
「参照画像を渡せば、同じ顔・同じ商品をそのまま動画にできる」と聞いて使い始めたのに、最初の一手で止まっていませんか。画像1はキャラ、画像2は服装、画像3は背景、と枠が決まっていると思い込むと、何を入れれば何が固定されるのかが分からなくなります。
Veo の Ingredients to Video は、執筆時点では最大3枚の参照画像を、自分で役割を決めて自由に渡せる仕組みです。服装専用の枠も、3枚目が必ず背景になる決まりもありません。この本当の仕組みをつかむだけで、ショットをまたいでも崩れない人物・商品・世界観を狙って作れるようになります。
この記事を読み終えるころには、自分が触る経路(Flow / Gemini アプリ / API)を選び、人物・商品・背景それぞれに画像を割り当て、役割を結ぶプロンプトで最初の一本を生成し、顔ブレが出ても直せる状態まで到達できます。
内容をまとめると…
参照画像は固定スロットではなく、最大3枚を自分で役割を決めて渡す柔軟な仕組み
服装専用の枠は無く、人物・商品・背景のどれを揃えたいかで画像の割り当てを組み替える
経路は使い方で選ぶ。作り込むなら Flow、手軽に試すなら Gemini アプリ、自動化なら API
崩したくないものを決める画像を先頭に置き、各画像の役割をプロンプトで名指しすると一貫性が上がる
顔ブレや崩れは、参照画像の差し替えと Flow の Insert / Remove で後から立て直せる
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Ingredients to Videoとは?まず誤解を解く
Ingredients to Video は、自分で用意した参照画像から動画を生成できる Veo 3.1 の機能です。ここではまず、この機能が何をするものなのかをはっきりさせます。
核になるのは、複数のショットをまたいでも同じ顔・同じ商品を一貫して保てることです。従来の AI 動画では、シーンが切り替わるたびに人物の顔つきや物の形が少しずつ別物になりがちでした。
参照画像は、執筆時点では最大3枚まで渡せます。たとえば人物の写真と、舞台になる場所の写真と、仕上がりの雰囲気を示す一枚、というように組み合わせて使えます。
ここで多いのが、「画像1はキャラ、画像2は服装、画像3は背景を固定する決まった枠」という思い込みです。実際はそうした固定スロットではなく、何を渡すかを自分で決められる柔軟な仕組みです。
服装専用の枠があるわけでも、3枚目が必ず背景になるわけでもありません。それぞれの画像が動画の中で何を担うのかは、次の章で正確に整理します。
まずは「最大3枚を柔軟に渡せる機能」という土台を押さえてください。
参照画像3枚は何を固定するのか
ここでは、渡した画像が動画の中で「何を担うのか」を整理します。決まった枠に当てはめるのではなく、よくある役割で考えると割り当てに迷いません。
参照画像は、執筆時点では最大3枚まで渡せます。実際の使い方として多いのは、次の3つの役割を1枚ずつに割り当てるパターンです。
