
2025年11月、Alibabaの研究チームTongyi-MAIから新しい画像生成AI「Z-Image」がリリースされました!
Z-Imageは、わずか8ステップで高品質な画像を生成できる高速性と、フォトリアルな表現力が特徴の画像生成モデルです。しかも、16GB VRAMのコンシューマー向けGPUでも動作するので、ハイスペックなPCを持っていない方でも利用できるんです。
という方のために、Z-Imageの特徴から使い方、プロンプト生成のコツまで初心者の方にも分かりやすく解説していきます!
内容をまとめると…
Z-Imageは60億パラメータの軽量モデルで、16GB VRAMのGPUでも高速・高品質な画像生成が可能
わずか8ステップで生成でき、フォトリアルな表現と英語・中国語のバイリンガル文字描画に優れている
ComfyUIやAPIを使って無料で利用でき、Apache 2.0ライセンスで商用利用も可能
Z-Imageのような最新AI画像生成ツールを実務で活用したい方は、まずAIの基礎から学ぶのがおすすめ!
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Alibabaが開発した高速画像生成AI「Z-Image」とは?

「Z-Image(造相)」は、2025年11月にAlibabaのAI研究チームTongyi-MAIが発表した画像生成AIモデルです。
最大の特徴は、60億パラメータという軽量設計でありながら、大規模モデルに匹敵する高品質な画像を生成できる点なんです!
従来の画像生成AIは高性能なGPUが必須でしたが、Z-Imageは16GB VRAMのコンシューマー向けGPUでも快適に動作します。そのため、「ハイスペックなPCを持っていないけど、AI画像生成を試してみたい!」という方にもおすすめのモデルといえますね。
また、生成速度も非常に速く、エンタープライズグレードのNVIDIA H800 GPUを使えば1秒未満で画像生成が完了します。一般的なGPUでも2〜5秒程度で生成できるので、試行錯誤しながら理想の画像を作りやすいのが魅力です。
ライセンスはApache 2.0を採用しているため、商用利用や改変、配布も自由に行えます。これは企業やクリエイターにとって非常にありがたいポイントですね!
Z-Imageの3つのバリエーション
Z-Imageには、用途に応じた3つのバリエーションが用意されています。
①Z-Image-Base(ベースモデル)
Z-Imageシリーズの基盤となるモデルです。高品質な画像生成の土台として機能しますが、2026年1月現在は未公開で、今後リリース予定となっています。
②Z-Image-Turbo(高速蒸留版)
現在唯一公開されているモデルで、Z-Image-Baseを蒸留(軽量化)した高速版です。
わずか8ステップ(正確には9回の推論ステップ)で高品質な画像を生成でき、他の主要モデルと同等以上の性能を発揮します。フォトリアルな人物や風景の生成が得意で、英語と中国語の文字描画にも対応しているのが特徴です。
「とりあえずZ-Imageを試してみたい!」という方は、まずこのTurbo版から始めるのがおすすめですよ。
③Z-Image-Edit(画像編集特化版)
画像編集タスクに特化したモデルで、既存の画像を自然言語のプロンプトで編集できます。
例えば、「背景を夜景に変更」「服装をカジュアルに」といった指示で、元の画像の特徴を保ちながら細かい調整が可能です。こちらも2026年1月現在は未公開ですが、リリースされれば画像編集のワークフローが大きく変わりそうですね!
Z-Imageの主な特徴
それでは、Z-Imageがどんな特徴を持っているのか、詳しく見ていきましょう!
特徴①:わずか8ステップで高品質な画像生成が可能
Z-Image-Turboの最大の魅力は、圧倒的な生成速度です!
従来の画像生成AIでは、高品質な画像を作るために数十ステップの処理が必要でした。しかしZ-Image-Turboは、わずか8回の関数評価(実質9回の推論ステップ)で、他のモデルと同等以上のクオリティを実現しているんです。
この高速化を支えているのが、「Decoupled-DMD」や「DMDR」といった蒸留技術です。これらの技術により、元のZ-Image-Baseモデルの性能を維持したまま、処理を大幅に軽量化することに成功しています。
実際の生成時間は、エンタープライズ向けのNVIDIA H800 GPUで1秒未満、一般的なRTX 4090でも25秒前後で完了します。「試しに生成してみて、気に入らなかったらすぐに別のプロンプトで試す」といった反復作業がストレスなく行えるのは、クリエイターにとって大きなメリットですね!
