
Midjourneyで「3人のアイドルを並べたい」「友だちグループの写真っぽい一枚を作りたい」
と思っても、人数を増やした瞬間に顔や体が崩れたり、なぜか一人だけ大きくなってしまったりして、「複数人ってむずかしい…」と感じていないでしょうか。
何度もプロンプトを直しているうちに、どこをどう工夫すればいいのか分からなくなってしまいますよね。
実は、画像生成AIはもともと、1枚の中で複数の人物をきちんと描き分けるのが得意ではありません。
ただ、最近のMidjourneyには、複数人をコントロールしやすくする機能が増えてきており、コツさえ押さえればかなり安定して複数人シーンを作れるようになっています。
この記事では、そうした機能を組み合わせて複数人を生成する具体的な手順と、失敗しにくいプロンプトの考え方、すぐにマネできる例文までまとめて紹介します。
まずは3人構図から、理想に近いグループイラストや写真風画像を一緒に作っていきましょう。
内容をまとめると…
Midjourneyは複数人が苦手なので前提を理解して対策する
パン機能で1人ずつ追加しながら、構図と人数を段階的に決めていく
Region Varyを使えば、あとから特定のキャラだけ自然に差し替えられる
複数人プロンプトは「人数の宣言+キャラごとの特徴+共通シーン」を分けて書くと安定しやすい
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。


Midjourneyが複数人生成を苦手とする理由

複数人を一枚に描こうとすると、急にクオリティが不安定になる——これはMidjourneyに限らず、多くの画像生成AIに共通する弱点です。
2025年にデフォルトとなったV7では、プロンプトの解釈精度や身体・手・オブジェクトの描写が大きく改善され、以前のバージョンよりも複数人シーンの安定感は確実に上がっています。それでも「3人並べたら1人だけ顔が崩れた」「指定した髪色が別のキャラに移った」といったトラブルは日常的に起こります。
なぜ完全には解決しないのか、その構造的な理由を押さえておくと、後で紹介するパン機能やOmni Reference、Region Varyを使うときに「どこを補強すればいいか」が判断しやすくなります。
特徴の割り当てがあいまいになる
「赤い髪の女の子」「黒い服の女の子」と条件を並べても、どの特徴をどの人物に振り分けるかをAIが正しく判断できないことが多いです。V7ではプロンプト理解力が向上し、長く複雑な指示にも対応しやすくなりましたが、同性・同体型のキャラを並べた場合は依然として特徴が混ざりやすい傾向があります。
一枚の中の情報量が多くなりすぎる
人数が増えるほど、位置関係・大きさ・ポーズ・視線など同時に処理すべき要素が一気に増え、破綻しやすくなります。V7は身体や手の整合性が大幅に改善されたとはいえ、4人以上のシーンではまだ不安定になりがちです。
学習データが「一人ドーン構図」に偏っている
AIが学習している写真やイラストは、中央に一人が大きく写っているものが圧倒的に多いため、「一人だけ目立つレイアウト」をAIが選びやすい傾向があります。これはV7でも根本的には変わっておらず、group photoやensembleといった構図キーワードを意識的に使わないと、一人にフォーカスした構図に引っ張られます。
似たキャラ同士がまとめられてしまう
髪色や服装が似ている人物を複数並べると、「別人として描き分ける」より「一人分としてまとめてしまう」方に寄りがちです。男女混合や、人間と非人間(エルフ・ロボットなど)のように見た目のコントラストが大きいキャラ同士のほうが、AIは描き分けやすくなります。
細かく盛ったプロンプトが逆効果になりやすい
多人数分の条件を一度に詰め込みすぎると、AIは優先度の低い情報から無視していくため、意図していない髪色や服装に置き換わることがあります。V7はプロンプトへの忠実度が上がった分、矛盾する指示にも敏感になっており、情報過多による予期しない結果が出やすい場面もあります。
V7でも解消しきれない「参照画像の制約」
V7で導入されたOmni Reference(–oref)は、キャラクターの一貫性を保つ強力な機能ですが、現時点では参照画像を1枚しか指定できません。そのため、異なる2人のキャラをそれぞれ別の参照画像で同時に指定する、といった使い方はそのままではできず、Region Varyなどと組み合わせる工夫が必要です。
【Midjourneyで複数人を生成する方法①】パン機能
いきなり3人分のプロンプトを書くのがむずかしいと感じるなら、パン機能を使って「まず1人 → あとから2人目・3人目を足していく」やり方がおすすめです。
ベースとなる1人目のキャラをしっかり作ってから、画面を横に広げつつ少しずつ人数を増やしていくので、構図が崩れにくく、どこに誰を置くかも直感的にコントロールできます。
パン機能とは?

パン機能は、生成済みの画像の左右上下に「キャンバスを少し広げて、空いた部分を描き足す」ためのアウトペイント機能です。
もともとは背景を伸ばしたり、構図を横長にしたりするときに使われますが、複数人生成では「1人ずつ画面の端から追加していく」用途と相性がとても良いです。
パン機能の最大の利点は、追加するキャラごとに別々のプロンプトを書けるため、特徴が混ざりにくいことです。
なお、操作方法はDiscord版とWeb版で異なります。
- Discord版:アップスケール後に表示される矢印ボタン(←→↑↓)をクリックし、ポップアップでプロンプトを書き換える
- Web版:画像をエディタで開き、グレーのバーをドラッグしてキャンバスを拡張し、プロンプトを更新して送信する
Web版のほうが視覚的にキャンバスの広がり具合を確認しながら操作できるため、初心者にはWeb版がおすすめです。
パン機能を使った複数人生成の手順
複雑なことはせず、次の流れをそのままなぞるだけでOKです。ここではDiscord版の手順をベースに解説しますが、Web版でも基本的な流れは同じです。
- ステップ1基本となるキャラクターを生成
まずは主役となる1人目のキャラを通常どおりプロンプトで作ります。
ここで全体のテイストや画風が決まるので、納得いく1枚が出るまで何度か試すのがおすすめです。
a bright cheerful girl with brown hair in twin tails, wearing sailor uniform, sitting on classroom chair, smiling, anime style --niji 6V7を使う場合は「–niji 6」の代わりに「–v 7」を指定します(アニメ調ならNiji 7も選択肢に入ります)。V7ではプロンプトの解釈精度が上がっているため、より自然な文章で指示を書いても反映されやすくなっています。
- ステップ2気に入った画像をアップスケール
複数人生成に使うのはアップスケール後の画像なので、「これをベースにしたい」と思える1枚を選んでアップスケールします。