- 被写体(キャラ) — 動画に登場させたい人物や商品の見た目。同じ顔・同じ形を保つ軸になります。
- 環境(背景) — どんな場所・舞台で動くか。世界観やロケーションを揃えます。
- スタイル(画調) — 色味や質感、全体の雰囲気。仕上がりのトーンを寄せます。
ただしこれは固定された枠ではなく、あくまで「よくある分け方」です。3枚すべてを同じ人物の別角度の写真にして見た目をよりしっかり揃えたり、商品だけを複数枚渡したりもできます。
何を固定したいかを先に決め、その軸になる画像を起点に残りを足す。この考え方が、後ほどの用途別の割り当てでもそのまま効いてきます。
どの経路にこの機能があるか

この機能は1つのアプリ専用ではなく、複数のGoogleのサービスから使えます。読者がまず触る入口はFlow・Geminiアプリ・Gemini API の3つで、ほかにVertex AIやGoogle Vids、YouTube向けの面でも提供されています。
どれを選ぶかは、やりたいことで決めると迷いません。3つの主な入口を、向いている使い方で並べると次のようになります。
- Flow — 動画を作り込み、生成後の手直しまでしたい人向けの制作寄りの入口です。
- Geminiアプリ — まず手軽に試してみたい人向けの、いちばん始めやすい入口です。
- API — 自分のツールやサービスに組み込み、自動で動かしたい人向けの入口です。
それぞれの開き方と始め方は、続く3つの章で順番に見ていきます。
経路ごとの細かな違い、たとえば対応する解像度や利用に必要な条件は、後ほどの『経路別の違いを早見表で比較』でまとめて確認できるようにします。まずは「自分はどの入口から入るか」をここで決めておきましょう。
①Flowで使う
Flow は Google が映像制作向けに用意したツールで、labs.google/flow からブラウザで開けます。Ingredients to Video は、この Flow を使う経路がもっとも作り込みの自由度が高く、ショットをつないで一本の映像に仕上げたい人に向いています。
始め方はシンプルです。Flow を開いたら、参照画像を渡すための入口(Ingredients や参照画像の追加)を選び、固定したい顔・商品・世界観の画像を最大3枚まで足します。枠は役割ごとに分かれておらず、服装専用といった決まったスロットはありません。3枚を柔軟に割り当てられるのが基本です。
画像を入れたら、プロンプトで「どの画像が何を担うのか」を文章で結びつけます。あとは生成を実行すると、Veo 3.1 がその参照をもとに動画を作ります。
Flow には、生成後の映像に要素を足す Insert、不要なものを消す Remove、続きを伸ばす Extend といった編集ツールも備わっています。一発で決まらなくても、後から手を入れて整えられるのが Flow を選ぶ理由のひとつです。生成後にうまくいかないときの直し方は、後ほどの専用の章でまとめて扱います。
画面の表記は更新されることがあるため、ボタン名が記事と少し異なる場合は、近い意味の項目を探してください。経路ごとにできることの対応は、後ほどの早見表を参照してください。
