
ChatGPTを使ううちに、ふと「自分が入力した内容って、AIの学習に使われているの?」と不安になったことはないでしょうか。
結論から言えば、無料プランやPlusプランのデフォルト設定では、入力データがOpenAIのモデル改善に利用される可能性があります。しかし、適切な設定を行えばこれを防ぐことは可能です。
本記事では、ChatGPTに学習させないための具体的な設定手順だけでなく、多くの人が混同しがちな「履歴」「メモリ」「モデル学習」の違いや、設定後に見落としやすいポイント、利用シーン別の最適な対処法まで、体系的に解説します。
内容をまとめると…
設定画面から「モデルを改善する」をオフにするだけで、データ学習を簡単に拒否できる!
確実に過去の会話まで学習から除外したいなら、OpenAIの公式サイトにある申請フォームからオプトアウトをする!
オプトアウト設定をすると会話履歴が残らなくなるから、過去のやり取りを後から見返したい人は要注意!
・ChatGPTについて体系的に知りたいなら、まずは無料で生成AIのプロに教えてもらうのがベスト!
豪華大量特典無料配布中!
romptn aiが提携する完全無料のAI副業セミナーでは収入UPを目指すための生成AI活用スキルを学ぶことができます。
ただ知識を深めるだけでなく、実際にAIを活用して稼いでいる人から、しっかりと収入に直結させるためのAIスキルを学ぶことができます。
現在、20万人以上の人が収入UPを目指すための実践的な生成AI活用スキルを身に付けて、100万円以上の収益を達成している人も続出しています。












\ 期間限定の無料豪華申込特典付き! /
AI副業セミナーをみてみる
そもそもChatGPTの「学習」とは何か?

ChatGPTのデータ利用には、似ているようでまったく異なる3つの仕組みがあります。これらを混同したまま設定を行うと、「対策したつもりなのに実は不十分だった」という事態に陥りかねません。
チャット履歴の保存
サイドバーに過去の会話が一覧表示される機能です。これはあくまで「自分が後から見返すための記録」であり、この履歴があるかどうかと、データが学習に使われるかどうかは直接関係しません。
履歴を消しても学習利用を止めたことにはなりませんし、逆に履歴を残したまま学習だけを停止することも可能です。
メモリ機能(パーソナライズ)