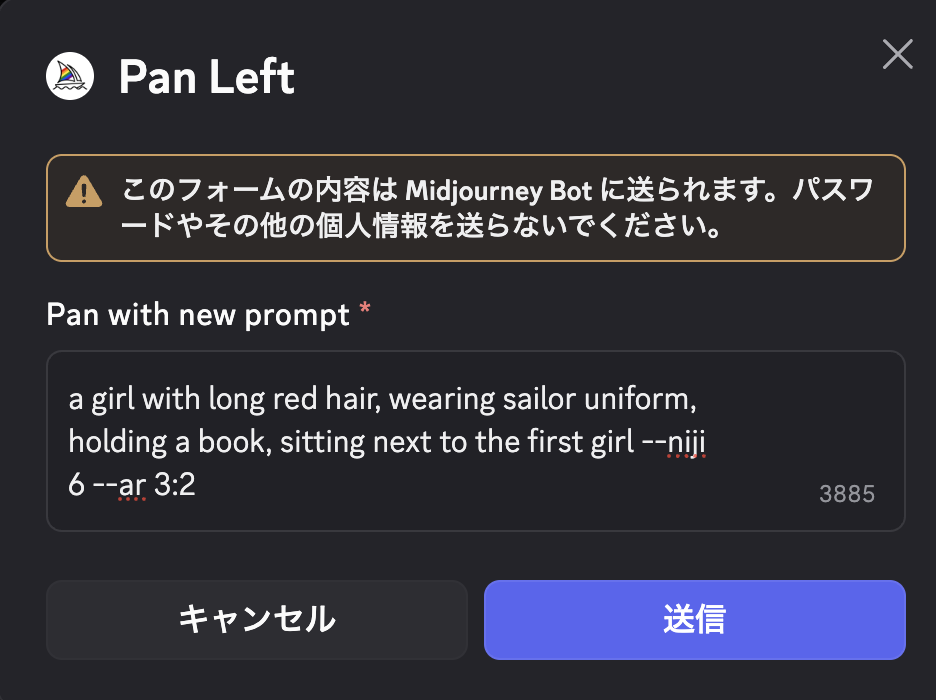
- ステップ3左矢印ボタンをクリックしてPan Left
アップスケール後の画像下にある矢印ボタンから、追加したい方向(例:左にキャラを足したい場合はPan Left)を選びます。
- ステップ4ポップアップに新しいキャラを書く
ここでは、いったん元のプロンプトをすべて削除し、「追加したいキャラの情報」を中心に書き直します。
そのうえで、必要に応じて first girl など、既にいるキャラとの位置関係だけを一行そえておくイメージです。
a girl with long red hair, wearing sailor uniform, holding a book, sitting next to the first girl --niji 6 --ar 3:2 - ステップ5候補から気に入ったものを選ぶ
生成された画像の中から、構図や表情のバランスが良いものを選びます。
違和感があれば、同じプロンプトでもう一度Panしてやり直してかまいません。
- ステップ6反対側にもPanして3人目を追加する
同じ手順で今度は右矢印のPan Rightを選び、3人目のキャラを追加します。

a girl with short black hair and glasses, wearing sailor uniform, serious expression, sitting on the right side of the group --niji 6