②Geminiアプリで使う
スマホひとつで思い立ったその場で試したいなら、Gemini アプリ(スマホ/ブラウザ)が一番手軽な入口です。アプリ内の動画生成メニューを開き、参照画像を添えてプロンプトを書けば、そのまま Veo で生成へ進めます。
手順はシンプルで、おおむね次の流れです。
- アプリの動画生成の入口を開く
- 参照画像(最大3枚まで)を添付する
- 作りたい内容をプロンプトで指定して生成する
メニュー名やボタンの位置は更新で変わることがあるため、迷ったら「動画」「ビデオ」に関する項目を探してください。縦長の画面でそのまま作れるので、ショート動画など縦型の素材づくりとも相性がよく、執筆時点では縦型の出力にも対応しています。
ただし Gemini アプリでの Veo 動画生成は、執筆時点では有料プランの利用が前提になります。上位の有料プランほど生成の上限が高くなり、無料・お試し枠は限られるため、自分に必要な水準は後ほどの『経路別の違いを早見表で比較』の章で確認してください。
③APIで使う
3つ目は、Gemini API や Vertex AI から動画生成をプログラムで呼び出す経路です。画面をクリックして1本ずつ作るのではなく、自分のアプリやスクリプトに組み込んで自動で動かしたい開発者向けの入口になります。
使い方の発想は他の経路と同じです。プロンプトと参照画像(執筆時点では最大3枚まで柔軟に渡せます)をリクエストとして送ると、生成された動画が結果として返ってきます。「服装専用の枠」のような固定スロットはなく、どの画像をどの役割に使うかは前の章で見たとおりプロンプト側で決めます。
バッチ生成や既存サービスへの組み込みなど、繰り返しの処理を自動化したいときにこの経路が活きます。仕上げの解像度を上げる4Kアップスケールも、この経路で扱えます。
この経路の利用には API のアクセス権とキーが必要で、料金は通常の Gemini プランとは別に API の利用量に応じて課金される点だけ押さえておきましょう。詳細なパラメータや料金体系は公式ドキュメント(ai.google.dev/gemini-api/docs/video)を参照してください。経路ごとの対応範囲の違いは、次の章の早見表でまとめて見比べられます。
経路別の違いを早見表で比較
ここまで見てきた3つの経路は、同じ Ingredients to Video でも使える機能と利用条件が少しずつ違います。自分がどこで使うかを決める前に、まず一覧で押さえておきましょう。
参照画像を最大3枚まで渡せる点と、渡した画像で同じ人物や被写体の一貫性を保てる点は、どの経路でも共通です。違いが出るのは、縦型動画への対応や高解像度への引き上げ、生成後の手直し、そして使い始めるための条件です。
| 観点 | Flow | Gemini アプリ | API・Vertex AI |
|---|---|---|---|
| 向いている用途 | 連続ショットの物語制作・後から手直しまで作り込む | まず手軽に試す・単発で作る | 自動化して大量に回す・自社サービスへ組み込む |