ChatGPTがユーザーの好みや背景情報を記憶し、次回以降の会話に反映する機能です。「私は東京在住のエンジニアです」と伝えると、以降の会話でそれを踏まえた回答をしてくれます。
これはあなた専用の記憶であり、他のユーザーへの回答に影響することはありません。ただし、メモリに保存された内容がモデル全体の学習に使われるかどうかは、後述する「モデル改善」の設定に依存します。
メモリ機能についてはこちらの記事をご覧ください。

モデル改善のためのデータ利用
ユーザーの入力データをOpenAIがAIモデルの精度向上に活用する仕組みです。これが「ChatGPTに学習される」と言われる正体です。
この設定がオンのままだと、あなたが入力した文章がモデルの改善材料となり、将来的に他のユーザーへの回答に影響を与える可能性がゼロとは言えません。企業の機密情報や個人情報を扱う場合、ここを確実にオフにすることが最も重要です。
学習を停止する方法は複数あり、それぞれ特徴と適用範囲が異なります。自分の状況に合った方法を選びましょう。
学習させない方法1:設定画面から「モデル改善」をオフにする
3つの方法のうち、最も手軽に実行できるのがこの方法です。
まず前提として、「オプトアウト」という言葉について触れておきます。これは「初期状態で許可されているものを、自分の意思で拒否する」という意味です。
ChatGPTでは、デフォルトの状態だとユーザーの会話内容がAIモデルの改善に活用される設定になっています。
OpenAIはプライバシーに配慮した上でデータを利用すると説明していますが、「自分の入力情報が外部に影響するのは避けたい」と感じる方は、このオプトアウト設定で学習対象から自分のデータを除外できます。
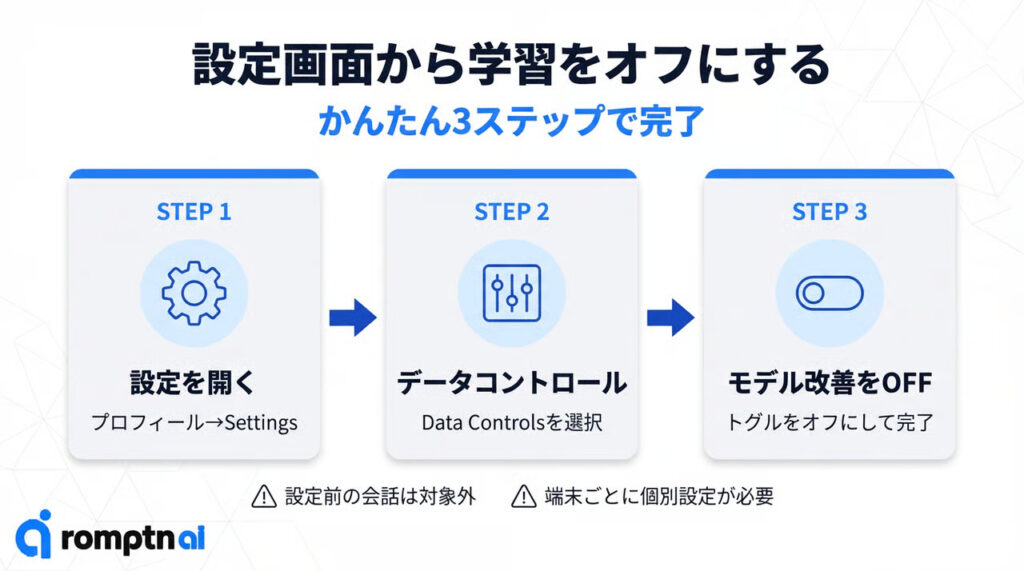
設定の手順は以下の3ステップです。
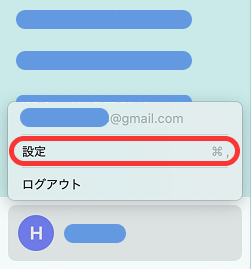
①画面右下にあるアイコンから「設定」を開く
ChatGPTの画面右上にあるプロフィールアイコンをクリックし、表示されるメニューから「Settings(設定)」を選択します。
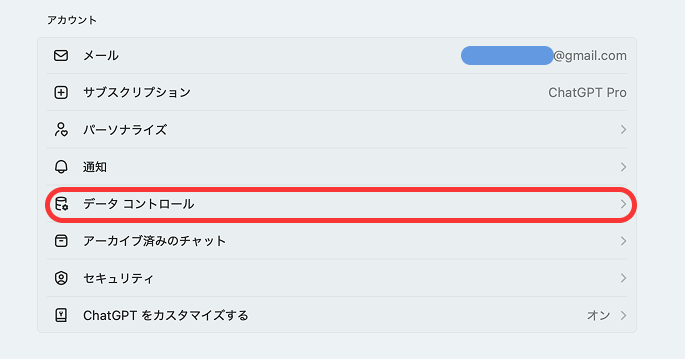
②「データコントロール」を選ぶ
設定画面が開いたら、左側のメニューから「Data Controls(データコントロール)」を選びます。この画面には、履歴の保存やモデル学習へのデータ提供など、プライバシーに関わる重要な項目がまとまっています。
