
画像生成AIの分野で毎日進化を遂げている「Stable Diffusion」シリーズ。その最新版である「Stable Diffusion 3.5」が2024年10月に公開され、画像生成の新たな可能性が広がっていますね。
でも、さまざまなバージョンが存在するStable Diffusionの違いや特徴、どれを使うべきなのか迷っている方も多いのではないでしょうか?
本記事では、Stable Diffusion 3を中心に各バージョンの特徴や違い、ローカル環境での導入方法、使い方などを徹底解説します。
- Stable Diffusionの歴史と進化
- Stable Diffusion 3の特徴
- Stable Diffusion 3.5シリーズの登場
- Stable Diffusion 3/3.5の導入方法
- Stable Diffusion 3/3.5の使い方とコツ
- Stable Diffusion 3/3.5の商用利用とライセンスについて
- 他の画像生成AIモデルとの比較
※Stable Diffusionの基本的な使い方については、下記記事で詳しく解説しています!

内容をまとめると…
Stable Diffusionは2022年の1.xから3.5まで進化し、各バージョン間でモデルやLoRAの互換性はない
SD3はMMDiT(Multimodal Diffusion Transformer)という新アーキテクチャを採用し、画像内テキスト表示の精度が他モデルを大きく上回る
SD3.5はLarge・Large Turbo・Mediumの3モデル構成で、年間収益100万ドル未満なら商用利用も無料
ローカル導入はComfyUIが最も安定しており、SD3.5 Mediumなら約10GBのVRAMで動作する
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Stable Diffusionの歴史と進化
Stable Diffusionは2022年8月に登場し、ソースコードの完全公開により画像生成AIの世界に革命をもたらしました。単なる画像生成ツールにとどまらず、テキストに基づいた高品質な画像生成の可能性を大きく広げたのです。
Stable Diffusionには、以下のようなバージョンがあります。
- Stable Diffusion 1.x (2022年8月〜):最初のメジャーリリースで、解像度512×512の画像生成
- Stable Diffusion 2.0/2.1 (2022年11月〜):解像度768×768に向上したが普及せず
- Stable Diffusion XL (2023年7月〜):解像度1024×1024、テキストエンコーダー2つ搭載で性能向上
- Stable Diffusion 3 (2024年2月〜):全く新しいアーキテクチャで高性能化
- Stable Diffusion 3.5 (2024年10月〜):SD3の改良版、カスタマイズ性と生成品質の両立
各バージョンは互換性がないため、モデルやLoRAなどのリソースは各バージョン専用に開発されたものを使う必要があります。特に注目すべきは、最新のStable Diffusion 3と3.5シリーズで、従来の拡散モデルから全く異なるアーキテクチャへと進化しています。
さらに、Stable Diffusionは、DALL-EやMidjourneyと並ぶ主要な画像生成AIの一つですが、オープンソースという特性から広範なカスタマイズが可能な点が特徴です。商用利用の自由度も高く、多くの企業やクリエイターに利用されています。
特に2022年からわずか2年の間に、生成画像の品質や精度が飛躍的に向上した点も注目のポイントです。初期のモデルで生成された画像と、最新のStable Diffusion 3.5やFlux.1で生成された画像を比較すると、その進化は一目瞭然です。