パン機能で複数人生成する際の注意点
①追加したキャラは描き込みが甘くなりやすい
中央の1人目より、後からPanで足したキャラほどディテールが弱くなることがあります。顔が小さくなりすぎない構図を選ぶと違和感が出にくいです。気になる場合は、後述するRegion Varyで該当キャラだけ再生成して描き込みを強化する方法も有効です。
②隣のキャラの影響を受けやすい
ポーズや服の雰囲気、色味などが、すでにいるキャラから引っ張られることがあります。まったく別ジャンルの服装やカラーを混ぜたいときは、何度か出し直して選びましょう。
③距離をとりすぎるとタッチがバラバラになりやすい
キャラ同士を離しすぎると、光の当たり方やコントラストだけ微妙に違う、コラージュっぽい仕上がりになることがあります。肩〜半身がほどよく重なるくらいの距離感を目安にすると安定します。
④一度で決めようとせず何回かPanし直す
最初のPanで納得いかなくても普通です。同じ方向に2〜3回Panし直して、その中から一番しっくりくる候補を選ぶ前提で試したほうが、結果的に早く仕上がります。V7のDraftモードを使えば通常の半分のコストで10倍速く生成できるため、構図の試行錯誤にはDraftモードを活用するのもおすすめです。
⑤最後は必ず全体バランスをチェックする
人数を増やしていくと、「1人だけ目線が変」「身長バランスがおかしい」といった細かいズレが出やすくなります。全員の顔の向き・明るさ・足元の位置まで一度引きで見直し、気になる箇所はRegion Varyでピンポイント修正すると仕上がりが安定します。
【Midjourneyで複数人を生成する方法②】キャラクター参照機能
Midjourneyには、指定した画像のキャラクターを参照して新しい画像に登場させる機能があります。いったん「この子」という元画像さえ作っておけば、別カットや別シーンでも同じキャラを何度でも再現できます。
ただし、この機能はバージョンによって名称や仕様が異なります。現在のV7では「Omni Reference(–oref)」、V6やNiji 6では「Character Reference(–cref)」を使います。ここでは両方の使い方を解説したうえで、複数の異なるキャラを1枚に配置するワークフローを紹介します。
キャラクター参照機能とは?
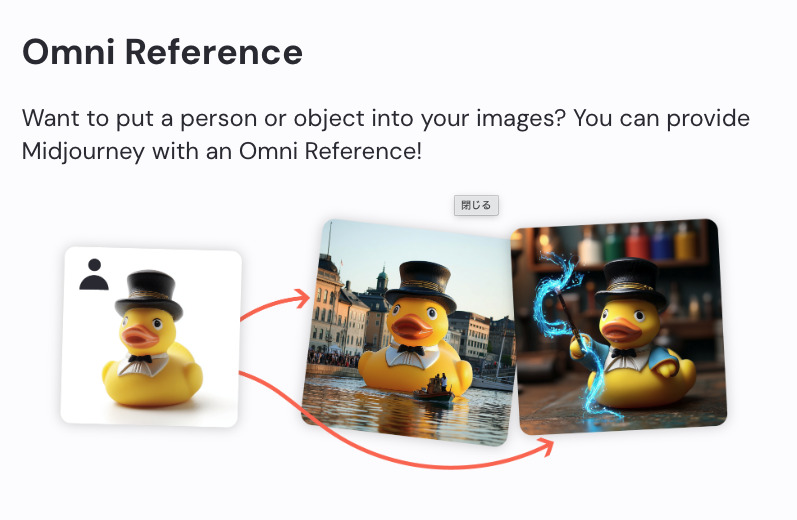
特定の画像を参照させて、その画像に写っているキャラの顔立ち・髪型・服装などの特徴を新しい画像に反映させる機能です。
同じ参照画像を使い続ければ、「同じキャラが別のシーンに登場している」ような絵を量産できます。ただし、あくまで「その画像のキャラを参考にする」機能であって、ドット単位で同じ顔をコピーするわけではありません。ポーズや角度、ライティングが変わると、表情や印象も少しずつ変化します。
V6 / Niji 6:–cref(Character Reference)
プロンプト末尾に「–cref 画像URL」を付けて使います。複数のURLをスペース区切りで指定することもできますが、2つ以上のキャラを同時参照するとキャラ同士の特徴が混ざりやすくなります。忠実度は–cw(Character Weight / 0〜100)で調整します。
V7:–oref(Omni Reference)
V7ではcrefが廃止され、代わりにOmni Referenceが導入されました。キャラクターだけでなくオブジェクトや乗り物なども参照できる汎用的な機能です。Web版ではプロンプトバーの画像アイコンから「Omni Reference」の枠に画像をドラッグ&ドロップするだけで使えます。Discord版では「–oref 画像URL」で指定します。
Omni Referenceの大きな制約として、参照画像は1枚しか指定できない点があります。また、GPU消費が通常のV7生成の2倍になります。忠実度は–ow(Omni Weight / 0〜1000、デフォルト100)で調整します。
V6についてはこちらの記事で詳細に解説しています。

V7についてはこちらの記事で詳細に解説しています。

キャラクター参照機能で複数の異なるキャラを配置する方法
Omni Reference(V7)もcref(V6)も、異なるキャラを同時に参照して1枚に描き分けるのは苦手です。そこで、「まず同じキャラで構図を作り、Region Varyで1人ずつ別キャラに差し替える」という2ステップが定番のワークフローになっています。
- ステップ1同じキャラで複数人を配置
まず同じキャラで複数人を配置します。
この段階では、双子のように「同じ顔の少女が2人」いる絵になりますが、構図(距離感やポーズ)はここで固めてしまいます。
ここでは上記でも使用した画像のURLを使用しています。V6 / Niji 6の場合:
two girls talking to each other, casual clothes, simple background --cref [URL] --niji 6V7の場合:
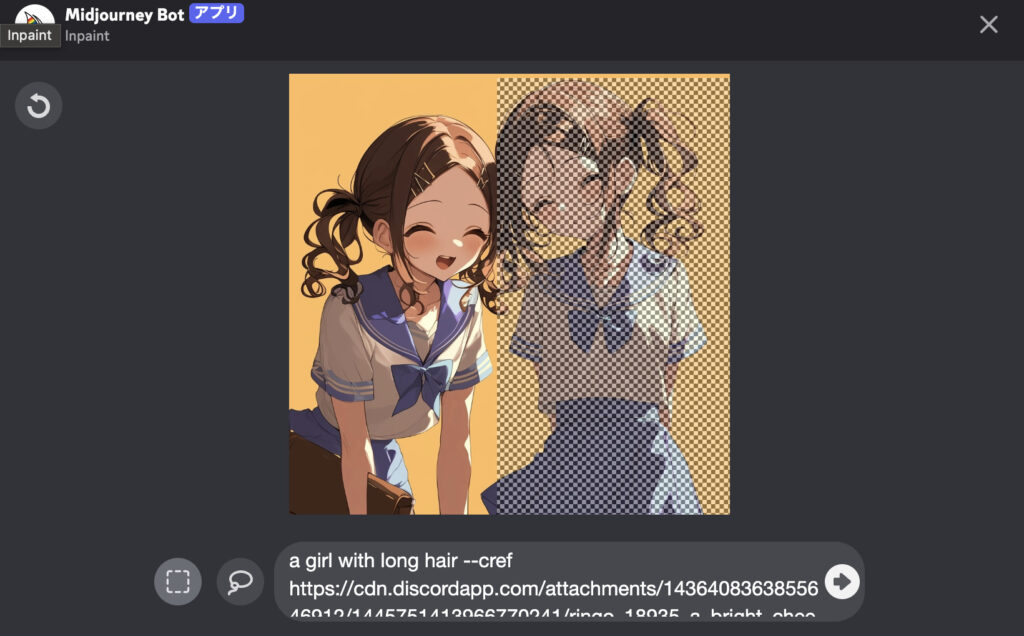
two girls talking to each other, casual clothes, simple background --oref [URL] --v 7 - ステップ2Region Varyで選択範囲を指定し、別のキャラのcrefで置き換え
置き換えたい片方のキャラの顔〜上半身あたりをRegion Varyで囲み、差し替えたいキャラの参照画像を指定して再生成します。
V6 / Niji 6の場合:
a girl with long black hair, smiling gently --cref [別のURL] --cw 70 --niji 6V7の場合: なお、V7ではOmni Referenceで生成した画像はそのままではVary RegionやPanに対応していません(2025年時点)。この場合、Web版のエディタに画像を読み込み、参照画像と–orefパラメータを外した状態で部分編集を行う必要があります。

