
最近、話題になっている「画像生成AI」。
プロが描いたようなイラストや画像を見て、そのクオリティの高さや手軽さから「私もやってみたいな~」と思っていませんか?
そんな方におすすめなのが「Draw Things」というAI画像生成アプリです。
Draw Thingsは、誰でも簡単に高品質な画像を生成できることで注目されています。
この記事では、Draw Thingsの概要や使い方、商用利用する際の注意点などを徹底解説し、魅力を余すことなくお伝えします。
内容をまとめると…
appleユーザーのための無料で使えるAI画像生成アプリ「Draw Things」!
オフラインで画像生成できる!モデルやLoRAの追加でカスタマイズも自由自在!
プロンプトはもちろん、「画像から画像」を生成するImg2Imgも搭載!
商用利用は可能!でも使うモデルのライセンス確認は自己責任!
新しいAIツールを誰よりも早く収入に繋げるためのコツを生成AIのプロから無料で学ぼう!
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Draw Thingsとは
Draw Thingsは、画像生成AI「Stable Diffusion」をベースにしたAI画像生成アプリです。
Draw Thingsは、テキストの指示をもとに幅広いジャンルの画像を生成できることで、人気を博しています。
従来の画像生成AIには「環境設定が難しい」、「高性能なGPUを搭載したハードウェアが必要」など様々な課題がありました。
しかしDraw Thingsの登場により、完全無料で、誰でも簡単にAIで画像生成ができるようになりました。
そんな便利なDraw Thingsの特徴について、以下で解説します。
Draw Thingsが使える環境:iphoneやiPadでも使える?
Draw Thingsは、Apple製品で利用することが可能なアプリで、MacやiPad、iPhoneで利用できます。
残念ながらWindowsは非対応です。
Apple製品に搭載されているM1・M2チップが、高速で複雑な画像処理を実現しています。
このチップのおかげで、Draw Thingsは外部GPUがなくても手軽に画像生成を楽しめるのです。
以下は、Draw Thingsの対応デバイス一覧です。
| iPhone | iOS 15.4以降、およびA12 Bionicチップ以降を搭載したデバイス |
| iPad | iPadOS 15.4以降、およびA12 Bionicチップ以降を搭載したデバイス |
| Mac | macOS 12.4以降 |
| Apple Vision | visionOS 1.0以降、およびA12 Bionicチップ以降を搭載したデバイス |
Draw Thingsは日本語対応しているか
対応言語は「英語、中国語、スペイン語」の3か国語のみで、日本語には対応していません。
今後のアップデートで日本語が追加されることを期待しましょう。
分からない言葉や単語があった際には、翻訳アプリなどを活用すると解決の糸口が見つかるでしょう。
またDraw Thingsのデフォルトの言語は、本体の設定画面から設定できます。