Stable Diffusion 3の特徴
Stable Diffusion 3は、2024年2月に発表された次世代モデルで、従来のバージョンとは大きく異なる技術を使用しています。その特徴を詳しく見ていきましょう!
特徴①:Multimodal Diffusion Transformer (MMDiT)アーキテクチャ
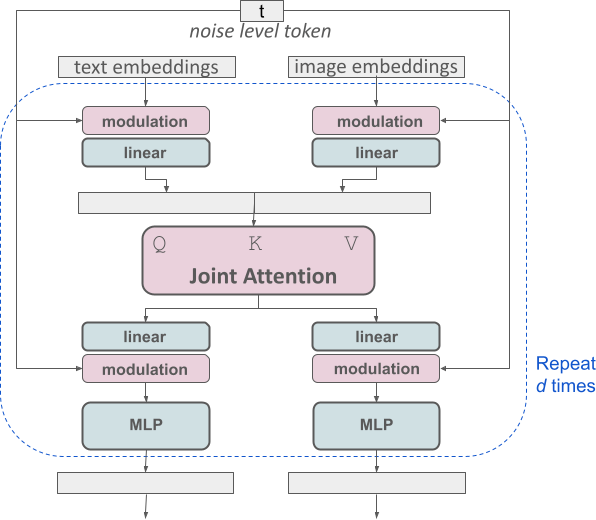
Stable Diffusion 3の最大の特徴は、Multimodal Diffusion Transformer (MMDiT)という全く新しいアーキテクチャを採用している点です。このアーキテクチャは、テキストと画像の2つのモダリティを扱うために設計されています。
具体的には、画像用とテキスト用の2つのTransformerが並列し、Attentionの部分で共通の情報を共有する構造になっています。さらに、入力されたプロンプト(テキスト)の処理には、CLIP-G/14、CLIP-L/14、T5 XXLという3つのモデルを使用してエンコードした結果を結合しています。
これにより、テキスト理解とスペリングの能力が大幅に向上し、特に画像内に文字を正確に表示するような難易度の高いタスクでも優れた性能を発揮します。
特徴②:Rectified Flow技術の導入
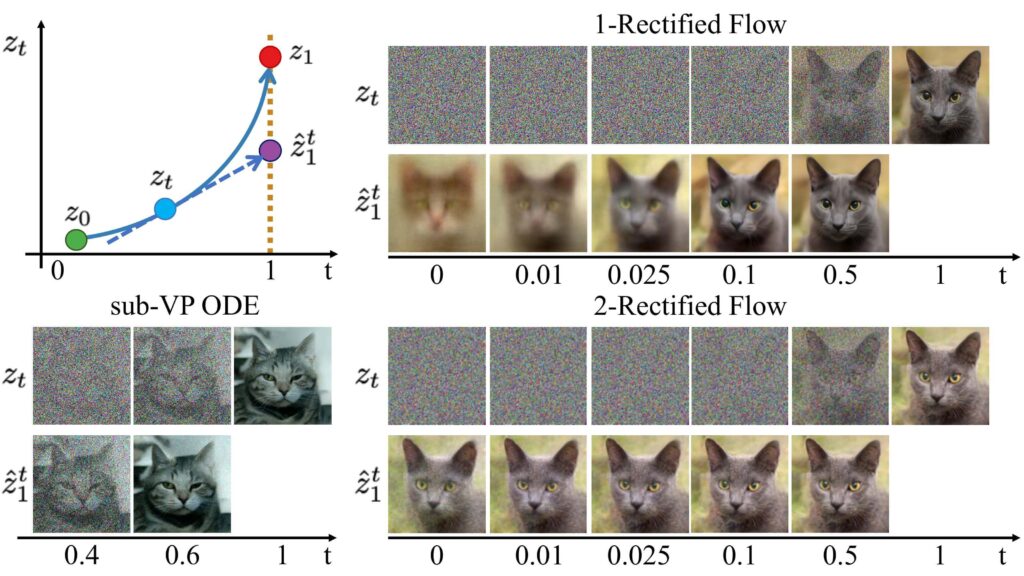
Stable Diffusion 3では、従来の拡散モデルとは異なる「Rectified Flow」というフロー・ベース生成モデルを採用しています。これは、データの分布と正規分布を線形に結びつけるシンプルなフローであり、効率的な画像生成を可能にしています。
この技術により、サンプリングステップ数を削減できるだけでなく、より直線的な推論パスを実現し、全体的な生成効率が向上しています。また、研究によると、モデルサイズや訓練ステップ数を増やすほど性能が向上する「スケーリング則」が確認されており、将来的な発展の余地を残しています。
特徴③:Stable Diffusion 3の性能評価

Stable Diffusion 3は、DALL-E 3やMidjourney v6などの競合モデルと比較しても、以下の点で優れた性能を発揮します。
- ビジュアルの美しさ: 生成される画像の美的品質が高い
- プロンプトへの忠実度: 指示したテキストの内容を正確に画像に反映
- テキスト表現: 画像内の文字を正確に表示する能力が特に優れている
特に、「画像内に特定のテキストを表示する」という課題において、Stable Diffusion 3は他のモデルを大きく上回る性能を示しており、この点が最大の強みと言えるでしょう。
Stable Diffusion 3のバリエーション
Stable Diffusion 3には、用途や必要なスペックに応じて選べる複数のバリエーションがあります。それぞれの特徴を詳しく見ていきましょう。
Stable Diffusion 3 Medium

