
Gemma 4 12B が気になっても、自分の 16GB 級ノートPCでどこまで現実的に動くのかは発表文だけでは判断しにくいはずです。先に答えると、Gemma 4 12B は 「E4B では物足りないが 31B は重すぎる」層に刺さる、中間サイズの本命候補 です。
しかも text・image・audio をまとめて扱え、ローカル導入の入口も Transformers と LiteRT-LM の 2 本立てで用意されています。単なる新モデル紹介ではなく、何が新しく、16GB 訴求をどう読むべきか、どこから試し始めるべきかまで一気に整理できるのがこの記事の価値です。
この記事を読めば、12B の新しさ、16GB 級での現実ライン、E4B や 31B との選び分け、最初の試し方まで迷わず判断できます。
内容をまとめると…
Gemma 4 12Bは、text・image・audio を 16GB級ローカル環境で試したい人の本命候補
16GB訴求は「常に快適」の保証ではなく、unified memory と VRAM の違いを踏まえて読むべき
E4Bでは軽さ、31Bでは重さが気になるなら、12Bがいちばん判断しやすい中間点
最初の入口は Transformers か LiteRT-LM の 2択で十分、text から段階的に広げるのが安全
生成AIを「少し触って終わり」にせず、業務効率化・副業・AIエージェント活用までつなげたい方向けに、基礎から実践まで整理できる無料資料を用意しています。
記事とあわせて、AIに作業を任せる考え方や長く使える活用スキルを確認しておきたい方は受け取っておいてください。

Gemma 4 12Bはどんなモデル?
Gemma 4 12B は、Google DeepMind が公開している Gemma 4 ファミリーの中核サイズです。text だけでなく image と audio を扱える点が特徴で、軽量寄りの E4B と大型の 31B のあいだを埋める立ち位置にあります。
大切なのは、12B が単に「少し大きいモデル」ではないことです。公式の位置づけでも、ノートPCやデスクトップ、小規模サーバーで扱いやすいサイズとして整理されており、ローカル実行と実用性の両立を狙う読者に向いた選択肢になっています。
まずは「ローカルで試しやすく、しかも音声まで扱える Gemma」と理解しておくと、このあとの新しさや選び方をつかみやすくなります。
Gemma 4 12Bの何が新しい?
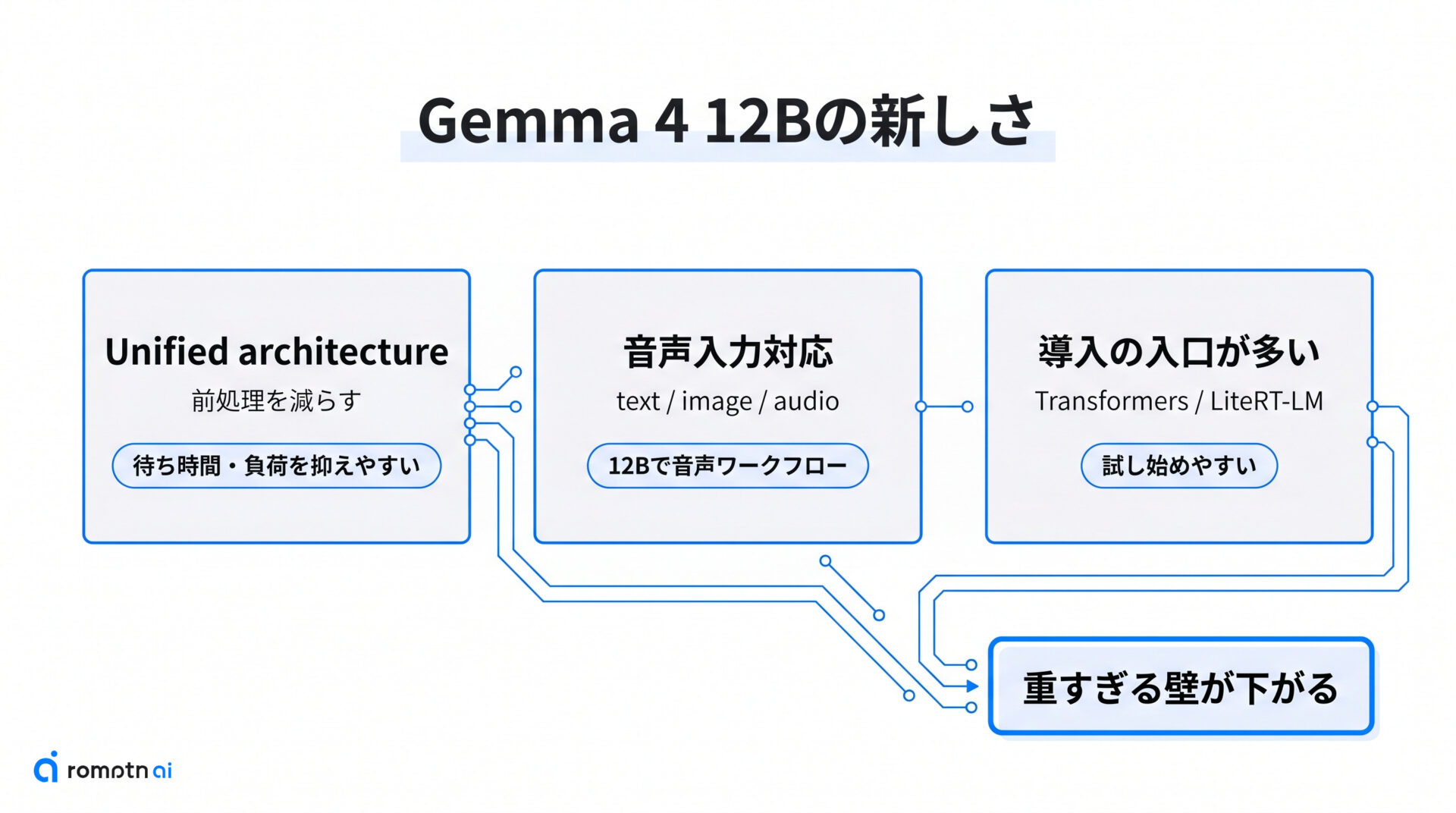
