
Z-ImageのワークフローをCivitaiから落とせば絵はもう出せる。でも配布JSONを開いた瞬間、ノードグラフがただの箱の集まりにしか見えず、どの箱が何を担っているのか読めないまま、自分の用途に合わせた改造で手が止まる——その引っかかりは『使い方』を知らないからではなく、配布物を『構造として読む』視点をまだ手にしていないからです。
この引っかかりは、実は1本の基幹グラフを地図として頭に入れるだけで一気にほどけます。img2imgもinpaintもupscaleも顔の修復も、まったく別のワークフローではなく、同じ1本の流れに同じ発想でノードを足したり差し替えたりしているだけ——その共通構造さえ掴めば、初見の配布物でも触りたいノードへまっすぐ辿り着けます。赤くなったノードも『壊れた』ではなく『どの拡張が足りないか』の目印として読めるようになります。
配布されたJSONを『読めない塊』として眺めるのをやめ、地図とノード群として捉え直す。その構造リテラシーが身につけば、手元の1本を自分の用途へ作り変える力が、別の配布物に乗り換えても長く効き続けます。
内容をまとめると…
配布ワークフローは別々の機能の寄せ集めではなく、1本の基幹txt2imgグラフへノード群を足し引きした差分の集合として読める
img2img・inpaint・upscale・顔の修復の改造点は、結局どこか1つのノードの入力欄(denoise・倍率・しきい値など)に集約する
All-in-One型はノード群のmute/bypassでモードを切り替える層を持ち、使うモードだけ生かせば改造対象も1グループに絞れる
赤ノードはエラーではなく不足している拡張(Impact Pack・rgthreeなど)を指す目印で、逆引きすれば依存を自力でそろえられる
変種・ファイル名・ワークフロー版は更新が速いので、構造を読む力を軸に据え、揺れる具体値は配布ページの指定を正とするのが長持ちする
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

配布JSONを「動かす」から「読む」へ
ここでは、配布されたワークフローを「動かす」だけの段階から、構造として「読む」段階へ踏み出すための地図を渡します。
Civitai から落とした JSON を ComfyUI に放り込めば、Z-Image の絵はもう出せているはずです。引っかかるのはその先です。中身のノードグラフが箱の集まりにしか見えず、どの箱が何を担っているのか読めないと、自分の用途に向けて手を入れられません。
そこで本記事は、配布物を「そのまま使う完成品」ではなく「読み解いて書き換えられる設計図」として扱います。実は配布されたグラフの多くは、1本の基幹的な生成の流れを土台にして、img2img・inpaint・拡大・顔の作り直しといった機能を、その流れにノード群を足したり差し替えたりする形で組み立てています。
だからこの記事は「使えるグラフを5本そろえる」リスト型ではなく、「1本のグラフを深く読む」教科書型で進めます。基幹の流れを地図として頭に入れてしまえば、目の前の配布物がどんな見た目でも、自分が触りたいノードへまっすぐ辿り着けるようになります。
まずは次の章で、その基幹となる1本の流れを地図として読み解いていきます。
基幹txt2imgグラフの地図を読む
配布された JSON がどれだけ複雑に見えても、Z-Image の中心には共通する1本の流れがあります。まずこの基幹を地図として頭に入れると、残りはすべてその周りの飾りとして読めるようになります。
基幹txt2imgグラフは、左から右へ次の一本道で進みます。
Load Diffusion Model → text encoder → CLIP Text Encode(pos / neg)→ KSampler → VAE Decode → Save Imageこの一本道に、生成へ必要な3つのファイルがそれぞれ別のノードから差し込まれます。どのファイルがどのノードに刺さり、そのノードが何をするのかを並べると、地図全体は一目で読めます。
| ノード | 役割 | ここに刺さるファイル |
|---|---|---|
| Load Diffusion Model | 画像を描く本体(拡散モデル)を読み込む | 拡散モデル本体 z_image_bf16 |
| text encoder | 入力した言葉を数値の意味へ変換する土台 | テキストエンコーダ qwen_3_4b |
| CLIP Text Encode(pos / neg) | 描きたい指示(pos)と避けたい指示(neg)を別々に言葉から条件へ変換する | (text encoder の出力を受ける) |
| KSampler | 受け取った条件に沿ってノイズから潜在画像を作る、生成の心臓部 | — |