| 参照画像の枚数 | 最大3枚 | 最大3枚 | 最大3枚 |
| 縦型(9:16)対応 | 執筆時点では対応 | 執筆時点では対応 | 執筆時点では対応 |
| 解像度の引き上げ(4K) | 対応 | 非対応 | 対応 |
| 生成後の手直し | Insert / Remove / Extend で部分的に直せる | 基本は作り直し | 基本は作り直し(コード側で再実行) |
| 利用条件・料金 | 有料プラン前提(上位プランほど上限が高い) | 有料プラン前提(無料・トライアル枠は限定的) | 従量課金(使った分だけ支払う) |
| 自動化 | 画面操作が中心 | 画面操作が中心 | コードから呼べる |
利用条件は経路ごとに考え方が異なります。Flow と Gemini アプリは Google の有料プラン(AI Pro / AI Ultra)が前提で、上位の AI Ultra ほど生成上限が高く、AI Pro はお試し寄りの位置づけです。無料・トライアル枠は限定的なので、本格的に使うなら有料プランを見込んでおくと安心です。一方、API・Vertex AI は使った分だけ支払う従量課金で、自動化や大量生成に向きます。
具体的な金額や生成上限は更新が早いため、本文では細かい数字を断定せず、契約前に各サービスの公式ページで最新の条件を確認してください。自分の用途が「連続した物語を作り込む」なら Flow、「とにかく手軽に試す」なら Gemini アプリ、「自動化したい」なら API、という分け方が出発点になります。
参照画像の渡し方と基本手順
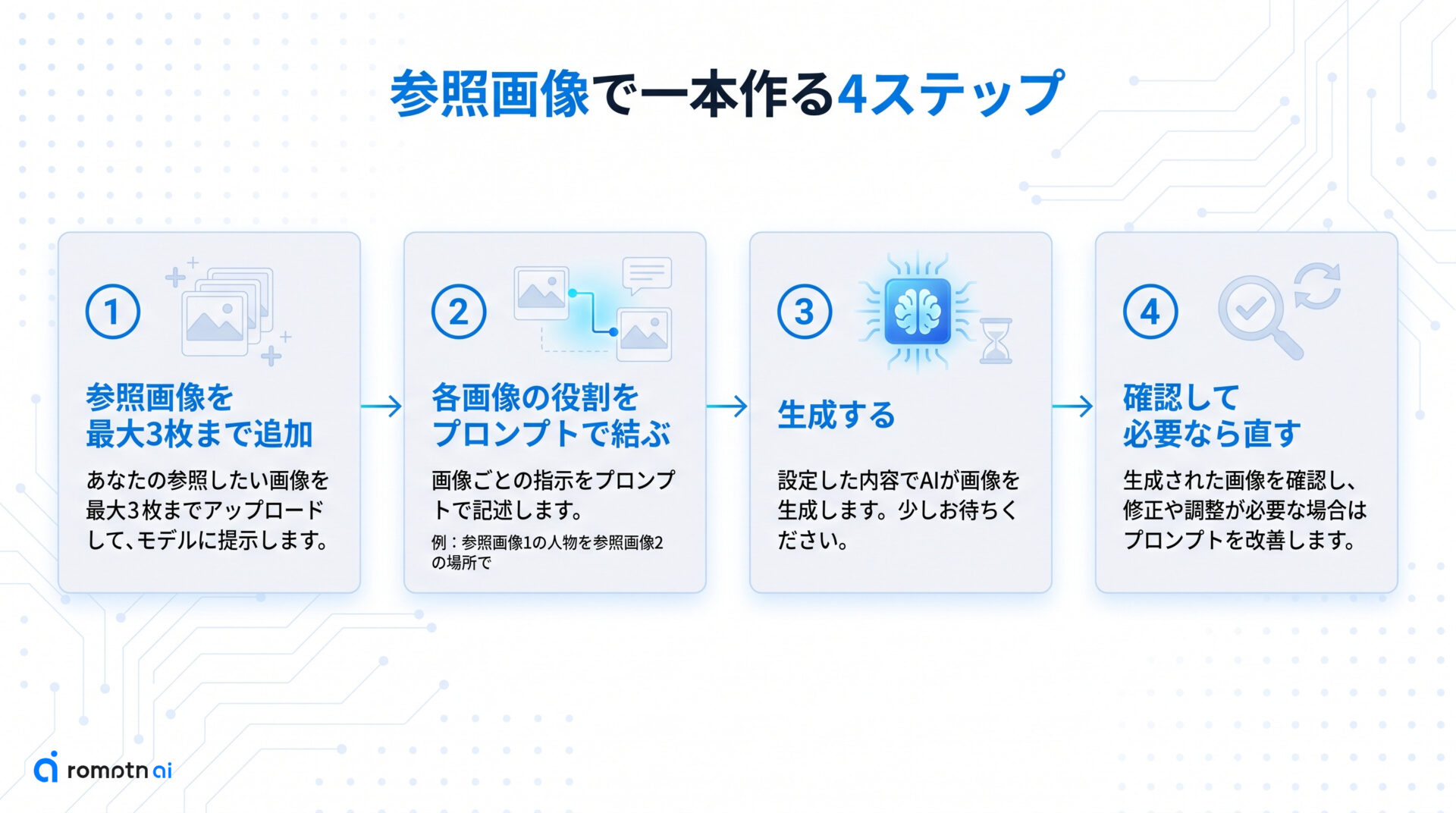
ここからは、どの経路でも共通する「参照画像を渡して最初の一本を作る」流れを押さえます。
最初に効くのは画像選びです。被写体・背景・画調はそれぞれ目的が1つに絞られた写真を用意します。人物なら顔がはっきり写った1枚、背景なら人物の写っていない場所の1枚、というイメージです。
もとの写真が鮮明なほど、ショット間で同じ見た目を保ちやすくなります。複数の意図を1枚に詰め込んだ写真は避けます。
渡せる枚数は執筆時点では最大3枚で、役割は固定スロットではなく柔軟に割り当てられます。identity を決めたい画像を先頭に置くと、その特徴が反映されやすい場面があります(並び順は必ず効くわけではありません)。
基本の流れは次の4ステップです。
- 参照画像を最大3枚まで追加する
- プロンプトで各画像の役割を言葉で結ぶ(例:「参照画像1の人物を、参照画像2の場所で」)
- 生成する
- 結果を確認し、思い通りでなければ直す
役割を明示する詳しい書き方は後ほどの『各画像を役割に結ぶプロンプト』で、思い通りにならないときの直し方は後ろの章で扱います。まずはこの4ステップで一本作るのが近道です。
3つの用途で画像を割り当てる
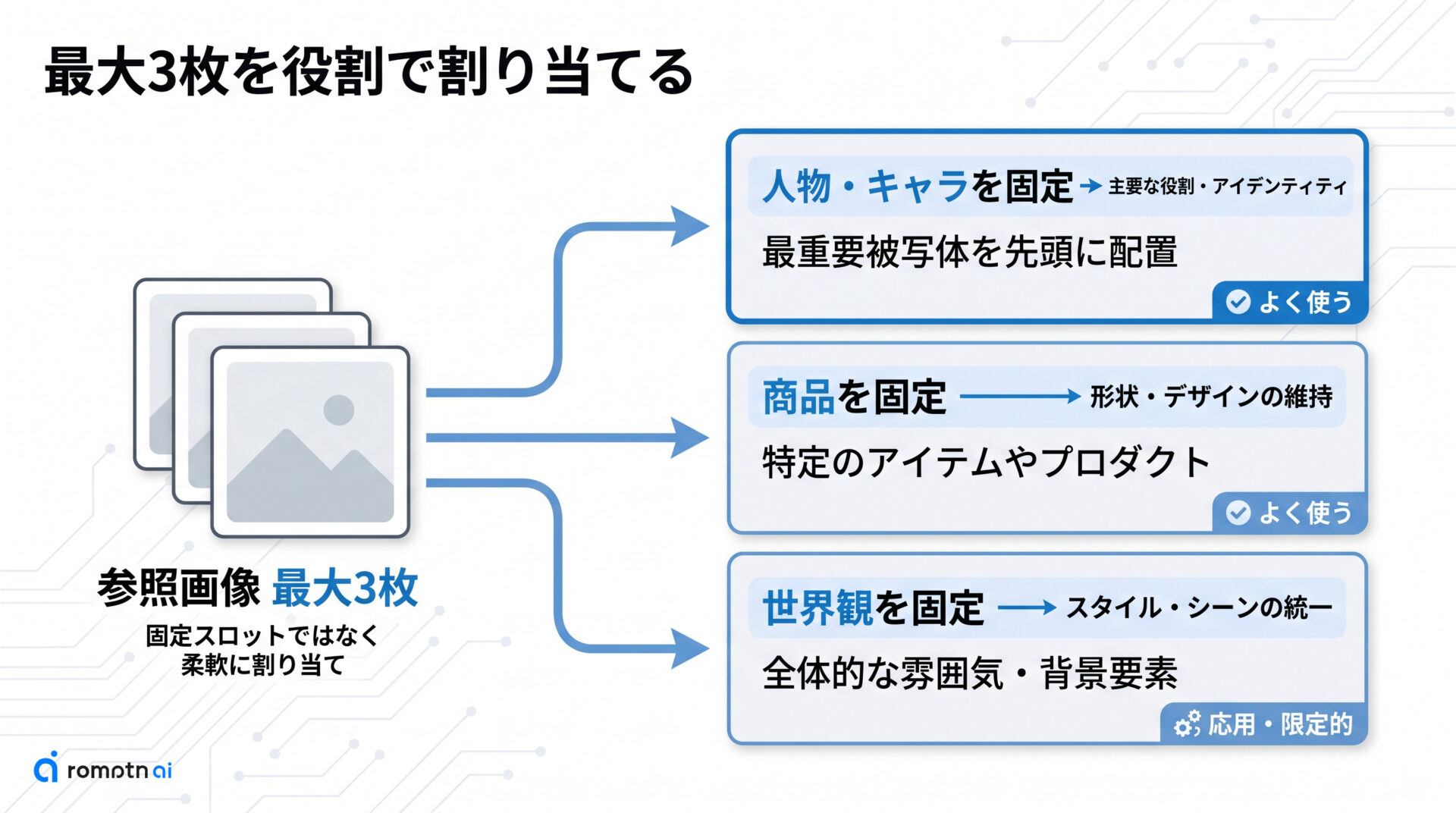
ここからは、最大3枚まで柔軟に渡せる参照画像という同じ仕組みを、具体的な目的に当てはめていきます。固定の枠が役割ごとに決まっているわけではなく、何を一番揃えたいかで割り当て方を組み替えるのがコツです。
