
最近、AIによる画像生成が急速に進化し、多くの人がStable Diffusionを使い始めています。
しかし、Stable DiffusionのWebUIには様々な種類があり、どれを選べばいいのか迷ってしまうこともあるでしょう。
特に「Stable Diffusion reForge」と「Stable Diffusion Forge」の違いがわからないという声をよく聞きます。
この記事では、それらの違い、インストール方法から実際の使い方まで、詳しく解説していきます。
低スペックPCでも快適に使いたい方や、拡張機能をたくさん使いたい方に特におすすめです!
- Stable Diffusion reForgeとは?Forgeとの違い
- Stable Diffusion reForgeのインストール方法
- Stable Diffusion reForgeの使い方
※Stable Diffusionの基本的な使い方については、下記記事で詳しく解説しています。

内容をまとめると…
reForgeはA1111とForgeの良いところを組み合わせたWebUIで、拡張機能の互換性と低VRAM環境での動作を両立している
Forgeが実験的機能を優先して互換性を犠牲にする中で派生したバージョンで、A1111からの移行がしやすいUI設計
インストールはGitHubクローン・Stability Matrix・EasyReforgeの3通りがあり、Python 3.10.6が最も安定
A1111・Forge・reForgeの3種のWebUIは目的や環境で使い分けるのがベストで、拡張機能重視ならreForgeが有力
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Stable Diffusion reForgeとは?Forgeとの違い
早速、Stable Diffusion reForgeとはどんなものなのか?
Forgeとの違いについて解説していきます!
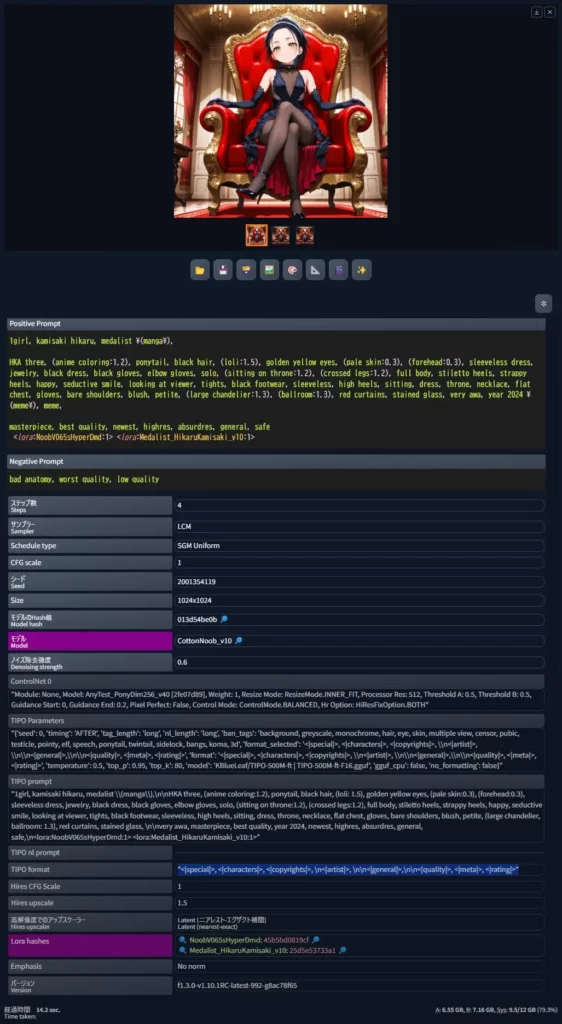
reForgeとは?