特徴②:16GB VRAMの低スペックGPUでも動作する軽量設計
Z-Imageのもう1つの強みが、ハードウェア要件の低さです。
60億パラメータという軽量設計により、16GB VRAMを搭載したコンシューマー向けGPU(RTX 3060や4060など)でも快適に動作します。中には、VRAM 6GBのRTX 3060で1024×1024の画像を実用的な速度で生成できたという報告もあるんです!
さらに驚きなのが、VRAM 2GBのMX150のような超ローエンドGPUでも、解像度とステップ数を調整すれば「数分かけて1枚ずつ生成する」運用が可能だったという検証結果です。
これは「専用GPUさえあれば、ハイエンドでなくても十分使える」ということを意味しています。高額なGPUを購入しなくても、AI画像生成に挑戦できるハードルの低さは、初心者の方にとって非常にありがたいポイントですね。
特徴③:フォトリアルな表現力と高い指示追従性
Z-Imageは、フォトリアリスティックな画像生成を得意としています。
特に人物ポートレートや都市夜景、ファッションエディトリアル系の画像において、その実力を発揮します。肌の質感や髪の流れ、光の反射といった細部まで自然に表現できるため、「本物の写真と見分けがつかないレベル」の画像を生成できるんです。
また、複雑なプロンプトに対する追従性も高く、「夕暮れの静かな山湖、バイリンガル標識付き」のような詳細な指示にもしっかり応えてくれます。これは統合されたプロンプトエンハンサー機能により、入力されたプロンプトを自動で最適化しているからなんですね。
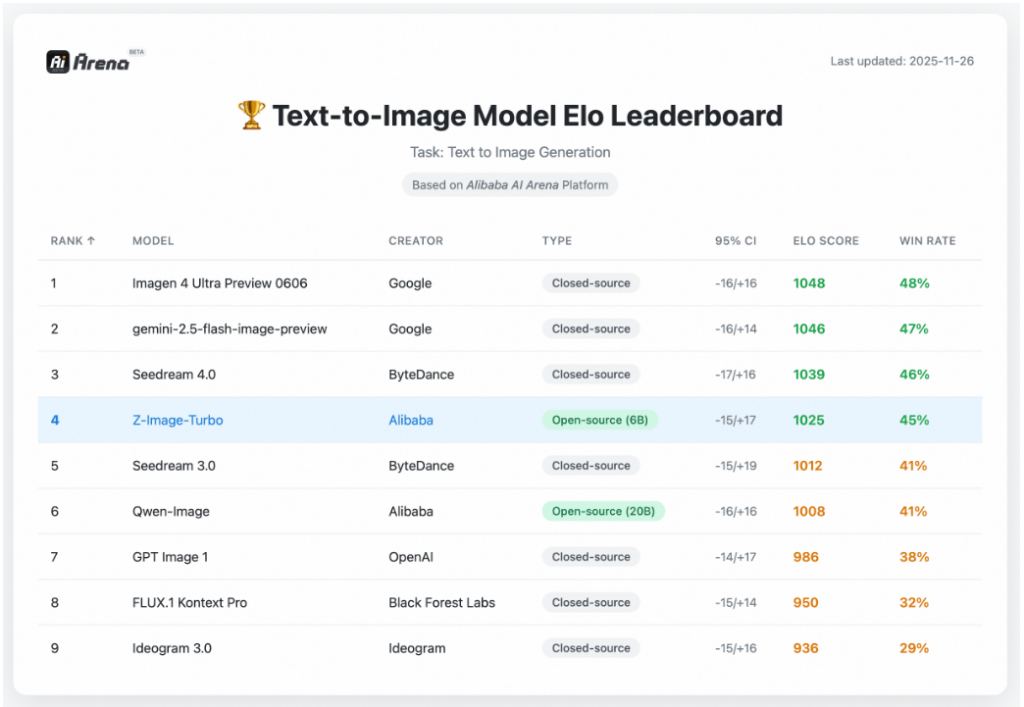
ベンチマーク評価でも、Qwen-ImageやSeedream 4.0といった主要モデルと肩を並べる高スコアを記録しており、その品質は折り紙付きです!