以下ではiPhoneを使った言語設定の手順を紹介します。
 | ①Draw Thingsのアプリの設定に移動し、「言語」をタップします。 |
 | ②好みの言語にチェックを入れると言語の設定が完了します。 |
Draw Thingsのメリット
Draw Thingsにはお勧めしたいポイントがたくさんあります。
ここでは、Draw Thingsを使うメリットを紹介します。
- 面倒な環境設定が不要
- 初心者でも利用しやすい
- 無料で使える
- オフラインで利用できる
- 多機種で対応!iOSおよびmacOSで使用できる
- 人気のあるモデルが使える
- モデルやLoRAが追加可能でカスタマイズしやすい
- アップデートされ続けている
Draw Thingsはインストールするだけで使用でき、会員登録や複雑な初期設定が不要なので手軽に始められます。
直感的な操作性なので、初心者でも簡単に画像を生成することが可能です。
さらに、無料でありながら、モデルやLoRAの追加、シード値やImg2Imgの調整など、高度な機能が豊富に備わっています。
またオフライン利用が可能で、iPhoneのような身近な機種で利用できるため、場所やデバイスに依存することなく作業できます。
Draw Thingsにはすでに便利な機能が豊富にありますが、アップデートによって最新の機能が追加され、さらに便利になっていくことでしょう。
このように、Draw Thingsは無料でありながらも非常に強力な画像生成ツールです。
そのため初心者から商用利用するプロまで幅広い層の利用者に愛されています。
Draw Thingsで使えるモデル一覧
Draw Thingsで使えるモデルは60種類以上あります!
多種多様なモデルが揃っており、目的に合った使い方がしやすいです。
また以下の記事では、Stable Diffusionで使われているオススメのモデルやモデルとは何かを丁寧に解説しているので、ぜひご覧ください。

ここでは、Draw Thingsで使えるモデルの一覧をご紹介します。
| モデル名 | 対応version |
|---|---|
| Generic HD (Stable Diffusion v2.0 768-v) | Stable Diffusion v2 |
| Generic (Stable Diffusion v1.4) | Stable Diffusion v1 |
| Generic (Stable Diffusion v1.5) | Stable Diffusion v1 |
| Inpainting (Stable Diffusion v1.5 Inpainting) | Stable Diffusion v1 |
| Generic (Stable Diffusion v2.0) | Stable Diffusion v2 |
| Inpainting (Stable Diffusion v2.0 Inpainting) | Stable Diffusion v2 |
| Depth (Stable Diffusion v2.0 Depth) | Stable Diffusion v2 |
