
Stable Diffusionは2022年に公開されて以来、AIによる画像生成の世界に革命をもたらしました。特にStable Diffusion 1.5(SD1.5)は、その後にStable Diffusion 2.0/2.1、SDXL、さらには最近発表されたStable Diffusion 3が登場した現在でも、多くのユーザーから高い支持を得続けている人気バージョンです。
なぜSD1.5がこれほどまで愛され続けているのか?その魅力と実用性、そして初心者から上級者まで幅広く使える柔軟性について、この記事では詳しく解説していきます。SD1.5の基本情報から導入方法、おすすめのモデル、さらには最新版との違いまで、徹底的に掘り下げていきましょう!
- Stable Diffusion 1.5とは
- Stable Diffusion 1.5の導入方法
- Stable Diffusion 1.5の基本的な使い方
- Stable Diffusion 1.5のアップデート・ダウングレード方法
- Stable Diffusion 1.5とSDXLの違い
- Stable Diffusion 1.5とStable Diffusion 3/3.5の違い
- Stable Diffusion 1.5用おすすめモデル
内容をまとめると…
SD1.5は軽量・高速で拡張機能やモデルの資産が豊富なため、SDXLやSD3登場後も根強い人気を維持
Google Colab・Windows(AUTOMATIC1111/Forge)・Macの3環境から導入でき、VRAM 4GB程度のPCでも動作可能
SDXLは高解像度・高品質だがVRAM 16GB以上が必要、SD3.5はテキスト描画に強いがコミュニティ資産が少ない
SD1.5用おすすめモデルにはアニメ系のAnything V5、実写系のRealistic Vision V6.0などがある
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Stable Diffusion 1.5とは
Stable Diffusion 1.5は、2022年10月にStability AI社から公開された学習済みモデルです。Stable Diffusionは2022年8月に初めてオープンソースとして公開され、その後1.1、1.2、1.3、1.4を経て1.5へとアップデートされてきました。
Stable Diffusion 1.5の提供元は「runwayml」で、バージョン1.4の提供元「CompVis」から変更されています。CompVisは大学の研究所チームであり、Stability AI社とRumwayMLはここに出資している関係にあります。公開当初は、RumwayMLが突然Stable Diffusion 1.5を公開したとして、Stability AI社が公開の差し止めを求めるなどのトラブルも発生しました。
現在では、Stable Diffusion 2.1、SDXL、SD3まで開発が進んでいますが、SD1.5は今でも根強い人気を持ち続けています。
Stable Diffusion 1.5の主な特徴
- 自分の好きなテキスト(プロンプト)を入力して、高品質なAI画像を生成できる
- NSFW(Not Safe For Work)画像が生成されにくく、安全性が向上
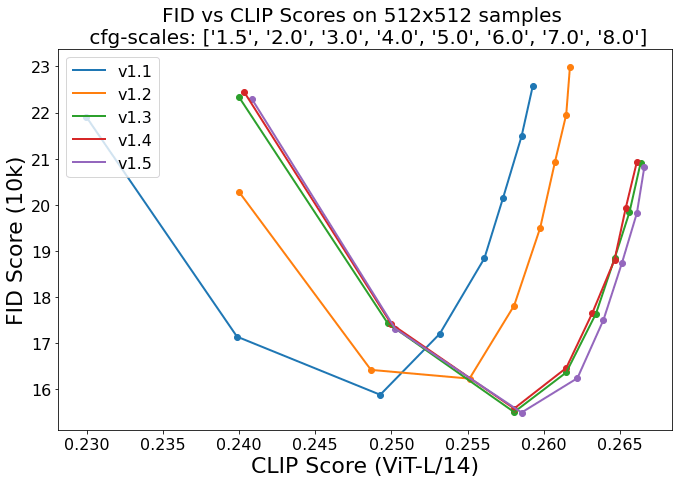
- 生成された画像のプロンプト適合度を示す「CLIP Score」と実際の画像との差を評価する「FID Score」のバランスが良好(※上記図参照)
- 軽量で処理速度が速く、標準的なPCでも快適に動作する
- 多くのコミュニティサポートと豊富な学習モデルが利用可能
Stable Diffusion 1.5の導入方法
SD1.5を始めるための方法はいくつかありますが、ここでは代表的な3つの導入方法を詳しく解説します。
Google Colabを使った導入方法(PC環境を問わない方法)
まず初めに1番メジャーなGoogle ColabでStable Diffusion1.5をインストールする方法を説明していきます。
※Google ColabでStable Diffusionを利用する方法について、以下の記事で詳しく解説していますので併せてお読みください!

①こちらにアクセスしてください。
今回は、こちらのノートブックでStable Diffusion1.5をインストールしていきます。
②ノートブックを開いたら、ランタイムを“GPU”に設定し、左の▶ボタンを押して上から順に実行していきます。
- はじめの『Connect Google Drive』の際は、Googleドライブへのアクセスを許可してください。
- 『Model Download/Load』の際は、『Model_Version』の項目から“1.5”を選んでください。
- 最後の『Start Stable-Diffusion』でURLが出てきたらクリックして、Stable Diffusionを立ち上げます。

これで、Stable Diffusion1.5のインストール(ダウンロード)は完了です!