Stable Diffusion 3 Mediumは、2024年6月に一般公開された最初のモデルで、パラメータ数は20億です。SDXL(26億パラメータ)より小さいサイズながら、性能は大幅に向上しています。
- パラメータ数:20億
- VRAM要件:約8GB(最低限の動作)、10GB(最適動作)
- 特徴:一般家庭のPCでも動作可能、商用利用には制限あり
- ライセンス:Stability AI Non-Commercial Research Community License
Stability AIは当初、このモデルについて「基準やコミュニティの期待を十分に満たすものではなかった」と評価し、フィードバックを元に改良を進めました。その結果が後述するStable Diffusion 3.5シリーズとなります。
Stable Diffusion 3 Large (8B)
Stable Diffusion 3 Largeは、パラメータ数80億の高性能モデルです。一般公開はされておらず、Stability AI社の公式サービス経由でのみ利用可能です。
- パラメータ数:80億
- VRAM要件:24GB以上
- 特徴:高品質な画像生成が可能、APIにて利用可能
- 利用方法:Stability AI API経由
このモデルは、NVIDIA RTX 4090クラスのGPUがあれば、ローカル環境でも動作可能とされていますが、公式からのモデル配布は行われていません。
Stable Diffusion 3 Ultra
Stable Diffusion 3 Ultraはさらに高性能なモデルで、詳細なパラメータ数は不明ながら、Largeを上回る性能を持つと考えられています。こちらも一般公開はされておらず、公式サービスでのみ利用可能です。
- パラメータ数:非公開(Largeより大きい)
- 特徴:最高品質の画像生成
- 利用方法:Stability AI API経由のみ
Stable Diffusion 3.5シリーズの登場
2024年10月22日、Stability AIは「Stable Diffusion 3.5」シリーズをリリースしました。これはSD3の改良版で、カスタマイズ性と生成品質のバランスを強化したモデルです。

Stable Diffusion 3.5では、以下の点が強化されています。
- カスタマイズ性: ユーザーのニーズに合わせた柔軟なモデル調整が可能
- 効率的なパフォーマンス: 一般的な消費者向けハードウェアでも高いパフォーマンス
- 多様な出力: 3D、写真、絵画、線画など幅広いスタイルの画像生成
- 多彩なスタイル: 特定の指示がなくても多様な出力が得られる
特に注目なのは、さきほどご紹介したMMDiTアーキテクチャの改良版「MMDiT-X」を採用している点です。これにより、テキストプロンプトへの準拠と画質において最高水準のパフォーマンスを維持しながら、より柔軟な画像生成が可能になりました。
Stable Diffusion 3.5の種類
Stable Diffusion 3.5には、以下の3つのモデルが用意されています。
| Stable Diffusion 3.5 Large | Stable Diffusion 3.5 Large Turbo | Stable Diffusion 3.5 Medium | |
|---|---|---|---|
| パラメータ数 | 80億 | 不明 | 26億 |
| 特徴 | 優れた品質と迅速な適合性、1メガピクセルの解像度に最適 | ・SD 3.5 Largeの蒸留版、わずか4ステップで高品質な画像生成 ・SD 3.5 Largeよりも高速 | MMDiT-Xアーキテクチャ採用、カスタマイズ性と画質の両立 |
| リリース日 | 2024年10月22日 | 2024年10月22日 | 2024年10月29日 |
これらのモデルはすべて、Stability AI Community Licenseの下で商用・非商用を問わず無料で利用可能となっています。
SD3とSD3.5の性能比較
Stability AIが公開した性能比較によると、Stable Diffusion 3.5シリーズは以下の点で優れています:
- プロンプト順守率: Fluxなど他の競合モデルよりも高い
- 美的クオリティ: これまでのStable Diffusionシリーズを上回る
- 生成速度と効率: 特にTurboモデルは高速
SD3.5は、SD3で指摘された問題点に対処し、より実用的なモデルとして設計されています。特に、「同じプロンプトでも、シードによって結果に大きなばらつきが生じる可能性がある」という特性は意図的なものであり、クリエイティブな用途に適していると言えるでしょう。
Stable Diffusion 3の導入方法
ここからは、Stable Diffusion 3をローカル環境で使用する方法を解説します!
ここでは主に一般公開されているStable Diffusion 3 Mediumの導入方法を説明します。
まず、準備としてStable Diffusion 3 Mediumをローカルで使用するには、以下のスペックが推奨されます。
- GPU: NVIDIA GPU、VRAM 8GB以上(10GB推奨)
- CPU: 特に制限はないが、高速なものが望ましい
- RAM: 16GB以上
- ストレージ: 少なくとも10GB以上の空き容量
VRAM 8GBでも最低限の動作は可能ですが、最適なパフォーマンスを得るには10GB以上のVRAMを搭載したGPUが推奨されます。
ComfyUIを使った導入方法
現時点(2026年1月)では、Stable Diffusion 3をローカルで使用するには、ComfyUIが最も安定した選択肢となっています。
ComfyUIでStable Diffusion 3 Mediumを導入する手順は、以下の通りです。
- ComfyUIをダウンロードしてインストール
- 公式GitHubから直接ダウンロード可能
- モデルファイルをダウンロード
sd3_medium.safetensorsをComfyUIのmodels/checkpointsフォルダに配置sd3_medium_incl_clips_t5xxlfp8.safetensorsをComfyUIのmodels/CLIPフォルダに配置
- ComfyUIを起動し、ワークフローをロード
- ワークフローファイルを使用すると簡単
- 画像生成設定
- サンプラーをEulerに設定
- 出力解像度を1024×1024に設定
- CFG Scaleを5に設定
これらの設定でComfyUIを起動すると、Stable Diffusion 3 Mediumを利用した画像生成が可能になります。
※ComfyUIの詳しい使い方については、下記記事を参考にしてください!