Gemma 4 12B の新しさは、12B という数字そのものよりも、ローカル実行の現実味を上げる設計がそろっている点にあります。読者目線で見ると、Unified architecture、medium-size での native audio input、そして公式に整ったローカル導入の入口という3つが大きな差です。
この3点がそろったことで、「高機能なマルチモーダルモデルは重すぎて手が出しにくい」という壁が下がりました。次の小見出しでは、それぞれが何を変えるのかを順番に整理します。
① Unified architectureで何が変わる?
従来の multimodal model は、画像や音声を別の encoder で変換してから言語モデルへ渡す構成が一般的でした。Gemma 4 12B はこの前処理をできるだけ減らし、画像パッチや音声波形を直接モデル側へ投影する Unified architecture を採っています。
読者にとってのメリットは、構成がシンプルになりやすく、ローカル実行で待ち時間やメモリ負荷を抑えやすいことです。技術用語だけだと難しく見えますが、「別の大きな部品を抱えずに、1つのモデルで multimodal を扱いやすくした」と捉えれば十分です。
② 音声入力対応でできること
12B は Gemma 系で初めて、medium-size のまま native audio input を受けられるモデルです。執筆時点では、text と image に加えて audio も扱え、音声認識や音声翻訳の用途まで公式に案内されています。
ここが大きいのは、軽量モデルだけでなく、もう一段余裕のある 12B でも音声を含むワークフローを組めることです。画像も見たいし音声も入れたいが、いきなり大型モデルまでは上げたくない読者にとって、12B の立ち位置が分かりやすくなります。
③ ローカル導入の入口が増えた理由
ローカルで試しやすい理由は、モデル本体だけでなく入口が整っていることにもあります。執筆時点では、公式 Hugging Face model card の Transformers 例で素直に触れますし、LiteRT-LM なら OpenAI 互換のローカル endpoint として立ち上げる流れも公式に案内されています。
つまり、「まずは Python で試す」「手元のツールやエディタから local API としてつなぐ」の2パターンが最初から選べます。モデルの新しさが、そのまま試しやすさにつながっている点は見落としにくいポイントです。
16GB級ノートPCで本当に動く?