| VAE Decode | 潜在画像を人が見えるピクセル画像へ戻す | VAE ae |
| Save Image | 出来上がった画像を保存する | — |
つまり3ファイルは、z_image_bf16 が Load Diffusion Model、qwen_3_4b が text encoder、ae が VAE Decode と、刺さる先がきれいに分かれています。どれか1つでも欠けると、その下流のノードが赤くなって止まる、というのが基幹グラフの素直な読み方です。
この一本道さえ掴めば、配布物の正体が見えてきます。img2img も inpaint も upscale も、別物の新しいワークフローではなく、この基幹のどこかにノードを足したり差し替えたりした形にすぎません。次の章からは、その「基幹を包む層」を1つずつほどいていきます。
各機能はノード群の差し替えで作る
基幹グラフの地図が頭に入ったので、ここからはその地図の上で各機能がどう作られているかを俯瞰します。
結論を言うと、img2img も inpaint も upscale も顔の修復も、それぞれが独立した別ワークフローではありません。どれも、さきほど読んだ1本の基幹グラフに対して、必要なノードの一群を足したり、一部を別のノードに差し替えたりして作られています。
たとえば img2img なら、基幹グラフが持つ「空の Latent」の部分を「画像を読み込んで Latent に変換するノード群」に差し替えるだけです。upscale なら、出力の手前に拡大用のノード群を継ぎ足します。骨格は同じまま、入口や出口のノードを入れ替えているだけだと捉えると、見通しが一気に良くなります。
この「ノード群を足す・差し替える」という1つの発想さえ掴めば、複雑そうに見える配布物も、基幹グラフ+差分という形で読めるようになります。
1本のグラフに5つの機能をすべて同居させた配布物では、考え方が少し変わります。ここではノードを物理的に差し替えるのではなく、機能ごとにまとめたノードの一群を、有効化と無効化(mute / bypass)で切り替えています。使いたい機能の一群だけを生かし、残りは眠らせておく、という作りです。
この後の章では、この差し替え・継ぎ足しの中身を、img2img・inpaint・upscale・顔の修復、そして機能を切り替える層の順に、1つずつノード単位で解剖していきます。
①img2img:入力画像とdenoise
img2img は、基幹グラフの Empty Latent Image を外し、Load Image と VAE Encode の 2 ノードに置き換えるだけで作れます。空の Latent の代わりに「すでにある画像を Latent に変換したもの」を入口にする、という差分です。
配線で変えるのは 1 本だけです。Load Image の IMAGE 出力を VAE Encode の pixels 入力へ、VAE Encode の LATENT 出力を KSampler の latent_image 入力へつなぎます。これまで Empty Latent Image から来ていた latent_image への線を、この VAE Encode からの線に差し替えるイメージです。VAE Encode には基幹グラフと同じ VAE を渡します。
もう 1 つ触るのが KSampler の denoise です。txt2img では 1.0(全ノイズから生成)ですが、img2img ではこれを下げます。下げるほど入力 Latent がそのまま残り、上げるほど入力から離れて作り直します。
目安は 0.4〜0.7 あたり。元の配置を保ちたいなら低め、プロンプトで大きく描き直したいなら高めへ振ります。img2img の調整点は実質この denoise 1 つだと捉えると迷いません。
②inpaint:マスクの注入経路
inpaint は、前の節で組んだ img2img の経路に「どこを描き直すか」を伝えるマスクを1本足しただけの形です。土台になる Load Image → VAE Encode → KSampler という流れはそのままで、ここにマスクの注入路が割り込みます。
マスクの作り方は2通りです。Load Image ノードが持つ mask 出力をそのまま使うか、ノード上で右クリックして開く Mask Editor(マスクエディタ)で塗ったマスクを使うかのどちらかです。塗った白い領域が「描き直す場所」になります。
そのマスクを潜在空間へ注入するノードが分岐点です。よく使われるのは Set Latent Noise Mask で、VAE Encode が出した latent にマスクを属性として貼り付け、後段の KSampler へ渡します。配線としては Load Image の mask を Set Latent Noise Mask の mask 入力へ、latent を latent 入力へつなぎます。