WebUIでの導入方法
AUTOMATIC1111のWebUIでStable Diffusion 3を使用するための対応は今のところ進行中であるそうです。2024年7月にリリースされたWebUI v1.10.0では、SD3の初期サポートが追加されました。
WebUIでSD3を使用する手順は、以下の通りです。
- 最新版のWebUI(v1.10.0以降)をインストール
- SD3のモデルファイルをダウンロードし、適切なフォルダに配置
- WebUI起動時に
--no-half-vaeオプションを追加して起動
ただし、現時点ではComfyUIに比べて機能制限や不安定さがあるため、本格的な利用にはComfyUIがおすすめです。WebUIの対応状況は今後のアップデートで改善される見込みです。
APIを使った利用方法
ローカル環境を構築せずに、API経由でStable Diffusion 3を利用することも可能です。
Stability AI APIを使った基本的な使用方法は以下の通りです。
- Stability AIのアカウントを作成し、APIキーを取得
- こちらから作成できます:https://platform.stability.ai/account/keys
- APIリクエストのサンプルコードを実行する
import requests
response = requests.post(
f"https://api.stability.ai/v2beta/stable-image/generate/sd3",
headers={
"authorization": f"Bearer YOUR_API_KEY",
"accept": "image/*"
},
files={"none": ''},
data={
"prompt": "A bustling urban street scene with skyscrapers",
"output_format": "jpeg",
},
params = {
"model" : "sd3.5-large" # モデルを指定
}
)
if response.status_code == 200:
with open("./generated_image.jpeg", 'wb') as file:
file.write(response.content)
else:
raise Exception(str(response.json()))APIを使用する場合、クレジットの購入が必要です。Stable Diffusion 3は1回の画像生成ごとに6.5クレジット、SD3 Turboは1回4クレジットかかります(10ドルで1000クレジット購入可能)。
Stable Diffusion 3.5の環境導入
Stable Diffusion 3.5も基本的にはSD3と同様の方法でローカル環境に導入できますが、必要なスペックや対応状況が若干異なります。
Stable Diffusion 3.5 Mediumのローカル導入方法
Stable Diffusion 3.5 Mediumは、一般的なGPUでも動作するように設計されています。
- VRAM要件:約10GB
- 導入方法:先ほどご紹介したComfyUIと同様の手順
Stable Diffusion 3.5 LargeとLarge Turboのローカル導入方法
Stable Diffusion 3.5 LargeとLarge Turboは、高性能なGPUが必要です。
- VRAM要件:24GB以上
- 必要なGPU:NVIDIA RTX 4090クラス以上が推奨
この高性能モデルは、一般的な家庭用PCではなく、難易度の高いプロの方が使用することを想定しているため、相応のハードウェア環境が求められます。
Stable Diffusion 3/3.5の使い方とコツ
続いては、Stable Diffusion 3/3.5を効果的に使うためのコツや、プロンプトの書き方について解説します。
効果的なプロンプトの書き方
Stable Diffusion 3/3.5では、プロンプトの書き方が画像生成の品質に大きく影響します。
効果的なプロンプトの構成要素はを6つほどご紹介します!
- スタイル: 生成したい画像の全体的な雰囲気やアートスタイルを指定
例:「油絵風」「サイバーパンク」「水彩画」 - 主題と動作: 画像の主題とその動作を明確に指定
例:「海辺を歩く女性」「空を飛ぶドラゴン」 - 構図とフレーミング: 画像内の配置やカメラアングルを指定
例:「クローズアップ」「広角ビュー」「鳥瞰図」 - 照明と色彩: 画像の照明条件や色調を指定
例:「柔らかな自然光」「ネオンライト」「モノクローム」 - 技術的パラメータ: 映画用語などを使って視点やフレーミングを指示
例:「鳥瞰図」「魚眼レンズ」「クレーンショット」 - テキスト: 画像内に表示したいテキストの内容や配置を指定
これらの要素を組み合わせることで、より意図に沿った画像を生成できます。
※その他プロンプトのコツについては、下記記事で詳しく解説しています!