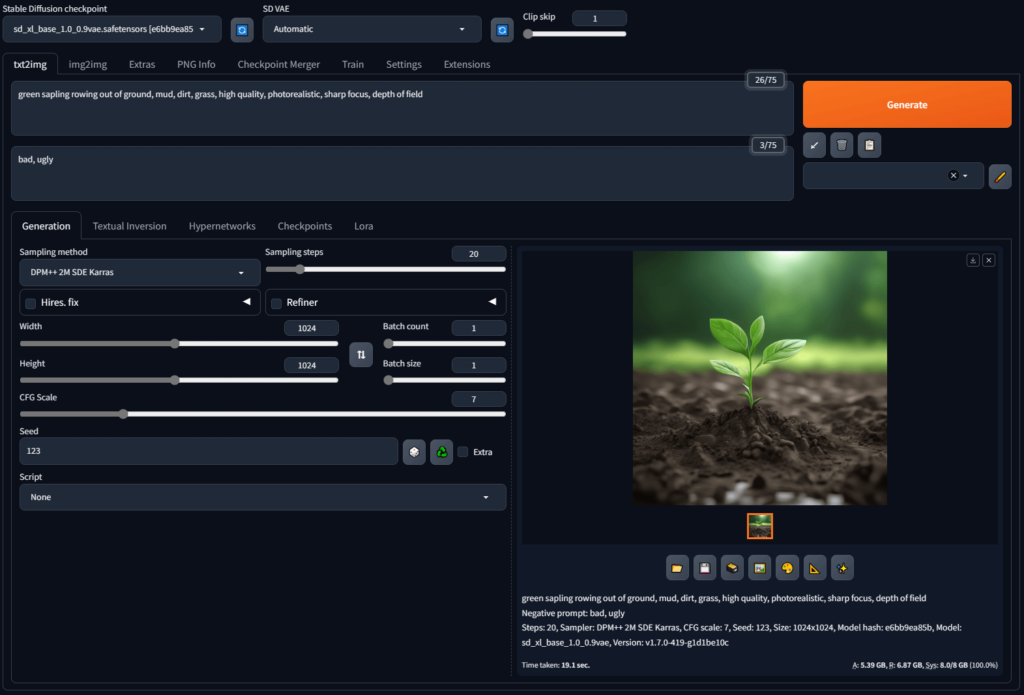
Stable Diffusion WebUI reForge (以下、reForge)は、オリジナルのStable Diffusion WebUI(通称A1111)とForgeの良いところを組み合わせたWebUIです。
特に、拡張機能の互換性や安定性を重視して開発されています。
reForgeは、Forgeがより実験的な機能の追加を進めるために互換性を犠牲にする中で派生したバージョンです。
「低VRAM環境でも画像を生成したい」「拡張機能を多く使いたい」というユーザーに特に人気があります。
reForgeとForgeの主な違い
reForgeとForgeの主な違いは以下の4点です。
- 性能
- Forgeは元々のA1111に比べて高速化されており、推論速度が大幅に向上しています。
- reForgeはさらに最適化されており、低スペックGPUでも高品質な画像生成が可能
- VRAMの効率的な利用を実現し、生成速度やVRAM消費面で優れた結果を示す
- 機能・拡張性
- reForgeは拡張機能のサポートが強化されており、様々な機能を追加できる柔軟性がある
- Forgeは基本的な機能に焦点を当てており、拡張性は限られている