特徴④:英語・中国語のバイリンガル文字描画に対応
画像生成AIの弱点の1つが、画像内のテキスト生成です。多くのモデルでは文字が崩れたり、意味不明な文字列になったりしてしまいます。
しかしZ-Imageは、英語と中国語の文字描画において非常に高い精度を誇ります!

ポスターやメニュー、看板といったデザイン用途で、小さな文字や縦書きレイアウトも正確に描画できるため、商業利用での可能性が広がります。特に中国語のような複雑な文字の形状も崩れにくく、実用レベルの品質を実現しているんです。
ただし残念ながら、2026年1月現在、日本語のテキスト生成には対応していません。漢字2〜3文字程度なら生成できることもありますが、長文や正確な日本語表示は難しいのが現状です。今後のアップデートに期待したいところですね!
特徴⑤:Apache 2.0ライセンスで商用利用も可能
Z-ImageはApache 2.0ライセンスで公開されているため、商用利用や改変、配布が自由に行えます。
これは企業やフリーランスのクリエイターにとって非常に重要なポイントです。多くの画像生成AIでは商用利用に制限があったり、別途ライセンス料が必要だったりしますが、Z-Imageではそうした心配がありません。
例えば、以下のような用途で自由に活用できます。
- EC サイトの商品画像生成
- 広告クリエイティブの制作
- ゲーム開発のコンセプトアート作成
- SNS投稿用のビジュアル制作
オープンソースでありながら商用利用可能という点は、Z-Imageの大きな強みといえるでしょう!
Z-Imageの料金設定
続いて、気になる料金についても見ていきましょう!
Z-Imageを無料で利用する方法
Z-Imageの大きな魅力の1つが、完全無料で利用できる点です!
現在公開されているZ-Image-Turboは、以下の方法で無料利用が可能です。
Hugging Face上に公開されている公式デモサイトでは、ブラウザ上で直接画像生成を試すことができます。アカウント登録も不要で、プロンプトを入力するだけですぐに使えるので、「とりあえず試してみたい!」という方に最適ですよ。
②ModelScope APIの無料枠
ModelScopeが提供するAPIサービスでは、Z-Image-Turboへの推論リクエストに料金が発生しません。公式のX(旧Twitter)投稿でも「無制限の無料計算」が発表されており、ホスティング費用や帯域幅、GPUリソースまで含めて無料で利用できるんです!
ただし、悪用防止のためレート制限が設けられています。無料アカウントの場合、1時間あたり約50〜100回の生成が目安となっており、制限を超えると一時的にスロットリング(速度制限)がかかります。それでも、個人利用や開発段階であれば十分な量ですね。
③ローカル環境での実行
モデルの重み(約24GB)をダウンロードすれば、自分のPCで完全無料で利用できます。Hugging FaceやModelScopeのリポジトリから入手可能で、PyTorchに対応した環境があればすぐに動かせます。
ローカル実行なら生成回数の制限もありませんし、インターネット接続も不要です。16GB VRAM以上のGPUを持っている方には、この方法が一番おすすめですよ!
有料プランについて
2026年1月現在、Z-Image専用の有料プランは存在しません。
ただし、ModelScopeには大量のリクエストを必要とする企業向けにプロティアが用意されています。無料枠のレート制限を超えて利用したい場合は、こちらのプランにアップグレードすることで、より高いスループットでの利用が可能になります。
料金は低価格から設定されているとのことですが、具体的な金額については公式情報が出次第、こちらで更新していきますね!
また、Apache 2.0ライセンスで公開されているため、自社サーバーに導入して独自にホスティングすることも可能です。この場合、ModelScopeのレート制限を気にせず、完全に自由な運用ができます。
☆今後のアップデート情報について
Z-Image-BaseやZ-Image-Editがリリースされた際には、料金体系が変更される可能性もあります。最新情報は随時このページで更新していきますので、ぜひブックマークしておいてくださいね!
Z-Imageの使い方
それでは、Z-Imageを実際に使う方法を3つのパターンに分けて解説していきます!