Google Colabでインストールに失敗した場合の対処法
huggingface_hub.utils._errors.RepositoryNotFoundError: 401 Client Error: Repository Not Foundこのエラーが表示された場合は、一度ローカルにモデルを保存してからGoogle Colabを実行するとうまくいくことがあります。
先程ご紹介したGoogle Colabの記事のモデルをダウンロードする方法のページに詳しいやり方を説明してありますので、こちらを参考にStable Diffusion1.5をインストールし直してみてください!
Windows PCへのインストール方法
ここでは、「AUTOMATIC1111版(スタンダード版)」と「Forge版(最新機能強化版)」に分けて説明していきます!
AUTOMATIC1111版(スタンダード版)
①GitHubからAUTOMATIC1111のリポジトリをダウンロード
②解凍したフォルダ内の「webui-user.bat」をダブルクリック
③初回起動時は必要なファイルがダウンロードされるため時間がかかります
④ブラウザが自動で開き、Web UIが表示されます
※詳しくは、下記記事を参考にしてください。

Forge版(最新機能強化版)
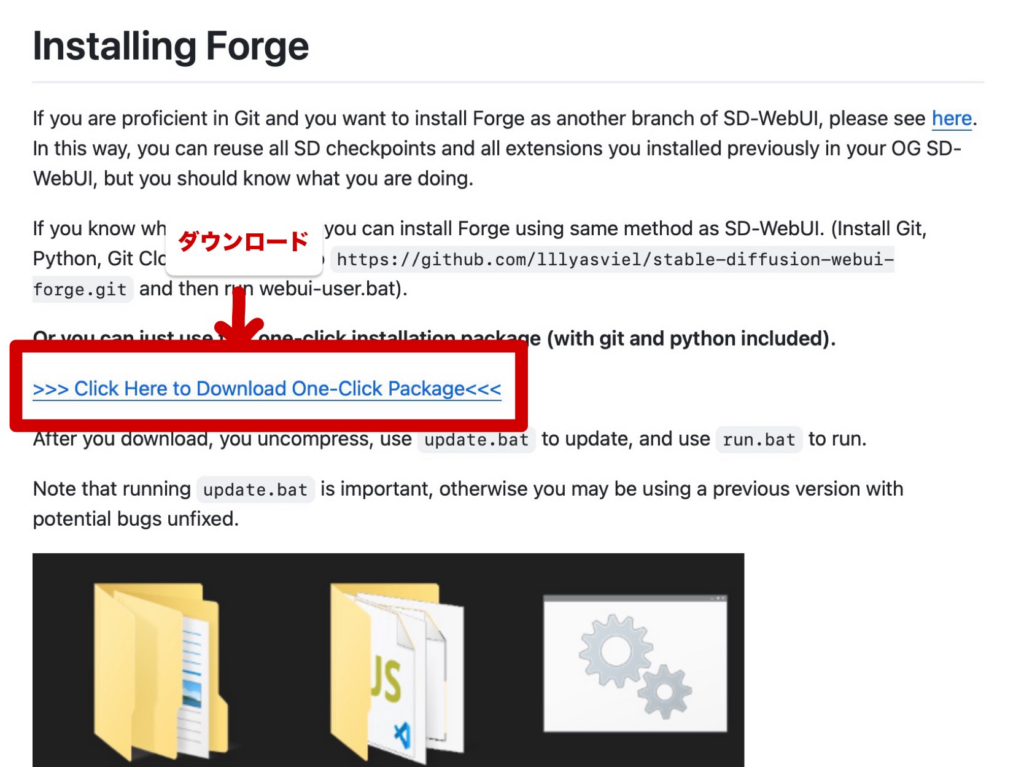
GitHubのページ上で提供されている圧縮ファイルをダウンロードすることでStable Diffusion WebUI Forgeをローカル環境で使用することができます!
手順は以下の通りです。
- GitHubから圧縮ファイルをダウンロードする
- ダウンロードした圧縮ファイルを解凍する
- ファイルが解凍されたら、「update.bat」を開く
- 次に「run.bat」を開くと、Stable Diffusion WebUI Forgeが起動します。
ファイルのダウンロードは以下のページから行いましょう!
※詳しくは、下記記事を参考にしてください。

Mac向けインストール方法
Macユーザーの場合は、ターミナルから以下の手順で導入できます。
①ターミナルを開き、リポジトリをクローンする
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui②ディレクトリに移動
cd stable-diffusion-webui③起動スクリプトを実行する
bash webui-user.sh④ブラウザで「http://localhost:7860」にアクセスしてWeb UIを開く
Stable Diffusion 1.5の基本的な使い方
SD1.5のセットアップが完了したら、実際に画像生成を開始しましょう。ここでは基本的な使い方を解説します。
いつも通り、呪文(プロンプト)やネガティブプロンプトを入力して画像を生成していきます。SD1.5で良質な画像を生成するためのプロンプト作成のコツとともに紹介します!
※Stable Diffusionの使い方については、下記記事を参考にしてください。

まず、効果的なプロンプトの書き方は以下の通りです。
- 具体的で明確な単語を使用する
- カンマで区切って重要な要素から順に記述する
- 画風や撮影スタイル、照明などの細かい指定を入れる
- 重要な要素には強調ウェイト(例:beautiful landscape:1.2)を付ける
- ネガティブプロンプトで不要な要素を除外する
これらを基に画像を生成してみましょう!