- ステップ3生成結果確認
差し替え後のキャラが周囲と馴染んでいるかを確認します。違和感がある場合は、選択範囲を少し広げたり、プロンプトに服装や背景の情報を補足して再度Region Varyを実行しましょう。


忠実度パラメータ調整のコツ
キャラクター参照の忠実度は、crefなら–cw、orefなら–owで調整します。考え方は共通で、数値を上げるほど元画像に寄り、下げるほどプロンプト側の指定が優先されます。
–cw(V6 / Niji 6)の目安:
- cw 0:顔の雰囲気だけゆるく似せて、服装・髪型・ポーズなどはプロンプトの指示に大きく従う。衣装を自由に変えたいときに便利
- cw 50〜70:元画像らしさとプロンプトの反映が半々くらいで、バランスが良いおすすめ帯
- cw 100(デフォルト):顔立ちも服装もほぼ元画像どおり。ただし体の大きさやポーズまで引きずりやすく、複数人配置ではサイズ感が崩れることもある
| cw 0 | cw 50 | cw 100 |
|---|---|---|
 |  |  |
a girl standing, full body --cref [URL] --cw [0/50/100] --niji 6–ow(V7)の目安:
- ow 25〜50:スタイル変換(実写→アニメなど)をしたいときに。顔の特徴はゆるく残しつつ、プロンプトの指示を優先
- ow 100(デフォルト):顔や服装をバランスよく再現。多くの用途ではこのあたりから調整を始めるのがおすすめ
- ow 200〜400:顔の細部や服装をかなり忠実に再現したいとき。ただし–stylizeや–expの値が高い場合は、owも同程度に上げないと参照が負けてしまう
- ow 400超:公式も「通常は400を超えないほうがよい」と案内しており、上げすぎると逆に品質が落ちることがある
キャラが大きすぎる・小さすぎるなどサイズ感が合わないときは、まず忠実度を少し下げて様子を見ましょう。逆に「この服装だけはほぼそのまま再現してほしい」ときは、忠実度を上げてみるとうまくいくことが多いです。
参照画像を作るときのコツ
キャラクター参照の精度は、元となる参照画像の質に大きく左右されます。以下のポイントを押さえておくと、参照の安定度が上がります。
- Midjourneyで生成した画像を使うのがもっとも高精度。実写の写真は正確に再現されないことが多い
- 顔がはっきり写った正面〜斜め向きの画像を選ぶ。後ろ姿や横顔だけの画像は参照精度が落ちる
- 背景はシンプルなものを選ぶ。複雑な背景は参照時にノイズになりやすい
- 可能であれば、正面・斜め左・斜め右など複数アングルを1枚にまとめた三面図風の画像を用意すると、角度が変わったときの再現性が大きく向上する
【Midjourneyで複数人を生成する方法③】Region Vary(部分再生成)