使い方①:ブラウザのデモサイトで試す方法
「まずは手軽に試してみたい!」という方には、Hugging Faceの公式デモサイトがおすすめです。
- STEP1Hugging Faceの「Z-Image-Turbo」ページにアクセス
- STEP2ページ内の「Spaces」セクションにあるデモリンクをクリック
- STEP3プロンプト入力欄に生成したい画像の説明を英語で入力

- STEP4「Generate」ボタンを押して生成開始

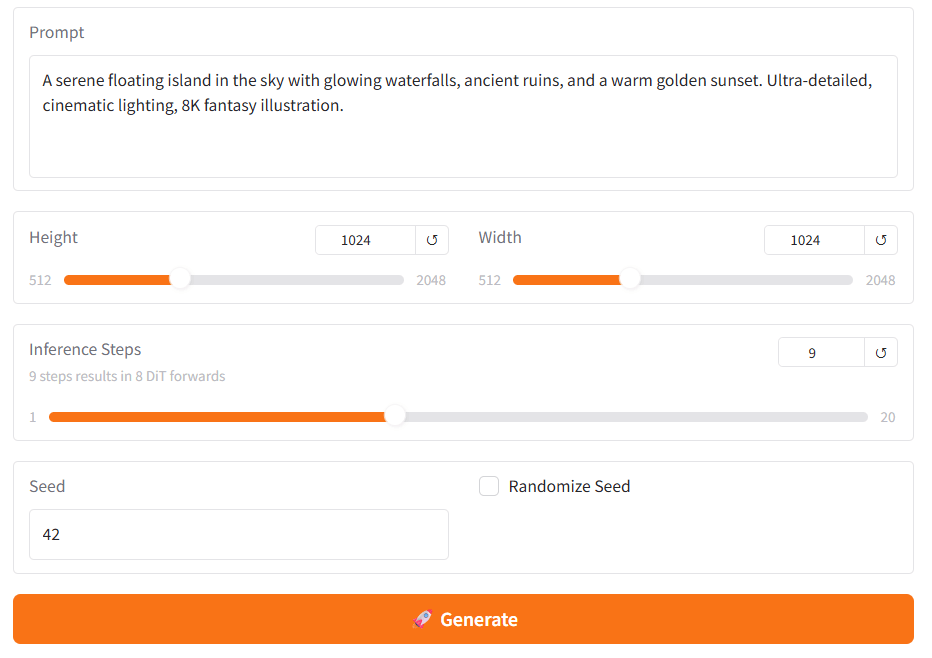

アカウント登録も不要で、ブラウザだけで完結するので、とても簡単ですよ!
生成時間は混雑状況によって変わりますが、だいたい10〜30秒程度で画像が表示されます。デモサイトでは基本的なパラメータ設定も可能で、画像サイズや生成ステップ数を調整できます。
ただし、デモサイトは多くのユーザーが同時にアクセスするため、時間帯によっては待ち時間が発生することもあります。より快適に使いたい方は、次に紹介するComfyUIやAPIでの利用がおすすめです!
※ステップ数って何?と言う方は、下記記事を参考にしてみてください。

使い方②:ComfyUIで使う方法
ComfyUIは、ノードベースで画像生成のワークフローを組める便利なツールです。Z-Image-Turboも対応しているので、詳しく見ていきましょう!
- STEP1必要なモデルのダウンロード
まずは、以下の3つのファイルをダウンロードして、それぞれ対応するフォルダに配置します。
①Diffusion Model(拡散モデル本体)
- ダウンロード元:Hugging FaceのComfy-Org/z_image_turbo
- 保存先:
ComfyUI\models\diffusion_models - ファイル名:通常版の場合は約12GB、GGUF量子化版もあり
②Text Encoder(テキストエンコーダー)
- ダウンロード元:同じくComfy-Org/z_image_turbo内の
qwen_3_4b.safetensors - 保存先:
ComfyUI\models\text_encoders - このファイルでプロンプトを解析します
③VAE(画像変換モデル)
- ダウンロード元:同じく
ae.safetensors - 保存先:
ComfyUI\models\vae - 生成された潜在表現を画像に変換する役割です
合計で約24GB程度のダウンロードになりますので、ストレージ容量に余裕を持っておきましょう!
