
Mistral Search Toolkit が気になっても、公開告知や docs を流し見しただけでは「結局どこまでできて、何を用意すれば試せるのか」が掴みにくいはずです。先に結論を言うと、これは RAG 検索基盤を継ぎはぎせずに、ingestion・retrieval・evaluation ごとまとめて試したい人向けの OSS です。
しかも starter app と Quickstart がそろっているので、Vespa 前提の最小構成で最初の検索まで一気に確認できます。単なる新機能紹介ではなく、何が新しく、既存の RAG 構成とどこが違い、どこまで本番目線で検証してよいかまで整理しておくことに価値があります。
この記事を読めば、Search Toolkit でできること、導入前に必要なもの、最短セットアップの流れ、相性のよいケースと注意点までまとめて判断できるようになります。
内容をまとめると…
Search Toolkit は ingestion・retrieval・evaluation を一体で回す検索基盤
starter app と Vespa でサンプル検索まで一度通せば、導入可否の感触を早く掴める
価値の中心は RAG 部品の寄せ集めではなく retrieval 品質の改善ループ
本番判断は public preview を前提に small start で見極めるのが安全
生成AIを「少し触って終わり」にせず、業務効率化・副業・AIエージェント活用までつなげたい方向けに、基礎から実践まで整理できる無料資料を用意しています。
記事とあわせて、AIに作業を任せる考え方や長く使える活用スキルを確認しておきたい方は受け取っておいてください。

Search Toolkitで何ができる?
ここでは、Mistral Search Toolkit が RAG 検索基盤のどこまで面倒を見てくれるのかを先に整理します。
Mistral Search Toolkit は、ingestion・retrieval・evaluation をまとめて扱う Python 製の open-source framework です。単にベクトル検索を足す小道具ではなく、文書を取り込み、検索し、検索品質を評価しながら改善する流れを一つの基盤としてそろえる発想が中心にあります。
執筆時点では public preview として公開されており、公式 docs でも production-ready な IR framework という位置づけです。つまり、学習用サンプルではなく、BM25・vector・hybrid の切り替えや reranking まで見据えた検索基盤として設計されています。
まずは「RAG の周辺部品を継ぎ足す」のではなく、「検索基盤そのものを一体で作る OSS」だと捉えると、このあとに出てくる導入条件や Vespa 前提の意味がつかみやすくなります。
導入前に必要なもの
ここでは、実際に触り始める前に詰まりやすい前提条件をまとめます。
最短で試すルートでも、Search Toolkit はブラウザだけで完結するサービスではありません。公式 Quickstart では Python 3.12 以上、Docker、Mistral API key、依存管理用の uv、そしてローカルで動かす Vespa を前提にしています。
特に見落としやすいのは、検索エンジン部分を自前で持つ前提だという点です。アプリだけ起動すれば終わりではなく、文書の取り込み先と検索インデックスをローカルで用意する必要があります。
もし「まず雰囲気だけ見たい」という段階なら、先に starter app の構成を眺めてから環境準備へ入るほうが迷いにくいです。逆に Docker やローカル検索基盤の準備が難しい環境では、いきなり本番利用を考えず、小さな検証から始めたほうが安全です。
最短セットアップ手順
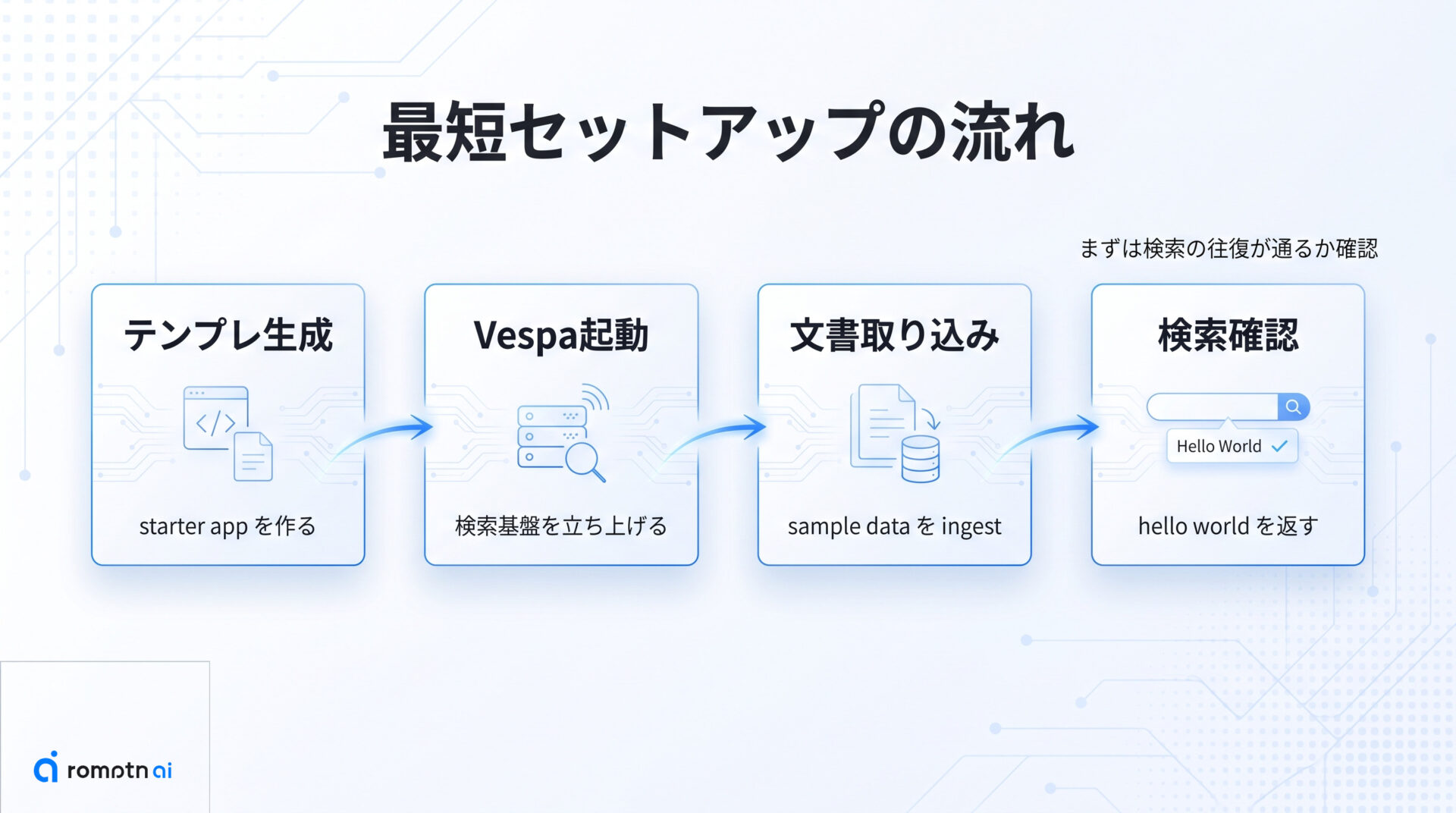
ここでは、starter app と公式 Quickstart をつないだ最短ルートだけに絞って流れを見ます。