ネガティブプロンプトの活用
ネガティブプロンプトは、生成したくない要素や避けたいスタイルを指定するものです。これを活用することで、より洗練された画像を生成できます。
- 不要な特徴の排除: 「smooth, neon, 3D render」など、避けたい表現を指定
- 画質の向上: 「low quality, blurry, bad anatomy」など、品質を下げる要素を排除
- コンセプトの調整: 特定のテーマやスタイルを排除することで、意図した方向性に導く
※ネガティブプロンプトについては、下記記事で詳しく解説しています!

Stable Diffusion 3/3.5の商用利用とライセンスについて

Stable Diffusion 3/3.5の商用利用については、商用利用に関する理解が不可欠ですので、必ずチェックしておきましょう!
Stability AI Community Licenseについて
Stable Diffusion 3.5はStability AI Community Licenseの下で公開されており、以下の条件で利用できます。
- 非営利目的の利用は無制限に可能
- 営利目的でも年間収益100万ドル未満であれば無料で利用可能
- より高額な商用利用の場合はEnterprise Licenseが必要
加えて重要なのは、モデル自体のライセンスと、生成された画像のライセンスは異なるという点です。
- モデル: Stability AI Community Licenseの下で配布
- 生成画像: 基本的に生成した利用者に著作権が帰属し、自由に使用可能
ただし、他者の著作物を明確に模倣するような利用は避けるべきです。また、各国の法令に従った利用が求められます。
Creator LicenseとEnterprise Licenseについて
先ほど紹介した「Stability AI Community License」より高額な商用利用のために、Stability AIは以下のライセンスを提供しています。
- Creator License:小規模の生成サービス提供者向け
- 収益100万ドル未満、資金提供100万ドル未満、月間アクティブユーザー100万人未満が対象
- 月6000枚程度の画像生成を想定
- Enterprise License:大規模な商用利用向け
- 無制限の商用利用が可能
※Stable Diffusionの商用利用についてさらに詳しく知りたい方は、下記記事を参考にしてください!

他の画像生成AIモデルとの比較
ここからは、皆さんが気になるであろうStable Diffusion 3/3.5と他の主要な画像生成AIモデルを比較してみました!
①DALL-E 3との比較

DALL-E 3とStable Diffusion 3.5の主な違いは以下の通りです。
- テキスト表現: SD3/3.5は画像内の文字表示に優れている
- オープン性: SD3.5はより高いカスタマイズ性を提供
- 料金: 同程度の画質なら、SD3.5 Turboの方がやや安価
ビジュアルの美しさやプロンプトへの忠実度では、両者は同等レベルと言えます。
②Midjourney v6との比較

Midjourney v6との比較ポイントは、以下の通りです。
- 使いやすさ: Midjourneyはディスコードを通じた簡単な操作性
- カスタマイズ性: SD3.5の方が高いカスタマイズ性
- テキスト表現: SD3.5が明確に優位
- 価格: Midjourneyはサブスクリプションモデル、SD3.5はAPIの従量課金
※Midjourney v6については、下記記事で詳しく解説しています。

③Fluxとの比較

元Stable Diffusion開発者が立ち上げたBlack Forest Labsによる「Flux」との比較は、以下の通りです。
- パラメータ数: Fluxは120億と大きい
- プロンプト順守率: SD3.5 Largeの方が高い傾向
- オープン性: 両者ともにオープンソースモデルを提供
- ライセンス: 類似しているが、細部に違いあり
Fluxは次世代画像生成AIの本命との評価もあり、今後の発展が注目されています。
まとめ
いかがでしたでしょうか?
Stable Diffusionの各バージョンの特徴や違い、そして最新のSD3、SD3.5シリーズの革新性について詳しく解説しました!
この記事で紹介したことをまとめると次のようになります。
- Stable Diffusionは2022年から急速に進化し、SD3/3.5で画期的なMMDiTアーキテクチャを採用
- SD3.5は3つのバリエーション(Large、Large Turbo、Medium)があり、用途に応じて選べる
- ローカル環境ではComfyUIが安定して動作し、AUTOMATIC1111のWebUIも対応進行中
- プロンプトはスタイル、主題、構図、照明などの要素を組み合わせることで高品質な生成が可能
- 商用利用は一定条件内で可能だが、ライセンスの理解が必要
画像生成AIに興味を持ちながらも「どのバージョンを使えばいいの?」「導入方法がわからない」と悩んでいた方にとって、参考になる情報だったのではないでしょうか?
ぜひ、最新のStable Diffusion 3/3.5シリーズを使ってみてくださいね!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