| Generic (Stable Diffusion v2.1) | Stable Diffusion v2 |
| Generic HD (Stable Diffusion v2.1 768-v) | Stable Diffusion v2 |
| Multi-Language HD (Kandinsky v2.1) | Kandinsky v2.1 |
| SDXL Base (v1.0) | Stable Diffusion XL Base |
| SDXL Turbo | Stable Diffusion XL Base |
| LCM SDXL Base (v1.0) | Stable Diffusion XL Base |
| SDXL Refiner (v1.0) | Stable Diffusion XL Refiner |
| SDXL Base v1.0 (8-bit) | Stable Diffusion XL Base |
| SDXL Refiner v1.0 (8-bit) | Stable Diffusion XL Refiner |
| SDXL Turbo (8-bit) | Stable Diffusion XL Base |
| LCM SDXL Base v1.0 (8-bit) | Stable Diffusion XL Base |
| Fooocus Inpaint SDXL v2.6 | Stable Diffusion XL Base |
| Fooocus Inpaint SDXL v2.6 (8-bit) | Stable Diffusion XL Base |
| Stable Video Diffusion l2V v1.0 | Stable Video Diffusion |
| Stable Video Diffusion l2V 1.0 (8-bit) | Stable Video Diffusion |
| Stable Video Diffusion l2V XT v1.1 | Stable Video Diffusion |
| Stable Video Diffusion l2V XT 1.1 (8-bit) | Stable Video Diffusion |
| SSD 1B (Segmind SDXL) | Segmind Stable Diffusion XL 1B |
| LCM SSD 1B (Segmind SDXL) | Segmind Stable Diffusion XL 1B |
| SSD 1B (8-bit) | Segmind Stable Diffusion XL 1B |
| LCM SSD 1B (8-bit) | Segmind Stable Diffusion XL 1B |
| Editing (Instruct Pix2Pix) | Stable Diffusion v1 |
| Anime (Waifu Diffusion v1.3) | Stable Diffusion v1 |
| Multi-Style (Nitro Diffusion v1) | Stable Diffusion v1 |
