
Claude CodeやCodexで大きいrepoを触るたびに、関係ないファイルまで読まれて重いと感じるなら、問題はAIの性能より渡している文脈の広さにあるかもしれません。code-review-graphは、その無駄読みを減らすために、repoの構造と差分を先に整理しておく発想のツールです。
この記事では、code-review-graphが何を変えるのか、なぜ読む量を減らせるのか、そして実際に試す時はどこから始めればいいのかを順番に整理します。派手なベンチマークだけで判断せず、自分のrepoで効くかどうかを見るための視点までまとめました。
読み終える頃には、今の開発環境で小さく試す価値があるか、導入前にどこを警戒すべきかがはっきりします。
内容をまとめると…
無駄読みの原因はAIそのものより渡す文脈の広さ
構造マップ・差分更新・最小読込の3段で効く
install → build → watch の順で試すと迷いにくい
中央値約82xと最大528xは分けて見るべき数字
大規模repoほど効きやすく、小規模repoでは過剰になりうる
生成AIを「少し触って終わり」にせず、業務効率化・副業・AIエージェント活用までつなげたい方向けに、基礎から実践まで整理できる無料資料を用意しています。
記事とあわせて、AIに作業を任せる考え方や長く使える活用スキルを確認しておきたい方は受け取っておいてください。

code-review-graphで何が変わる?
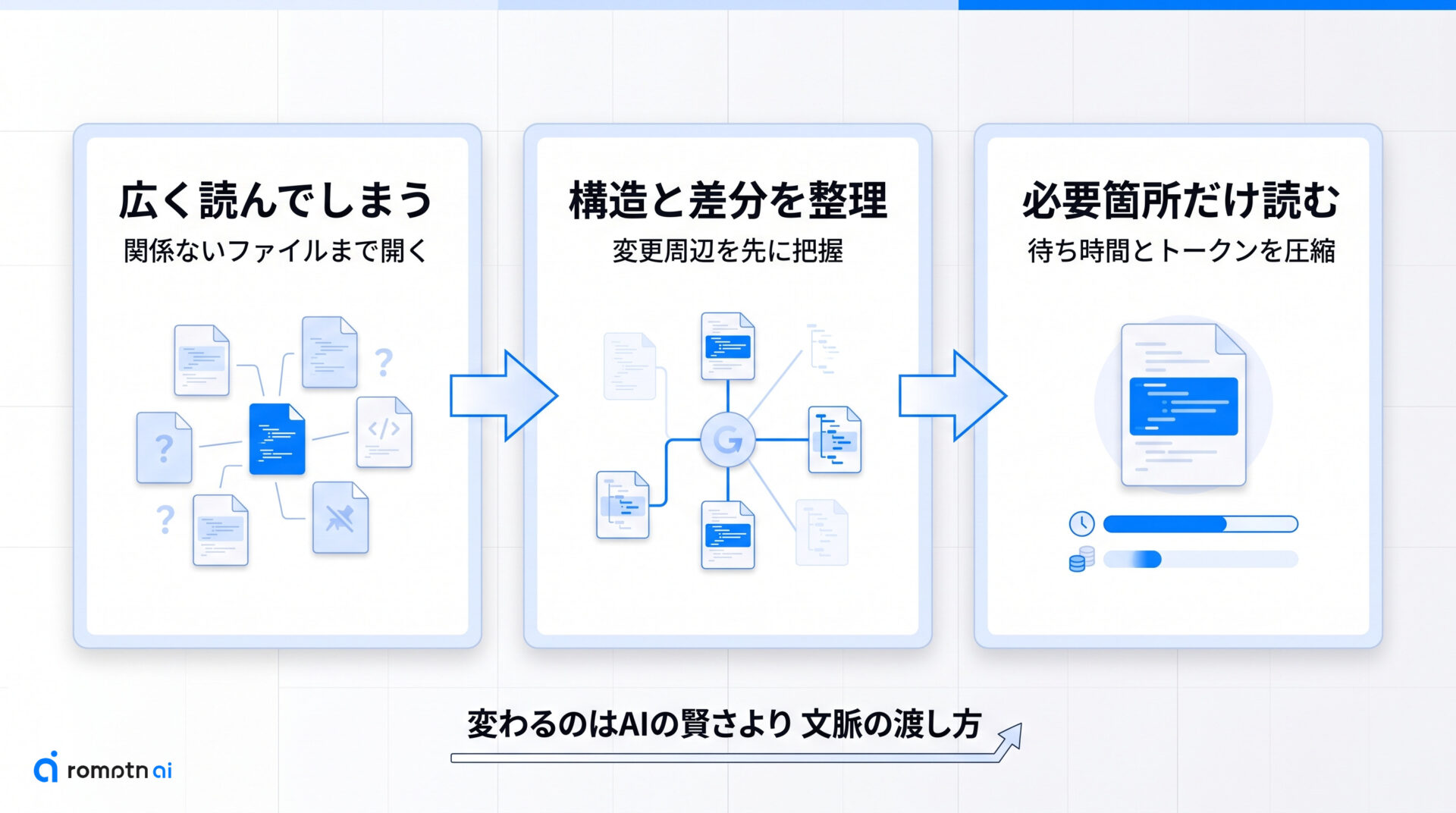
