
DiffusionGemma が速いと聞いても、Gemma 4 より本当に優先して選ぶべきなのか、手元の GPU でどこまで現実的に試せるのかは発表文だけでは判断しにくいはずです。先に結論を言うと、DiffusionGemma は 「品質より待ち時間を先に削りたい人向け」の別軸モデル です。
しかもポイントは、単に 4倍速 という派手な数字だけではありません。text diffusion と 256-token canvas が何を変えるのか、18GB級の訴求と公式 notebook の重さをどう読むか、standard Gemma 4 とどう使い分けるかまで見ないと、期待値がずれやすい題材です。
この記事を読めば、DiffusionGemma の速さの意味、ローカル実行の現実、そして自分が試す価値があるモデルかどうかを迷わず判断できます.
内容をまとめると…
4倍速の本質は「1 tokenずつ待たない」生成方式
DiffusionGemma は Gemma 4 の上位互換ではなく speed-first の別軸
18GB級の期待値と公式 notebook の重さには隔たりがある
最初は Transformers 経由で小さく試すのが安全
生成AIを「少し触って終わり」にせず、業務効率化・副業・AIエージェント活用までつなげたい方向けに、基礎から実践まで整理できる無料資料を用意しています。
記事とあわせて、AIに作業を任せる考え方や長く使える活用スキルを確認しておきたい方は受け取っておいてください。

DiffusionGemmaはどんなモデル?
まずは、DiffusionGemma を「何者か」から先にそろえます。
DiffusionGemma は、Google が experimental な open model として公開した、速度重視のテキスト生成モデルです。通常の standard Gemma 4 と同じ土俵で万能さを競うというより、単一ユーザーのローカル推論で待ち時間を下げることに主眼があります。
そのため、見るべきポイントは「新しい最強モデルか」ではなく「自分の用途で速さの恩恵が大きいか」です。公式も品質面では standard Gemma 4 の方が強い場面があると示しているので、DiffusionGemma は上位互換ではなく別軸の選択肢として捉えるのが自然です。
この前提を押さえると、次の章で扱う text diffusion やローカル実行条件も、誇大な売り文句ではなく speed-first 設計の延長として読みやすくなります。
DiffusionGemmaの何が速い?
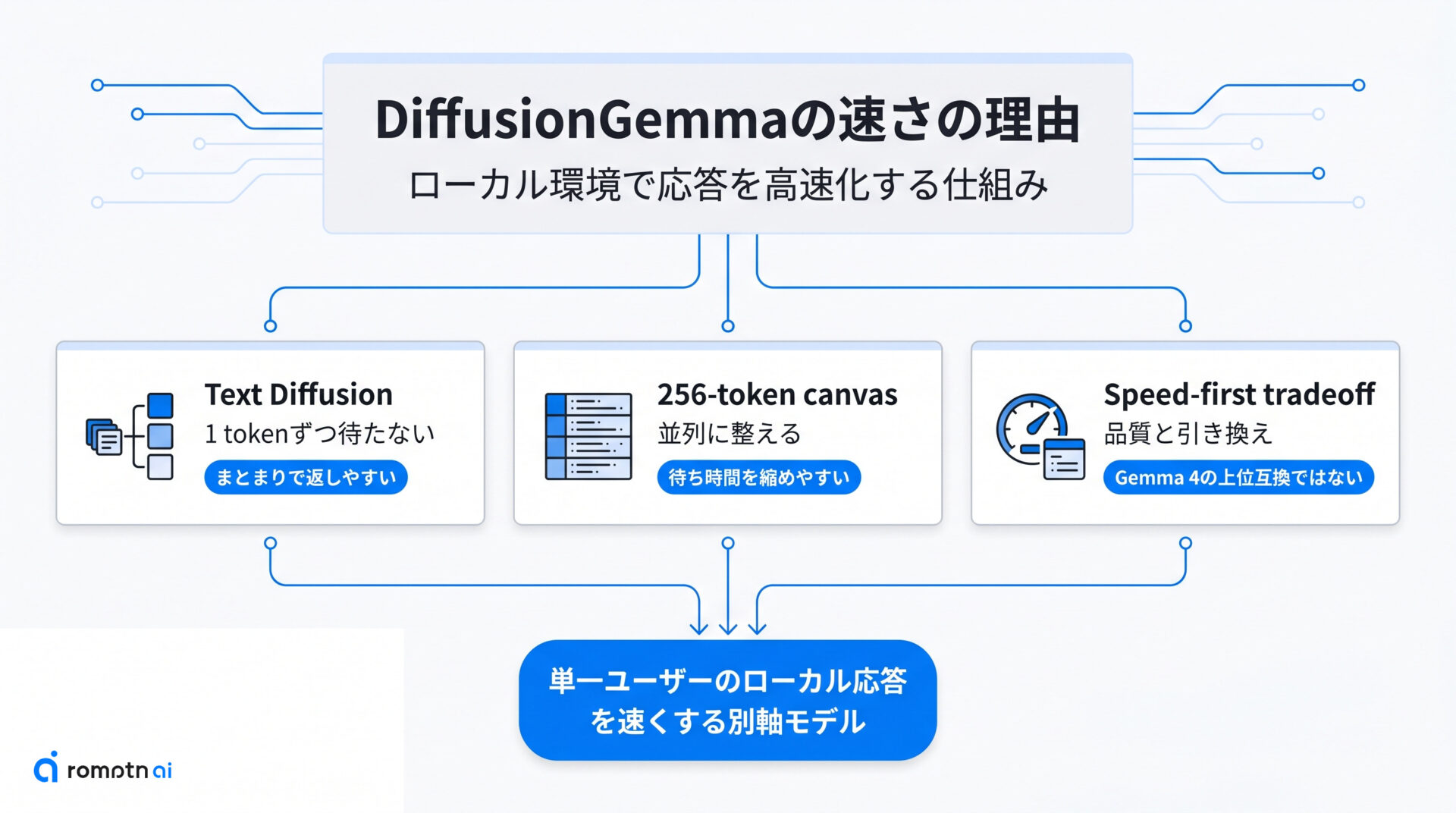
ここでは、「なぜ速いのか」を体感ベースで整理します。
公式が強調するのは、単にベンチマーク数字が良いことではなく、1 token ずつ待つ感覚を縮めやすい設計です。DiffusionGemma は text を順番に1語ずつ伸ばすより、大きめのまとまりを並列に整えていくため、単一ユーザーの対話や下書き生成で待ち時間を削りやすい方向へ振られています。
ただし、速さの理由は1つではありません。次の3つで見ると、text diffusion の考え方、256-token canvas の意味、そして品質との引き換えまでつながって理解できます。