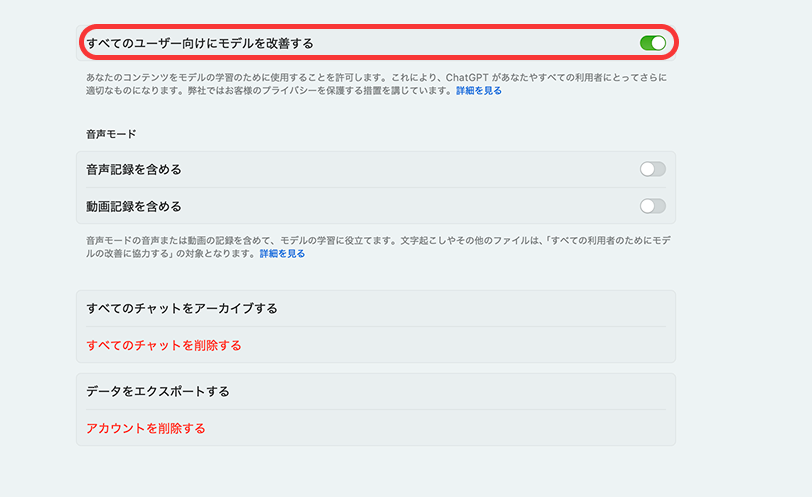
③「すべてのユーザー向けにモデルを改善する」をオフにする
「Improve the model for everyone(すべての人のためにモデルを改善する)」という項目を見つけたら、トグルスイッチをオフに切り替えて「実行する」を押します。これだけで、以降の会話内容がOpenAIの学習データとして使われなくなります。
設定後に押さえておきたい注意点として以下の2点が挙げられます。
1つ目は、この設定が適用されるのは「変更後の会話のみ」という点です。設定前に入力したデータはすでに学習対象になっている可能性があるため、過去のデータまで遡って除外されるわけではありません。
2つ目は、設定がブラウザやデバイスごとに独立しているという点です。たとえばPCのブラウザで設定をオフにしても、スマートフォンのChatGPTアプリには反映されません。普段使っているすべての端末・ブラウザで個別に確認するようにしましょう。
学習させない方法2:OpenAIプライバシーポータルからオプトアウト申請
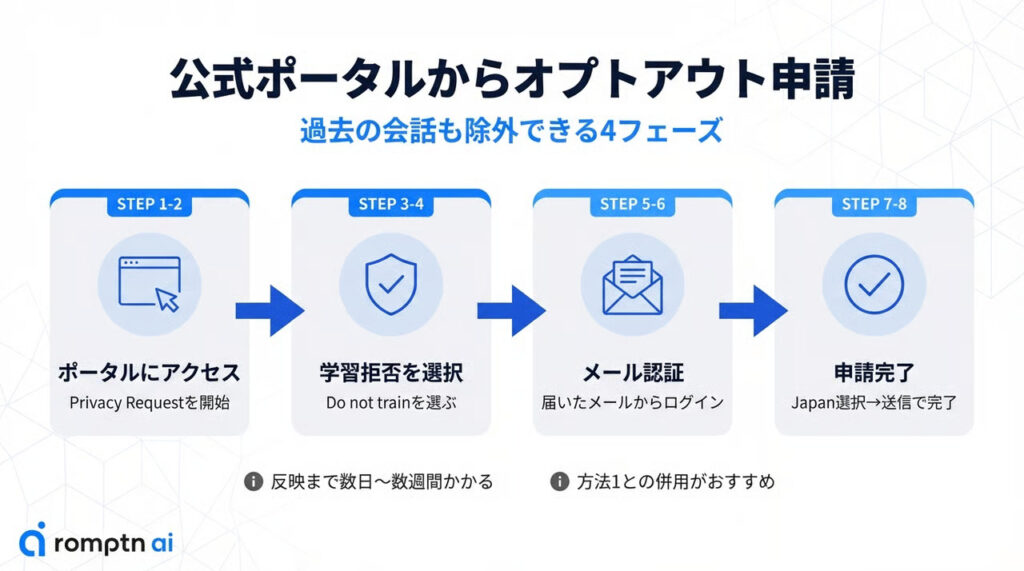
方法1の設定画面からの変更は手軽ですが、対象となるのは「設定変更後の会話」のみです。過去に入力したデータまで含めて学習対象から除外したい場合は、OpenAIが公式に提供している「プライバシーリクエストポータル」からの申請が有効です。
両者の違いを整理すると次のようになります。
| 設定画面からオフにする | 公式ポータルから申請する | |
|---|---|---|
| 除外対象 | 今後の会話のみ | 過去の会話+今後の会話 |
| 反映タイミング | 即時 | 数日〜数週間 |
| 特徴 | 手軽で誰でもすぐできる | より包括的にデータを保護できる |
業務でChatGPTを使っている方や、過去に機密性の高い情報を入力してしまった可能性がある方は、この方法も併せて行っておくと安心です。
申請フォームは英語ですが、操作自体はシンプルなので、以下の流れに沿って進めれば問題ありません。
①OpenAI公式の申請フォームにアクセス
まずは、OpenAI公式のOpenAI Privacy Request Portal(英語)にアクセスします。
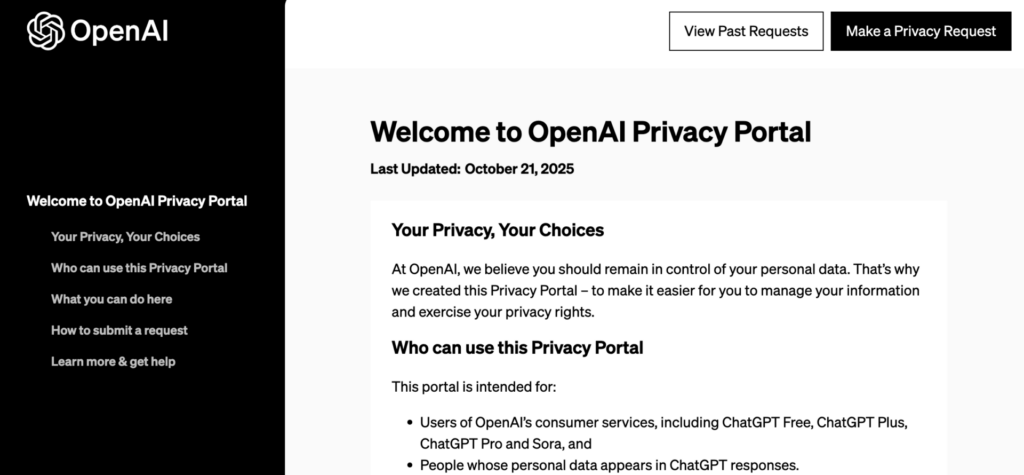