| Cyberpunk Anime | Stable Diffusion v1 |
| 3D Model (Redshift v1) | Stable Diffusion v1 |
| 3D Model 768 (Redshift 768) | Stable Diffusion v2 |
| Dungeons and Diffusion (30000) | Stable Diffusion v1 |
| Tron Legacy | Stable Diffusion v1 |
| Openjourney | Stable Diffusion v1 |
| Anime (Anything v3) | Stable Diffusion v1 |
| Classic Animation (v1) | Stable Diffusion v1 |
| Modern Disney (v1) | Stable Diffusion v1 |
| Arcane (v3) | Stable Diffusion v1 |
| Hassanblend (v1.5.1.2) | Stable Diffusion v1 |
| Van Gogh Style (Lvngvncnt v2) | Stable Diffusion v1 |
| Spider-Verse (v1) | Stable Diffusion v1 |
| Elden Ring (v3) | Stable Diffusion v1 |
| Paper Cut (v1) | Stable Diffusion v1 |
| VoxelArt (v1) | Stable Diffusion v1 |
| Balloon Art (v1) | Stable Diffusion v1 |
| F222 | Stable Diffusion v1 |
| Super Mario Nation (v2) | Stable Diffusion v1 |
| Inkpunk (v2) | Stable Diffusion v1 |
| SamDoesArt (v3) | Stable Diffusion v1 |
| Ghibli (v1) | Stable Diffusion v1 |
| Analog (v1) | Stable Diffusion v1 |
| DnD Classes and Species | Stable Diffusion v1 |
| AloeVera’s SimpMaker 3K1 | Stable Diffusion v1 |
| H&A’s 3DKX 1.1 | Stable Diffusion v1 |
| seek.art MEGA (v1) | Stable Diffusion v1 |
| Deliberate v2.0 (8-bit) | Stable Diffusion v1 |
| Disney Pixar Cartoon Type B (8-bit) | Stable Diffusion v1 |
| Realistic Vision v3.0 (8-bit) | Stable Diffusion v1 |