- reForgeでは特定の条件下でForgeよりも速いパフォーマンスを発揮することが報告されている
- ユーザーインターフェース
- Forge:Gradio 4.x UI を採用しており、新しいデザインや操作感が特徴です。
- reForge:従来のUIに近く、A1111から移行するユーザーが馴染みやすい設計になっています。
- 更新とサポート
- Forge:現在も活発に開発が続けられています。
- reForge:2024年後半に更新が停滞しましたが、2025年3月にブランチ説明が更新され、開発が継続していることが示されました。
これらの違いからわかるように、reForgeは特に拡張機能やA1111との互換性を重視する方に適しています。
reForgeのバージョンについて
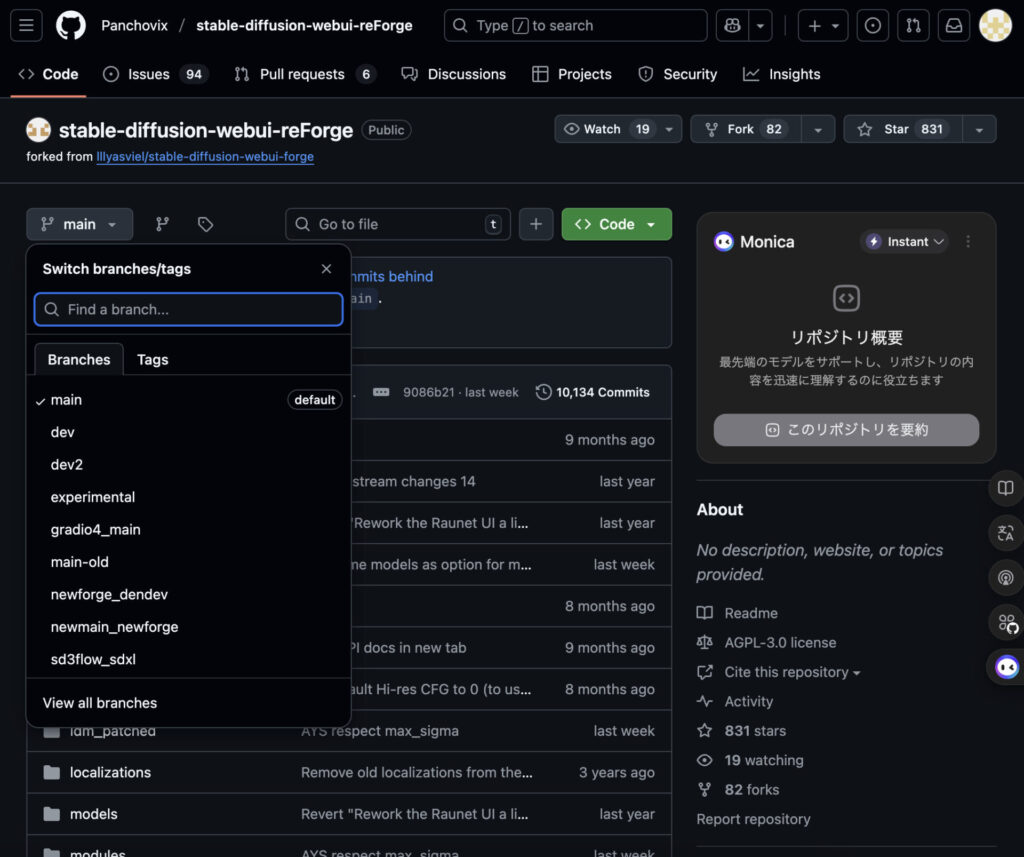
※ 以前存在していた「dev_upstream」「dev_upstream_experimental」などのブランチは、
現在は名称変更や廃止が行われており、最新のリポジトリには表示されません。
reForgeには主に以下のバージョンがあります。
- main:現行の安定ブランチ。基本的にこのブランチを利用すれば問題ありません。