②画面右上の「Make a Privacy Request」ボタンを押す
画面右上に表示されるボタンを押して、申請手続きを開始します。
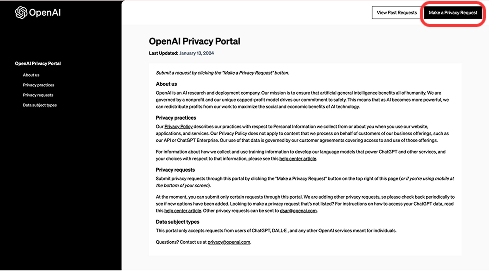
③chatGPTアカウントへのログイン方法を選択
ChatGPTアカウントのログイン方法を聞かれるので、「Email Address」を選びます。
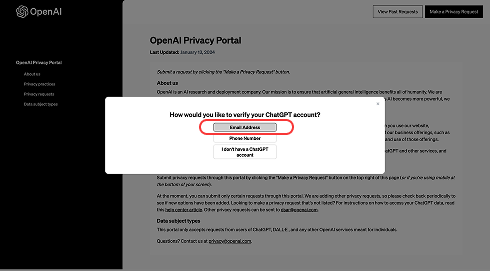
④「Do not train on my content」を押す
4つの選択肢が表示されます。その中から、右上にある「Do not train on my content(自分のデータを学習に使わないでほしい)」を選んでください。
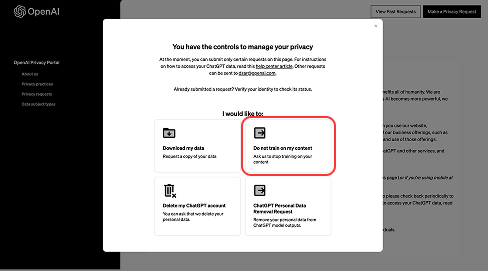
⑤申請フォームを送信するメールアドレスを入力
ChatGPTに登録しているメールアドレスを入力して送信します。入力したアドレス宛に、申請用のリンクが届きます。
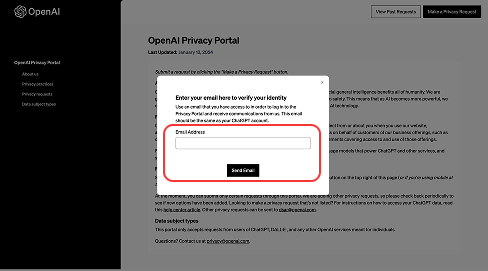
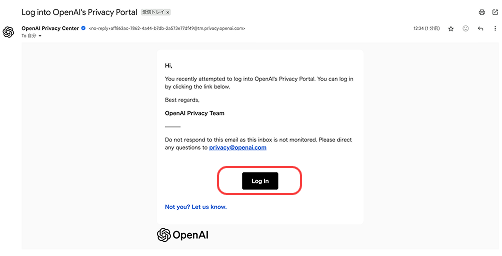
⑥OpenAIからのメールを開いて「Log In」ボタンを押す
OpenAIから届いたメールを開き、「Log In」をクリックすると、申請の確認画面に進みます。
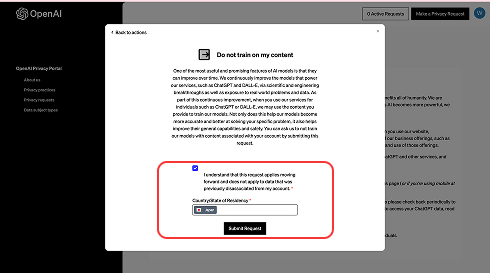
⑦チェックをつけて居住国「JAPAN」を選択、「Submit Request」を押す
チェックボックスにチェックを入れ、居住国で「Japan」を選択したら、「Submit Request」を押して申請を送信します。
⑧申請完了 (完了メールを確認する)
申請が受理されるとOpenAIから完了通知のメールが届きます。念のため、メールが届いているか確認しておきましょう。
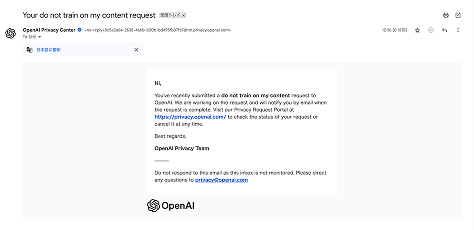
オプトアウトの反映には数日〜数週間かかる場合があります。急ぎで学習を止めたい場合は、方法1の設定変更も同時に行っておくのがおすすめです。
また、OpenAIの公式ヘルプでは過去データの除外が可能とされていますが、「すべてのデータが確実に学習から除外される」と断言されているわけではありません。あくまで追加の保護手段として捉え、機密情報はそもそもChatGPTに入力しないという意識を持つことが大切です。