プロンプト
(masterpiece, best quality:1.4), (8k, raw photo, photo realistic:1.2), (shiny skin), 1girl, whole face, detailed skin, detailed face, detailed eyes, extremely beautiful faceネガティブプロンプト
(worst quality, low quality:2), (painting, sketch, flat color), monochrome, grayscale, ugly face, bad face, bad anatomy, deformed eyes, missing fingers, acnes, skin blemishesそして、生成された画像がこちらです!

アニメ系でも生成してみましょう。
プロンプト
(masterpiece, best quality:1.3), anime style, 1girl, cute face, long silver hair, blue eyes, magical girl, detailed school uniform, cherry blossom, soft lighting, detailed background, standing poseネガティブプロンプト
(worst quality, low quality:1.4), bad anatomy, bad hands, extra digits, fewer digits, missing arms, deformed face, blurry, cropped, lowres, text, watermark, signature
バージョンが最新でなくても、きれいに生成できています!
※さらに詳しい呪文(プロンプト)を入力する際のコツや、おすすめのネガティブプロンプトについては以下の記事で詳しく解説していますので、併せてお読みください!


さらに、Stable Diffusion 1.5で最良の結果を得るための推奨設定もあります。
- サンプラー:DPM++ 2M Karras、Euler a
- ステップ数:20~40(値が大きいほど品質が向上するが時間がかかる)
- CFGスケール:7~8(値が大きいほどプロンプト忠実度が上がる)
- 解像度:512×512(正方形)または 512×768(縦長の場合)
- Clip skip:2(多くのSD1.5モデルで推奨)
- VAE:vae-ft-mse-840000-ema(多くのモデルで相性が良い)
- Hires. fixを使用する場合:
- Denoising strength:0.3~0.6
- アップスケーラー:R-ESRGAN 4x+ Anime6B(アニメ調)、4x-UltraSharp(写実調)
※Stable Diffusionの設定については、下記記事で詳しく解説しています。

Stable Diffusion 1.5のアップデート・ダウングレード方法
Stable Diffusion Web UIのバージョンを管理する方法についても解説します。
バージョンの確認方法
現在使用しているSD Web UIのバージョンを確認する方法は、以下の通りです。
①Web UIを起動したときにターミナルに表示されるCommit hashを確認

②Web UIの画面上部に「Version: vX.X.X」の形式でバージョンが表示される

Stable Diffusionの最新版へのアップデート方法
①ターミナルを開いてstable-diffusion-webuiのディレクトリ行きましょう。ターミナル上で
cd ~/stable-diffusion-webuiコピペして、enterキーでOKです。stable-diffusion-webuiのディレクトリに着いたら
git pullこれもコピペして、enterキーでOKです。たったこれだけで更新作業が始まります。
②ターミナルを開いてstable-diffusion-webuiのディレクトリにいきましょう。操作は先ほどと全く同じです。
ターミナル上で
cd ~/stable-diffusion-webuienterしてください。もうそこにいる場合は飛ばしてください。
次に
./webui.shenterで起動します。
新しいバージョンがどんな感じなのかとても気になります。イシューを見る限りかなりバグが多そうですね。
とりあえず何か描かせてみましょう。
ちなみに私が「V1.6.0」へバージョンアップした時は問題なく作動しました。
UIが今までとは変わっています。loraの場所がいつもの場所に無くて探せませんでした。そしてやっと見つけてloraを入れたら、今度はそれを閉じられません。
なんとかできましたが、慣れるまで苦労しそうです。最後はSettingsタグも確認しておきましょう!
特定バージョンへのダウングレード方法
下記コードを実行することでダウングレードが可能になります!
git checkout ダウングレードしたいバージョン(例:v1.3.0)ここで注意が必要なのですが、ダウングレードは以前に「git pull」でバージョンアップしたことがあるという場合のみ実行できます!
ダウングレードした後にアップグレードする方法
旧バージョンにダウングレードしたけど、やっぱり最新バージョンにアップグレードしたい!というときは、以下のコードを実行すると最新バージョンに変更できます。
git checkout master※詳しくは、下記記事を参考にしてください!

Stable Diffusion 1.5とSDXLの違い
多くのユーザーが気になるのは、SD1.5と最新版のSDXLとの違いです。それぞれの特徴を比較してみましょう。
まずは基本性能を比較してみました。
| 特徴 | Stable Diffusion 1.5 | SDXL |
|---|---|---|
| 基本解像度 | 512×512 | 1024×1024 |
| パラメーター数 | 少ない | 多い(約3倍) |
| メモリ要件 | 低い(4GB~) | 高い(8GB~推奨) |
| 処理速度 | 速い | やや遅い |
| 画質・ディテール | 良好 | より細密 |
| プロンプト対応 | カンマ区切りキーワード型 | より自然言語に近い |
| 色表現 | 鮮やか | くすんだ印象になることも |
どちらもメリット・デメリットがあり、使いたい機能の優先順位によってどちらを使うかが分かれそうな結果となりました。
画像生成の特徴と得意分野の比較
SD1.5の得意分野は、以下の通りです。
- リアルな人物や学習したキャラクターの再現性が高い
- プロンプトのコントロールが効きやすい
- 処理が速く、多くの画像を短時間で試せる
- 特にアニメ風やイラスト系の画像生成が優れている
SDXLの得意分野は、以下の通りです。
- 高解像度でディテールの多い画像
- 複雑な構図や背景の描写
- 現実に存在しない創造的な要素の表現
- 風景や建築物などの細密な描写
初心者の方は、Stable Diffusion 1.5から始めて、慣れたらSDXLを使うといった用途が良さそうですね。
なぜStable Diffusion 1.5が今でも人気なのか?