| DreamShaper v6.31 (8-bit) | Stable Diffusion v1 |
Draw ThingsのiPhoneでの使い方:実際に画像生成してみた
ここでは、Draw Thingsの導入から画像作成までの流れを紹介します。
以下では、iPhoneの画面で解説します。
 | ①AppleStoreでDraw Thingsのアプリをインストールします。 Wi-Fi環境でのインストールがおすすめです。 |
 | ②アプリを立ち上げ、モデルの選択をします。 私はGeneric (Stable Diffusion v1.5)を選択しました。「Generic~」は、色々なジャンルに対応しているベーシックなモデルです。 |
 | ③「Next」ボタンをクリックします。 |
 | ④「選択したモデルはネットワーク経由でダウンロードする必要があります。続行しますか?」 という警告文が表示されます。 Wi-Fiに接続していることを確認し「continue」ボタンをクリックしてください。 |
 | ⑤モデルのダウンロードをします。 モデルのダウンロードには15分ほどかかります。 |
 | ⑤ダウンロードしたモデルを使って画像生成します。 デフォルトで様々な設定がされているので、そのまま「Generate」ボタンを押してみるのもいいでしょう。 |
 | こちらは、プロンプトを変更せずに「Generate」ボタンをクリックして生成された画像です。 |
プロンプト(呪文)を変える場合は以下の手順でします。
①プロンプト(呪文)を入力する
②「Generate」ボタンをクリックする
iPhone版アプリを使う場合の、プロンプトの入力方法を解説します。
 | ◇ポジティブプロンプトの入力◇ 赤枠部分に、生成する画像に含めたい要素を入力します。 カンマと半角スペースで、単語や文章を区切ります。 |
 | ◇ネガティブプロンプトの入力◇ 画面右端にある「 〉」をタップするとネガティブプロンプトの入力欄に切り替わります。 |
 | 「Enter negative promput…」と書かれた枠の中にネガティブプロンプトを入力します。 |
プロンプトの内容が画像生成のポイントになりますが、初めは難しく思うかもしれません。
そのためプロンプトの紹介サイトを参考にしながら、徐々に使い方覚えていきましょう。
プロンプトの書き方について詳しく知りたい方は、以下の記事をご参照ください。

また、生成画像のクオリティを高めるには、ネガティブプロンプトの設定が欠かせません。
プロンプトが、画像に含めたい要素をAIに指示する役割を果たすのに対し、ネガティブプロンプトには除外したい要素を指定します。
ネガティブプロンプトの詳細について知りたい場合は、以下の記事をご覧ください。

これらの情報を踏まえた上で、まずはDraw Thingsの基本操作に慣れてみましょう。
Draw Thingsの使い方:モデルを使用して画像を生成してみた
Draw Thingsを使用する際、基本的かつ強力な機能の一つが「モデル」です。
モデルを用いることで、特定のスタイルやテーマに基づいた画像を生み出せます。
ここでは、実際にモデルを使用して画像を生成する方法を解説します。