複数人の画像を作ってみたものの、「全体の雰囲気は気に入っているけれど、このキャラだけ別の子に差し替えたい」「表情だけ変えたい」ということはよくあります。
そんなときに便利なのが、画像の一部分だけを描き直せるRegion Varyです。構図や背景はそのままに、指定したキャラだけをピンポイントで調整できます。
方法②「キャラクター参照機能で複数の異なるキャラを配置する方法」のステップ2でも使用した、複数人生成の要となる機能です。
Region Varyとは?
Region Varyは、生成済みの画像の中から任意の範囲を選択し、その部分だけを再生成してくれるインペイント(部分描き直し)機能です。
Discord版では、アップスケール後の画像詳細画面で「Vary(Region)」ボタンを選ぶと、画像の上に選択用の枠が表示されます。描き直したい箇所をドラッグで囲み、新しいプロンプトを入力して再生成します。
Web版では、画像をクリックしてエディタを開き、ブラシツールやなげなわツールで範囲を選択します。Web版のほうが選択範囲を細かく調整しやすく、複数人構図での「隣のキャラを巻き込まない範囲指定」がやりやすいです。
いずれの方法でも、背景やほかのキャラは基本的にそのまま残るため、「全体はそのまま、ここだけ差し替えたい」という調整に向いています。
パン機能やキャラクター参照機能と組み合わせることで、複数人構図の仕上げツールとして非常に強力に機能します。
Region Varyで複数人を自然に配置するコツ
①選択範囲は「少し広め」が鉄則
キャラの輪郭ギリギリだけを選ぶより、髪の毛の外側やまわりの背景も少し含めて、ひと回り大きめに囲むと自然な仕上がりになりやすいです。範囲が狭すぎると、境界部分に不自然な継ぎ目やにじみが出てしまいます。
ただし、隣のキャラの顔まで選択範囲に入れてしまうと、その子まで一緒に変わってしまうことがあるので、そこだけは注意が必要です。Web版のなげなわツールを使えば、矩形では難しい「隣のキャラを避けながら対象だけを囲む」操作がしやすくなります。
②密集構図はPanで余白を作ってから編集する
キャラ同士の距離が近すぎる構図だと、Region Varyで囲んだ範囲にどうしても他の人物が入り込みやすく、サイズ感も崩れがちです。
一度Panで左右に少し余白を作ってからRegion Varyを使うと、選択範囲を取りやすくなり、キャラの大きさも安定します。「構図が窮屈だな」と感じたら、まずPanで空間を広げるのが先です。
③キャラクター参照機能と組み合わせてキャラを差し替える
「この位置のキャラだけ、別の子に差し替えたい」というときは、Region Varyで範囲を選んだうえで、プロンプト側にキャラクター参照を指定します。
V6 / Niji 6の場合は–crefで差し替えたいキャラの画像URLを指定し、cw(Character Weight)を70前後にしておくと、元画像らしさとプロンプトの指示のバランスが取りやすいです。
a girl with pink hair, cheerful expression --cref [URL] --cw 70 --niji 6V7の場合、Omni Referenceで生成した画像はそのままではVary RegionやPanに対応していない点に注意が必要です(2025年時点)。V7環境でRegion Varyを使いたい場合は、Web版のエディタに画像を読み込み、–orefパラメータを外した状態で部分編集を行います。公式も今後のアップデートでの対応を示唆しているため、最新の対応状況はMidjourney公式ドキュメントで確認してください。
④1箇所ずつ順番に差し替える
複数のキャラを一度に差し替えようとすると、変更箇所同士が干渉して意図しない結果になりやすくなります。「左のキャラを差し替え → 結果を確認 → 次に右のキャラを差し替え」と、1人ずつ順番に処理していくのが安定のコツです。
Vary(Region)の詳細な使い方については以下の記事で解説しています。

Midjourneyで複数人生成をする際のプロンプトのコツ
複数人を一度に描こうとすると、つい情報を詰め込みすぎてしまい、「誰がどんなキャラなのか」がAIに伝わりにくくなりがちです。
ここでは、パン機能やRegion Varyといった機能面のテクニックとは別に、プロンプトの書き方そのものを少し整理するだけでキャラ同士が混ざりにくくなるコツをまとめます。難しいテクニックは使わず、「どの順番で、どんな情報を書けばいいか」にしぼって解説していきます。
最初に人数をはっきり宣言する
プロンプトの冒頭で人数を明確に書くだけで、AIが「何人描けばいいのか」を正しく認識しやすくなります。
人数の宣言がないと、AIは学習データの傾向から「一人が中央にドーンと立つ構図」をデフォルトで選びがちです。「two girls」「three friends」「a group of four people」のように、プロンプトの先頭付近で人数を指定しましょう。
Midjourneyではプロンプトの前方に書かれた情報ほど重視される傾向があるため、人数の宣言は後半ではなく最初のほうに置くのがポイントです。
(良い例)three school girls wearing sailor uniforms, standing together in a bright classroom...
(悪い例)bright classroom, sailor uniforms, there are three girls standing...キャラごとの特徴を「セット」で書き分ける
複数人プロンプトでもっとも重要なのは、「誰がどの子なのか」をAIにはっきり教えてあげることです。ふわっとした言葉だけで書くと、全員が同じような見た目になってしまいます。
効果的なのは、1人ずつ「番号や呼び名+外見+ポーズや動作」をセットにして書く方法です。
1st girl: cheerful, brown twin tails, holding a phone,
2nd girl: serious, long black hair with glasses, reading a book,
3rd girl: sporty, short red hair with headband, stretching armsこのとき意識したいのは、キャラ同士の見た目のコントラストを大きくすることです。髪色・髪型・服装・体型など、パッと見で区別がつく差をつけるほど、AIは描き分けやすくなります。同性・同体型・同髪色のキャラを並べると混ざりやすいのは前述のとおりなので、男女混合にしたり、身長差(tall / short / petite)を明示したりすると安定度が上がります。
「left / center / right」で配置を指定する
キャラの特徴だけでなく、画面上のどこにいるかも指定すると、AIが配置を判断しやすくなります。
left: purple short hair girl in frilly dress,
center: black long hair girl in elegant dress,
right: blonde twin tails girl in cute dress「left / center / right」のほかにも、「foreground(手前)/ background(奥)」や「sitting on the left side / standing behind」など、位置関係を表す言葉を使うと構図のコントロール精度が上がります。
ただし、V7ではプロンプトの解釈精度が向上しているとはいえ、位置指定が100%正確に反映されるわけではありません。あくまで「傾向を誘導する」程度に考え、理想どおりにならなければ何度か再生成するか、Region Varyで微調整しましょう。
背景とシチュエーションを「共通要素」としてまとめる
キャラの説明ばかりに気を取られると、背景や雰囲気がバラバラになり、まとまりのない絵になってしまいます。プロンプトの最後に「全員に共通する舞台装置」をまとめて指定しておくと、一枚のシーンとして成立しやすくなります。
意識すべき共通要素は次の4つです。
- 場所:classroom / concert stage / office / cafe など
- 時間帯・光の雰囲気:at sunset, warm lighting, soft focus など
- カメラの距離と角度:medium shot, eye-level, group photo, wide angle など
- 全員の感情・ムード:cheerful, relaxed, serious meeting など
特に「group photo」「ensemble shot」のような構図キーワードは、AIに「複数人を均等に映す構図」を選ばせるのに効果的です。これがないと、1人だけがクローズアップされる構図に引っ張られやすくなります。
プロンプトは「盛りすぎない」ことが最大のコツ
複数人ぶんの条件を1つのプロンプトに詰め込みすぎると、AIは優先度の低い情報から無視していき、意図しない髪色や服装に置き換わることがあります。V7ではプロンプトの理解力が向上していますが、それでも情報過多は逆効果になりがちです。
目安として、1人あたりの特徴は3〜5要素(髪色・髪型・服装・ポーズ・持ち物のうちいくつか)にとどめ、細かいアクセサリーや表情のニュアンスはRegion Varyで後から調整するくらいの割り切りが、結果的にもっとも安定します。
プロンプトの基本構造をテンプレートとしてまとめると、次のようになります。
[人数] + [キャラA:外見+動作], [キャラB:外見+動作], [キャラC:外見+動作], [共通の場所・光・構図・ムード] + [パラメータ]この「人数の宣言 → キャラごとの特徴 → 共通シーン → パラメータ」の順番を守るだけで、複数人プロンプトの成功率はかなり上がります。
マルチプロンプト(::)で要素を分離する
Midjourneyには、ダブルコロン(::)でプロンプトを区切ることで、各要素を独立したコンセプトとして処理させる「マルチプロンプト」機能があります。複数人生成では、キャラ同士の特徴が混ざるのを防ぐテクニックとして活用できます。
a girl with red hair wearing a blue dress:: a boy with black hair wearing a white shirt:: sitting together at a cafe, warm lighting --v 7このように書くと、「赤い髪の女の子+青いドレス」と「黒い髪の男の子+白いシャツ」がそれぞれ独立した情報として処理されるため、髪色や服装が相手に流れ込む「色移り」を軽減できます。
さらに、要素ごとに重み(ウェイト)をつけることも可能です。たとえば「a girl with red hair::2 a boy::1」のように書くと、女の子のほうがより目立つ構図になりやすくなります。
ただし、マルチプロンプトは万能ではなく、区切りすぎると全体の統一感が失われることもあります。まずは通常のプロンプトで試し、特徴の混ざりが気になる場合にマルチプロンプトを使う、という順番がおすすめです。
実際に使える!複数人生成のプロンプト例
ここからは、すぐにコピペして試せる複数人プロンプトの例をいくつか載せておきます。好みに合わせて髪色や服装だけ変えて使ってみてください。
アニメ系複数人のプロンプト例
学園もの3人組