考え方はシンプルです。自分が一番崩したくないものを、被写体を決める役割の画像に据えます。残りの枠には、それを置く環境や全体の雰囲気を伝える画像を足していきます。
割り当ての先頭には、揃えたい当人や対象の写真を置くと効きやすくなります。後ろの枠は環境や雰囲気の補助として使う、という並べ方が基本です。
実務で多いのは、同じ人物を保ちたい使い方と、同じ商品を保ちたい使い方の2つです。世界観だけを揃えたい場面はやや限定的で、人物や商品ほど頻度は高くありません(需要の偏りは未確認のため、扱いの軽重として捉えてください)。
次の3つの章で、人物を揃えるとき・商品を揃えるとき・世界観を揃えるときの順に、どの写真をどの役割へ割り当てるかを具体的に見ていきます。
①人物・キャラを固定する
同じ人物やキャラクターをショットをまたいで同じ顔のまま登場させたいときは、まずその人物の identity を決める1枚を一番目に置きます。この並び順が、誰を主役として固定するかを伝える土台になります。
一番目に選ぶのは、顔がはっきり写った正面の写真です。前髪で目が隠れていない、影で半分潜っていない、ピントの合った1枚を選ぶと、同じ顔のまま保ちやすくなります。これがキャラ固定のいちばんの肝です。
人物の見た目をさらに伝えたいときは、2枚目・3枚目で別アングルや全身を足します。横顔や斜めの角度、立ち姿を加えると、顔だけでなく髪型や体格まで含めた「その人らしさ」までしっかり受け継がれます。参照画像は最大3枚まで柔軟に使えるので、服装専用のスロットといった決まりはなく、人物を伝える写真でまとめて構いません。
プロンプトは、人物そのものは参照画像に任せ、文章側では「何をしているか」「どこにいるか」だけを変えるのがコツです。被写体を参照画像に固定したまま、動作や舞台を言葉で差し替えていきます。
参照画像1の人物が、夕暮れのカフェのテラス席でコーヒーを飲みながら微笑んでいる。
参照画像1の人物が、雨上がりの street を傘を閉じて歩いている。
この書き方なら、同じ人物のまま場面や動作だけを切り替えられるので、1人の登場人物を複数のシーンで動かす短い物語も組み立てられます。動画を1本ずつ作りながら、同じ参照画像を使い回して場面をつないでいくイメージです。
それでも顔がうまく揃わないときの直し方は、後ほどの章でまとめて扱います。ここではまず、顔がはっきりした正面の1枚を先頭に置くことだけ押さえてください。
②商品を固定する
広告や商品ページのように、ひとつの商品をいくつもの場面に登場させたいときは、その商品を写した写真を被写体の役割に置きます。被写体を固定したまま、まわりの場面だけを文章で差し替えていくのが基本です。
渡す写真は、商品だけが大きく写ったカタログ撮影のような一枚が適しています。余計な物が写り込まない無地の背景で、形・色・ロゴ・ラベルがはっきり見える状態にすると、別の場面に置いても同じ商品として再現されやすくなります。