モデルを使用して画像を生成する
モデルを活用する手順をご紹介します。
まずはDraw Thingsに搭載されている、既存のモデルを活用する方法をご紹介します。
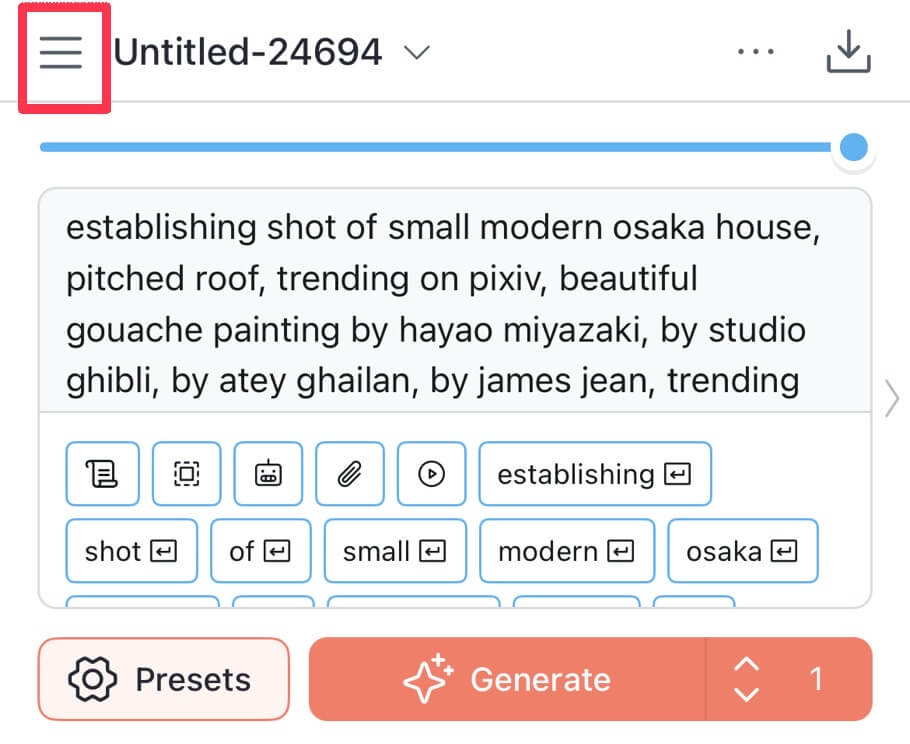 | ①画面左上のメニューをタップします。 |
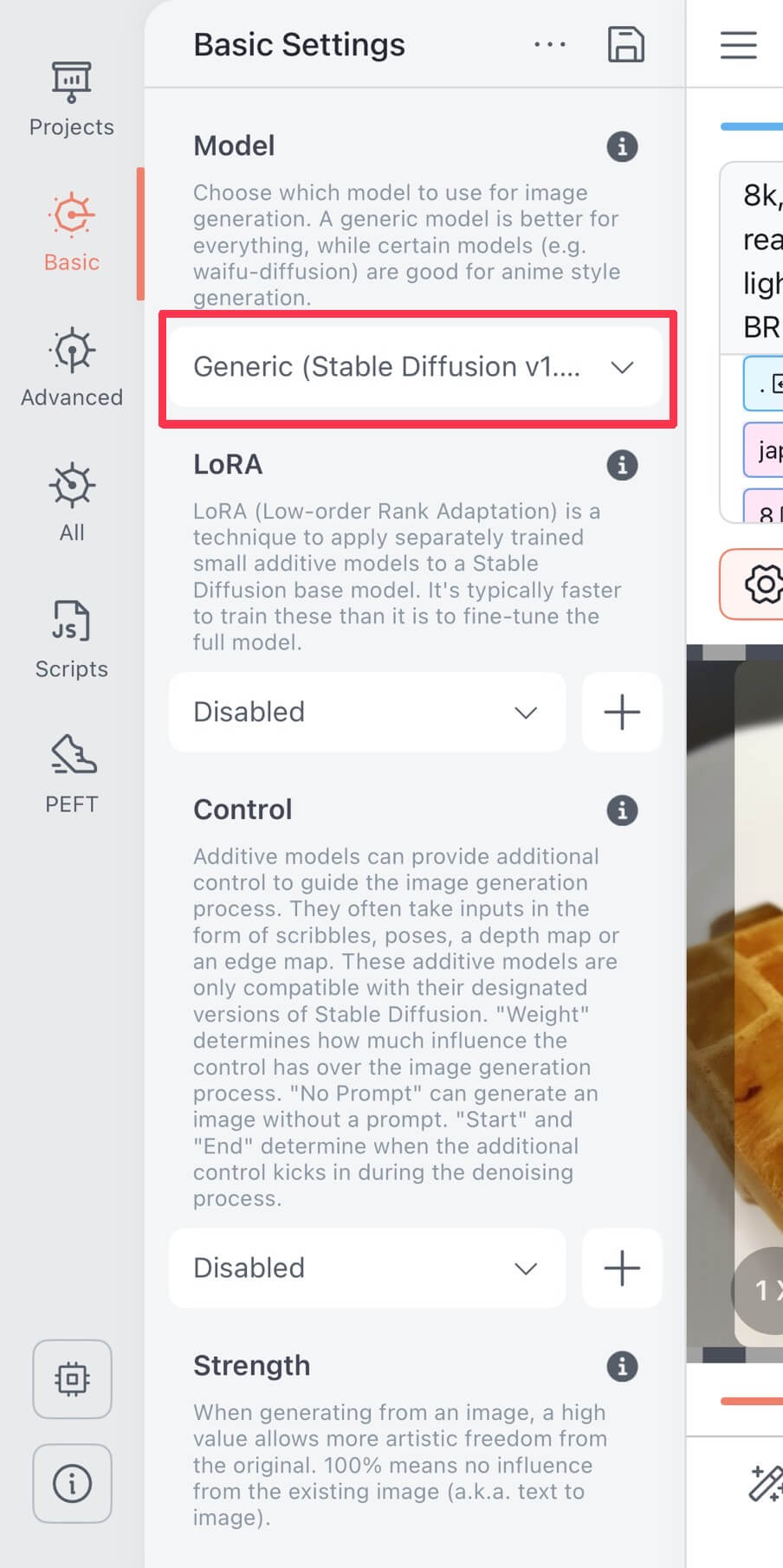 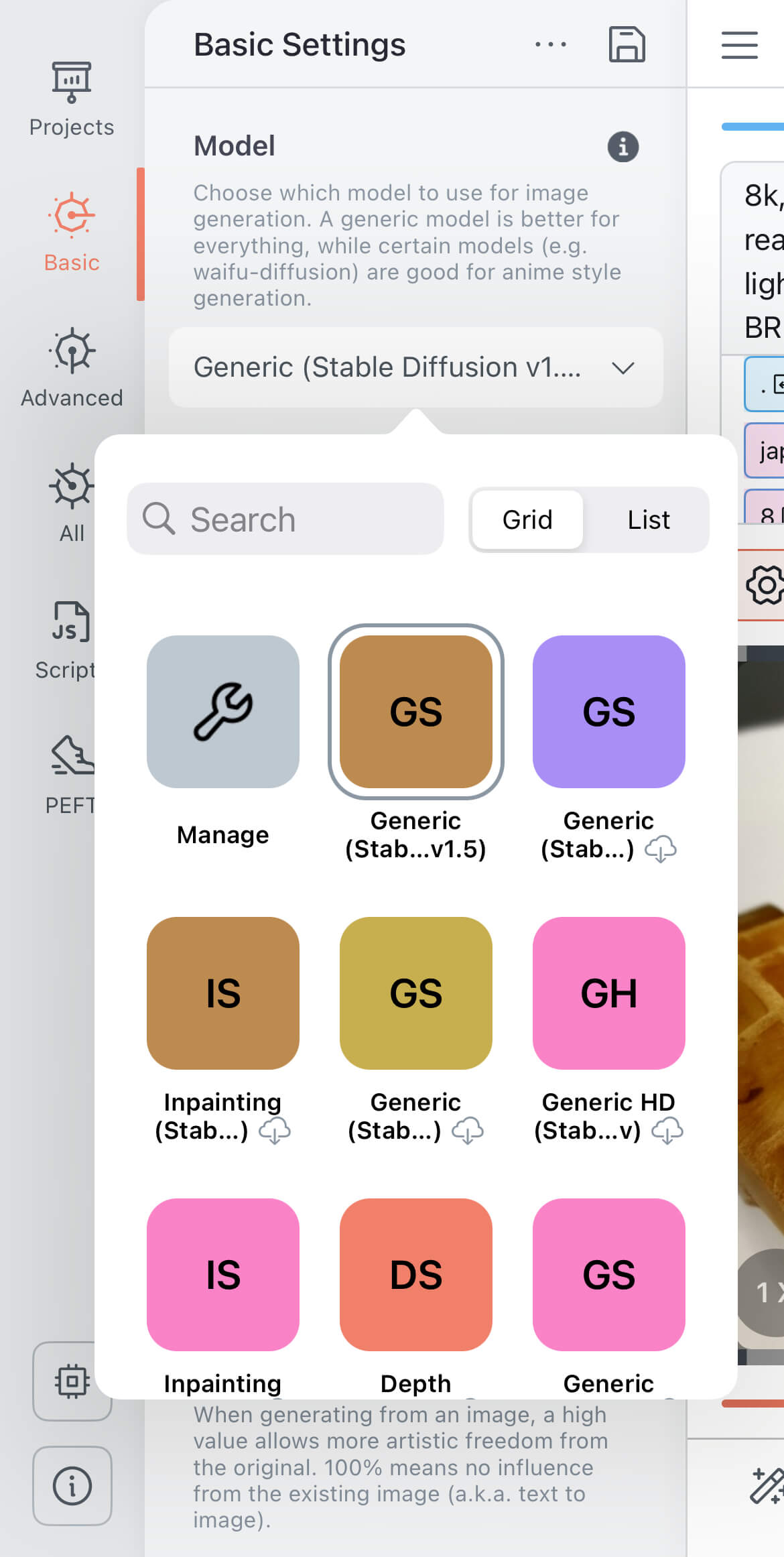 | ②「Model」という欄にあるプルダウンをクリックし、目的に合ったモデルを選びます。 モデルごとに特徴が異なり、画像生成のイメージが変わります。 |
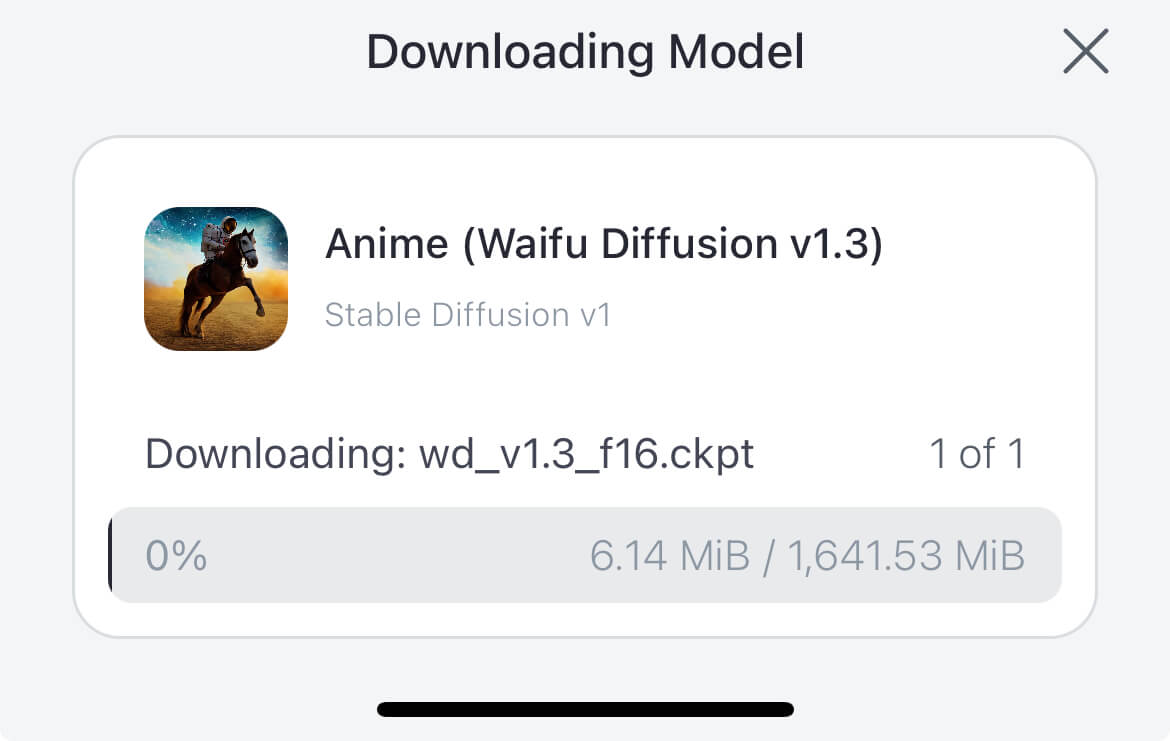 | ③モデルをダウンロードします。 新しいモデルを選択すると、その都度ダウンロードされ、容量を逼迫する恐れがあります。 ※一度ダウンロードしてしまえば、それ以降はいつでも利用可能です。 |
さらにDraw Thingsは、外部からダウンロードしたモデルをインストールして使うことが可能です。
CivitaiというStable Diffusionのモデルを共有しているサイトから、無料でダウンロードできます。
今回は以下の記事を参考に、アニメ系美少女のAI画像を生成する際に使われるモデル「Counterfeit-V3.0」を活用して画像を生成します。
それでは、Draw Thingsの外部モデルを活用する方法をご紹介します。
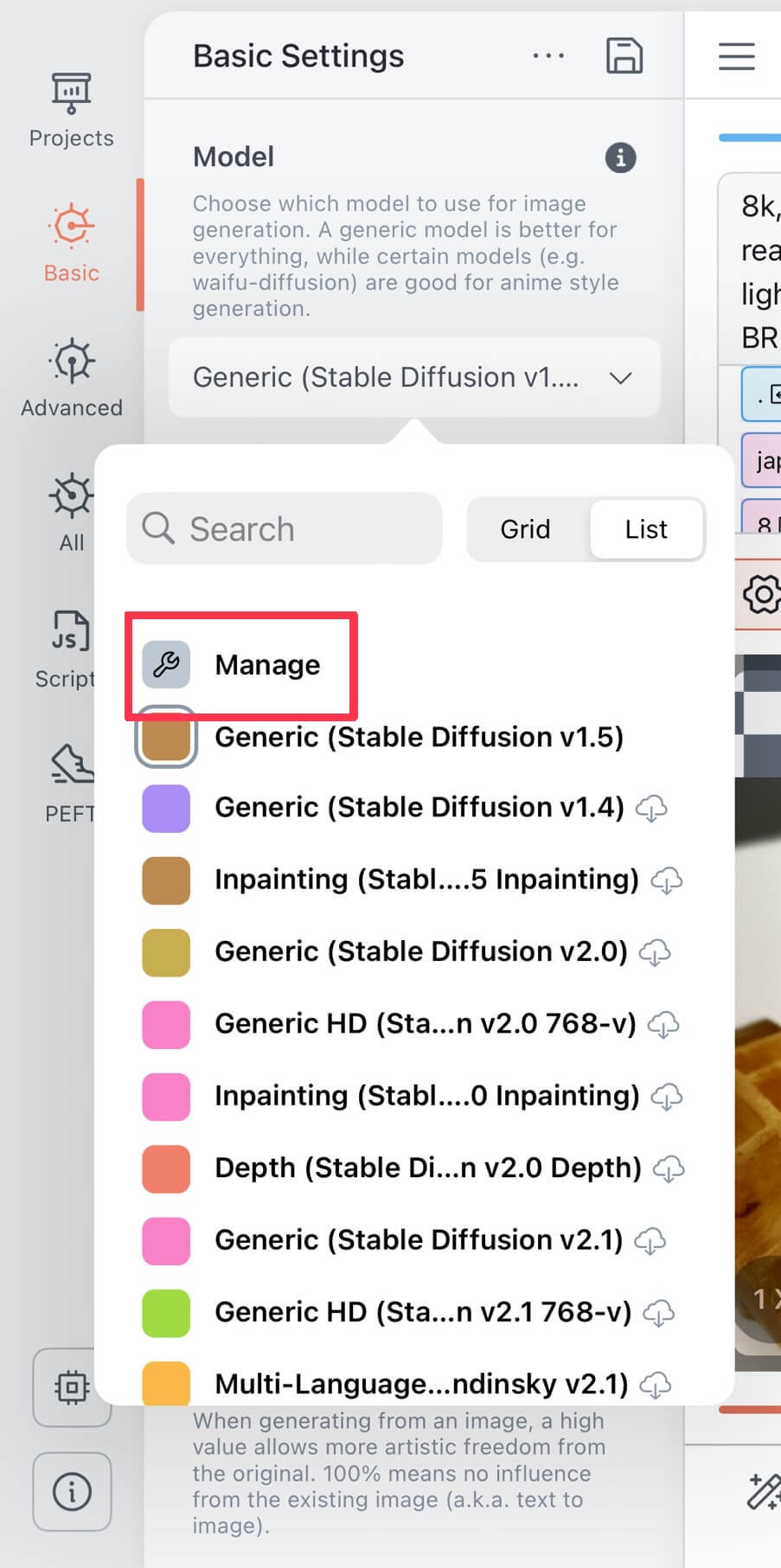 | ①モデル欄の「Manage」をクリックします。 |
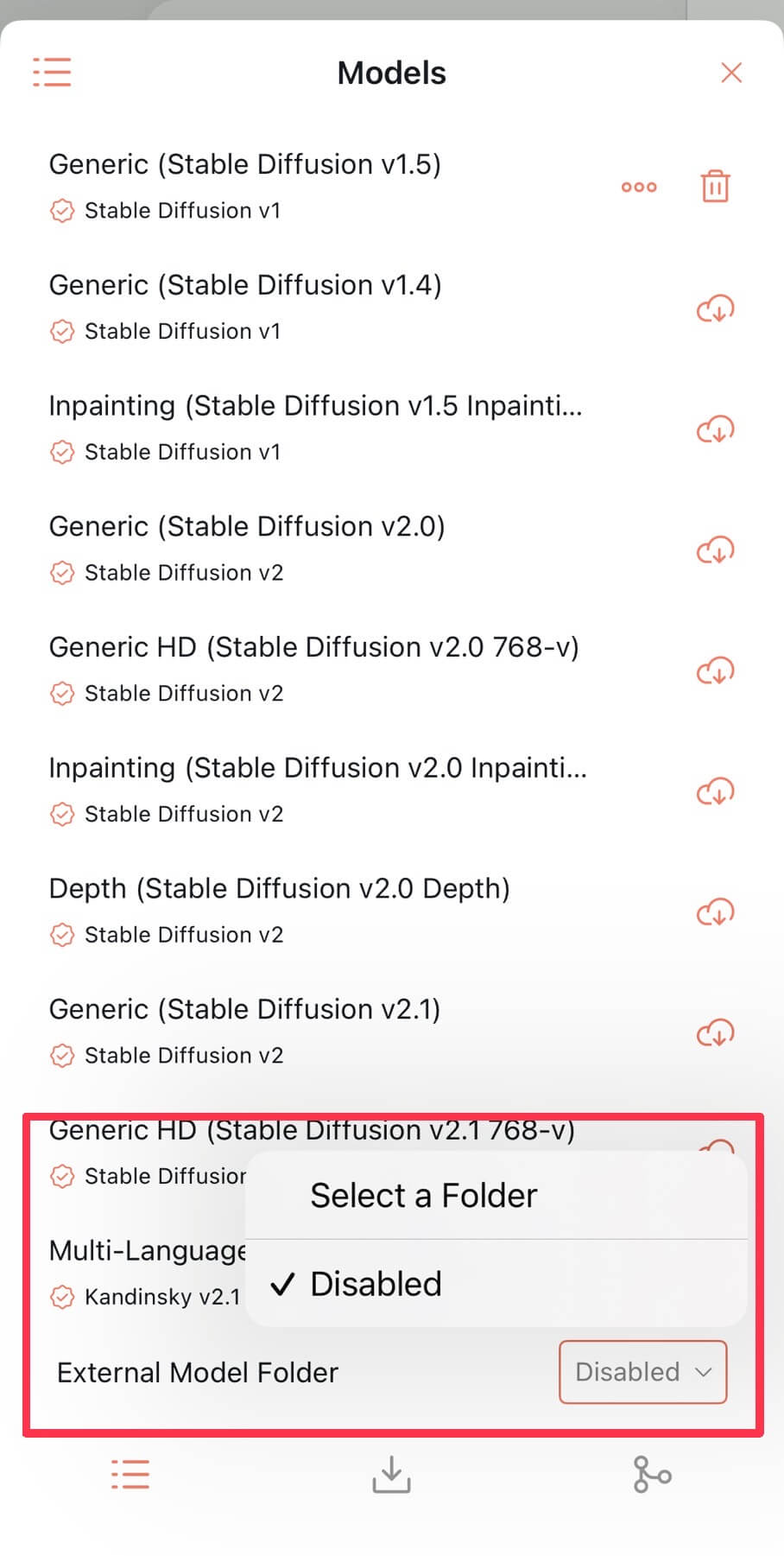 | ②モデルをインポートする ◇フォルダでモデルを追加する場合◇ ❶「Exteral Model Folder」のプルダウンを選択します。 ❷「Select a Folder」をクリックし、自身のフォルダから追加します。 |
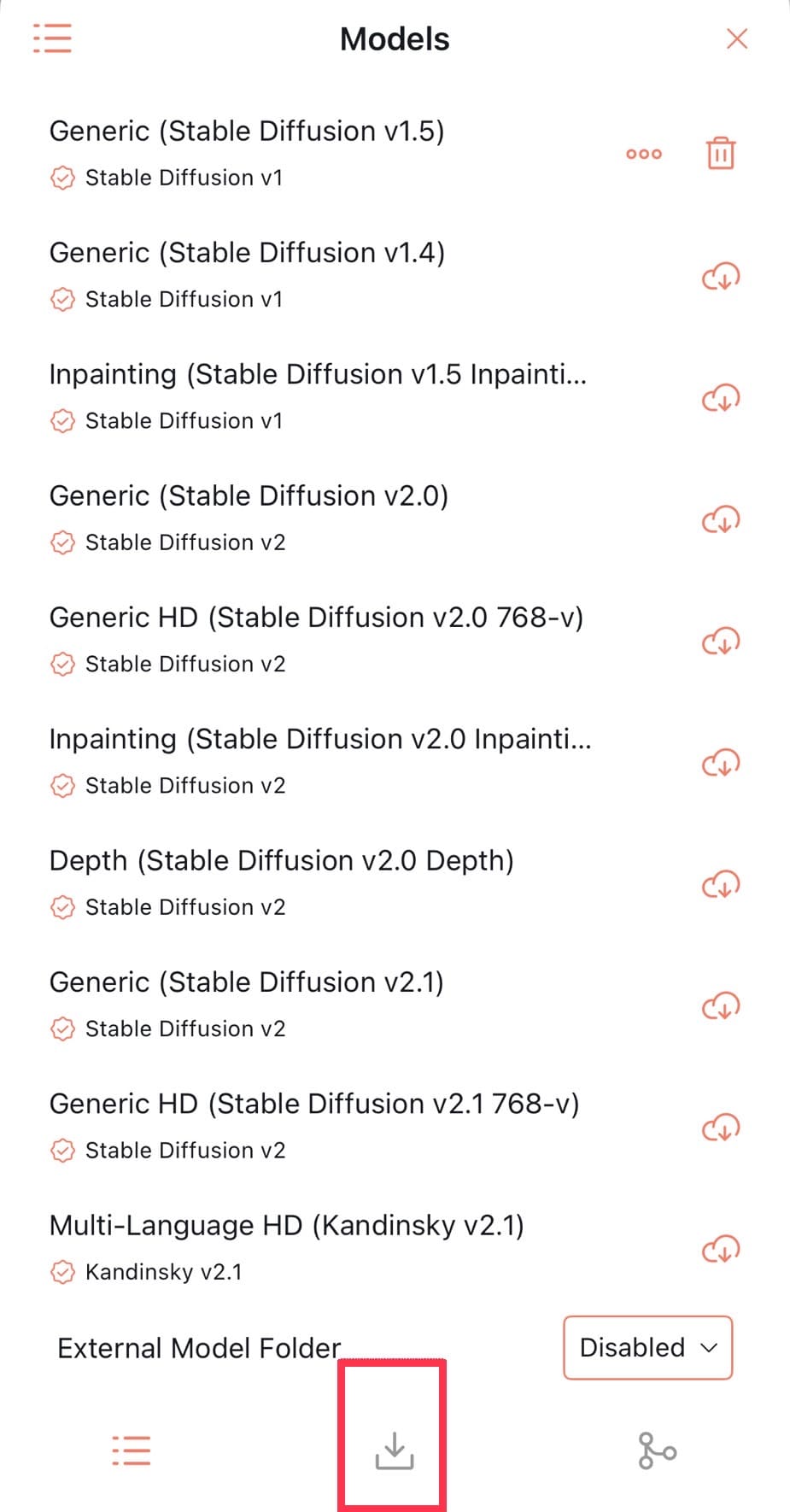 | ◇Civitaiのモデルを追加する場合◇ ❶赤枠部分のimportアイコンをクリックします。 |
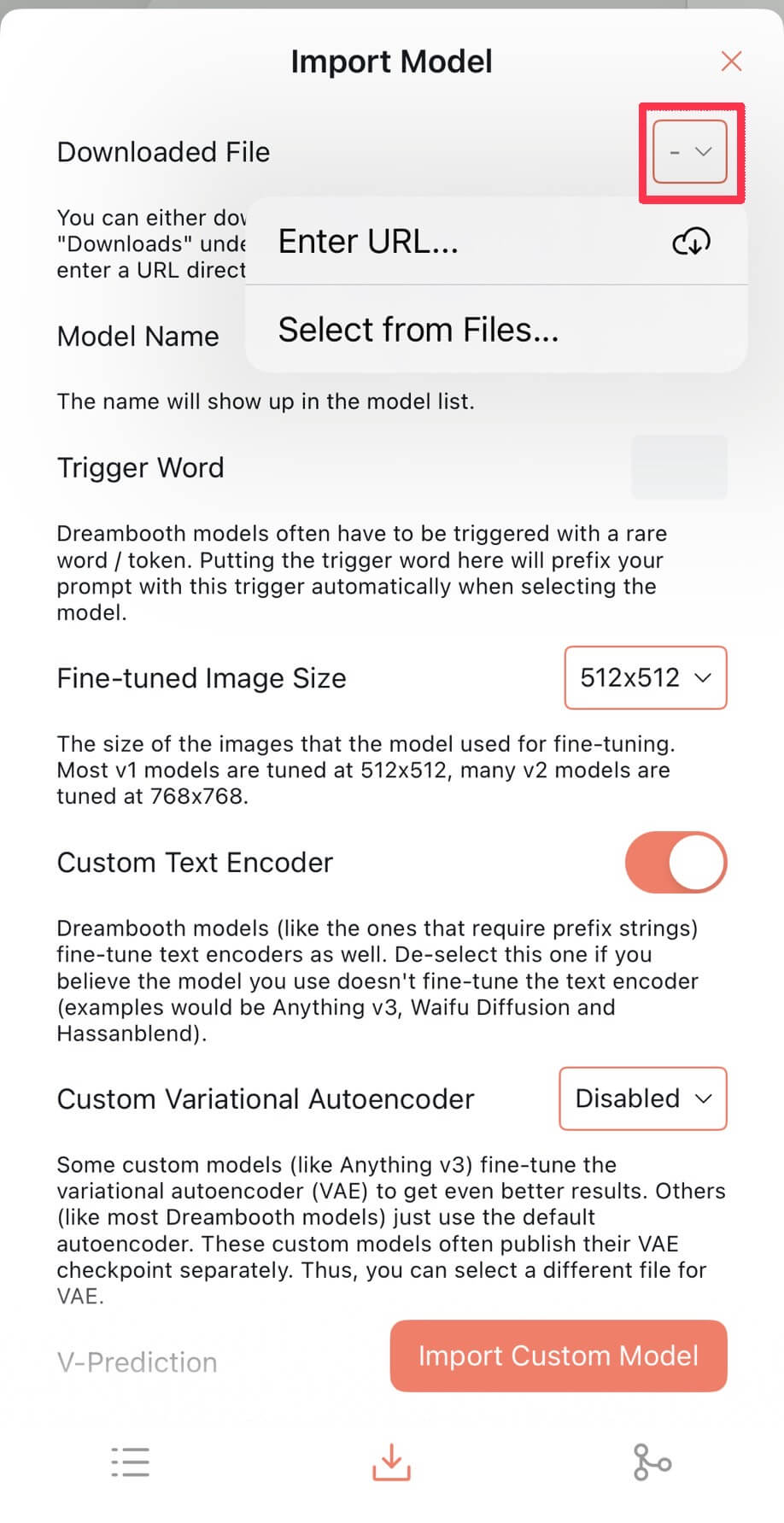 | ❷Download File欄のプルダウンをタップし、「Enter URL…」を選択します。 |
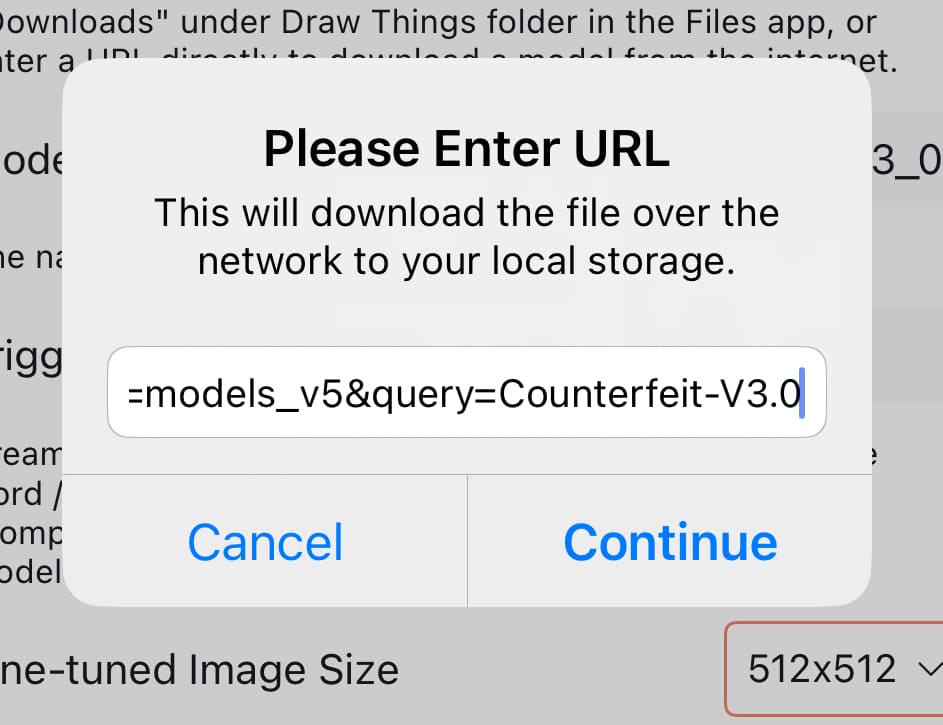 | ❸「Please Enter URL」というポップアップが表示されるので、空欄にURL(Civitaiのモデルの保存先)を貼り付けて「Continue」をクリックします。 するとダウンロードが開始されます。 |
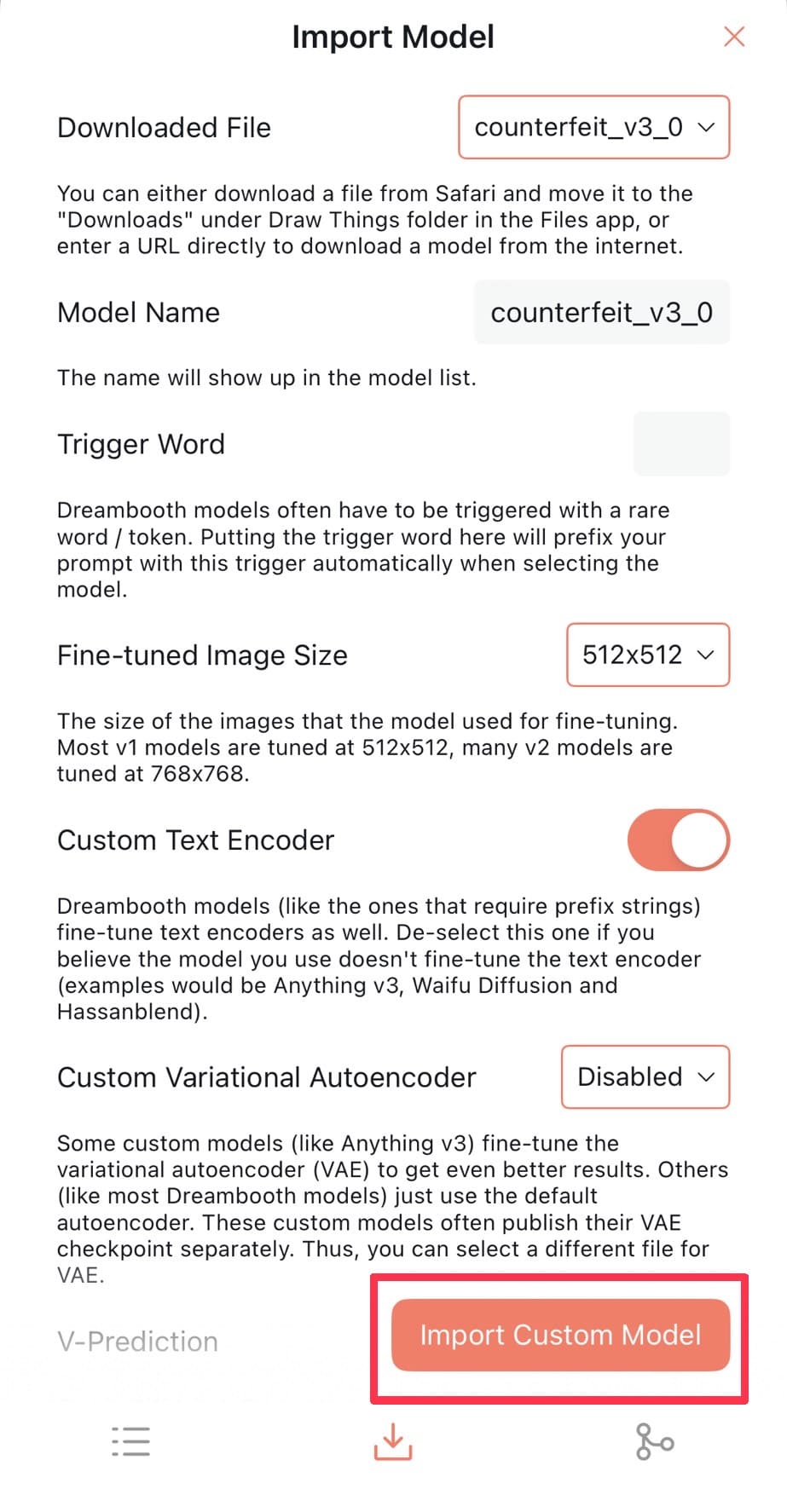 | ❹「Import Custome Model」ボタンをクリックし、対象のモデルをインポートします。 |