まず押さえたいのは、code-review-graphはAIにコードベース全体を広く読ませる前提を変えるツールだという点です。大きいrepoほど、Claude CodeやCodexが関係ないファイルまで開いてしまい、待ち時間とトークン消費が膨らみやすくなります。
code-review-graphは、リポジトリの構造を先に地図として持っておき、変更と依存関係に近い場所だけを返します。そのため「毎回ひと通り読む」よりも、影響範囲を絞って確認しやすくなります。
要するに変わるのは、AIの賢さそのものより渡す文脈の量と精度です。次の章で、なぜそれで無駄読みが減るのかを3つの流れに分けて見ていきます。
仕組みを3つで理解する
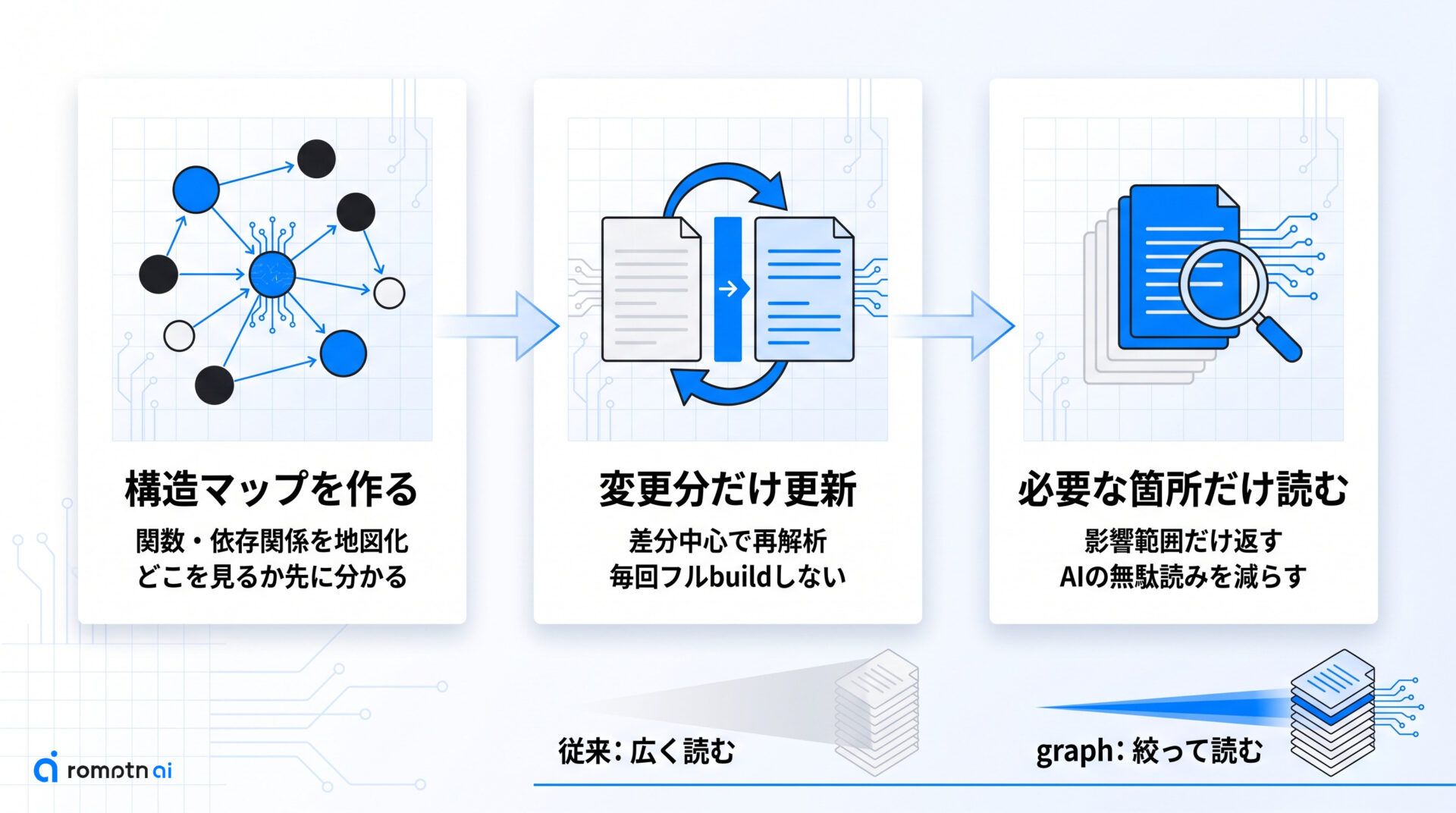
ここでは、code-review-graphがどうやって読む量を減らすのかを3段階で整理します。単なる全文検索の強化ではなく、事前に構造を持ち、差分だけ更新し、その結果をAIが参照する流れで効いてきます。
普通のgrepは「文字列がどこにあるか」を探すのは得意ですが、どの関数がどこから呼ばれ、変更がどこまで波及するかまでは毎回組み立て直す必要があります。code-review-graphはその組み立てを先回りして残しておくイメージです。
この3つを押さえると、ベンチマークの数字だけでなく「自分のrepoで効きそうか」も判断しやすくなります。
① 構造マップを作る