以上のことを踏まえて、SD1.5が新しいバージョンの登場後も人気を維持している理由は、以下の5つが考えられます。
- パラメーター数の少なさがメリットに:パラメーター数が少ないため、学習素材に近い「リアル」な画像が生成されやすく、特に人物やキャラクターの生成で強みを発揮
- 豊富なコミュニティリソース:長い期間使われてきたため、情報やチュートリアル、トラブルシューティングの資料が充実
- 多様なカスタムモデル:数多くのチェックポイントモデル、LoRAモデル、Textual Inversionが開発されている
- 低リソース要件:中~低スペックのPCでも快適に動作し、処理速度も速い
- プロンプトの扱いやすさ:プロンプトの挙動が理解しやすく、意図した画像を生成しやすい
Stable Diffusion 1.5とStable Diffusion 3/3.5の違い

では、最新のStable Diffusion 3/3.5シリーズと比較すると、どのような違いがあるのでしょうか。
性能と機能の比較をしてみました。
| 特徴 | SD1.5 | SD3/3.5 |
|---|---|---|
| 文字生成能力 | 不正確 | 大幅に向上 |
| 位置関係の理解 | 弱い | 非常に優れている |
| プロンプト対応 | 限定的 | 長文・詳細な指示に対応 |
| ネガティブプロンプト | 対応 | 未対応(SD3) |
| 処理要件 | 軽量 | 非常に重い |
| 使いやすさ | 簡単 | 複雑な設定が必要 |
使い分ける条件に関しては、以下を参考にすると良いでしょう。
SD1.5が適している状況
- 中~低スペックのPC環境での使用
- アニメ風やイラスト系の画像生成
- リアルな人物やキャラクターの生成
- 高速で多くのバリエーションを試したい場合
- 特定の学習モデル(LoRAなど)を使いたい場合
SD3/3.5が適している状況:
- 高スペックのPC環境がある
- 文字や位置関係を正確に表現したい
- 詳細で長いプロンプトを使用したい