- STEP2ワークフローの設定方法
ComfyUIの公式examplesページから、Z-Image専用のワークフローをダウンロードできます。
- ComfyUI_examplesの「Z Image」セクションにアクセス
- ワークフロー画像を右クリックで保存
- ComfyUIのウィンドウに画像をドラッグ&ドロップ
これだけで、必要なノードが自動的に配置されたワークフローが読み込まれます!
ワークフロー自体は非常にシンプルで、以下のノードで構成されています。
- STEP3基本的な生成手順
ワークフローを読み込んだら、以下の手順で画像を生成します。
1. 各ノードでモデルを選択
- Load Diffusion Model:ダウンロードした拡散モデルを選択
- Load CLIP:qwen_3_4b.safetensorsを選択
- Load VAE:ae.safetensorsを選択
2. プロンプトを入力
CLIP Text Encodeノードのテキスト欄に、生成したい画像の説明を英語で入力します。デフォルトのプロンプトを参考にしつつ、自分の好みに合わせて調整しましょう。
3. パラメータ設定
- 解像度:デフォルトは2048×2048(4090環境の場合)
- ステップ数:4〜15の範囲で調整可能(4で十分高品質)
- サンプラー:res_multistep(推奨)
- スケジューラー:simple(推奨)
- CFG:1.0固定(蒸留モデルのため変更不要)
4. 生成実行
「Queue Prompt」ボタンを押せば生成が始まります。RTX 4090環境で2048×2048の場合、約25秒前後で完成しますよ!
ネガティブプロンプトは蒸留モデルのため使用できませんが、ポジティブプロンプトで細かく指定することで十分にコントロール可能です。
※ComfyUIの使い方については、下記記事で詳しく解説しています。

使い方③:APIを使って無料で利用する方法
プログラムから呼び出したい方や、自動化したい方にはAPI利用がおすすめです!
まずは、ModelScopeへの登録から始めましょう。
- ModelScopeの公式サイトにアクセス
- メールアドレスまたはGitHubアカウントで新規登録
- ログイン後、プロフィール画面から「API」セクションに移動
- 「Generate Token」をクリックしてAPIトークンを生成
- 生成されたトークンを安全な場所にコピー保存
このトークンは、すべてのAPIリクエストで使用する認証キーになります。外部に漏らさないよう注意してくださいね!
続いては、「APIエンドポイントの設定」に進みます。
Z-Image APIは非同期処理を採用しています。つまり、画像生成リクエストを送信すると即座にタスクIDが返され、その後ポーリング(定期的な確認)で結果を取得する仕組みです。
| 主要なエンドポイント | ・生成リクエスト:POST https://api-inference.modelscope.cn/v1/images/generations・ステータス確認: GET https://api-inference.modelscope.cn/v1/tasks/{task_id} |
| 必須ヘッダー | ・Authorization: Bearer {あなたのトークン}・ Content-Type: application/json・ X-ModelScope-Async-Mode: true(生成時)・ X-ModelScope-Task-Type: image_generation(確認時) |
次は「リクエストの送信方法」です。実際のcurlコマンド例で見てみましょう。
# ステップ1:生成タスクを送信
curl -X POST "https://api-inference.modelscope.cn/v1/images/generations" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-H "X-ModelScope-Async-Mode: true" \
-d '{
"model": "Tongyi-MAI/Z-Image-Turbo",
"prompt": "A photorealistic Japanese woman in kimono, cherry blossoms background, cinematic lighting",
"height": 1024,
"width": 1024,
"num_inference_steps": 9,
"guidance_scale": 0.0
}'レスポンスで返ってきたtask_idをメモしておきます。
# ステップ2:5〜10秒ごとにステータスを確認
curl -X GET "https://api-inference.modelscope.cn/v1/tasks/abc123" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "X-ModelScope-Task-Type: image_generation""task_status": "SUCCEED"が返ってきたら完了です!レスポンスのoutput_images配列にダウンロードURLが含まれているので、そこから画像を取得できます。
通常、エンドツーエンドで5〜15秒程度で完了しますよ。
- 401エラー:トークンが無効または期限切れ
- 429エラー:レート制限超過(少し待ってから再試行)
- 500エラー:サーバー側の問題(指数関数的バックオフでリトライ)
PythonやNode.jsなどのプログラミング言語からも同様に呼び出せるので、自動化ワークフローにも簡単に組み込めます!