最初の全体像はシンプルで、テンプレートからプロジェクトを生成し、Vespa を立ち上げ、サンプル文書を取り込み、検索結果を返すところまで確認すれば十分です。細かい最適化や独自データ投入はそのあとでよく、最初から構成を広げすぎないほうが Search Toolkit の役割をつかみやすくなります。
この流れで重要なのは、検索 UI を作ることより先に、取り込みと検索の往復が通るかを確認することです。Search Toolkit は retrieval の改善まで含めた基盤なので、最初の一歩も「入れた文書がちゃんと見つかるか」を軸にすると理解がぶれません。
次の 2 つの小見出しでは、テンプレート生成と初回検索までの最小コマンド列を順番に見ていきます。
① テンプレートを生成する
starter app は Copier template として配布されているので、まずは土台を生成します。公式リポジトリのまま始めると、Search Toolkit と Vespa をどう結び付けるかを自分で配線し直す手間を減らせます。
最小手順は次のとおりです。
uvx copier copy gh:mistralai/search-starter-app my-search-project
cd my-search-project生成時にアプリ名や初期設定を聞かれますが、最初は大きく悩まなくて構いません。大事なのは、ここで出来上がるひな形が「検索 UI」ではなく、ingestion・retrieval・evaluation を前提にした検索アプリの骨組みだという点です。
② Vespaで初回検索する
テンプレート生成後は、Vespa を起動してサンプル文書を入れ、検索が返るところまで確認します。最初から大量データを流すより、短いテキストで往復を通すほうが原因切り分けがしやすくなります。
公式の starter app で追いやすい最小コマンド列は次の流れです。
make setup-vespa
make ingest path=sample_data/hello.txt
make search query="hello world"この段階で確認したいのは、Vespa が立ち上がること、取り込んだ文書が index に入り、検索語に対して結果が返ることの 3 点です。ここまで通れば、その後に BM25 なのか hybrid なのか、reranking をどう足すかという改善フェーズへ進めます。
内部構成を整理する
ここでは、Search Toolkit を 3 層に分けて見ると理解しやすい理由を整理します。
1 つ目は ingestion です。文書の読み込み、chunking、前処理、投入先への書き込みまでを pipeline として扱うので、単発の埋め込み処理よりも「どう流し込むか」を設計しやすくなります。
2 つ目は retrieval で、vector・BM25・hybrid の切り替えに加えて、query rewriting や reranking まで含めて QueryEngine 側で組み合わせられます。検索品質を上げるときに、検索方式と後段の並べ替えを別々の道具で継ぎ足さずに済むのが大きな利点です。
3 つ目は evaluation です。取り込めたかで終わらず、検索結果の良し悪しを見ながら改善ループへ戻せるため、Search Toolkit は単なる検索ラッパーではなく、検索基盤の改善サイクルを持つフレームワークとして理解したほうが実態に近いです。
既存RAG基盤との違い
ここでは、既存の継ぎはぎ型 RAG 構成と比べたときの違いを絞って見ます。
よくある RAG 構成では、文書投入、検索、再ランキング、評価を別のライブラリや自前コードでつないでいきます。これでも動きますが、検索品質を改善したい段階になると、どこを直せば効くのかが見えにくくなりがちです。
Search Toolkit は最初から検索基盤として統合されているので、BM25 と vector の切り替え、hybrid 検索、query rewriting、reranking を同じ流れの中で扱いやすくなります。さらに Vespa 前提で search index を持つため、単なるサンプル RAG よりも検索エンジン寄りの考え方で改善を進めやすい点が違いです。