- dev/ dev2:新機能をテストするためのブランチ。将来的に main に統合される予定があります。
- experimental:実験的な変更を含むブランチ。動作が不安定になる可能性があります。
- main-old/newforge系:現在は Deprecated(非推奨)のため、新規利用は避けた方が安全です。
新規で使う場合は main または dev 系ブランチを選ぶのがおすすめです。
- Qブランチとは?
- A
GitHubには「同じソフトの別バージョン」を同時に置いておける仕組みがあります。
それを「ブランチ」と呼びます。
- QGitHubとは?
- A
プログラムやソフトのファイルを置いて、みんなで共有・管理できるサービスです。
開発者が作った最新のソフトを公開したり、利用者がダウンロードしたりできます。この記事で紹介している内容も、GitHubで配布されています。
だから GitHub からダウンロード(クローン)して、自分のPCに入れる手順が必要になります。
Stable Diffusionの種類と違い
Stable DiffusionのWebUIについても解説します!大きく分けて3種類があるんです。
- Stable Diffusion WebUI (A1111)

- オリジナルのStable Diffusion WebUI
- 最新機能への追従はやや遅い
- 豊富な拡張機能が多数利用可能
- 拡張機能の相性問題も少なく、動作も安定
- Stable Diffusion WebUI Forge

- 新機能や実験的機能が実装されているWebUI
- FLUX.1のモデルやStable Diffusion 3/3.5のモデルを利用可能
- 利用できない拡張機能があったり、一部の拡張機能では相性が合わずうまく動作しない場合も
- 詳しい使い方については、こちらの記事で解説しています
- Stable Diffusion WebUI reForge

- V-Predictionモデルへの対応や高速化などの新機能が早いタイミングで追加
- Forge版と異なり、Stable Diffusionでの利用をメインにしたUI
- 拡張機能はA1111と互換性があり、多くの機能をそのまま利用可能です。
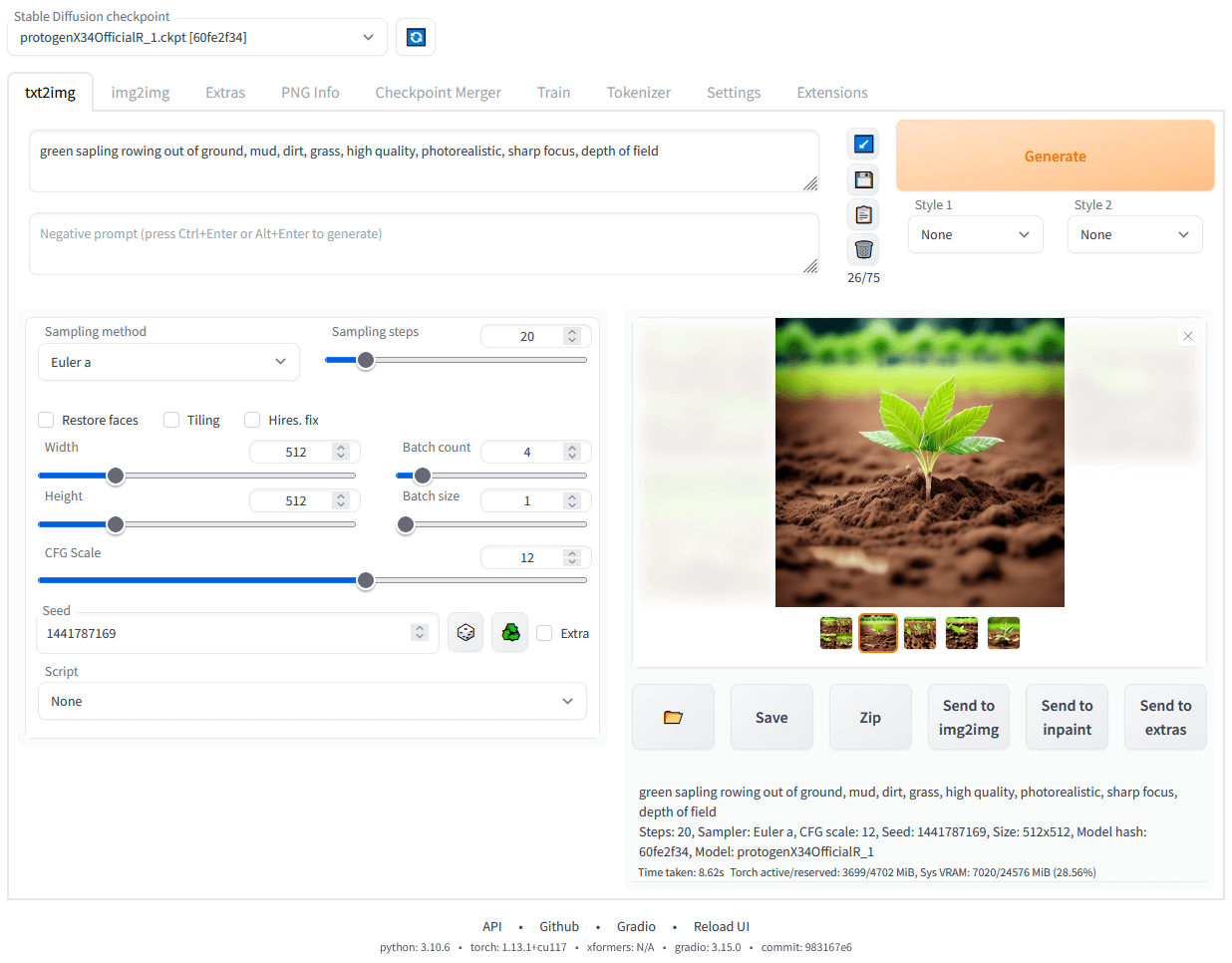
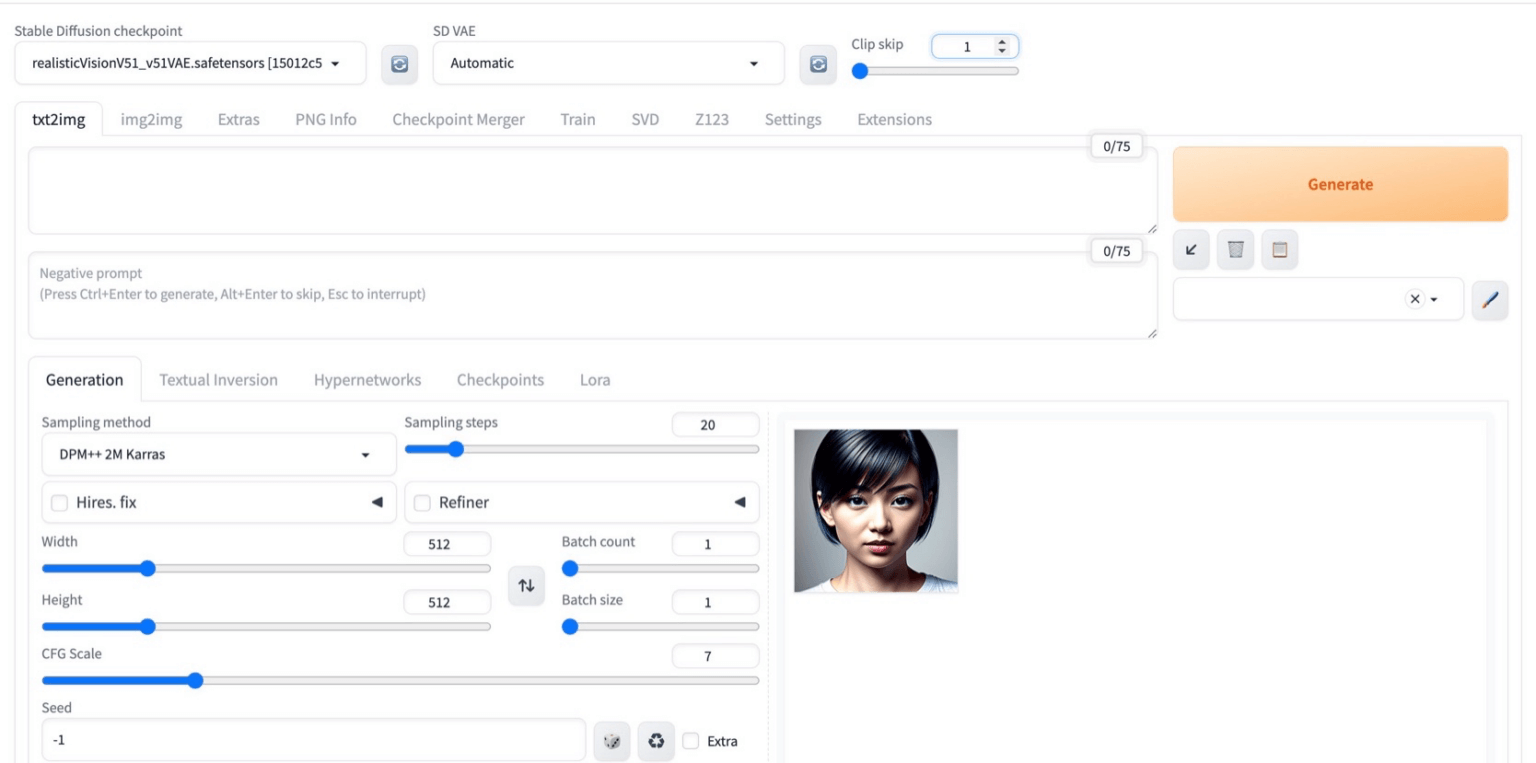
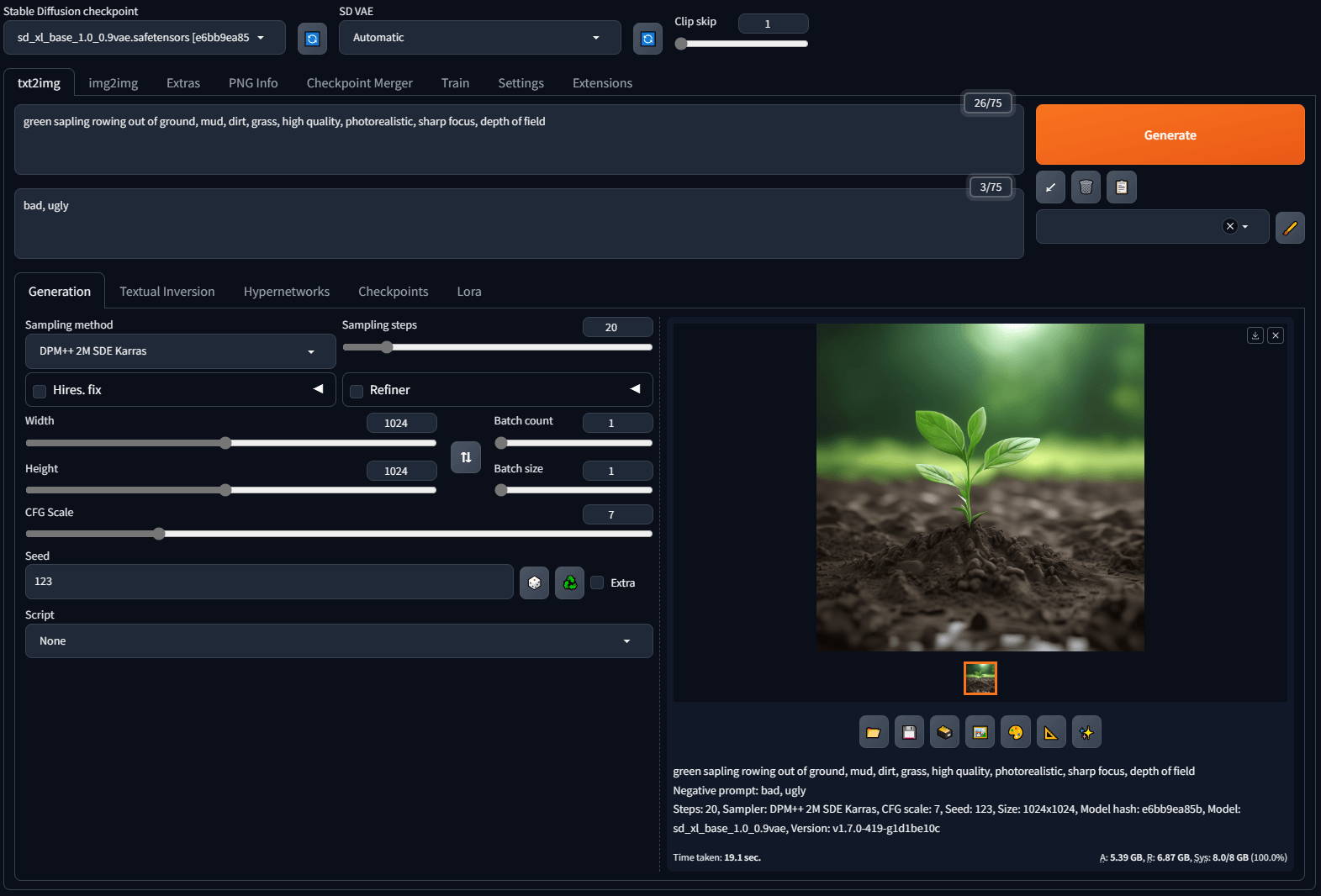
それぞれのWebUIは、目的や環境によって使い分けるのがおすすめです!