参照画像は柔軟に最大3枚まで渡せます。商品の見え方を揃えたいときは、正面・斜め・側面など複数のアングルを足すと、立体的な形が伝わりやすくなります。残りの枠は、置きたい場所の雰囲気や画調を示す写真に使えます。
プロンプトは、商品はそのままに場面だけを指定する形で書きます。たとえば次のように、被写体役割の画像を主語にして、まわりの状況を言葉で添えます。
参照画像1の製品が、明るいカフェのテーブルに置かれ、朝の自然光が差し込む場面。手前から穏やかにズームインする。この組み立ては、同じロゴを保ったまま複数の舞台で見せたいときにも使えます。場面を表す一文を入れ替えるだけで、屋外・店頭・自宅といった別の場面のカットを揃えられます。
仕上がりが思うように出ないときの直し方は、後ほどの章でまとめて扱います。
③背景・世界観を固定する
同じ場所や同じ雰囲気をショットをまたいで保ち、そこに登場する人や物だけを変えたいときの応用です。人物や商品ほど出番は多くありませんが、世界観を揃えたい場面でははっきり効きます。
ここまでの2つと役割の置き方が逆になります。揃えたい当人を先頭に置くのではなく、場所や雰囲気を写した画像を環境の役割に回し、登場する被写体のほうを文章や別の参照画像で差し替えます。
環境の役割に渡す写真は、次の2種類が使いやすいです。
- 舞台そのものを写した1枚(人や主役の物が写っていない、場所だけの写真)
- 色味やムードの見本になる1枚(全体のトーンや雰囲気を決めたいとき)
どちらも参照画像として渡せます。枚数は執筆時点では最大3枚まで柔軟に使えるので、舞台の写真とムードの見本を同時に添えても構いません。背景専用の固定スロットがあるわけではない点は、ここでも同じです。
プロンプトは、揃えたい舞台を参照画像で指し示し、そこに置く被写体や動きだけを言葉で変えます。
参照画像2の場所・雰囲気の中で、一人の客が席に着いてメニューを眺めている。この一文の被写体部分だけを書き換えれば、同じ世界観のまま別のカットを揃えられます。さらに、揃えたい人物や商品の写真を参照画像として一緒に渡せば、「決まった被写体を、決まった舞台に置く」という両取りもできます。3つの役割をまとめて指定する書き方は、後ほどの『各画像を役割に結ぶプロンプト』で扱います。
各画像を役割に結ぶプロンプト
用途ごとの割り当て方を見てきたので、ここでは仕上げとして「どう書けば狙いどおりに伝わるか」という文面の作り方をまとめます。コツは1つで、それぞれの参照画像を、役割の言葉で名指ししてからプロンプトを書くことです。
やってしまいがちなのは、画像を渡しただけで「カフェで笑う動画」のようにふわっと指示することです。これだと、どの画像から何を受け継いでほしいのかがツールに伝わりません。
代わりに、画像の番号と「そこから何を取るか」をセットで書きます。たとえば「参照画像1の人物を、参照画像2の場所で、参照画像3の画調で」のように、1枚ずつ役割を宣言してから動きを足すと、伝わり方が大きく変わります。
そのまま使える型が次のものです。参照画像は最大3枚まで柔軟に渡せるので、使わない役割の行は丸ごと省いてかまいません(全部を埋める必要はありません)。
参照画像1の【役割:例 人物 / 商品 / 場所】を、