学習させない方法3:法人向けプランを利用する
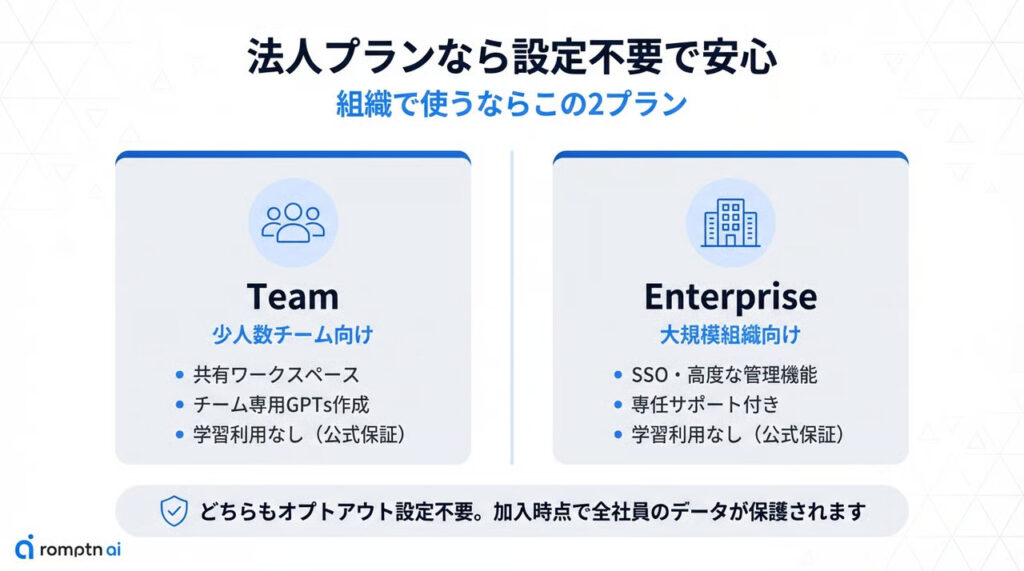
ChatGPT TeamおよびChatGPT Enterpriseでは、ユーザーの入力データがモデルの学習に使用されないことがOpenAIの公式ポリシーとして明記されています。
方法1・2のように個人で設定や申請を行う必要がなく、プランに加入した時点で組織全体にデータ保護が適用されるのが大きな特徴です。
Teamプランは少人数のチーム向けで、共有ワークスペースやチーム専用GPTsの作成が可能です。Enterpriseプランは大規模組織向けに設計されており、SSO(シングルサインオン)やより高度な管理機能、専任サポートが提供されます。
いずれのプランでも、ユーザーが追加でオプトアウト設定を行う必要はありません。
オプトアウトに関する注意点

「オプトアウトしたから安心」と思い込むのは危険です。設定後も以下の点は見落とされがちです。
リスク1:30日間のデータ保持期間
オプトアウト設定を行った場合でも、OpenAIはユーザーの会話データを最大30日間サーバー上に保持します。これはモデル学習のためではなく、不正利用の監視や利用規約違反の検出を目的としたものです。
つまり、オプトアウト=データが即座に消えるわけではありません。30日間はシステム上にデータが存在し続けるため、万が一セキュリティインシデントが発生した場合にはリスクが残ります。
リスク2:過去の入力データは取り消せない
モデル改善をオフにした時点で、それ以降のデータは学習対象から外れます。しかし、設定変更前に入力したデータについては、すでに学習プロセスに組み込まれている可能性があります。
OpenAIは個人情報が直接回答に含まれないよう技術的な対策を講じていますが、それでも「完全にゼロリスク」とは言い切れません。
リスク3:アップデートによる設定変更の可能性
ChatGPTは頻繁にアップデートが行われています。過去には設定画面のUI変更に伴い、オプトアウトの項目名や場所が変わったこともありました。
一度設定して安心するのではなく、月1回程度は設定画面を開いて、オプトアウトが有効なままであることを確認する習慣をつけましょう。
オプトアウト設定の必要性!どんなときにするべき?