Z-Imageで高品質な画像を生成するプロンプトのコツ
Z-Imageで理想の画像を生成するには、プロンプトの書き方が重要です!ここでは、すぐに使えるコツを紹介していきますね。
プロンプトの基本構成
Z-Imageは長くて具体的なプロンプトを書くほど、性能を発揮するタイプのモデルです。
以下のような構成を意識すると、狙った通りの画像が生成しやすくなりますよ!
[撮影タイプ] + [被写体の詳細] + [服装・アクセサリー] + [表情・ポーズ] + [背景・環境] + [ライティング] + [カメラ・レンズ設定] + [スタイル指定]
それぞれの要素について、もう少し詳しく見ていきましょう。
①被写体の詳細
人物を生成する場合は、年齢や雰囲気、職業などを具体的に書くと精度が上がります。


例
a 25-year-old Japanese woman(25歳の日本人女性)a mysterious 27-year-old professional model(ミステリアスな27歳のプロモデル)a tall elegant businesswoman(背の高いエレガントなビジネスウーマン)
Z-Imageはフォトリアルな美人・モデル系の生成が得意なので、elegant(エレガント)、sophisticated(洗練された)、stunning(目を見張る)、glamorous(魅力的な)といった形容詞を使うと、モデルの特性に合った画像が生成されやすくなります。
逆に、cute(かわいい)やadorable(愛らしい)といったアイドル的な表現は苦手な傾向があります。
②環境・背景の指定
どこで撮影するかを明確にすると、シーンの雰囲気がぐっと良くなります。


例
standing in Shinjuku alley at night, rain falling(夜の新宿の路地裏、雨が降っている)sitting by the window in a cozy Tokyo café during daytime(昼間の東京の居心地の良いカフェの窓際に座っている)in a minimalist studio with soft beige backdrop(柔らかなベージュの背景のミニマルなスタジオで)
特に都市の夜景やストリートスナップ系の背景は、Z-Imageが非常に得意としている領域です!
③ライティング・カメラ設定
プロっぽい仕上がりにしたいなら、照明とカメラの設定も忘れずに指定しましょう。


ライティングの例
soft natural light on her face(顔に柔らかな自然光)strong side lighting creating dramatic shadows(ドラマチックな影を作る強いサイドライティング)cinematic golden hour lighting(映画的な夕暮れの照明)
カメラ・レンズの例
shot on Sony A7S III, 35mm f/1.4(ソニーA7S III、35mm f/1.4で撮影)shot on Fujifilm X-T5 with 56mm f/1.2 lens(富士フイルムX-T5、56mm f/1.2レンズで撮影)medium format camera, ultra sharp details(中判カメラ、超シャープなディテール)
実在するカメラやレンズの名称を入れると、そのカメラ特有の描写に近い画像が生成されることがあります!
スタイルの指定
最後に、全体の仕上がりを決めるスタイルを指定します。


例
8K resolution, photorealistic(8K解像度、フォトリアリスティック)Blade Runner aesthetic(ブレードランナー風)film-like colors, gentle pastel tones(フィルムのような色、優しいパステルトーン)high-end magazine aesthetic(高級雑誌の雰囲気)
Z-Imageの場合、フォトリアルを前提としているため、photorealisticやultra detailedといった指定は効果的ですよ。
すぐに使えるプロンプト例
それでは、実際にコピペして使えるプロンプトをいくつか紹介します!
①フォトリアル系
Close-up portrait of a 25-year-old Japanese woman sitting by the window in a cozy Tokyo café during daytime. Soft natural light on her face, shallow depth of field, background softly blurred. Wearing a cream knit sweater and delicate gold earrings. Warm smile, relaxed pose, looking slightly away from the camera. A latte with latte art on the wooden table, soft bokeh lights in the background. Shot on Fujifilm X-T5 with 56mm f/1.2 lens, film-like colors, gentle pastel tones.
このプロンプトは、カフェでくつろぐ自然な雰囲気の女性を生成します。柔らかな光と浅い被写界深度がポイントですね!