参照画像2の【役割】で、
参照画像3の【画調】で動かしてください。
動き・カメラ:【何をする / カメラはどう動く】
固定したいもの:【最後まで変えないでほしい要素】
音声:【あり=セリフや環境音を付ける / なし=無音にする】人物と場所を組み合わせる場合は、こう埋めます。
参照画像1の人物を、参照画像2のオフィスの場所で動かしてください。
動き・カメラ:席に座ってノートPCを開き、カメラは正面からゆっくり寄る
固定したいもの:参照画像1の顔と髪型、参照画像2の窓の景色
音声:なし(無音)動きやカメラを差し替えたいときは、役割を結んだ行はそのまま残し、「動き・カメラ」だけを書き換えます。固定したいものを毎回はっきり書き、変えたいものと分けて指示するのが、同じ人物や同じ商品を保ったまま場面を変えるコツです。
音声は付けるかどうかをプロンプト側で決めて明記します。執筆時点では Veo 3.1 が映像と一緒に音も作るため、何も書かないとセリフや環境音が入ることがあります。無音にしたいなら「音声:なし」と書き、しゃべらせたいなら話す内容を具体的に指定します。
全体を通して、抽象語より具体語が効きます。「おしゃれに」ではなく「夕方の逆光で、ゆっくり横移動」のように、場所・光・動き・カメラを言い切るほど、狙いどおりの一本に近づきます。
顔ブレ・崩れが起きたときの対処
参照画像を渡しても顔や被写体がショットの途中で別人っぽくなることはあります。多くは「どの画像で何を固定したいか」がうまく伝わっていないのが原因なので、まずは渡す画像とプロンプトを見直すのが近道です。
最初に効くのは、参照画像そのものの見直しです。次の3点を順に試すと、人物の同一性が安定しやすくなります。
- 顔がはっきり写った、正面寄りで高画質の人物写真を identity 用の1枚にする
- 同じ役割を主張し合う似た画像を複数渡さず、枚数を絞る
- 「この画像の人物を、別の画像の場所で」のように、画像と役割を1対1で結んで書く
この役割の結び方は、前の『各画像を役割に結ぶプロンプト』の章で扱った書き方をそのまま使えます。曖昧なまま枚数だけ増やすと、Veo がどれを基準にすべきか迷い、かえって乱れやすくなります。
生成し直す前提も持っておくと楽です。同じ設定のまま数本まとめて作って一番良いものを選ぶ、プロンプトを少し変えて作り直す、といった振り直しは前提として織り込みます。
それでも一部だけ気になるときは、Flow の後修正ツールが使えます。Insert で要素を足し、Remove で不要なものを消し、Extend で尺を伸ばす、という具合に、作り直さず部分的に直せます。気になる箇所だけ手当てできるので、全体を捨てずに済みます。
最後に期待値の話です。執筆時点では、細かい文字や小さな表示、ごく細部の見た目はまだ乱れることがあります。ショット間の一貫性は以前より大きく改善していますが、完璧ではありません。重要なカットは複数本作って選ぶ前提で進めると、仕事に使えるレベルまで詰め切れます。
よくある質問
- QIngredients to Video は無料で試せますか?