ChatGPTを安全に活用するうえで、ChatPGTにデータを学習されることについて嫌悪感はないけど、重大な情報はなんとなく学習させないほうがいいのかな、と感じている方もいると思います。
ここでは具体的なケースを例に、データを学習させないための設定をするべき判断ポイントを紹介します。
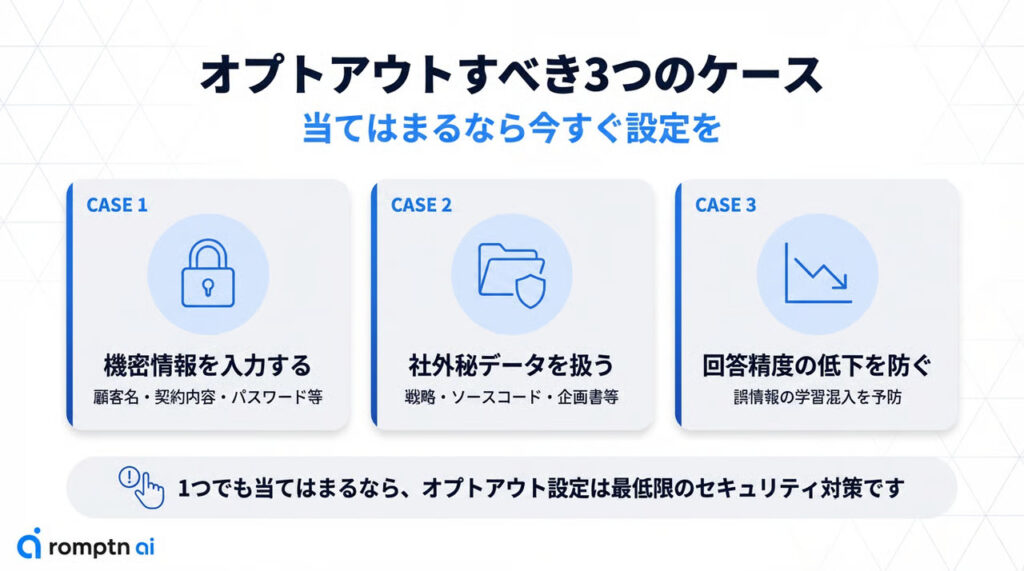
業務上のやり取りや顧客情報など機密情報を入力する場合
企業利用やビジネスシーンでは、顧客名・住所・契約内容・パスワード・非公開のやり取りなど、センシティブな情報を含むケースが多くあります。
こうした情報がOpenAIのサーバーに保存・学習されてしまうと、将来的に他のユーザーの回答に間接的に現れる可能性もゼロとは言い切れません。
オプトアウトは、機密情報の不正活用を防ぐ最低限のセキュリティ対策といえるため、上記のような情報を含めて質問する可能性がある場合は設定をしておきましょう。
自社の社内データや技術情報を不特定に学習されるのを防ぎたい場合
たとえば、独自アルゴリズム・マーケティング戦略・ソースコード・新規事業の企画書など、まだ社外秘の段階である内容をChatGPTに入力するケースもあります。
このときオプトアウトしていないと、OpenAIのAIモデルがその情報を学習し、他者に再利用される可能性が完全には排除できません。
企業で正式にChatGPTを導入する際は、社内ガイドラインを整備してオプトアウト設定をルールに含めるのが好ましいです。
粗悪なデータ学習による回答精度の低下を防ぎたい場合
ChatGPTの学習精度は、ユーザーから収集したデータにも依存しています。また、今後はより長期記憶のようなものが発達し、過去の会話ログを文脈として活用とした回答の生成が行われると予測できます。
そのため、誤った情報や誤解を招く質問内容が学習に混入すると、回答精度の劣化に繋がる恐れもあります。
「この会話内容はAIに学習させるべきじゃない」、「今後の会話で今の内容を考慮して欲しくない」と感じる場合には、オプトアウトによってその影響を最小限に抑えることができます。
ChatGPTの学習についてよくある質問(FAQ)
- Qオプトアウトすると、ChatGPTの回答品質は下がりますか?
- A
個人のユーザー体験としてはほとんど変わりません。モデル改善はOpenAI全体で行われるものであり、一人のユーザーがオプトアウトしたからといって、そのユーザーへの回答精度が低下するわけではありません。
- Qチャット履歴を残したまま学習だけを止めることはできますか?