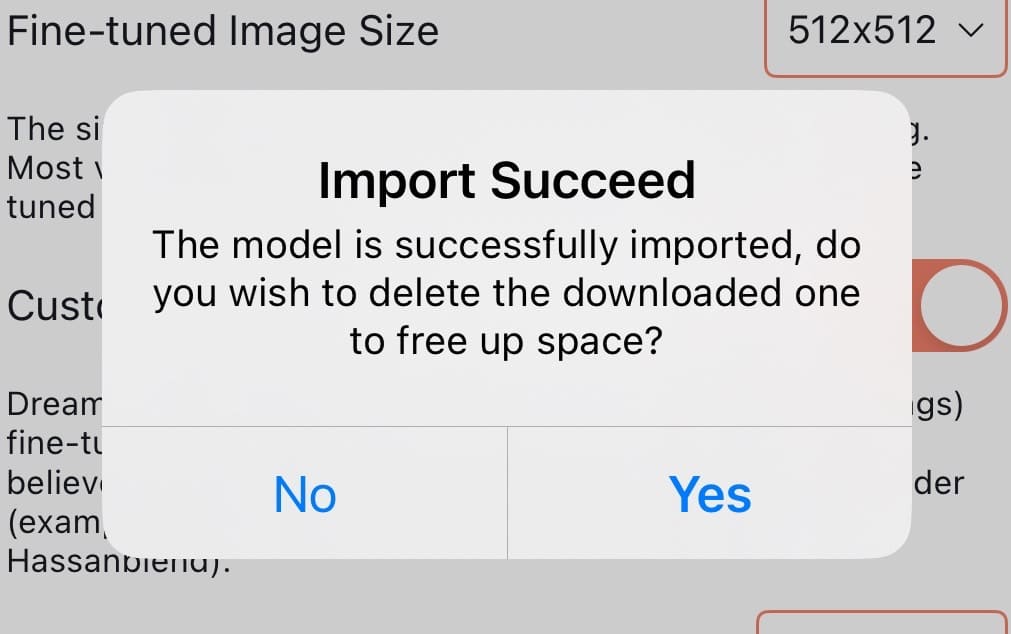 | ❺インポート完了後、「容量を空けるためにダウンロードしたモデルを削除しますか?」と確認されます。 問題なければ「Yes」を押してください。 |
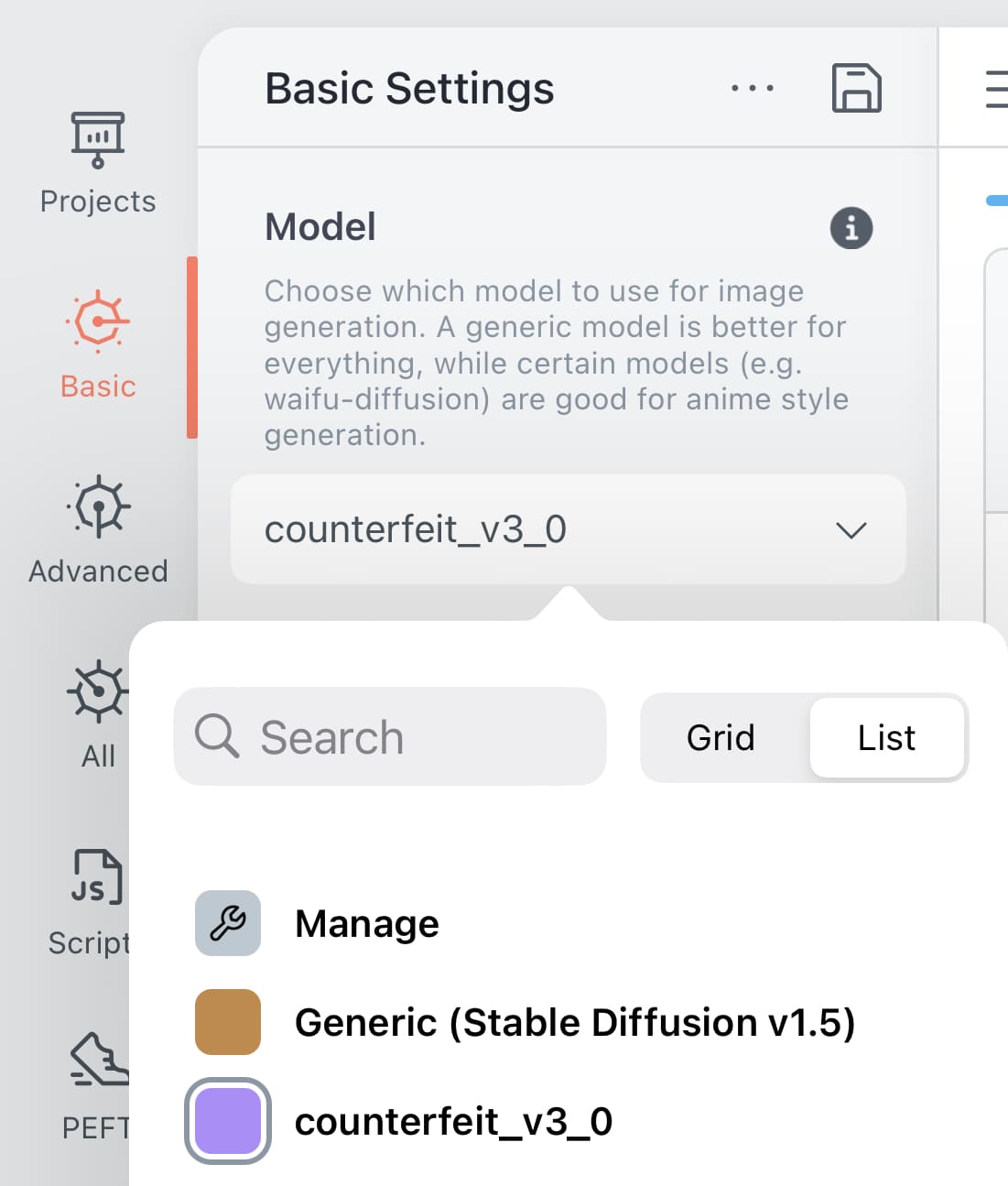 | ③設定画面に戻り、Modelの欄を見て「Counterfeit-V3.0」が選択されていることを確認します。 |
上記の通り、外部モデルを使えるように設定した後、以下のプロンプトを入力しました。
プロンプト
4k Fantasy-like illustration, anime-style beautiful girl, wearing a yukata, vibrant colors, detailed texture, cheerful expression, standing in a fantasy garden, high-quality illustration, elegant posture, soft lighting, detailed background, sakura petals, serene atmosphere, vivid and bright, detailed facial features, flowing hair, traditional Japanese yukata with modern twist, magical ambiance, in the style of popular anime illustrators
ネガティブプロンプト
Easy Negative
このプロンプトで生成された画像がこちらです。

このようにして、モデルを活用して画像生成できます。
LoRAを使用して画像を生成する
LoRA(Low-Rank Adaptation)は、モデルに追加学習を行わせて、モデルの性能を向上させる手法です。
従来の追加学習では、膨大の計算量をこなす必要がありコストがかかりましたが、LoRAは効率的に追加学習を行えます。
ここではLoRAを活用する手順を紹介します。
 | ①LoRA欄のプルダウンをタップします。 ②好みのLoRAをインストールします。 |
 | ③インストール完了後、LoRAが適切に設定されていることを確認します。 ④Weightを調整すると、LoRAの適用度合いが変化します。 |
LoRAにおいても、外部からダウンロードしたデータの活用が可能です。
モデルのインポート方法と同様で、LoRA欄のプルダウンを選択し、「Manage」をクリックする。→ importアイコンをクリックしてインストールするとできます。
Img2Imgを使用して画像を生成する
Draw Thingsでは、Img2Img機能を利用して、既存の画像をもとに新しい画像を生成できます。
この機能は、「画像+テキスト」のプロンプトを使用し、元の画像に追加したい要素や変更点をテキストで指示することが可能です。
プロンプトの知識が浅くても、基本となる画像があれば、完成度の高い画像を生成することができます。
それでは、Img2Imgの使い方を紹介します。
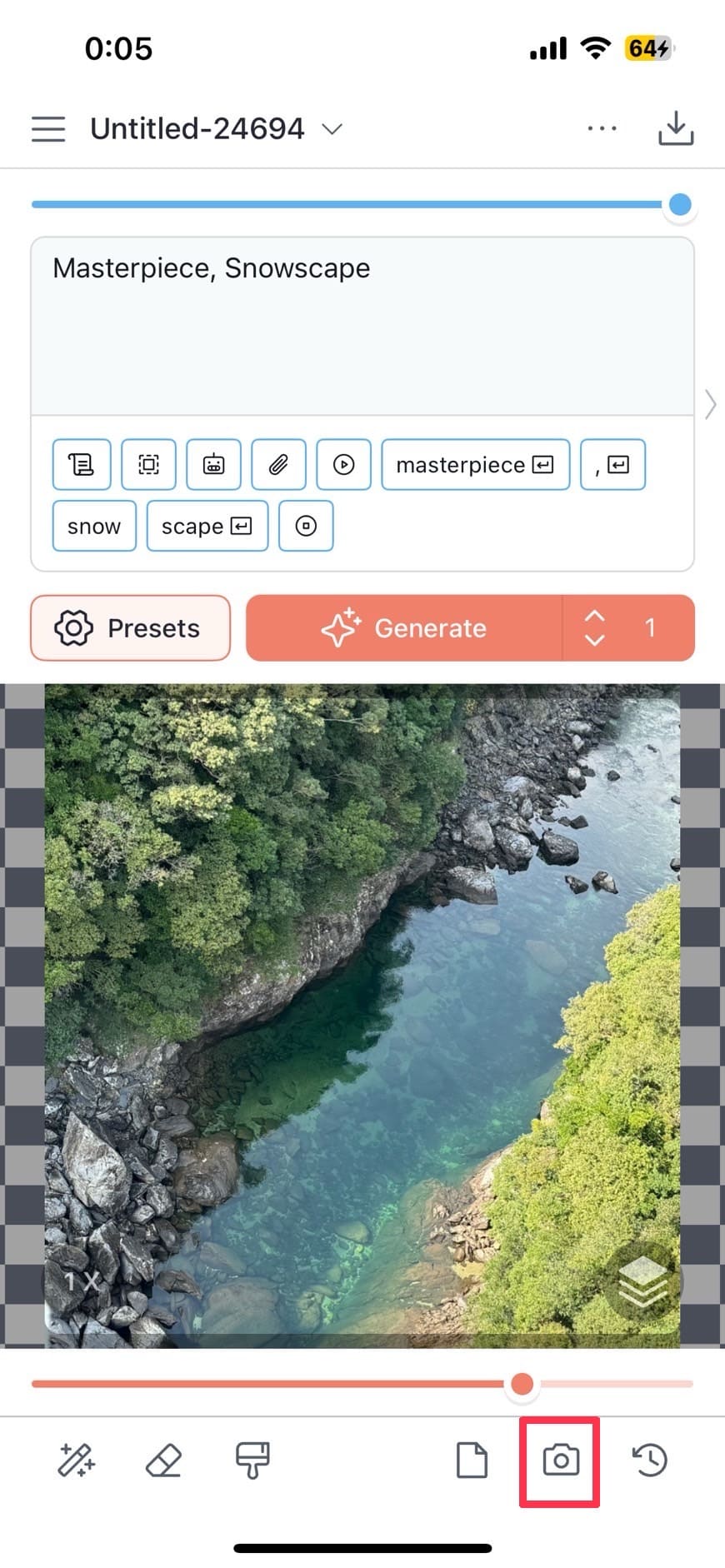 | ①画像とプロンプトを挿入する。 画像は、画面右下のカメラマークから挿入可能です。 |