②ファッションエディトリアル系
Fashion magazine close-up portrait of a tall Japanese woman in a minimalist studio with a soft beige backdrop. Upper body framing, slightly turned to the side, looking back toward the camera with a gentle, confident gaze. Wearing a light ivory blazer over a simple white top, delicate gold necklace and small earrings. Soft side lighting creating a warm highlight on her face and hair, gentle shadows on the opposite side. Natural makeup with soft pink lips, smooth skin, subtle glow, slightly wavy hair resting on her shoulders. Clean, modern Japanese women's fashion magazine aesthetic, high resolution, ultra detailed.
ファッション誌風の洗練されたポートレートが生成できます。Z-Imageの得意分野を活かしたプロンプトですよ!
③夜景・ストリートスナップ系
Full body street photography of a mysterious 27-year-old Japanese woman standing in Shinjuku alley at night, rain falling. Wearing a long black leather coat, burgundy turtleneck dress, black ankle boots. Bold red lipstick, smoky eyes. Wet slicked-back hair, dramatic look. Intense gaze at camera, holding clear umbrella. Neon signs reflecting in puddles, steam from vents, cinematic noir atmosphere. Sony A7S III, 35mm f/1.4, rain droplets in focus. Blade Runner aesthetic, 8K resolution.
都市の夜景とモデルを組み合わせた、映画のワンシーンのような画像が生成されます。Z-Imageが最も得意とする領域の1つです!
プロンプト生成を支援するシステムプロンプト
「プロンプトを考えるのが難しい…」という方には、LLM(大規模言語モデル)を使ったプロンプト生成がおすすめです!
以下のシステムプロンプトをChatGPTやClaudeに入力すれば、Z-Image向けの最適化されたプロンプトを自動生成してくれます。
あなたは視覚的な描写に特化したアーティストです。ユーザーからの簡単な要望を、Z-Image向けの詳細で美的に洗練された画像生成プロンプトに変換してください。
以下の順序で構成してください:
1. まず、ユーザーの要望から変更してはいけない核心要素(被写体、数量、動作、状態など)を確定
2. 生成的推論が必要か判断(問題解決やデザインを求められている場合)
3. プロフェッショナルな美的詳細を追加(構図、照明、質感、色彩、空間の奥行き)
4. 画像内に表示すべきテキストがあれば、英語のダブルクォーテーション("")で囲んで明示
最終的なプロンプトは客観的で具体的に。比喩や感情的な修辞は避け、"8K"や"masterpiece"のようなメタタグも不要です。
ユーザーの入力: {ここにあなたの要望を入力}このシステムプロンプトを使えば、「夜のカフェでコーヒーを飲む女性」といった簡単な入力から、数百語の詳細なプロンプトを自動生成してくれますよ!推奨されるLLMはqwen3-max-preview(温度:0.7、top_p:0.8)ですが、ChatGPTやClaudeでも十分な品質が得られます。


Z-Imageを使う際の注意点
Z-Imageは非常に優秀なモデルですが、いくつか知っておくべき制限事項があります。事前に把握しておけば、より効率的に使えますよ!
日本語テキスト生成の制限について
Z-Imageは英語と中国語の文字描画に優れていますが、日本語のテキスト生成には正式対応していません。
実際にデモサイトで試してみたところ、日本語プロンプトで生成しても、画像内の日本語テキストは崩れたり文字化けしたりすることが多いです。漢字2〜3文字程度なら生成できることもありますが、長文や正確な日本語表示は現時点では難しいのが実情です。
もし日本語テキストを含む画像が必要な場合は、以下の方法を検討してみてください。
- 英語で画像を生成してから、画像編集ソフトで日本語テキストを後から追加する
- Z-Image-Editがリリースされたら、そちらで編集を試みる
- 日本語対応の他モデル(Stable Diffusionなど)と組み合わせて使う
ポスターやメニューといったデザイン用途で日本語が必須の場合は、現状では他のツールとの併用が現実的ですね。今後のアップデートに期待したいところです!
推奨される解像度とステップ数
Z-Image-Turboは高速性を重視して設計されているため、極端に高い解像度には対応していません。
推奨される設定は以下の通りです。
| 解像度 | ・基本は1024×1024または2048×2048 ・1536×1536程度までなら問題なく生成可能 ・それ以上(例:3072×3072)になると、ファインチューニングなしではぼやけが生じる可能性あり |
| ステップ数 | ・推奨は4〜9ステップ ・4ステップでも十分高品質(特に動画用途なら十分) ・8〜10ステップで静止画としても申し分ない品質 ・15ステップ以上にしても恩恵が少なく、生成時間が長くなるだけ |
ステップ数を増やしすぎると、かえってシワや不要なディテールが増えてしまうこともあります。まずは推奨設定で試してみて、必要に応じて微調整するのがおすすめですよ!