Stable Diffusion reForgeのインストール方法
reForgeをインストールする方法はいくつかありますが、ここでは主に3種類の方法を紹介します。
①GitHubからのクローン(mainブランチを利用したインストール方法)
最も一般的な方法はGitHubからのクローンです。
以下の手順で実行してください!
- GitとPythonをインストール(Python 3.10.xx~3.12.xxのバージョンで動作)
- コマンドプロンプトで以下のコマンドを実行
git clone https://github.com/Panchovix/stable-diffusion-webui-reForge.git cd stable-diffusion-webui-reForge
- mainブランチに切り替える場合は以下のコマンドを実行
git checkout main
- webui-user.batを編集(必要に応じて)
- webui-user.batを実行してセットアップを開始
※ 公式リポジトリの README には以下のように記載されています。 Python (Python 3.7 up to 3.12 works fine, 3.13 still has some issues) つまり Python 3.7〜3.12 は動作確認済みで、3.13 は不具合の可能性があります。 実際の利用では 3.10.x 系(特に 3.10.6)が安定しているとの報告が多く、推奨されます。
②Stability Matrixを使ったインストール方法
Stability Matrixを使うとワンクリックで簡単にインストールできます。
- Stability Matrixをダウンロードしてインストール
- Stability Matrixを起動し、「+ パッケージの追加」からreForgeを選択
- インストールボタンをクリックするだけで自動的にセットアップが完了
※詳しい使い方については、下記記事を参考にしてください!

③EasyReforgeを使ったインストール方法
日本語解説付きのワンクリックインストーラー「EasyReforge」も利用可能です。
- EasyReforgeをダウンロード
- インストーラーを実行するだけで日本語環境のreForgeが簡単にセットアップ可能
PyTorch 2.4での高速化する方法(上級者向け)
より高速化したい上級者向けに、PyTorch 2.4でのインストール方法も紹介します。
# PyTorchの再インストール
!pip uninstall -y torch torchvision torchaudio
!pip install torch==2.4.0+cu124 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124
# 必要なCUDAライブラリのリンクを作成
!sudo ln -s /usr/local/cuda/lib64/libcudart.so /usr/local/cuda/lib64/libcudart.so.11.0
!sudo ln -s /usr/local/cuda/lib64/libcudart.so /usr/local/cuda/lib64/libcudart.so.12.0
# 環境変数の設定
!echo 'export BNB_CUDA_VERSION=124' >> ~/.bashrc
!echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64' >> ~/.bashrc
!source ~/.bashrc
# bitsandbytesの再インストール
!pip uninstall -y bitsandbytes
!pip install bitsandbytesこのセットアップにより、最新のPyTorch 2.4とCUDA 12.4を使った高速な環境が構築できます!
Stable Diffusion reForgeの使い方
それでは、Stable Diffusion reForgeの使い方をご紹介していきます!