もう一つの作法が VAE Encode (for Inpaint) です。こちらは画像とマスクをまとめて受け取り、マスク済みの latent を直接出力するので、img2img の VAE Encode を丸ごとこのノードに差し替える形になります。配布物によってどちらが組まれているかは違うので、まず「マスクがどこで latent に合流しているか」を目で追うのが読み解きの起点です。
denoise の効き方も img2img とは変わります。KSampler の denoise 値は同じ意味のままですが、マスクが付いた latent では、白く塗った領域だけが denoise の強さに従って描き直され、塗っていない領域は元のまま温存されます。つまり値は「画像全体をどれだけ作り直すか」ではなく「マスク内をどれだけ作り直すか」に読み替わります。
③upscale:倍率と再サンプリング
upscale は基幹グラフの末尾、VAE Decode が画像を吐き出した直後に小さなサブグラフを継ぎ足す改造です。基幹の流れを書き換えるのではなく、出力済みの画像をもう一段下流で受け取り、解像度を引き上げて作り直す経路を後ろに伸ばします。
配布物でこの役を担うのは Upscale 系ノードです。素朴な拡大なら Upscale Image By、繰り返し拡大なら Iterative Upscale、タイルに割って一段ずつ作り直すなら Ultimate SD Upscale が置かれます。分散構成のワークフローでは Tile 系 upscaler や SeedVR2 が同じ位置に入ることもあります。
触り所は2つだけと考えると見通しが良くなります。1つ目は 倍率(scale_by や upscale_by) で、これは上記の Upscale ノード本体が持つ入力欄です。元の何倍の大きさにするかをここで決めます。
2つ目は 再サンプリングの強さ です。拡大しただけでは輪郭が甘くなるため、拡大画像を latent に戻して KSampler でもう一度通します。この再生成の効き具合を握るのが、その KSampler 側の denoise です。
値を低くすると元画像をほぼ温存したまま輪郭だけ締まり、高くすると拡大時にディテールを大きく描き直します。配布 JSON を読むときは、倍率は Upscale ノード、作り直しの強さは下流 KSampler の denoise、と役割で切り分けて追うと迷いません。
④FaceDetailer:検出と修復
FaceDetailer は基幹グラフ本体には手を入れず、VAE Decode で画像になった後ろに足す後処理ノードです。Impact Pack が提供する1つのノードの中に、顔を見つける検出と、その顔だけ作り直す修復の2段が入っています。
検出側はノードに刺した bbox_detector(顔を四角で囲むモデル)が担い、bbox_threshold で「どれくらい顔っぽければ拾うか」を決めます。低くすると小さな顔まで拾い、高くすると確実な顔だけに絞れます。
修復側は、拾った顔を切り出して(crop)、その範囲だけをもう一度サンプリングし(再生成)、元の位置に貼り戻す(paste)流れです。触り所は3つで、denoise が作り直しの強さ、feather が貼り戻す縁のぼかし幅(目安は5前後で境目を馴染ませる)、force_inpaint が顔の範囲をマスク扱いで描き直すかの切り替えです。
複数人や顔以外も整えたい場合は、出力に DETAILER_PIPE を持つ FaceDetailer (pipe) を使い、後ろに別の Detailer を連結して多段で回せます。
⑤switch:モードを切り替える層
All-in-One 系の配布物は、ここまでの分岐を別々のグラフに分けず、1本のキャンバスに全部並べて同居させています。そのままだと全部が一度に走ってしまうので、各分岐のノード群を「いま使う1つだけ生かす」ための仕切りが要ります。それが switch の層です。
仕切りの正体は、rgthree の Fast Groups Muter / Bypasser のようなトグル系ノードです。ノードを グループ単位でまとめて mute(無効化)/ bypass(素通し) し、オフにしたグループだけ計算から外します。Load Image を抱えた img2img のグループ、Set Latent Noise Mask を含む inpaint のグループ、Upscale 系のグループ、FaceDetailer のグループが、それぞれ1つのスイッチに紐づいている、という読み方です。