- 最新の生成品質を求める場合
- 創造的で複雑な表現を実現したい場合
Stable Diffusion 1.5用おすすめモデル10選!
Stable Diffusion 1.5の大きな魅力は、多様なチェックポイントモデルが利用できることです。ここでは、カテゴリ別に優れたモデルを紹介します。
※Stable Diffusionのモデルの導入方法については、下記記事で詳しく解説しています。

アニメイラスト系モデル
①Dark Sushi Mix 2.25D
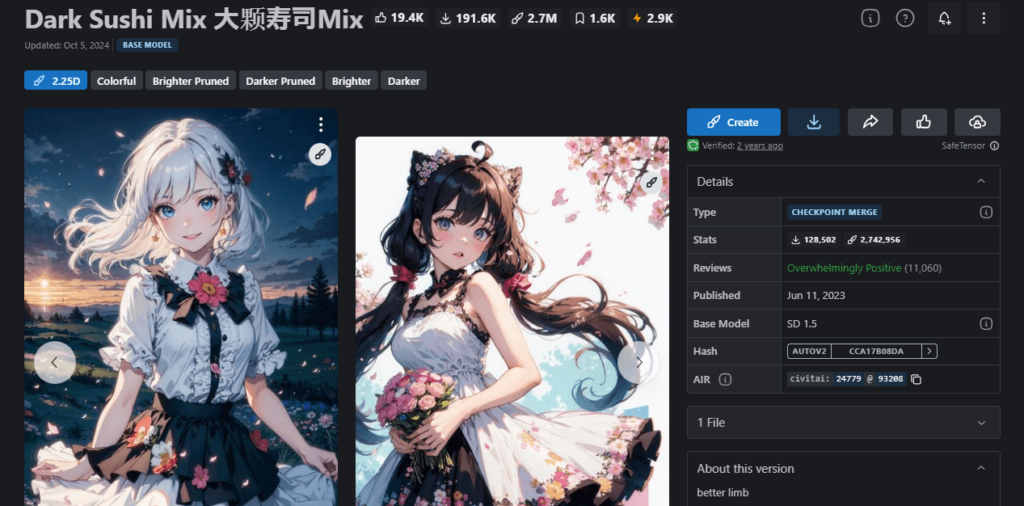
| 作者 | Aitasai |
| 特徴 | 2Dと2.5Dの中間で、女性や背景描写が細かく美しい |
| 推奨設定 | VAE: vae-ft-mse-840000-ema Hires.fix: オン |
| ダウンロードリンク | https://civitai.com/models/24779/dark-sushi-mix |
| 参考になる記事 | https://romptn.com/article/14659 |
②ShiratakiMix
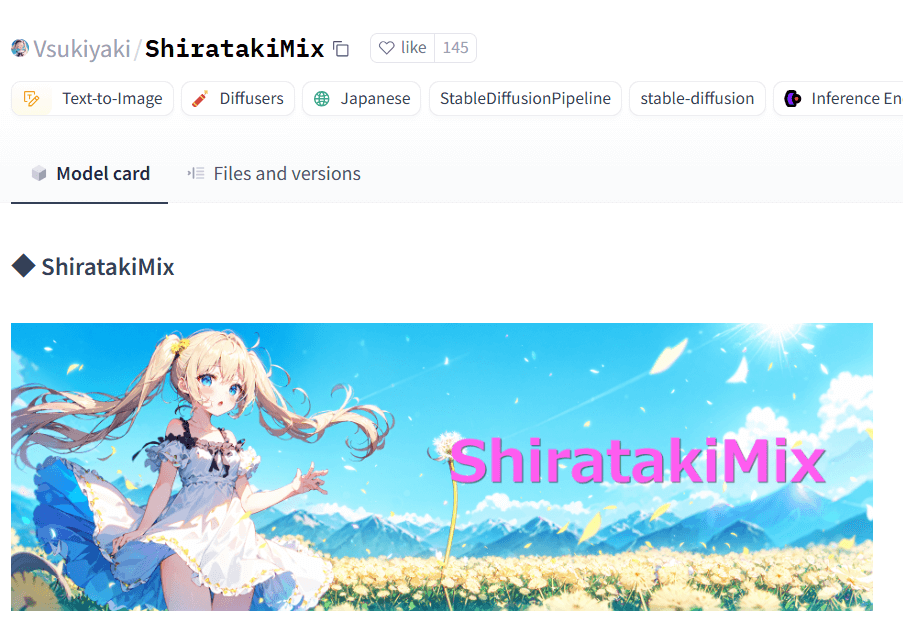
| 作者 | Vsukiyaki |
| 特徴 | カラフルで細かい描写が特徴的なアニメ調モデル |
| 推奨設定 | サンプラー:DPM++ SDE Karras ステップ:20~60 |
| ダウンロードリンク | https://huggingface.co/Vsukiyaki/ShiratakiMix |
③Counterfeit-V3.0
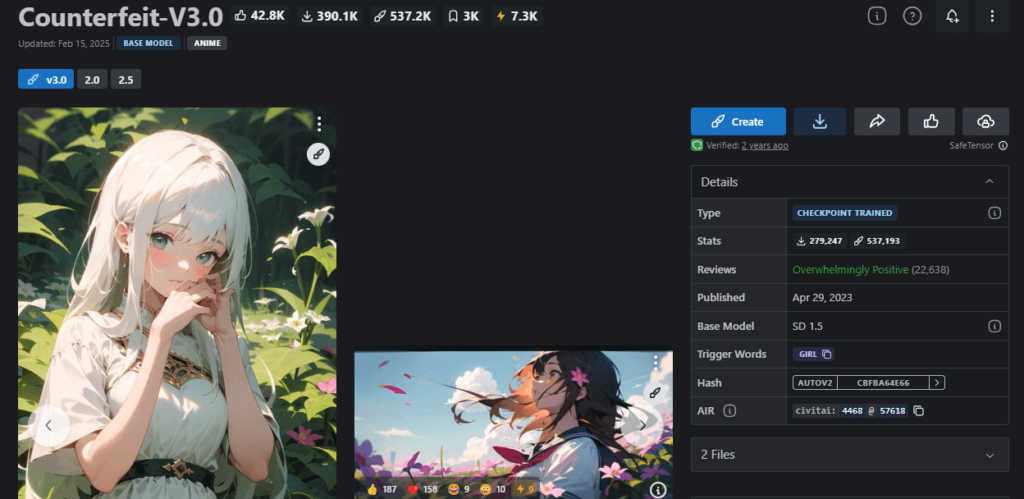
| 作者 | rqdwdw |
| 特徴 | Civitaiで30万以上ダウンロードされた人気モデル |
| 推奨設定 | EasyNegativeを併用すると効果的 |
| ダウンロードリンク | https://civitai.com/models/4468/counterfeit-v30 |