基本的な使い方
reForgeのインストールが完了すると、ブラウザでUIにアクセスできるようになります。(通常はhttp://127.0.0.1:7860/)

- モデルの選択
- 「Stable Diffusion checkpoint」からモデルを選択
- 必要に応じてVAEも選択
- プロンプト入力
- 上部のテキストエリアにプロンプト(生成したい画像の説明)を入力
- 下部のテキストエリアにネガティブプロンプト(避けたい要素)を入力
- 生成設定の調整
- サンプリング方法:リアル系画像は”DPM++ SDE Karras”、アニメ系イラストは”DPM++ 2M Karras”がおすすめ
- CFG Scale:7.0前後が一般的(値が低いほど創造的、高いほどプロンプトに忠実)
- ステップ数:20~30が一般的(値が高いほど品質が上がるが生成時間も増加)
- 生成実行
- 「Generate」ボタンをクリックして画像を生成
以前のdev_upstream版の追加機能
以前のdev_upstream版では、以下のような追加機能が利用できました。
なお、公式の更新記録では「dev_upstreamブランチはDeprecatedとなり、mainに統合された」とのみ案内されています。
どの機能がmainやdevに残っているかの詳細なリストは公開されていません。
- サンプラーとスケジューラーの追加
- 「Gradient estimation」などの新しいサンプラー
- 様々なスケジューラーの追加と詳細設定が可能
- MaHiRo CFG
- ビルトイン拡張機能として追加された新しいCFG方式
- 通常のCFGより2低い値で設定するとよい結果が得られる
- Torch Compile機能
--torch-compileを起動オプションに追加することで使用可能- 生成速度がわずかに向上(10.7秒→10.0秒程度)
- ベータスケジューラーの詳細設定
- αとβの値を細かく調整可能
- 「設定」タブの「Scheduler parameters」で変更できる
※Stable Diffusionのサンプラーなどについては、下記記事で詳しく解説しています!

reForgeへの拡張機能の追加方法
reForgeの大きな特徴の一つは、A1111向けの拡張機能の互換性です。
以下の手順で拡張機能を追加できます。
- 「Extensions」タブを選択
- 「Available」をクリック
- 検索ボックスに追加したい拡張機能の名前を入力
- 「Install」ボタンをクリックしてインストール
- インストール完了後、「Apply and restart UI」をクリック
人気の拡張機能には以下のようなものがあります。(リンク先に解説記事があります!)
- ControlNet:参照画像からポーズや構図を制御
- Regional Prompter:画像の特定領域にプロンプトを適用
- ADetailer:人物の顔などを自動検出して修正
- Deforum:アニメーションやビデオ生成
reForgeの日本語化
reForgeのインターフェースを日本語化する方法も簡単です。
- 「Extensions」タブ→「Available」をクリック
- 「localization」のチェックを外してから「Load from:」ボタンを押す
- 検索ボックスに「ja_JP」と入力
- 「ja_JP Localization」の「Install」ボタンをクリック
- 「Settings」タブで「Localization」を検索
- 更新ボタンを押して言語選択リストを更新し、「ja_JP」を選択
- 「Apply settings」をクリックして設定を適用
- 「Reload UI」で画面を再読み込み

v-predictionモデルの使用方法
2024年後半から注目されている「v-predictionモデル」(特にnoobai)をreForgeで使用する方法を紹介します。
v-predモデルは従来のEpsilon-Predictionモデルと比較して、背景がより正確に、色も正確に出力されるという特徴があります。
v-predモデルの設定方法
①v-pred対応モデル(例:noobai v-pred)をダウンロード
②モデルを「models/Stable-diffusion」フォルダに配置
③WebUIで「Stable Diffusion checkpoint」の更新ボタンを押し、v-predモデルを選択
④プロンプトを入力し、解像度を設定(困ったら1024×1024)
⑤sampling methodを「Euler a」に設定
⑥Schedule typeを「Simple」に設定
⑦「Advanced Model Sampling for reForge」でv-predの設定を有効化
⑧「Generate」ボタンをクリックして生成
v-predモデルを使うことで、従来のモデルでは難しかった高品質な画像生成が可能になります。特にリアルな写真のような画像生成に優れています。
Stable Diffusion reForgeのAPI活用
reForgeはAPIを提供しており、外部スクリプトからの制御も可能です。
以下は簡単なPythonスクリプトの例です。
import requests
import json
import os
import io
import base64
from pydantic import BaseModel, Field
from PIL import Image, PngImagePlugin
from datetime import datetime, timezone, timedelta
# 日本標準時
JST = timezone(timedelta(hours=9))
# APIエンドポイント
SD_SERVER_URL = "http://127.0.0.1:7860" # LAN内のサーバーURLに変更してください
# 入力データを管理するクラス
class ImageGenerationParams(BaseModel):
prompt: str = Field(..., example="1girl", description="生成したい画像のプロンプト")
negative_prompt: str = Field(
"worst quality", example="worst quality", description="否定プロンプト"
)
steps: int = Field(25, example=25, description="生成ステップ数")
cfg_scale: float = Field(7.0, example=7.0, description="CFGスケールの値")
width: int = Field(512, example=512, description="生成画像の幅")
height: int = Field(512, example=512, description="生成画像の高さ")
sampler_index: str = Field(
"Euler a", example="Euler a", description="サンプラーの種類"
)
batch_count: int = Field(1, example=1, description="バッチ生成の数")