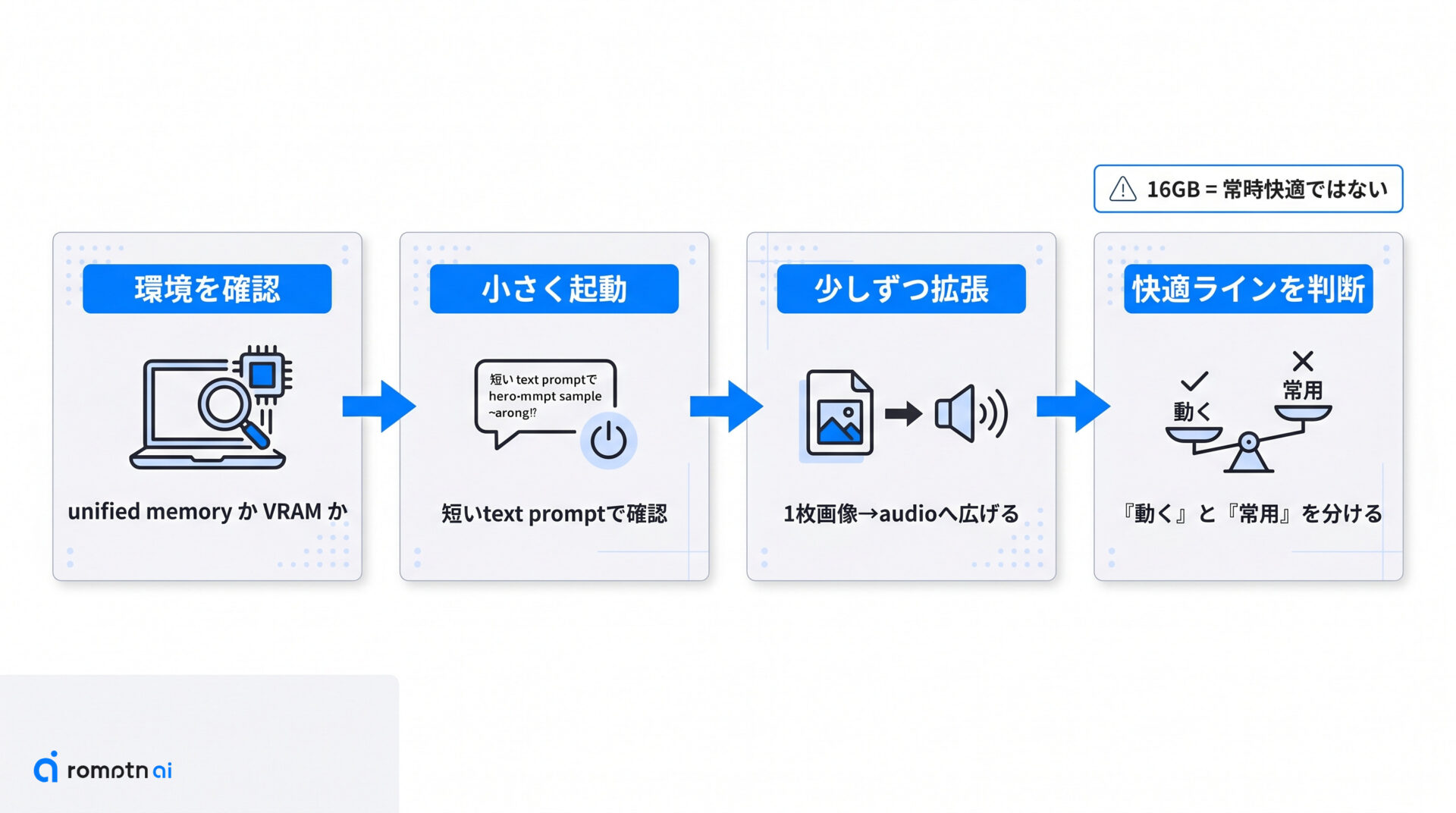
Google の 16GB 訴求は魅力的ですが、「16GB なら誰でも常に快適」という意味ではありません。公式文脈では consumer laptop で動かせるサイズ感を示しており、Apple Silicon の unified memory と dGPU ノートPCの VRAM では読み方が少し変わります。
目安としては次の整理が分かりやすいです。
- unified memory のノートPCでは、ローカルで multimodal を試す現実的な入口として見る
- dGPU ノートPCでは、16GB VRAM 級を一つの目安にしつつ、入力の長さや modality が増えるほど余裕は減る
- 最初は短い text prompt や 1 枚画像の確認から始めて、動作と応答の重さを見ながら広げる
大切なのは、「動く可能性が高いサイズ」と「常用して快適な設定」を分けて考えることです。12B の魅力はその境界を下げた点にありますが、無条件に余裕があると決めつけない方が実運用では安全です。
Gemma 4の他サイズとどう選ぶ?