three school girls wearing sailor uniforms, together in a bright classroom, cheerful girl with brown twin tails, serious girl with long black hair and glasses holding a book, sporty girl with short red hair and headband, energetic pose, anime style --niji 6アイドルグループ

Three idol girls on stage, left: purple short hair girl in frilly dress, center: black long hair girl in elegant dress, right: blonde twin tails girl in cute dress, spotlights, concert stage --niji 6ファンタジーパーティー

A female elf archer with long blonde hair and green cloak. A dwarf warrior with red beard and heavy armor. A human mage with blue robe and staff, forest background, adventure party --niji 6リアル系複数人のプロンプト例
ビジネスシーン

three business people standing together in a modern office, a businessman in navy suit with short black hair, a businesswoman in gray suit with glasses and brown hair in bun, a young professional in casual blazer with short blonde hair, professional photography style --v 7友人グループ

Three friends at cafe, left: Asian woman with long dark hair in white blouse, center: Caucasian man with brown hair in casual shirt, right: African woman with curly hair in colorful dress, laughing together, natural lighting --v 7Midjourneyの複数人生成でよくある失敗パターンと対処法
ここまで紹介した方法を使っても、複数人生成では特有のトラブルが起きることがあります。ここでは、実際によく遭遇する失敗パターンとその原因・具体的な対処法をまとめます。「うまくいかない」と感じたときに、該当するパターンがないか確認してみてください。
キャラの顔や特徴が混ざってしまう
症状:「赤い髪の女の子」と「黒い髪の女の子」を指定したのに、両方とも赤黒い髪になったり、片方の服装がもう片方に移ったりする。
原因:Midjourneyはプロンプト内のどの特徴をどのキャラに割り当てるか判断するのが苦手です。特に同性・同体型のキャラを並べた場合、特徴が相互に流れ込みやすくなります。キャラクター参照で複数のURLを同時指定した場合も、顔の特徴が混ざった「ハイブリッドキャラ」が生成されることがあります。
対処法:
- キャラ同士の見た目のコントラストを大きくする(髪色・髪型・性別・体格を明確に変える)
- マルチプロンプト(::)でキャラごとの情報を区切り、特徴の流入を防ぐ
- 1つのプロンプトで複数キャラを同時に参照するのではなく、同じキャラで構図を作ってからRegion Varyで1人ずつ差し替える「2ステップ生成」を使う
指定した人数と合わない(多い・少ない)
症状:「three girls」と書いたのに2人しか描かれない、あるいは4人に増えてしまう。
原因:プロンプト内の人数指定が後半に埋もれていると、AIが正しく認識しないことがあります。また、プロンプトの情報量が多すぎる場合、人数の指定自体が無視されることもあります。
対処法:
- 人数はプロンプトの冒頭付近に明確に書く(「Three girls standing together」のように最初のほうに配置する)
- プロンプト全体の情報量を絞り、人数+主要な特徴だけに集中する
- それでも合わない場合は、まず少ない人数で生成し、Panで1人ずつ追加していく段階的アプローチに切り替える
1人だけ極端に大きい・小さい(サイズ感のバグ)
症状:3人並べたのに、1人だけ巨大に描かれたり、逆に極端に小さく遠くに配置される。
原因:キャラクター参照を使うと、元画像のキャラの構図やサイズ感まで引きずってしまうことがあります。特にcw(V6)やow(V7)の値が高すぎると、元画像のキャラが画面いっぱいに写っている場合にそのサイズ感が新しい画像にも影響します。また、学習データの偏りで「一人だけ中央にドーンと大きく映る」構図に引っ張られるケースもあります。
対処法:
- キャラクター参照の忠実度(cw / ow)を下げる。cw 0やow 50程度まで下げると、サイズ感の引きずりが軽減される
- 参照画像を「三面図」や「バストアップ+全身」など複数アングルを1枚にまとめたものにすると、特定のサイズ感に引っ張られにくくなる
- 「group photo, medium shot, eye-level」のような構図キーワードを追加して、全員が均等に映る構図を誘導する
手や指が崩れる
症状:キャラ同士が手をつないだり腕を組んだりするシーンで、指の本数がおかしい、手が溶けている、関節があり得ない方向に曲がっている。
原因:V7では手や指の描写が大幅に改善されましたが、複数人が物理的に接触するシーンでは依然として崩れやすい傾向があります。特に「手をつなぐ」「肩を組む」など、異なるキャラの身体パーツが交差する描写は難易度が高いです。
対処法:
- 最初のプロンプトではキャラ同士の身体的な接触を避け、それぞれが独立したポーズをとる構図で生成する
- 接触ポーズが必要な場合は、「holding hands」のような直接指定よりも「standing close together, friendly atmosphere」のような雰囲気指定のほうが自然に仕上がることが多い
- どうしても手の描写が崩れる場合は、Region Varyで手の部分だけを選択し、再生成で修正する
全体のタッチや光の統一感がない(コラージュ感)
症状:パン機能で追加したキャラと元のキャラで、ライティング・彩度・画風のタッチが微妙に異なり、まるで別々の画像を貼り合わせたように見える。
原因:Panで画面を広げて新キャラを追加する際、元画像と拡張部分で光源や色調の計算が独立して行われるため、微妙なズレが生じることがあります。特にキャラ同士の距離が離れているほど、この傾向が強くなります。
対処法:
- キャラ同士の距離は近めにして、肩や腕が軽く重なるくらいの構図を目指す
- Panのプロンプトにも「same lighting, consistent color tone」のような統一感を求めるキーワードを追加する
- Style Reference(–sref)を設定し、画風やトーンをロックしておくと全体の一貫性が保ちやすい
- 仕上げにRegion Varyで違和感のある箇所のライティングや色調を部分的に再生成して整える
キャラ同士のインタラクション(やりとり)が不自然
症状:「会話しているシーン」や「肩を組んでいるシーン」を指定しても、視線がかみ合わない、身体の向きがバラバラ、明らかに別撮りの写真を合成したように見える。
原因:Midjourneyは「キャラ同士の関係性」を理解するのが苦手です。「talking to each other」と書いても、それぞれが別の方向を向いていたり、距離感が不自然だったりすることがあります。V7では改善されていますが、複雑なインタラクションの再現はまだ発展途上です。
対処法:
- 具体的な身体の向きや視線を指定する(「facing each other, making eye contact」など)
- 複雑なインタラクションよりも、まずは「並んで立つ・座る」のようなシンプルな配置で構図を作り、自然な距離感を確保してから微調整する
- 個別のアイテムを持つ指定(「1st girl holding a coffee cup, 2nd girl holding a book」)のほうが、キャラ同士が直接触れ合うポーズよりも安定する
- Region Varyで目線の方向や顔の向きだけをピンポイント修正する
参照画像を使ったのに似ていない
症状:crefやorefでキャラクター参照を使っているのに、生成されたキャラが元画像とまったく似ていない。
原因:参照画像の品質や条件が不適切な場合に起こります。ライティングが極端な画像、横顔や後ろ姿だけの画像、背景がごちゃごちゃした画像では、AIが顔の特徴を正しく拾えません。また、cw / owの値が低すぎる場合もプロンプト側の指示が優先され、元画像の特徴が薄まります。
対処法:
- 参照画像はMidjourneyで生成したものを使う(実写の写真は再現精度が落ちやすい)
- 顔がはっきり写った正面〜斜め向きのシンプルな構図を選ぶ
- cw / owの値を段階的に上げて、どの程度の忠実度が必要かを確認する(V6ならcw 50〜70、V7ならow 100〜200あたりから試す)
- 可能であれば、正面・斜め左・斜め右の3アングルを1枚にまとめた「キャラクターシート」を参照画像として使い、あらゆる角度からの再現性を高める
Midjourney以外のツールとの比較・使い分け
Midjourneyは複数人生成に使える機能(パン、キャラクター参照、Region Vary)が豊富ですが、万能ではありません。他の画像生成AIにもそれぞれ異なる強みがあり、目的やシーンによっては別のツールを使ったほうがスムーズに仕上がることもあります。
ここでは、複数人生成という観点に絞って、主要な画像生成AIとMidjourneyの違いを比較します。
| 比較項目 | Midjourney(V7) | ChatGPT(GPT-4o) | Stable Diffusion(SDXL / SD3) | Adobe Firefly |
|---|---|---|---|---|
| 複数人の描き分け | パン+Region Vary+orefの組み合わせで安定。ただし工程が多い | 会話形式で指示でき、Gen-IDで部分修正も可能。手軽さはトップクラス | ControlNet+IP-Adapterで高精度な配置制御が可能。ただし環境構築が必要 | Generative Fill(生成塗りつぶし)で部分差し替えが可能。構図のコントロール精度はやや低め |
| キャラの一貫性 | oref(V7)/ cref(V6)で高い一貫性を実現 | Gen-IDで同一キャラを維持できるが、複数人の同時管理は不安定 | LoRA・DreamBooth等で独自モデル学習すれば最高精度。ただし学習コストが高い | キャラクター一貫性の専用機能はなし。参照画像ベースでの類似表現にとどまる |
| 操作の手軽さ | Web版エディタで直感的に操作可能。Discord版はやや慣れが必要 | ChatGPTの会話欄に日本語で指示するだけ。もっとも手軽 | WebUI等の環境構築が必要。技術的知識がないとハードルが高い | Photoshopに統合されており、デザイナーには馴染みやすい |
| 画風・アート性 | 芸術性が高く、ファンタジー・コンセプトアートに強い。Nijiモデルでアニメにも対応 | 実用的でクセのない画風。文字入れやインフォグラフィックに強い | モデル次第であらゆる画風に対応。リアル系からアニメ系まで自由自在 | 商用素材向けのクリーンな画風。著作権面での安心感が強み |
| 料金 | 月額10〜120ドルのサブスク制。無料プランなし | ChatGPT Plus(月額20ドル)で利用可能。無料プランでも制限付きで生成可 | オープンソースで無料(ローカル環境の場合)。クラウドサービス利用時は従量課金 | 無料枠あり(月25クレジット)。Adobe CCプランに含まれる場合も |
ChatGPT(GPT-4o画像生成)