batch_size: int = Field(1, example=1, description="1バッチあたりの画像数")
enable_hr: bool = Field(
False, description="高解像度リサイズモードを有効にするかどうか"
)
denoising_strength: float = Field(
0.4, example=0.4, description="高解像度リサイズ時のノイズ低減強度"
)
hr_scale: float = Field(1.5, example=1.5, description="高解像度リサイズのスケール")
hr_steps: int = Field(
15, example=15, description="高解像度リサイズ時の追加ステップ数"
)
hr_upscaler: str = Field(
"R-ESRGAN 4x+ Anime6B", example="R-ESRGAN 4x+ Anime6B", description="高解像度リサイズのアップスケーラー"
)
def text_to_image(params: ImageGenerationParams, output_dir: str, unique_id: str):
"""
Stable Diffusion API (txt2img) を使用して画像を生成し、PNGとして保存する。
Args:
params: ImageGenerationParamsオブジェクト(画像生成パラメータを含む)
output_dir: 出力先ディレクトリ
unique_id: ファイル名に使用する一意の識別子
"""
# APIへのリクエストペイロード
payload = {
"prompt": params.prompt,
"negative_prompt": params.negative_prompt,
"steps": params.steps,
"cfg_scale": params.cfg_scale,
"width": params.width,
"height": params.height,
"sampler_index": params.sampler_index,
"batch_count": params.batch_count,
"batch_size": params.batch_size,
"enable_hr": params.enable_hr,
"denoising_strength": params.denoising_strength,
"hr_scale": params.hr_scale,
"hr_upscaler": params.hr_upscaler,
"hr_second_pass_steps": params.hr_steps,
}
headers = {"Content-type": "application/json"}
url = f"{SD_SERVER_URL}/sdapi/v1/txt2img"
# APIリクエスト送信
response = requests.post(url, json=payload, headers=headers, timeout=300)
response.raise_for_status()
# レスポンス処理
result = response.json()
meta = json.loads(result["info"])["infotexts"][0]
# 出力ディレクトリの作成
os.makedirs(output_dir, exist_ok=True)
# 画像の保存
for i, image_data in enumerate(result["images"]):
image = Image.open(io.BytesIO(base64.b64decode(image_data.split(",", 1)[0])))
pnginfo = PngImagePlugin.PngInfo()
pnginfo.add_text("parameters", meta)
now = datetime.now(JST).strftime("%Y%m%d%H%M%S")
file_path = os.path.join(output_dir, f"{now}_{unique_id}_{i+1}.png")
print(f"Saving image to {file_path}")
image.save(file_path, pnginfo=pnginfo)このスクリプトを使うことで、バッチ処理や自動化が可能になります。
※ APIのエンドポイントや利用方法は reForge の公式READMEで最新情報を確認してください。
Deforumの活用方法
Deforumは動画生成のための強力な拡張機能で、reForgeでも利用可能です。
以下の手順でインストールできます。
%cd /path/to/stable-diffusion-webui-reForge/extensions
!git clone --branch main https://github.com/deforum-art/sd-forge-deforum.gitDeforumを使用するには、以下の追加パッケージが必要です(特に3Dモードでdepth zoeを使用する場合)
!pip install timm==0.6.7
!pip uninstall -y opencv-python
!pip uninstall -y opencv-python-headless
!pip install opencv-python==4.9.0.80
!pip install opencv-python-headless==4.9.0.80Deforumを使えば、アニメーションやビデオ生成が可能になり、創作の幅が大きく広がります。
※Stable DiffusionでDeforumを使う方法は、以下の通りです。

まとめ
いかがでしたでしょうか?
Stable Diffusion reForgeについての特徴やForgeとの違い、インストール方法から実際の使い方まで詳しくご紹介しました。
この記事で紹介したことをまとめると次のようになります。
- reForgeはA1111の互換性とForgeのパフォーマンスを兼ね備えたWebUI
- Forgeと比較して拡張機能の互換性が高く、特にRegional PromperやControlNetなどが使える
- 低スペックPCでも高速に動作し、VRAMの効率的な利用ができる
- 最新のブランチ(main / dev)では、サンプラーやTorch Compileなどの追加機能が統合されており、引き続き利用可能
- v-predモデル(noobaiなど)に対応しており、高品質な画像生成が可能
Stable Diffusionの各WebUIの特徴を理解し、自分の目的に合ったものを選ぶことで、より快適なAI画像生成環境が構築できるはずです。
特に拡張機能を多用したい方や、低スペックPCでも快適に使いたい方にはreForgeがおすすめですよ。
ぜひ、この記事を参考にreForgeを試してみて、あなた好みのAI画像生成を楽しんでください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