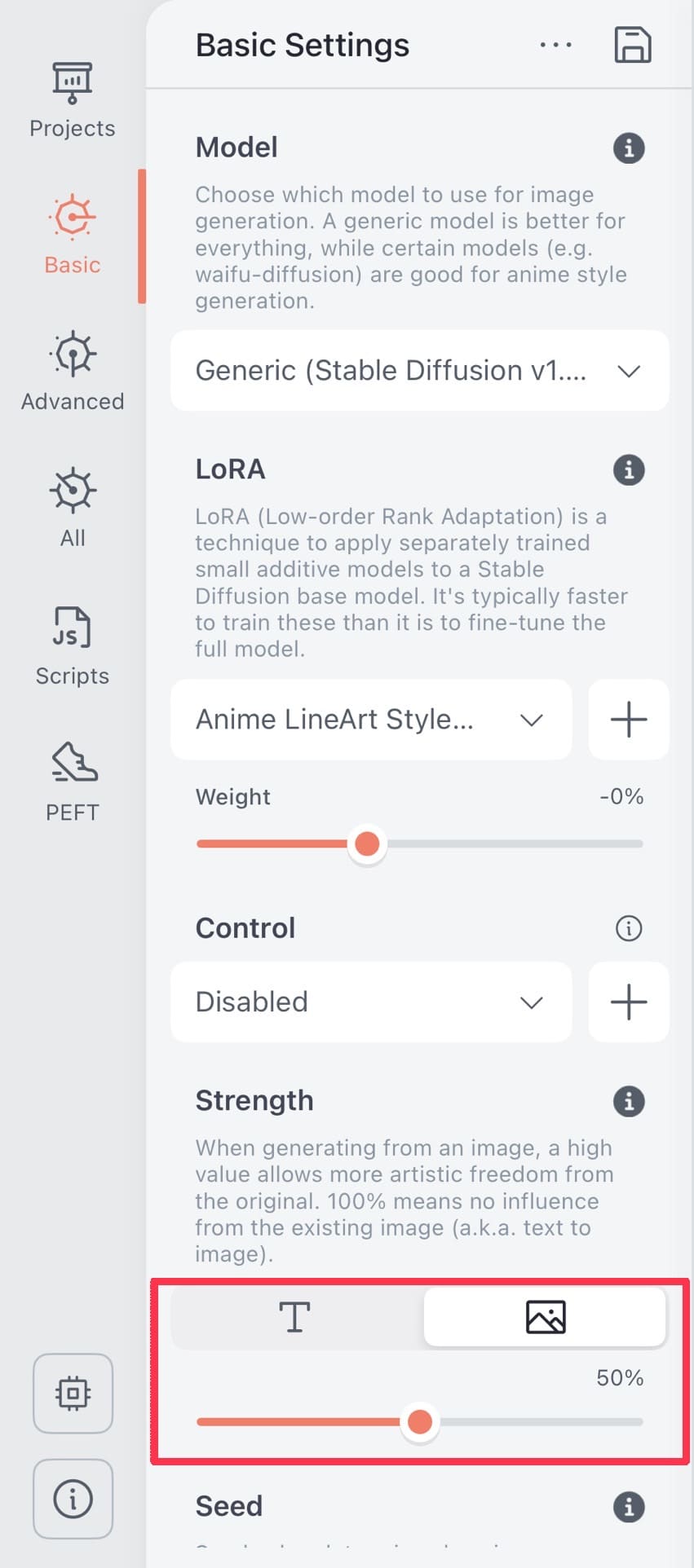 | ②メニュー内にある「Strength」の設定を変更します。 赤枠部分の「写真マーク」のタブを選択し、テキストと画像の指示の優先度を調整します。 数字が大きいほど、画像よりテキストの指示が優先されます。 |
 | ③「Generate」ボタンをクリックし、画像を生成します。 今回はテキストと画像の指示の強度を50%ずつに設定しましたが、微調整を繰り返し、いい塩梅を見つけてください。 |
モデルやLoRA、Img2Imgを利用した画像生成の手順をお伝えしました。
機能を知れば、あなたの想定通りの画像を生成できるようになるでしょう。
Draw Thingsで生成した画像の商用利用について
Draw Thingsで生成した画像は商用利用が可能です。
商用利用する場合は、著作権や肖像権の侵害に注意し、リスクを避ける必要があります。
商用利用時には、以下の2点に留意してください。
使用モデルのライセンス確認
Draw Thingsで生成した画像は、使用しているモデルによって商用利用の可否が異なります。
オープンソースで提供されているモデルは比較的自由度が高いですが、一部のモデルは、利用条件によっては商用利用が制限されます。
例えば、特定のアーティストによる作品を模倣するモデルは、著作権の問題が絡むため商用利用に制限がある場合があります。
商用利用が許可されているか、使用するモデルの利用規約を確認してください。
著作権の尊重
画像に有名人や特定のブランドが含まれる場合、著作権や肖像権を侵害していないか慎重に検討しましょう。
また、既存の画像をもとに生成する「Img2Img」を利用する際は、既存の画像が著作権を持っていないか、商用利用を許可しているのか確認する必要があります。
他者の著作物に「依拠性」や「類似性」が認められれば著作権の侵害になります。
著作権の侵害が懸念される場合には、著作者への許可を申請しましょう。
Draw Thingsの使い方まとめ
この記事では、Draw Thingsの特徴や画像生成の手順、そして商用利用する際の注意点についてご紹介しました。
この記事をまとめると
- Draw Thingsは、画像生成AI「Stable Diffusion」をベースにしたAI画像生成アプリ
- Draw Thingsは初心者でも利用しやすく、無料とは思えないほど豊富な機能で、幅広い層から活用されている
- 「モデル」、「LoRA」、「Img2Img」を活用した画像生成の手順
- 生成した画像を商用利用する場合は、利用条件を確認し、商用利用可能なモデルであること調査する必要がある
でした。
AI画像生成アプリ「Draw Things」を使うことで、誰でも手軽に、本格的に画像生成を楽しめます。
便利なアプリなので、ぜひ活用してみてください!
また、RomptnではAIに関する記事を多く掲載していますので、他の記事もぜひご覧ください。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