① text diffusionでどう変わる?
通常の autoregressive model は、左から右へ 1 token ずつ確定しながら文章を伸ばします。これだと返答が長くなるほど、読者は「次の1語」を何度も待つことになります。
一方の DiffusionGemma は、最初からある程度の text の塊を置き、それを何度か整えながら答えに近づける発想です。専門用語だけで見ると難しく感じますが、「文章を1文字ずつ彫る」というより「下書きをまとめて直していく」に近いと考えるとイメージしやすくなります。
この違いが、ローカル環境での待ち時間の感じ方を変える土台です。細かい token の積み上げより、まとまった出力を早く返しやすいことが、speed-first という立ち位置につながっています。
② 256-token canvasの意味
DiffusionGemma の説明でよく出てくる 256-token canvas は、256 token 分の作業スペースをまとめて扱う考え方です。1 token ずつ確定させる代わりに、この canvas 全体を何度か更新しながら精度を上げていきます。
読者目線で大事なのは、ここで複数 token を並列に調整できることです。Google はこの設計によって、単一ユーザーの推論を memory-bound から compute-bound に寄せやすいと説明しており、これが待ち時間短縮の根拠になっています。
また、途中で塊ごと整え直せるため、あとから全体の一貫性を寄せやすいのも特徴です。単に「まとめて速い」ではなく、速さと整え直しやすさを両立させようとしている点が DiffusionGemma らしさです。
③ speed-firstの代償はある?
あります。DiffusionGemma は speed-first の設計であるぶん、品質まで standard Gemma 4 を一律に上回るモデルとしては案内されていません。
ここを見落とすと、「4倍速なら全面的に乗り換えるべき」と誤解しやすくなります。実際には、 reasoning の深さや総合的な品質を優先するなら standard Gemma 4 の方が向く場面が残ります。
つまり、DiffusionGemma の価値は「何でも最強」ではなく、「単一ユーザーのローカル応答を速く返したい時に、品質と引き換えでも選ぶ意味がある」ことです。使い分けを前提に見た方が、期待値のズレが起きにくくなります。
ローカルで本当に使える?
ここでは、ローカル実行の期待値を現実的な線でそろえます。
DiffusionGemma で混乱しやすいのは、Google の「18GB級でも視野」という訴求と、公式の Hugging Face notebook が 60GB 超 GPU を前提にしている点が同時に存在することです。これは片方が間違いというより、量子化した軽量経路の話と、公式の最短スタート経路の話が混ざって見えやすいと考えると整理しやすくなります。
見るべきポイントは次の3つです。
つまり、DiffusionGemma は「軽いから安心」ではなく、「条件が合えば speed-first の価値が大きい」モデルとして見るのが安全です。
Gemma 4とどう使い分ける?