どのモードが生きているかは、ノードを見れば判別できます。mute されたグループはノードが暗く沈み、bypass されたグループは枠線の色が変わって配線を素通りします。トグル側のオン/オフ表示と、グループのタイトルバーの状態がセットで「いま走るのはどれか」を示しています。
やることはシンプルで、自分が使うモードのグループだけをオンにし、残りは全部オフにします。これで余計なノードが走らず、改造で値をいじる対象も1グループに絞れます。逆に「動くはずの機能が出力に効かない」時は、そのグループのスイッチがオフのまま、という見落としを真っ先に疑ってください。
改造で触るノードとparamの早見
ここまでで各機能がノード群の差し替えだと分かったので、最後に「自分の用途に向けて何を変えたいとき、どのノードのどの入力欄を触ればいいか」を一枚にまとめておきます。
配布ワークフローを開いたら、変えたい項目を左の列から探し、対応するノードを画面上で選んで、その入力欄の値を書き換える、という読み方で使えます。ノード名はワークフロー作者によって日本語ラベルが付いていることもありますが、機能は同じです。
| 変えたいこと | 触るノード | 入力欄 |
|---|---|---|
| 使うモデル本体を変える | Load Diffusion Model | unet_name(モデルファイルの選択) |
| 出力サイズ(縦横の画素)を変える | Empty Latent Image | width / height |
| サンプラーや反復回数を変える | KSampler | sampler_name / steps / cfg |
| 元画像をどれだけ作り変えるか | KSampler | denoise |
| inpaint で塗り直す範囲を指定する | Set Latent Noise Mask / VAE Encode (for Inpaint) | mask(マスクの入力) |
| 拡大の倍率を変える | Upscale 系ノード | scale_by(拡大率) |
| 顔を検出する範囲を調整する | FaceDetailer | bbox_threshold / feather |
| 顔の作り直しの強さを変える | FaceDetailer | denoise |
同じ denoise でも、基幹グラフの KSampler に置くか FaceDetailer の中に置くかで効く対象が違う点だけ注意してください。前者は画像全体、後者は切り出した顔だけにかかります。
推奨されるサンプラーやステップ数、解像度の具体的な値は Base と Turbo の変種で変わるため、後ほどの『変種とバージョンの比較リファレンス』の章で一覧にしています。ここでは「どこを触るか」だけ押さえておけば十分です。
赤ノードの正体と直し方
前の章で触り所のノードを一望しました。ところが配布物を読み込んだ瞬間、肝心のノードが赤く表示されて手が止まることがあります。ここではその赤ノードの読み解き方を扱います。
赤いノードは、エラーではなく「このノードを提供する custom node(拡張)が、いまの ComfyUI に入っていない」というサインです。配布ワークフローは標準ノードだけでなく、第三者が公開した拡張のノードを前提に組まれているため、その拡張が無いと該当ノードだけが赤くなります。
つまり赤ノードは「どの機能の拡張が欠けているか」を指す目印として読めます。赤くなっているノード名から、足りない拡張を逆引きできます。
| 赤くなるノード | 欠けている拡張 |
|---|---|
| FaceDetailer・Detailer 系 | Impact Pack |
| グループ切替・スイッチ系のノード | rgthree-comfy |
| GGUF 形式のローダー | ComfyUI-GGUF |
| 配布元だけの見慣れないノード | その作者独自の拡張 |
足りない拡張は、次の順番でまとめて揃えるのが確実です。
- ComfyUI Manager を開く
- 不足している拡張をインストールする
- ComfyUI を再起動して読み込み直す
再起動後も赤いままなら、拡張は入ったが ComfyUI 本体や他拡張とのバージョン整合が取れていないケースを疑います。どの拡張がどの版に対応するかは、後ほどの『変種とバージョンの比較リファレンス』の章にまとめて整理しています。
赤ノードを「壊れている」と捉えると直し方が見えませんが、「この機能の拡張がまだ無い」と読み替えれば、入れるべき拡張が一意に決まります。この読み方ができれば、初見の配布物でも依存を自力で揃えられます。
5本そろえるか1本を深く読むか
依存ノードまで揃え終えたら、最後に運用の方針を1つ決めておきたい。txt2img・img2img・inpaint・upscale・FaceDetailer を別々のワークフローで5本そろえるか、1本の同居型グラフを深く読むか、という方針です。