最初の要点は、コードをファイルの羅列ではなく構造付きの地図として持つことです。READMEではTree-sitterを使って関数、クラス、import、呼び出し関係などを拾い、後から問い合わせやすい形にしています。
この地図があると、AIは「認証処理の入口はどこか」「この変更に連動するテストは何か」を、テキスト一致だけに頼らず探せます。名前が似た関数を片っ端から開くより、関係線に沿って当たりをつけやすいのが大きな違いです。
つまり初回の解析は少し手間でも、以後のレビューや調査で迷いにくくなる土台を先に作っているわけです。
② 変更分だけ更新する
次の要点は、地図を毎回ゼロから作り直さないことです。作者コメントでは、変更ファイルとその依存先を中心に再解析する増分更新が核だと説明されています。
これが効くのは、日常の開発ではrepo全体が一気に変わることは少ないからです。1つのPRや数ファイルの修正なら、影響が及ぶ周辺だけ追えれば十分な場面が多く、全ファイル再解析より待ち時間を抑えやすくなります。
大きいrepoほど「前回との差分だけ見る」価値は大きくなります。無駄読み削減は、検索の上手さよりこの更新戦略に支えられています。
③ 必要な箇所だけ読む
3つ目は、AIが最終的に受け取る文脈そのものを細くすることです。graphは変更箇所の周辺、呼び出し元、依存先、関連テストなどを絞り込み、レビューに必要そうな範囲だけ返す前提で動きます。
その結果、AIは「関係がありそうな数ファイル」から考え始められます。人間でも、影響範囲が見えた状態ならレビューが速くなるのと同じで、AIも読む対象が整理されるほど判断が安定しやすくなります。