また、CFG(guidance_scale)は0.0固定で使用してください。Z-Image-Turboは蒸留モデルのため、classifier-free guidanceをスキップする設計になっています。この値を変更しても品質向上にはつながりません。
アニメ・イラスト系の生成には不向き
Z-Imageはフォトリアリスティックな画像生成に特化しているため、アニメやイラスト調の画像生成は苦手です。
特に以下のような用途には向いていません。
- 日本のアニメ風キャラクター
- SDXLで人気の「アニメ塗り」スタイル
- デフォルメされたキャラクター
- マンガ風のイラスト
例えば「cute anime style one-eyed cyberpunk nurse(訳:かわいいアニメ風の片目のサイバーパンクナース)」というプロンプトでは、「片目」の指定が正確に反映されないことが報告されています。

Z-Imageの得意分野は、
- リアルな人物ポートレート
- ファッションエディトリアル
- 都市夜景やストリートスナップ
- 商品写真のようなフォトリアル表現
アニメ・イラスト系の画像が必要な場合は、Stable Diffusion XLのアニメ系モデルや、専用のイラスト生成AIを使う方が確実ですよ!
ネガティブプロンプトは使用不可
Z-Image-Turboは蒸留モデルのため、ネガティブプロンプトに対応していません。
通常の画像生成AIでは「生成してほしくない要素」をネガティブプロンプトで指定できますが、Z-Imageではその機能が使えないんです。
その代わり、ポジティブプロンプトで細かく制御する必要があります。例えば、
| ❌ ダメな例 | ・プロンプト:a beautiful woman・ネガティブ: blurry, low quality, distorted hands |
| ⭕ 良い例 | プロンプト:a beautiful woman with natural hands, sharp focus, high quality, photorealistic, professional photography |
「〜ではない」という否定形ではなく、「〜である」という肯定形で、理想の状態を詳しく記述することが重要ですよ!
VRAMとモデルサイズに注意
Z-Image-Turboは比較的軽量ですが、それでも最低12〜16GB程度のVRAMが快適な利用には必要です。
VRAM 6GBのGPUでも工夫次第で動きますが、解像度やバッチサイズに制限がかかります。もしVRAMが不足している場合は、
- GGUF量子化モデルを使う(精度は若干落ちるが軽量化される)
- 解像度を512×512や768×768に下げる
- APIやデモサイトを利用する(クラウド側のGPUを使うので自分のVRAMは関係なし)
また、モデルファイルの合計サイズは約24GBになるため、ストレージ容量にも余裕を持っておきましょう。特にComfyUIで複数のモデルを管理している場合、容量不足になりがちなので注意が必要ですね!
まとめ
いかがでしたでしょうか?
Alibabaが開発した画像生成AI「Z-Image」の特徴から使い方、プロンプトのコツ、注意点まで詳しくご紹介しました。
この記事で紹介したことをまとめると次のようになります。
- Z-Imageは60億パラメータの軽量モデルで、16GB VRAMのGPUでも高速・高品質な画像生成が可能
- わずか8ステップで生成でき、フォトリアルな表現と英語・中国語のバイリンガル文字描画に優れている
- Apache 2.0ライセンスで商用利用も可能で、無料で利用できる方法が複数ある
- デモサイト、ComfyUI、APIの3つの方法で利用でき、用途に応じて選べる
- プロンプトは「被写体+環境+ライティング+カメラ設定+スタイル」の構成で詳細に書くと高品質
- 日本語テキスト生成やアニメ・イラスト系の画像は苦手なので、用途に応じて他のAIとの使い分けが必要
「AI画像生成を始めてみたいけど、ハイスペックなPCがない…」という方や、「最新の画像生成AIを無料で試してみたい!」という方にとって、Z-Imageは非常に強力な選択肢になるのではないでしょうか?
ぜひ、この記事を参考にZ-Imageで理想の画像生成にチャレンジしてみてくださいね!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