要するに、「LLM に文書を渡す前段を何とかする」ための寄せ集めではなく、「検索そのものを良くする基盤」をまとめて持ちたい人に向いた設計だと言えます。
向いているケースと注意点
ここでは、どんなケースで相性がよく、どこで慎重になるべきかを分けて考えます。
相性がよいのは、社内文書検索や RAG API を作るだけでなく、retrieval 品質を評価しながら改善したいケースです。特に agent が大量に検索を叩く前提では、取り込みから検索、評価までを一体で扱える価値が出やすくなります。
一方で、執筆時点では public preview なので、運用ノウハウや大規模実績まで含めて成熟していると決め打ちしないほうが安全です。Vespa を含むローカル検証環境をまず小さく回し、投入データ量や検索要件を見ながら本格導入を判断する進め方が現実的です。
「まず試したい OSS」でもあり、「すぐ全面移行する基盤」とは限らないという温度感を持っておくと、期待値がぶれにくくなります。
よくある質問
- QMistral Search ToolkitはLangChainやLlamaIndexの代わりになりますか?
- A
完全な置き換えと考えるより、検索基盤に特化した別の立ち位置だと見るほうが正確です。LangChain や LlamaIndex はアプリ全体の接続役として使われる場面が多い一方で、Search Toolkit は ingestion・retrieval・evaluation をまとめて改善する検索インフラ寄りの設計です。
- QVespaを使わずにSearch Toolkitを試すことはできますか?
- A
最短ルートとしては Vespa 前提で考えたほうがよいです。公式 Quickstart と starter app の両方で Vespa を中心にした流れが案内されているため、まずはその構成で動かし、あとから自分の要件に合わせて検討するほうが迷いにくくなります。
- Qpublic previewの段階でも本番導入を前提に検証してよいですか?
- A
検証自体は進めて問題ありませんが、いきなり全面移行の前提で見るのは早いです。執筆時点では公開直後の段階なので、まずは小規模データで retrieval 品質や運用負荷を確かめ、本番要件に足りるかを段階的に見たほうが安全です。
まとめ
ここでは、Search Toolkit をどう見るべきかを最後にまとめます。
Mistral Search Toolkit は、文書取り込み、検索、評価までを一体で回したい人に向いた OSS です。特に RAG 検索基盤を継ぎはぎで組むのではなく、改善サイクルごとまとめて持ちたい場合に強みが出ます。
重要ポイントを振り返ると、次の 4 点です。
- Search Toolkit は ingestion・retrieval・evaluation をまとめて扱える
- 最初に確認すべき前提は Python、Docker、API key、uv、Vespa
- 最短の入口は starter app から Vespa で初回検索まで通す流れ
- 本番判断は small start で retrieval 品質を見てから進める
次に動くなら、まず starter app でサンプル検索を 1 回通し、そのうえで自分のデータをどの pipeline で取り込むかを決めるのが自然です。検索精度の改善余地まで見え始めると、Search Toolkit を使う意味もかなり具体的になります。
最初の検証で「検索基盤として筋がよいか」を見極める意識で触ると、この OSS の価値を判断しやすくなります。
AIを実務で使い続けるには、ツール名を覚えるだけでなく、目的を分解し、文脈を渡し、出力を評価する力が必要です。AI副業やAIエージェント活用の入口をまとめた資料セットを無料で受け取れます。
無料資料を受け取る