この記事は後者を推しています。理由ははっきりしていて、配布されている実物の多くが、すでに分岐を1グラフに同居させているからです。
All-in-One Turbo や 3-in-1 Combo は、複数の用途を別ファイルに分けず、1つのグラフへ束ねて配っています。各用途は「モードを切り替える層」の章で見たとおり、mute / bypass でノード群をオンオフして切り替わります。
この形を読み解く力は、1本に閉じません。どのノードが何を担い、どこで配線が分岐するかという読み方は、別の配布物に乗り換えても通用します。5本を別々に覚えるより、構造を読む力の方が長持ちします。
もちろん、別々にそろえる方が合う場面もあります。
| 方針 | 効くのはこんな時 |
|---|---|
| 1本を深く読む | 同居型をそのまま改造したい / 複数用途を1グラフで回したい / 構造を覚えて他の配布物にも応用したい |
| 別々にそろえる | 1用途だけを徹底的に作り込む / 不要な分岐を物理的に外して軽く保ちたい / チームで用途ごとに配布を分けたい |
用途を1つに絞って深く作り込んだパイプラインは、同居型の switch を持たない方がむしろ見通しが良くなります。自分がどちらに寄っているかを決めてから、次の章の比較リファレンスで自分の変種に必要な設定だけを拾ってください。
変種とバージョンの比較リファレンス
ここまで読んだノードの役割は変わりませんが、変種・ファイル名・ワークフロー版・依存ノードは更新が速く、最初に踏むつまずきもここに集中します。手元の配布物がどれに当たるかを照らし合わせられるよう、執筆時点での対応関係をまとめておきます。
まず Z-Image 本体には2つの変種があります。Base は蒸留前の土台モデルで、LoRA 学習やファインチューニングの基盤に向きます。Turbo はそれを蒸留した少ステップ高速版で、配布ワークフローの大半はこちらを前提に組まれています。どちらを使うかでステップ数とサンプラーの噛み合わせが変わるため、設定はセットで覚えるのが安全です。
| 変種 | 位置づけ | ステップ / サンプラーの噛み合わせ |
|---|---|---|
| Z-Image Base | 蒸留前のファインチューニング土台 | 多めのステップで通常のサンプラーを回す前提。少ステップ設定をそのまま流用すると品質が出ない |
| Z-Image Turbo | 蒸留済みの少ステップ高速版 | 少ステップ+専用の噛み合わせが前提。Base 用の重い設定を当てると速度の利点が消える |
次に、どの変種でも基幹グラフが要求する必須ファイルは共通です。3つのファイルがそれぞれ別のフォルダに入る点が、赤ノードを生む最初の落とし穴になります。
| ファイル | 置き場所 | 役割 |
|---|---|---|
| qwen_3_4b.safetensors | models/text_encoders/ | プロンプトを読むテキストエンコーダ |
| z_image_bf16.safetensors | models/diffusion_models/ | 画像を生成する本体モデル |
| ae.safetensors | models/vae/ | latent と画像を相互変換する VAE |
さらに配布されているワークフロー版は、執筆時点で次のものが代表的です。同じ作者でもファイル形式や同居構成で枝番が分かれます。
| ワークフロー | 版 | 特徴 |
|---|---|---|
| AmazingZImageWorkflow | v4.0 | GGUF 版と SAFETENSORS 版が用意され、量子化ファイルか通常ファイルかで選ぶ |
| All-in-One Z-Image Turbo | v5.0 | txt2img から後処理までを1本に同居させた Turbo 前提の構成 |
最後に、これらを動かすために要求される custom node です。import 時の赤ノードは、ここのどれかが未導入かバージョン差であることをほぼ示します。
| 依存ノード | 主な担当 |
|---|---|
| rgthree-comfy | グループの mute/bypass によるモード切替 |
| ComfyUI-Impact-Pack | FaceDetailer など検出・修復系の後処理 |
| ComfyUI-GGUF | GGUF 量子化モデルの読み込み |
| 作者独自の拡張 | 各配布物に固有のユーティリティ群 |
ここに挙げた版・ファイル名・依存は更新で入れ替わることがあるため、自分の配布物を開く前に、その配布ページが指定している組み合わせを正としてください。
よくある質問
- Q配布ワークフローのJSONはどこから構造を読み始めればいいですか?