- A
可能です。方法2のプライバシーポータル経由であれば、履歴を保持しつつ学習を停止できます。また2024年以降のアップデートで、設定画面からもこの2つを個別に管理しやすくなっています。
- Q無料プランでもオプトアウトできますか?
- A
はい、無料プランでも設定画面からのオプトアウトとプライバシーポータルからの申請の両方が利用可能です。
- QGPTsを使う場合も学習されますか?
- A
無料プランやPlusプランでGPTsを利用する場合、オプトアウト設定をしていなければ入力データが学習に使われる可能性があります。TeamプランやEnterpriseプランであれば、GPTsの利用時もデータが学習に使われることはありません。
- Q一度学習に使われたデータを削除してもらうことはできますか?
- A
OpenAIのプライバシーポータルからデータ削除のリクエストを送ることは可能です。ただし、すでにモデルの学習に組み込まれたデータを完全に「忘れさせる」ことは技術的に困難です。予防としてのオプトアウト設定が最も効果的な対策と言えます。
まとめ
ChatGPTに学習させないための対策は、設定画面から数クリックで完了するシンプルなものから、組織全体のセキュリティ設計に関わるものまで幅広く存在します。
最も大切なのは、「履歴を消す」「メモリをオフにする」だけでは学習利用を止めたことにはならないという事実を正しく理解することです。モデル改善のオプトアウトという核心部分の設定を確実に行い、それでも残るリスクには運用ルールで対処する——この二段構えの考え方が、ChatGPTを安心して活用するための鍵になります。
扱う情報の機密度と利用規模に応じて、個人設定・プライバシーポータル申請・法人プラン・API活用の中から最適な組み合わせを選び、定期的に設定状況を確認する習慣を持ちましょう。
豪華大量特典無料配布中!
romptn aiが提携する完全無料のAI副業セミナーでは収入UPを目指すための生成AI活用スキルを学ぶことができます。
ただ知識を深めるだけでなく、実際にAIを活用して稼いでいる人から、しっかりと収入に直結させるためのAIスキルを学ぶことができます。
現在、20万人以上の人が収入UPを目指すための実践的な生成AI活用スキルを身に付けて、100万円以上の収益を達成している人も続出しています。
\ 期間限定の無料豪華申込特典付き! /
AI副業セミナーをみてみる