| 参考になる記事 | https://romptn.com/article/6344 |
④MeinaMix
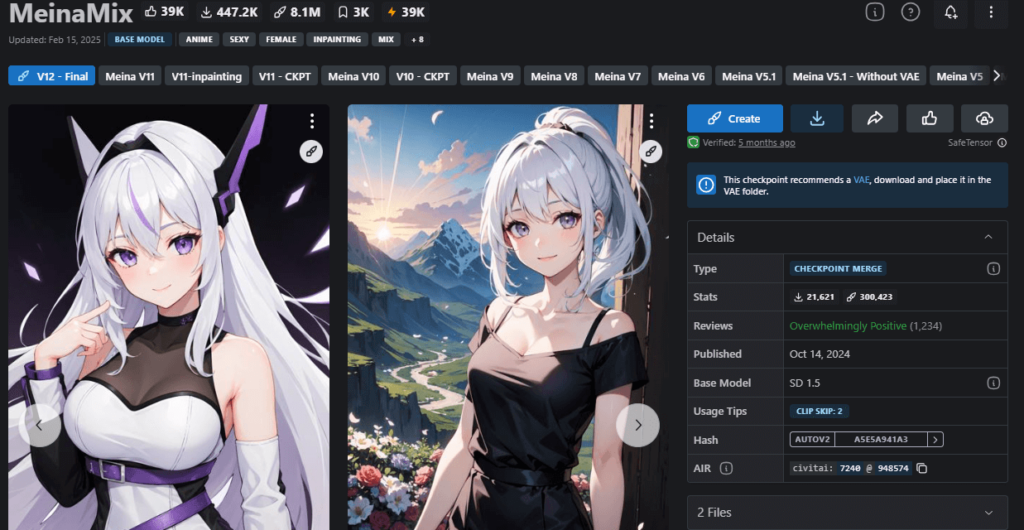
| 作者 | Meina |
| 特徴 | シンプルなプロンプトで高品質なアニメイラストを生成 |
| 推奨設定 | 特になし |
| ダウンロードリンク | https://civitai.com/models/7240/meinamix |
| 参考になる記事 | https://romptn.com/article/14898 |
2.5D系モデル
2.5D系モデルは2Dと3Dの中間的な表現が特徴で、立体感のあるイラストが生成できます。
①AniVerse
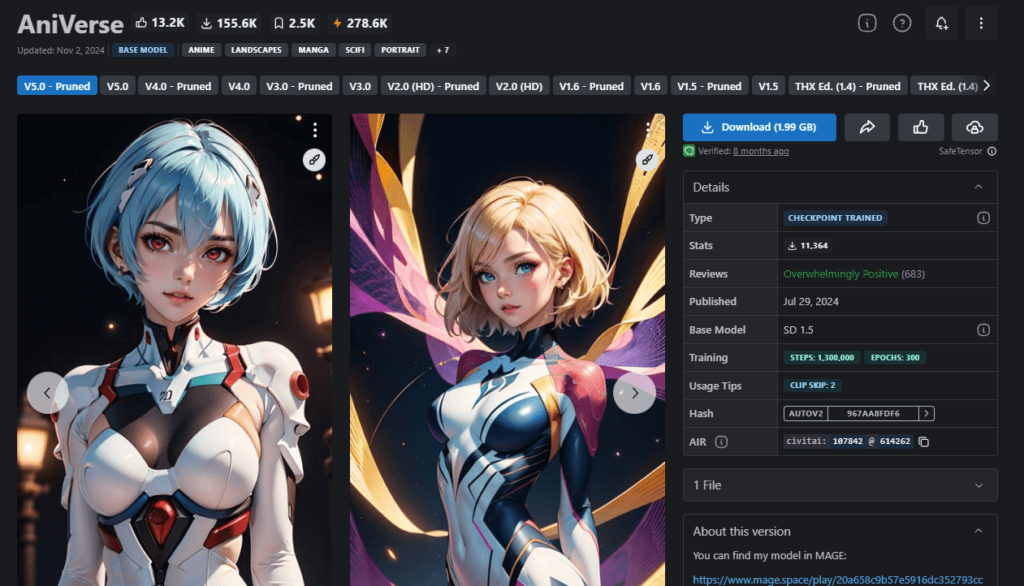
| 作者 | Samael1976 |
| 特徴 | 高品質な2.5D系画像を生成、背景描写も優れている |
| 推奨設定 | 特になし |
| ダウンロードリンク | https://civitai.com/models/107842/aniverse |
②RealCartoon3D
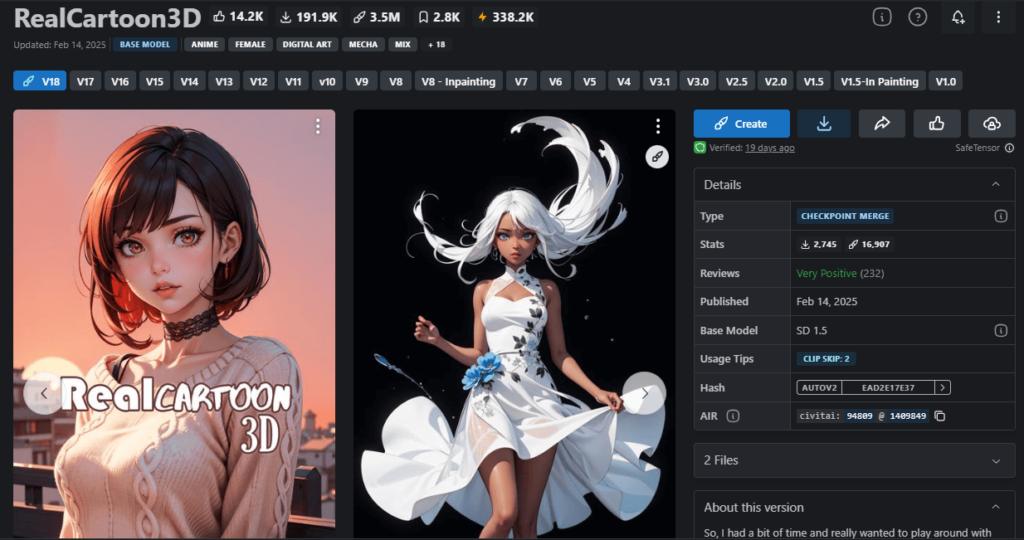
| 作者 | 7whitefire7 |
| 特徴 | Civitaiで15万以上ダウンロードされた人気の2.5Dモデル |
| 推奨設定 | 特になし |
| ダウンロードリンク | https://civitai.com/models/94809?modelVersionId=1409849 |
③Kakarot 2.8D
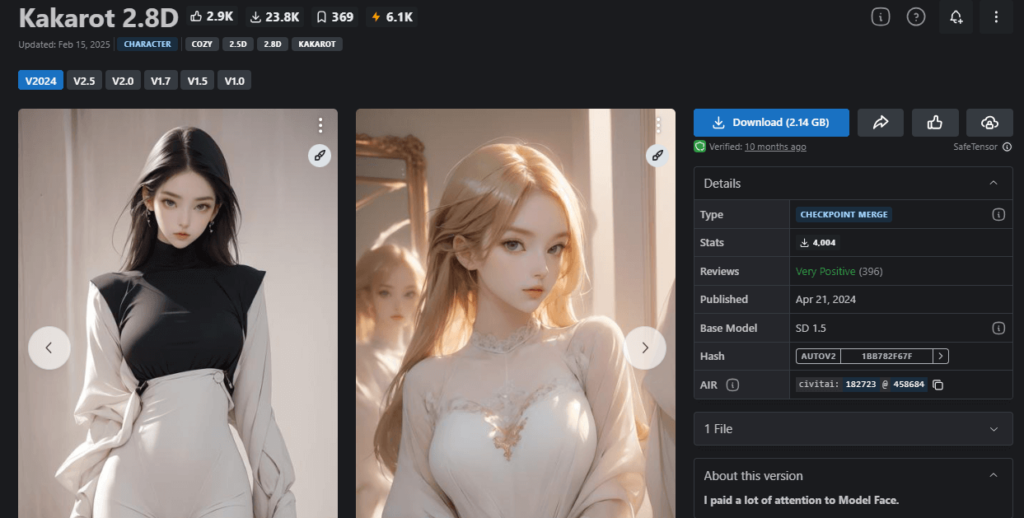
| 作者 | vay_kakarot |
| 特徴 | オリジナリティのある2.5D系画像を生成 |
| 推奨設定 | 特になし |