- A
完全に無料というわけではなく、基本的には有料の Google AI プランが前提です。執筆時点では、上位の AI Ultra が最も上限が高く、下位の AI Pro はお試し向けに使える範囲が限られます。
プランによっては一定のクレジットが付くため、その枠内で実質的に試せる場合もあります。ただし付与量や条件は変わりやすいので、最新の内容は前の章の早見表とリンク先の公式プランページで確認してください。
- Q4K で出力できるのはどの経路ですか?
- A
4K アップスケールに対応するのは Flow・Gemini API・Vertex AI の経路です。コンシューマー向けの Gemini アプリ単体では、執筆時点では 4K 出力には対応していません。
高解像度で書き出したい場合は、Flow で仕上げるか、自動化したいなら Gemini API / Vertex AI を選ぶのが確実です。経路ごとの対応状況は前の章の早見表にまとめています。
- Q参照画像で『服装だけ』を固定できますか?
- A
「服装だけ」を切り出して固定する専用のスロットはありません。3 枚の参照画像は役割が固定された枠ではなく、被写体・環境・画調などを柔軟に渡すための画像です。
服装は被写体(人物・キャラ)に紐づく要素なので、服装まで写った人物画像をはっきり選び、プロンプトで服装の特徴を言葉でも指定して固定します。被写体ごと固定する形になるため、服装だけを単独で必ずロックする保証はない点を理解しておくと安心です。
- Q縦型(9:16)の動画は作れますか?
- A
作れます。執筆時点では、縦長の 9:16 をネイティブに出力できるため、ショート動画や縦型 SNS 向けの素材づくりに使えます。
アスペクト比の指定方法は経路によって場所が異なるので、生成設定の縦横比の項目を確認してください。対応状況は変わることもあるため、最新情報は公式の案内も合わせて見ておくと確実です。
- Q生成した動画に音声は付きますか?
- A
付きます。基盤となる Veo 3.1 は映像と一体で音声やセリフを生成できるため、効果音やナレーション、キャラクターの発話まで含めた動画を作れます。
音声のあり・なしはプロンプトで指定するのが基本です。静かな映像にしたいなら無音である旨を、しゃべらせたいなら台詞を文面で書き込むと、狙った音の付き方に近づけられます。
まとめ
ここまでで、参照画像を渡すことの本当の意味がはっきりしたはずです。固定された服装スロットのような決まった枠ではなく、最大3枚までの参照画像を役割を決めて自由に渡し、ショットをまたいで人物・商品・背景の見た目をそろえる仕組みでした。
要点をふり返ります。
- 参照画像は柔軟な枠組み:最大3枚を自分で役割分担して渡し、同じ顔・同じ商品・同じ世界観をショット間で保つ
- 経路は使い方で選ぶ:じっくり作り込むなら Flow、手軽に試すなら Gemini アプリ、自動化するなら API。経路ごとの細かい違いは早見表の章を見れば一目で比べられる
- コツは画像と役割を結ぶこと:プロンプトでどの画像が被写体・環境・画調かを言葉で指定する。顔ブレや崩れが出たら、より分かりやすい参照画像に差し替え、Flow の Insert / Remove で後から直す
あとは手を動かすだけです。まずは自分が触りやすい経路を1つ選び、固定したい人物・商品・背景の参照画像を1〜3枚きれいに用意しましょう。そのうえで役割を意識したプロンプトを添えて、最初の一本を生成してみてください。
一度この流れを通せば、二本目からは画像の差し替えとプロンプトの調整だけで、同じキャラや商品を保ったまま自在にショットを増やせるようになります。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