全文検索や手作業のgrepが不要になるわけではありません。ただ、最初に当たる範囲を狭められるので、深掘りの起点を作る道具としてかなり相性が良いです。
導入手順
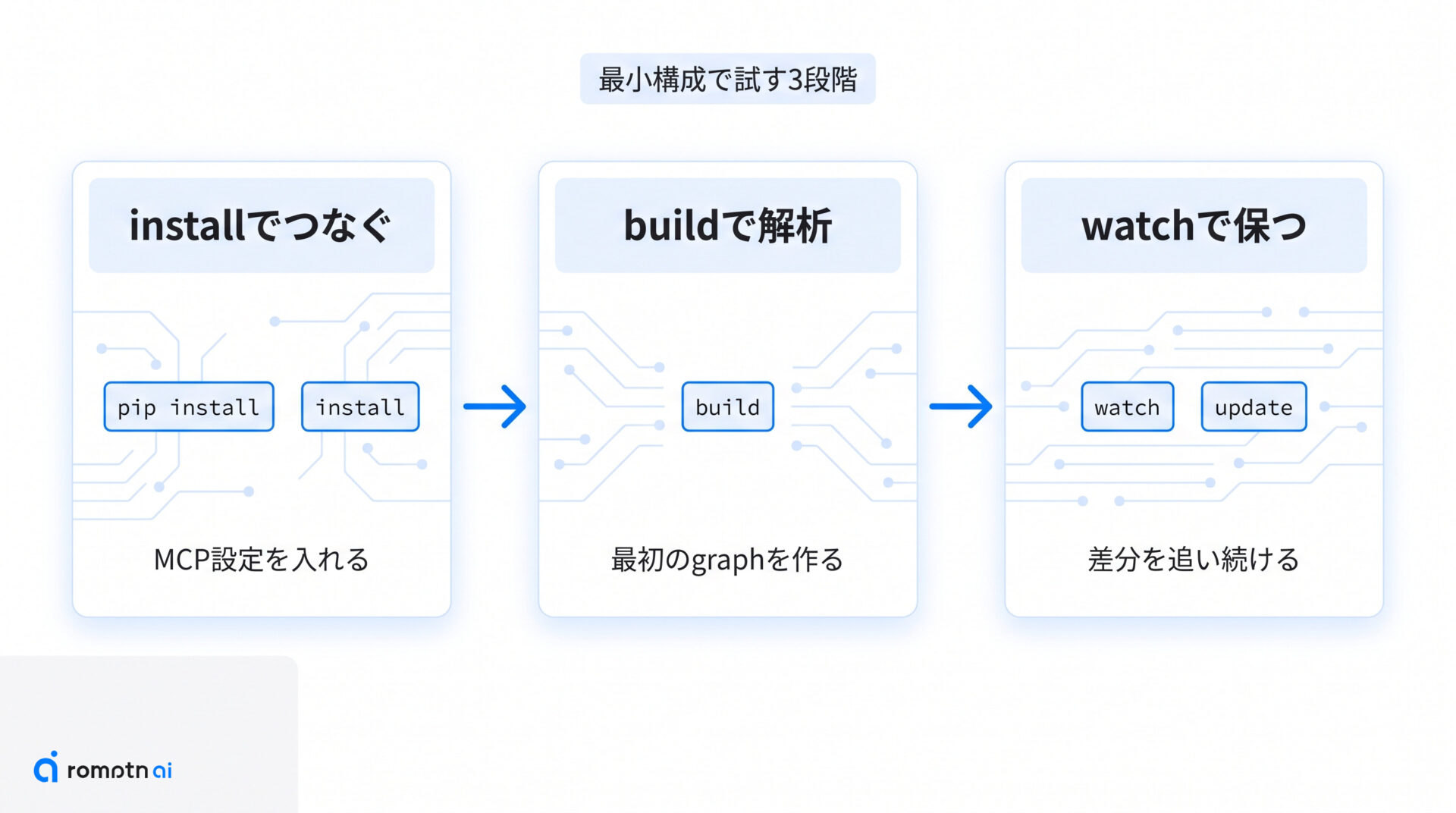
ここからは、実際に試すための流れを install・build・更新維持の3段階で見ます。READMEのQuick Startもこの順番なので、まずはこの並びのまま触るのが最短です。
大事なのは、最初から高度な運用まで覚えなくていいことです。最初の目的は「自分のrepoでgraphが作れるか」「AIツール側から参照できるか」を確認することなので、導入直後は最小構成で十分です。
次の3つの章を順に進めれば、初回セットアップから普段の更新方法まで全体像を一気に掴めます。
① installで環境をつなぐ
最初はCLIを入れて、MCP設定を書き込む段階です。執筆時点ではREADMEのQuick Startが次の形になっています。
pip install code-review-graph
code-review-graph installinstall は、入っているAIツールを見つけて設定ファイルやルールを整える役目です。個別に試したいなら code-review-graph install --platform codex や --platform claude-code のように絞れます。
もし入れたのに認識されないなら、READMEどおりエディタやCLIを再起動してから確認してください。環境差分で最初につまずく人もいるので、ここは一気に詰め込まず、まず1つのツールで動くかを見るのが安全です。
② buildで解析する
設定が入ったら、次はgraphそのものを作ります。READMEの案内はシンプルで、まずは次の1コマンドです。
code-review-graph build執筆時点では、公式READMEで「500ファイル規模なら初回buildは約10秒」と案内されています。ここは絶対値として受け取るより、初回解析でも長時間待たされにくい目安と考えるのが自然です。
build が終われば、AIはrepo全体を手探りで読む代わりに、このgraphを問い合わせの起点にできます。最初の確認では、build後に status や実際のレビュー指示で動作を見ると手応えをつかみやすいです。
③ 更新を追い続ける
導入後に大事なのは、graphを一度作って終わりにしないことです。READMEでは watch mode と hooks を使って、保存やコミットに合わせて更新を回す運用が案内されています。
code-review-graph watch
code-review-graph update毎回フルbuildするより、普段は watch や update で差分を反映させる方が現実的です。そうしておくと、次にAIへレビューや調査を頼んだ時も古い地図を読ませずに済みます。
チーム運用まで考えるなら daemon やGitHub Actionもありますが、まずはローカルで更新が回る状態にするだけでも十分効果を感じやすいはずです。
ベンチマークはどう見る?