- A
まず基幹のtxt2imgグラフを背骨として探してください。モデルを読み込むノードから、プロンプトを処理するエンコード、ノイズを除去するKSampler、画像に戻すVAE Decode、保存までの一本道です。
この背骨を見つけてしまえば、残りのノード群はそこに枝として足された改造分だと読めます。配布物は基幹を起点に外側へ読み広げるのが最短です。
- Qtxt2imgとimg2imgはノードグラフ上で何が違うのですか?
- A
どちらも同じ背骨を使い、入口の作り方だけが違います。txt2imgが空のLatentから始めるのに対し、img2imgはそこをLoad ImageとVAE Encodeに差し替え、入力画像を出発点にします。
さらにKSamplerのdenoiseを下げ、元画像をどれだけ残すかを決めます。つまり別物のワークフローではなく、入口ノードと一つの値の差分だと捉えてください。
- QFaceDetailerやupscaleが赤ノードになるのはなぜですか?
- A
赤いノードは、そのノードを提供するカスタムノードのパックが入っていないという合図です。FaceDetailerならImpact Pack、モード切替まわりならrgthreeのように、配布物が前提にしている拡張が未導入だと、その箇所だけ赤く欠けます。
足りないパックを入れて読み込み直せば赤は消えます。どのパックが必要かは、後ほどの『変種とバージョンの比較リファレンス』の章にまとめています。
- QBaseとTurboのどちらを前提に改造すればいいですか?
- A
腰を据えて品質や作り込みを追うならBase、とにかく軽く速く回したいならTurboが向きます。Turboは少ないステップで仕上がるよう調整された変種なので、Base向けの設定値をそのまま流用すると「動くが品質が出ない」改造ミスにつながりやすい点に注意してください。
推奨ステップやサンプラーなど変種に紐づく値は、後ほどの『変種とバージョンの比較リファレンス』の章で対応づけています。
- QAll-in-One1本と独立した5本、どちらを使うべきですか?
- A