Gemma 4 を選ぶときは、数字の大きさだけでなく「どこで動かすか」「audio まで必要か」で見ると判断しやすいです。
| まず見るサイズ | 向いている場面 | 考え方 |
|---|---|---|
| E4B | できるだけ軽く試したい | mobile / edge 寄りで、まず動かすことを優先したい人向け |
| 12B | ノートPCで multimodal を実用ラインまで試したい | text・image・audio をまとめて扱いたい人の本命 |
| 31B | より大きな計算資源で品質を優先したい | workstation や server 寄りで、重さを許容できる人向け |
迷ったら、「E4B では物足りないが 31B までは重すぎる」ところに 12B が入ると覚えておけば十分です。特に audio を含めたローカル用途を想定するなら、12B を先に検討する価値があります。
最初に試すならどの方法?
最短で触るなら、Python に慣れている人は Transformers から始めるのが素直です。公式 model card の読み込み例をそのまま使えるので、まずは短い prompt で text 応答を確認し、次に image や audio を足す流れが分かりやすくなります。
一方で、手元のエディタや agent tool から local API として使いたいなら LiteRT-LM が合います。serve で OpenAI 互換 endpoint を立てられるので、既存の開発フローに差し込みやすいからです。
最初から全部の modality を盛るより、「text だけで起動確認 → image 追加 → audio 追加」の順で広げる方が失敗しにくいです。これなら自分の環境でどこまで現実的かも早めに見極められます。
よくある質問
- QGemma 4 12Bは画像だけでなく音声も入力できますか?
- A
できます。執筆時点では、公式 docs と model card の両方で 12B は text と image に加えて audio も扱えると案内されています。音声認識や音声翻訳まで公式 capability として示されているため、画像理解だけのモデルとして見ると特徴を見落とします。
- Q16GBメモリなら誰でも快適に動かせますか?
- A
そこは分けて考えるのが安全です。Google の訴求は「16GB 級の consumer laptop でも試しやすいサイズ」という意味合いが強く、実際の余裕は unified memory か VRAM か、text だけか image や audio も使うかで変わります。まずは短い入力で動作確認し、そこから広げる方が失敗しにくいです。
- QE4Bと12Bで迷ったら、どちらを選ぶべきですか?
- A
まず動かす軽さを優先するなら E4B、ノートPCで multimodal をもう少し実用ラインまで使いたいなら 12B が向いています。特に audio まで含めたローカル用途を想定していて、E4B では物足りなさが気になるなら 12B を先に検討すると判断しやすいです。
- Qローカルで試すならTransformersとLiteRT-LMのどちらが簡単ですか?
- A
Python に慣れているなら Transformers が分かりやすく、既存ツールから local API として使いたいなら LiteRT-LM が手早いです。前者は公式の読み込み例をそのまま追いやすく、後者は OpenAI 互換 endpoint としてつなぎやすいのが違いです。
まとめ:Gemma 4 12Bは「16GB級で試したい人」の本命候補
Gemma 4 12B は、「ローカルで multimodal を試したいが、いきなり大規模モデルには行きたくない」という読者に向くモデルです。
- text・image・audio をまとめて扱える中間サイズ
- 16GB級ローカル実行の訴求があり、ノートPC環境でも検討しやすい
- E4B より余裕が欲しく、31B までは重すぎる読者にちょうどよい
- Transformers と LiteRT-LM の入口があり、試し始めやすい
まずは自分の環境で短い text prompt から起動確認し、必要なら image や audio を足していくのが現実的です。そこで物足りなければ E4B や 31B と比べれば、12B が自分の用途に合うか判断しやすくなります。
AIを実務で使い続けるには、ツール名を覚えるだけでなく、目的を分解し、文脈を渡し、出力を評価する力が必要です。AI副業やAIエージェント活用の入口をまとめた資料セットを無料で受け取れます。
無料資料を受け取る