| ダウンロードリンク | https://civitai.com/models/182723?modelVersionId=458684 |
写実・リアル系モデル
写真のようなリアルな画像を生成したい場合におすすめのモデルです。
①majicMIX realistic
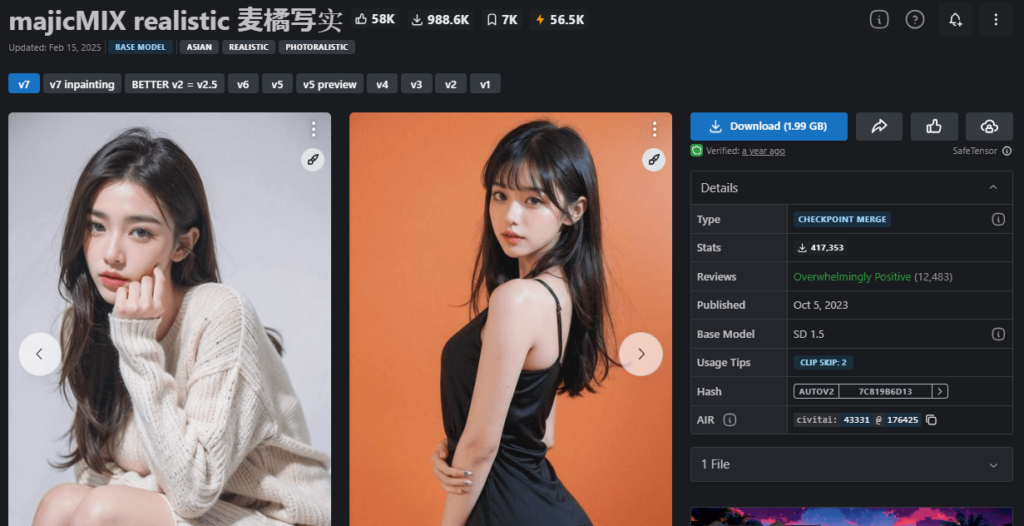
| 作者 | Merjic |
| 特徴 | アジア人の生成を得意とした実写系モデル |
| 推奨設定 | 特になし |
| ダウンロードリンク | https://civitai.com/models/43331?modelVersionId=176425 |
| 参考になる記事 | https://romptn.com/article/11681 |
②DreamShaper
| 作者 | Lykon |
| 特徴 | MidJourneyの代替として開発された幅広い表現が可能なモデル |
| 推奨設定 | 特になし |
| ダウンロードリンク | https://civitai.com/models/4384?modelVersionId=128713 |
| 参考になる記事 | https://romptn.com/article/51325 |
③XXMix_9realistic
| 作者 | Zyx_xx |
| 特徴 | Civitaiで12万以上ダウンロードされている実写系人気モデル |
| 推奨設定 | 特になし |
| ダウンロードリンク | https://civitai.com/models/47274/xxmix9realistic |
| 参考になる記事 | https://romptn.com/article/12459 |
【FAQ】Stable Diffusion 1.5を使用する際によくある質問
Stable Diffusion 1.5を使用する際に発生しがちな問題とその解決策をFAQ形式でご紹介します。
- Q「CUDA out of memory」というエラーが出て画像が生成できません。どうすれば解決できますか?