構造リテラシーを身につけたいなら、All-in-One1本を深く読むのをおすすめします。txt2imgやimg2img、inpaint、upscale、顔の修復といったモードは同じ背骨を共有しており、1本を読み解けば各モードの差分が同時に見えるからです。
独立した5本は、特定モードだけを軽く回したい場合や、他人に渡す最小構成として有効です。学ぶ目的か使い回す目的かで選び分けてください。
配布ワークフロー改造のまとめ
ここまでで、配布ワークフローを「動かす」段階から「構造として読む」段階へ進めてきました。最後に、改造の軸になる読み方をひと続きで振り返ります。
配布物がどれだけ巨大に見えても、土台にあるのは1本の基幹グラフです。各機能は、その地図のどこに何を足すかという視点で整理できます。
- 基幹txt2imgグラフは地図:画像生成の本流はこの1本で、ほかの機能はすべてこの地図への追記として読める
- 各機能はノード群の差し替え:img2img・inpaint・upscale・顔の修復は、別物ではなく基幹への追加や置き換えで生まれる
- All-in-Oneは切り替えの層:1本に同居した複数モードは、使わない側をオフにする切り替えの仕組みで成り立っている
- 触り所はノード単位:画像の大きさ・denoise・倍率・検出のしきい値など、変えたい値は必ずどこか1つのノードの入力欄にある
この読み方が身につくと、改造は「どこを触ればいいか分からない」から「目的のノードを探す作業」に変わります。
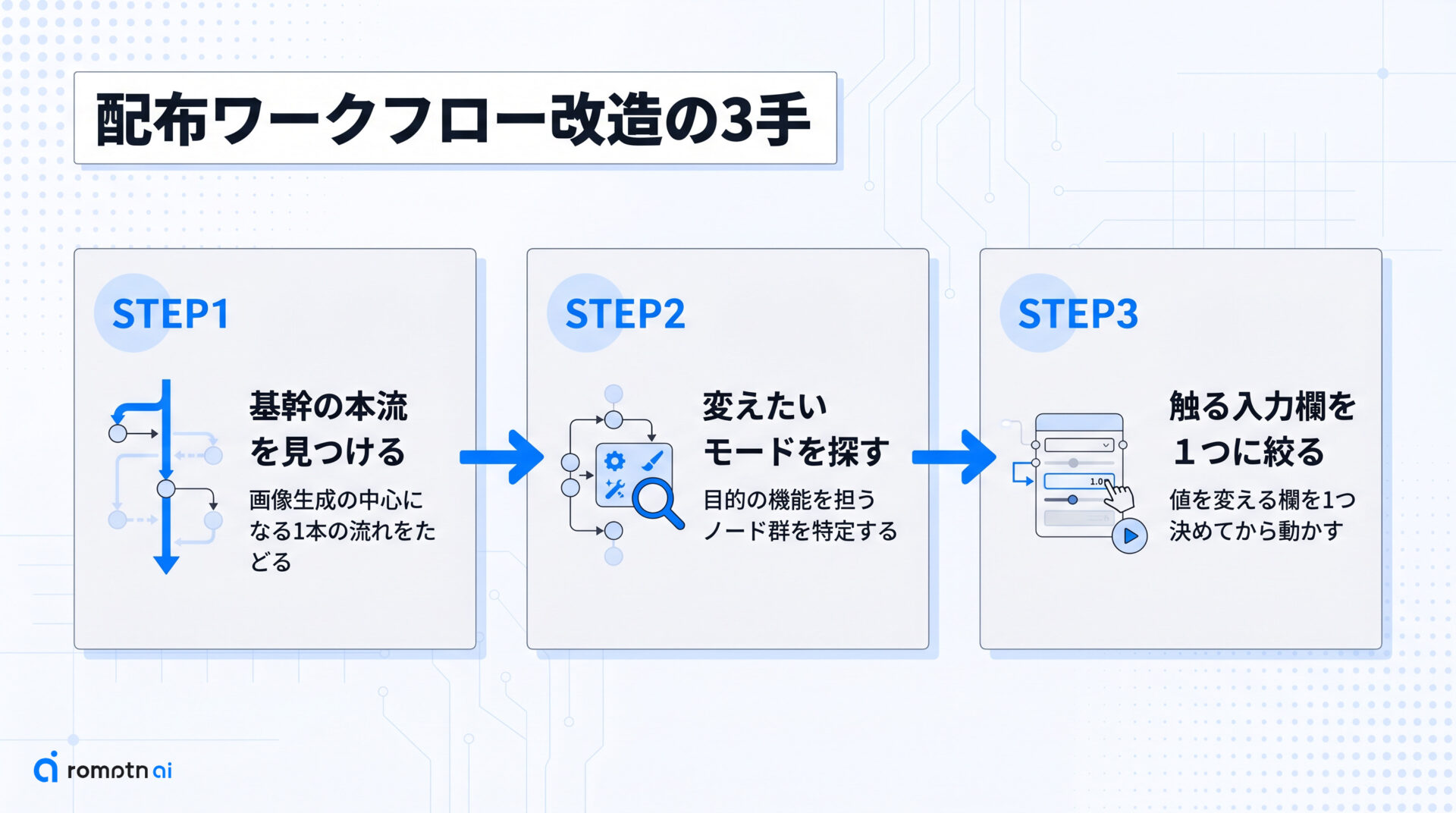
次の一手は、自分が落とした配布ワークフローを開き、3手で当たりを付けることです。
- 基幹の本流を見つける:画像生成の中心になっている1本の流れを最初にたどる
- 変えたいモードのまとまりを探す:img2imgや顔の修復など、目的の機能を担うノード群を特定する
- 触る入力欄を1つに絞る:そのまとまりの中で、実際に値を変える欄を1つ決めてから動かす
配布物を「読めない塊」として眺めるのをやめ、地図とノード群として捉え直す。その視点があれば、手元の1本を自分の用途に合わせて作り変えていけます。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