ここは、派手な数字をそのまま期待値にしないための章です。執筆時点では公式READMEが、6つの実repo評価で中央値を約82x、レンジを38x〜528xと説明しています。
見るべきなのは「528xも減る」ではなく、528xは最良条件で、典型値は中央値側にあるという点です。README自体も best case と typical result を分けて書いているので、記事でもそのまま受け取るのが安全です。
自分のrepoで近い結果になるかは、ファイル数、変更の広がり、質問の仕方で変わります。まずは導入して、普段のレビュー質問でどれだけ読む範囲が絞られるかを観察するのが現実的です。
向く人と注意点
最後に大事なのは、誰にとって効きやすいかを冷静に見ることです。code-review-graphは面白い仕組みですが、どんなrepoでも同じ価値が出る万能薬ではありません。
判断の軸はシンプルで、無駄読みの痛みがどれだけ大きいかです。大規模repoや依存関係が広い変更では恩恵を感じやすく、逆に小さいrepoでは導入コストの方が目立つこともあります。
次の2つで、向いているケースと先に知っておきたい注意点を分けて整理します。ここを読むと、試すべきか見送るべきかをかなり決めやすくなります。
① 効果が出やすいケース
効果を感じやすいのは、まずファイル数が多く、変更の影響先が見えにくいrepoです。バックエンドやモノレポのように、1つの変更が複数レイヤーへ波及しやすい環境では特に相性が出ます。
また、自分で実装する時間よりレビューや調査に時間を使う人にも向いています。影響範囲を先に絞れるだけで、PR確認や不具合調査の初動がかなり軽くなるからです。
「AIは便利だが、毎回読ませる量が重い」と感じているなら、試す価値は高めです。逆に、その痛みをまだ感じていないなら優先度は少し落ちます。
② つまずきやすい点
注意したいのは、導入が完全にノーリスクではないことです。Hacker Newsでも、推奨の導入手順でうまく動かなかったという声があり、環境差分や既存設定との相性は見ておく必要があります。
もう1つは、repoが小さい場合です。数十ファイル規模で影響範囲も頭に入りやすいなら、graphを維持するより普通に読む方が早いこともあります。
期待値としては、「大きいrepoほど効きやすい」「最初の導入確認は小さく試す」が妥当です。いきなり全社標準にするより、自分の代表的なrepoで価値を測る方が失敗しにくいです。
よくある質問
- Qcode-review-graphは何をするツールですか?
- A
リポジトリを構造付きのgraphとして保持し、AIがレビューや調査で読むべき範囲を絞り込むためのツールです。全文検索を置き換えるというより、どこから読むと無駄が少ないかを先に示す役割だと考えると分かりやすいです。
- QClaude CodeやCodexのどこが変わるのですか?
- A
一番の変化は、AIが最初に開く文脈の量です。repo全体を広く探る代わりに、変更箇所や依存関係に近いファイルから当たりやすくなるので、待ち時間とトークン消費の両方を抑えやすくなります。
- Qベンチマークの数字は自分のrepoでも同じですか?
- A
同じにはなりません。執筆時点では公式READMEが中央値約82x、最大528xと示していますが、repo規模、変更の広がり、質問内容で大きく変わります。まずは自分の普段のレビュー質問で、読む範囲がどこまで減るかを見るのが確実です。
- Q小さいrepoでも入れる意味はありますか?
- A
小さいrepoでも試す意味はありますが、効果は相対的に小さくなりやすいです。数十ファイル規模なら人やAIが直接読んでも十分追えるため、導入と維持の手間が勝つことがあります。無駄読みの痛みが強いかどうかで判断してください。
まとめ
最後に、導入判断で覚えておきたい点だけを絞ります。code-review-graphは「AIを賢くするツール」ではなく、「AIに渡す読み取り範囲を賢く絞るツール」と捉えると全体像がつかみやすいです。
- Tree-sitterベースの構造マップを先に作り、関係の深い場所から読ませる
- install → build → watch の順で試すと、初回導入から日常運用まで迷いにくい
- ベンチマークは中央値と上振れ値を分けて見て、自分のrepoで小さく検証する
- 大規模repoやレビュー中心の作業では効きやすく、小規模repoでは過剰になることもある
次にやることはシンプルです。まずは1つの開発環境で install と build を試し、普段のレビュー質問で読む範囲がどう変わるかを確認してください。その差がはっきり見えるなら、watch やチーム運用まで広げる価値があります。
AIを実務で使い続けるには、ツール名を覚えるだけでなく、目的を分解し、文脈を渡し、出力を評価する力が必要です。AI副業やAIエージェント活用の入口をまとめた資料セットを無料で受け取れます。
無料資料を受け取る