- A
このエラーはGPUのメモリ不足を意味します。以下の方法を試してみてください。
- 画像サイズを小さくする(512×512など)
- バッチサイズを1に設定する
- Web UIの「Settings」>「Optimization」で「Low VRAM mode」を有効にする
- 「Cross attention optimization」設定を「Scaled Dot Product」に変更する
- 不要な拡張機能を無効化する
- Qダウンロードしたモデルが読み込めません。どうしたらいいですか?
- A
モデルの読み込みエラーは以下の方法で解決できることが多いです。
- モデルファイルが正しいフォルダ(models/Stable-diffusion)に配置されているか確認する
- ファイル名に特殊文字や日本語が含まれていないか確認し、あれば英数字に変更する
- ファイル形式が正しいか確認する(.safetensors または .ckpt)
- Web UIを完全に終了して再起動してみる
- QGoogle Colabで「Repository Not Found」エラーが出ます。
- A
このエラーはHugging Faceからのモデルダウンロードに失敗した場合に発生します。
- 一度ローカルにモデルを保存してからGoogle Colabを実行する
- 一時的なネットワーク問題の可能性があるため、少し時間をおいて再試行する
- 別のミラーサイトからモデルをダウンロードしてGoogleドライブにアップロードする
- Q生成された画像の品質が低いです。改善方法はありますか?
- A
画質を向上させるために以下を試してみてください。
- VAEを変更する(vae-ft-mse-840000-emaなどの高品質VAEを使用)
- ステップ数を増やす(30~50程度)
- CFGスケールを調整する(7~9が一般的に良好)
- Hires. fixを使用して解像度を上げる
- プロンプトに品質を示す単語(masterpiece, best quality, detailedなど)を追加する
- Q手や指が不自然に崩れる画像が多く生成されます。対策はありますか?
- A
手の崩れはAI画像生成におけるよくある問題です。
- ネガティブプロンプトに「bad hands, extra fingers, missing fingers, fused fingers」などを追加する
- ADetailerなどの拡張機能を使って手を自動修正する
- 手を強調せずに、他の部分に注目するプロンプトを使用する
- QWeb UIが起動しない、または途中で固まってしまいます。
- A
起動の問題は以下の対処法で解決できることが多いです。
- webui-user.batファイル(Macの場合はwebui-user.sh)を編集して「–medvram」オプションを追加する
- 最新バージョンに更新する(git pullコマンドを実行)
- 特定の拡張機能が問題を引き起こしている可能性があるため、extensions-disabledフォルダを作成し、extensionsフォルダから内容を移動して、一つずつ有効化していく
- Python、CUDAのバージョンが互換性があるか確認する
- Q生成された画像が保存されません。どうすれば良いですか?
- A
画像保存の問題は以下の方法で解決できます。
- 「Settings」>「Saving」で保存パスを確認・変更する
- 「Save images to a subdirectory」オプションを有効にして別のフォルダに保存を試みる
- 何らかの理由でファイル名に問題がある可能性があるため、「Add number to filename when saving」を有効にする
- QSDXLのモデルをSD1.5のWeb UIで使用できますか?
- A
はい、可能です。ただし以下の点に注意してください。
- SDXLモデルは「models/Stable-diffusion」フォルダに配置する
- SDXLモデルは通常のSD1.5より多くのVRAMを必要とする
- 適切な解像度(1024×1024など)と設定を使用する必要がある
- 「Refiner」機能を使うには別の設定が必要
- Qエラーメッセージ「RuntimeError: Expected all tensors to be on the same device」が表示されます。
- A
このエラーは以下の方法で解決できることがあります。
- Web UIの「Settings」>「Optimization」で「Move model to CPU after processing」オプションを無効にする
- xFormersを有効にする(NVIDIA GPUの場合)
- 「Settings」>「Optimization」で「Cross attention optimization」を変更する
- 古いモデルを使用している場合は、最新のモデルに更新する
- QMac(特にApple Silicon)でSD1.5を効率よく動かす方法はありますか?
- A
Mac向けの最適化方法は、以下の通りです。
--no-halfオプションを追加する- M1/M2チップの場合は「MPS」をバックエンドとして使用する
- 解像度を控えめにする(512×512など)
- メモリ使用量の少ないモデル(pruned版など)を使用する
- 複数のタブやアプリを閉じてメモリを解放する
これらのFAQで問題が解決しない場合は、Stable DiffusionコミュニティフォーラムやReddit、Discordなどのコミュニティで質問することをおすすめします。多くの経験豊富なユーザーが助けてくれますよ!
まとめ
いかがでしたでしょうか?Stable Diffusion 1.5は、パラメーター数が少ないことによる高い再現性、豊富なモデル、低リソース要件という強みを持ち、初心者から上級者まで幅広く活用されています。
この記事のポイントをまとめると、以下の通りです。
- Stable Diffusion 1.5は軽量で処理速度が速く、標準的なPCでも快適に動作する
- Google Colab、Windows、Macなど様々な環境に導入可能
- イラスト系、2.5D系、フォトリアル系など多様なチェックポイントモデルが利用可能
- SDXLと比較して軽量だが品質も高く、特に人物やキャラクターの再現性に優れる
- 最新のSD3/3.5と比べると文字生成や位置関係の理解は劣るが、アクセシビリティが高い
目的に合わせてSD1.5、SDXL、SD3を使い分けることで、あなたのAI画像生成ワークフローがさらに充実するでしょう。まずはSD1.5から始めて、AIイメージ生成の可能性を探求してみてください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

