live_previews_enable,enable_pnginfo
入力できたら、「Apply for quit」で設定を適用させ、Stable Diffusionを再起動させると完了です!
よく使う設定項目はこちらです、是非参考にしてください!
| 設定項目 | 名前 |
|---|---|
| モデルの選択 | sd_model_checkpoint |
| VAEの選択 | sd_vae |
| Clip Skipの数値 | CLIP_stop_at_least_layers |
| グリッド画像の保存 | grid_save |
| 生成したPNG画像にパラメータ情報を含める | enable_pnginfo |
| 顔修正に使うモデルの選択 | face_restoration_model |
| CodeFormerでの顔復元の重み | code_former_weight |
| 画像のライフプレビューのオンオフ | live_previews_enable |
Stable Diffusion web uiで設定を初期化する方法
Stable Diffusion web uiでは、上で紹介した様々な設定を変更した後、その数値をデフォルトに戻すコマンドは特にありません。
UIの再読み込みをすれば初期化されます。
Stable Diffusion web uiで設定値を保存する方法
逆に言うと、UIの再読み込みの度に設定値は初期化されてしまいます。
そんな時に役に立つのが、PNG Infoを使って生成画像から設定値を呼び出す方法です。
保存したい設定値を指定したら、一度画像を生成し、ローカルに保存しておきましょう。
この画像がメモリーカードのような役割をしてくれます。
UIが再読み込みされてしまったら、この画像を各種機能タブから選択できる、「PNG Info」にドラッグ&ドロップし、「txt2img」を選択しましょう。

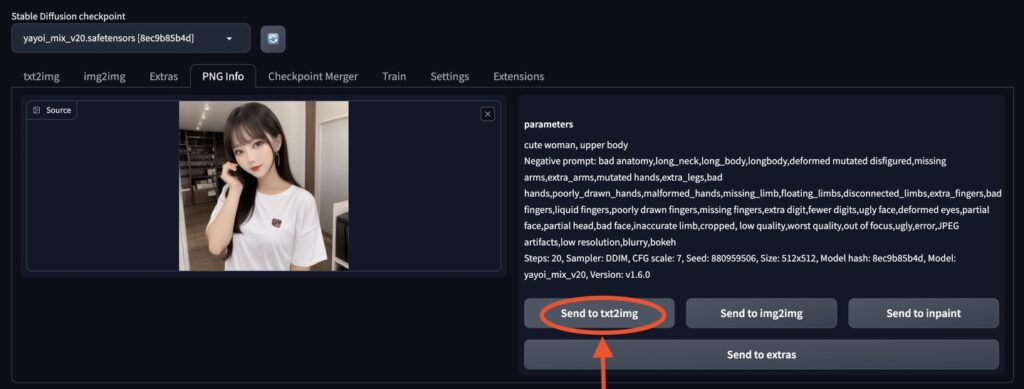
すると設定値がその画像を生成した時のものになっています。
Stable Diffusion Web UIを自動で起動する設定方法
毎回毎回自分でStable Diffusionを立ち上げるのは面倒くさいですよね?
そんな方に「Stable Diffusion Web UIを自動で起動する」というおすすめの設定方法があります!
①「webui-user.bat」の「set COMMANDLINE_ARGS=」の後ろに
--autolaunchと入力するだけです!
一緒に「xformers」を有効化させたい方は、以下を入力してください。
--xformers --autolaunchたったこれだけで次回から、「webui-user.bat」から起動させると、自動でブラウザのStable Diffusion Web UIが立ち上がるようになります!
まとめ
いかがでしたでしょうか?
今回は、Stable Diffusionの設定項目について、おすすめから基本まで解説してきました!
ポイントをまとめると、以下のようになります。
- Stable Diffusionでは様々な設定項目があり、生成したい画像に合わせることができる
- VAE・拡張機能の導入は特におすすめ
- UIの再読み込みで設定の初期化ができる
- 設定の保存には、画像の保存とPNG Infoを使った復元が便利
ぜひ様々な設定を使いこなして、Stable Diffusionでの画像生成を楽しみましょう!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