ここでは、DiffusionGemma を選ぶべき場面を standard Gemma 4 と切り分けます。
迷った時は、まず重視する軸を比べると判断しやすくなります。
| まず見る軸 | DiffusionGemma | standard Gemma 4 |
|---|---|---|
| 優先する価値 | 低遅延のローカル応答 | 総合的な品質や安定感 |
| 向いている場面 | 単一ユーザーで素早く返したい対話や下書き生成 | 品質を落としたくない推論や比較的重い本番用途 |
| 読み方のコツ | speed-first の別軸モデルとして使う | ベースラインの品質重視モデルとして使う |
要するに、待ち時間を削る価値が大きいなら DiffusionGemma、多少重くても品質を優先したいなら standard Gemma 4 です。どちらが上かではなく、何を先に取るかで選ぶ方が失敗しにくくなります。
試す前に知るべき注意点
ここでは、試し始める前のつまずきどころを先に潰します。
執筆時点では、公式の最短経路として Hugging Face / Transformers notebook が案内されていますが、要求されるライブラリや GPU 条件は軽くありません。vLLM や SGLang の入口も示されている一方で、公開直後は import error や meta device 関連の報告もあり、普段使いの local app まで完全に追いついている段階とは言いにくいです。
迷ったら、まずは公式の Transformers 経路で短い prompt を試し、次に自分が使いたい runtime が DiffusionGemma に追随しているかを確認する順番が安全です。いきなりエディタ統合や別 runtime を前提にすると、モデル自体の問題か周辺実装の問題かを切り分けにくくなります。
よくある質問
- QDiffusionGemmaは画像や動画も入力できますか?
- A
執筆時点では、公式情報の書き方に少し揺れがあります。overview や Hugging Face 側では image や video input に触れている一方、model card の表では text と image を中心に整理されているため、少なくとも text 以外の広がりはあるが、動画まで含めて一般的な用途として断定しない方が安全です。
- Q18GB級GPUがあれば、執筆時点ですぐ快適に動かせますか?
- A
そこは分けて考えるのが安全です。18GB級という訴求は量子化や条件がそろった場合の目安で、公式の最短 notebook 経路はかなり重い前提です。まずは「起動できるか」と「常用して快適か」を別に見て、小さな prompt から確認する方が失敗しにくくなります。
- Qstandard Gemma 4ではなく DiffusionGemma を選ぶべき場面はどこですか?
- A
単一ユーザーでの待ち時間短縮が大きな価値になる場面です。たとえば、ローカルで対話を何度も往復したい時や、下書きを素早く返してほしい時は DiffusionGemma が合います。反対に、多少重くても品質や安定感を優先したいなら standard Gemma 4 を軸に見る方が自然です。
- Qローカルで試すなら、まず Transformers と vLLM / SGLang のどれから入るべきですか?
- A
最初は Transformers から入るのが安全です。公式 notebook があり、モデル自体が動くかを素直に切り分けやすいからです。そのあとで、常用したい runtime として vLLM や SGLang の対応状況を確認すると、周辺実装の成熟度でつまずきにくくなります。
まとめ:DiffusionGemmaは速度重視の別軸モデル
最後に、判断軸だけを短くまとめます。
- DiffusionGemma は「Gemma 4 の上位版」ではなく、低遅延のローカル推論へ寄せた別軸モデル
- 速さの理由は text diffusion と 256-token canvas にあり、そのぶん品質は standard Gemma 4 に譲る場面がある
- 18GB級の訴求は量子化前提の目安で、公式の最短 notebook 経路はかなり重い
- 公開直後なので、runtime の成熟度も確認しながら触る方が安全
まず試すなら、公式の Hugging Face / Transformers 経路で短い prompt から動作確認し、そのあと vLLM や SGLang を検討すると失敗しにくいです。
自分が求めるのが「少しでも高い品質」なのか「単一ユーザーでの待ち時間短縮」なのかを先に決めれば、DiffusionGemma を試す価値があるかはかなり判断しやすくなります。
AIを実務で使い続けるには、ツール名を覚えるだけでなく、目的を分解し、文脈を渡し、出力を評価する力が必要です。AI副業やAIエージェント活用の入口をまとめた資料セットを無料で受け取れます。
無料資料を受け取る