2025年にGPT-4oに画像生成機能が統合され、ChatGPTの会話欄から直接画像を生成できるようになりました。複数人生成においては、日本語の自然文で「3人の女子高生が教室で話している」のように指示するだけで、ある程度安定した構図が得られます。
「Gen-ID」を使えば生成済みの画像を部分的に修正でき、「この画像のGen-IDを教えて → Gen-IDを維持したまま左の子の髪色を変えて」のようなやりとりで微調整も可能です。
ただし、キャラクターの一貫性を保つ仕組みはMidjourneyほど強力ではなく、複数回にわたってまったく同じキャラを再現したい場合には不向きです。「手軽さ重視で、細かいキャラ管理は必要ない」というケースに向いています。
Stable Diffusion(SDXL / SD3)

オープンソースの画像生成AIで、ローカル環境で動かせるため自由度が圧倒的に高いのが最大の特徴です。
複数人生成においては、ControlNetを使ったポーズ・構図の精密制御、IP-AdapterやInstantIDによるキャラクター参照、さらにLoRAやDreamBoothで独自のキャラクターモデルを学習させるといった、Midjourneyにはないレベルの細かいコントロールが可能です。
一方で、これらの機能を使いこなすにはWebUI(AUTOMATIC1111やForge)の導入、モデルファイルの管理、パラメータの理解など、相応の技術的知識が求められます。「最高の精度で複数人を描き分けたいが、環境構築に時間をかけられる」という中〜上級者向けの選択肢です。
MidjourneyとStable Diffusionの比較については以下の記事で詳細に解説しています。

Adobe Firefly

Adobe製品に統合された画像生成AIで、Photoshopの「生成塗りつぶし(Generative Fill)」機能として使えるのが最大の強みです。
複数人生成の観点では、Photoshop上で人物の一部を選択して別キャラに生成し直す、といった操作がMidjourneyのRegion Varyに近い感覚で行えます。ただし、MidjourneyのOmni Referenceやcrefのようなキャラクター一貫性を保つ専用機能はないため、同じキャラを厳密に再現し続けるのは得意ではありません。
Adobe Stockの学習データを使用しており、商用利用時の著作権リスクが低い点は大きなメリットです。「商用素材として安心して使える複数人画像を作りたい」「すでにPhotoshopを使い慣れている」という方に向いています。
結局どう使い分ける?
用途に応じた使い分けの目安は次のとおりです。
- アート性の高い複数人イラスト・コンセプトアート → Midjourney
- 手軽にサクッと複数人画像を作りたい → ChatGPT(GPT-4o)
- キャラの一貫性と構図を完璧にコントロールしたい → Stable Diffusion
- 商用素材として著作権リスクを最小限にしたい → Adobe Firefly
もちろん、1つのツールに絞る必要はありません。たとえば「Midjourneyでベースの構図を作り、Photoshop(Firefly)で仕上げの微調整を行う」「Stable Diffusionで精密なキャラモデルを作り、Midjourneyでアート性の高い背景と合成する」など、複数ツールの組み合わせでそれぞれの弱点を補うハイブリッド運用も有効です。
まとめ
Midjourneyで複数人をきれいに並べるには、「AIは複数人が苦手」という前提を踏まえて、段階的に整えてあげることが大事です。
まずはパン機能で1人ずつ増やしながら構図を決めて、crefで同じキャラの顔や雰囲気をそろえ、必要なところだけRegion Varyで入れ替える、という流れを押さえておけば、大きく崩れることは減っていきます。
プロンプトも、最初に人数をはっきり書き、キャラごとの特徴と共通のシチュエーションを分けて書くだけで安定度がかなり変わります。
この記事のサンプルをベースに、自分の作品用に少しずつアレンジしながら、理想の「3人組・4人組カット」をどんどん増やしてみてください。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

