
ChatGPTを使っていて、「あれ?この情報、本当に正しいのかな…」と不安になったこと、ありませんか?
実は、ChatGPTをはじめとするAIツールは、時に事実と異なる情報を自信満々に答えてしまうことがあります。この嘘をつく現象は「ハルシネーション(幻覚)」と呼ばれ、多くのユーザーが直面する課題の一つなんです。
でも、安心してください!ChatGPTが間違える理由を理解し、適切な使い方を知ることで、この問題を大幅に減らすことができます。
今回は、ChatGPTが嘘をついたり間違えたりする具体的な理由から、誤りを防ぐための実践的なプロンプトの工夫、さらには自分でできるファクトチェックの方法まで、徹底的に解説していきます!
内容をまとめると…
ChatGPTが嘘や間違いを起こす理由として、学習データの限界や質問の意図の誤解、不明点の推測での補完などがある
誤りを防ぐためのプロンプトの工夫として、明確・具体的に質問すること、段階的に分解して質問すること、関連資料を提供し不明点は答えないように指示することなどが挙げられる
プロンプト以外の工夫として、ブラウジング機能の活用や最新モデルの使用、GPT自身にファクトチェックをさせることが有効
自分自身でのファクトチェックは不可欠!AIの回答を鵜呑みにせず、必ず検証する
生成AIを「少し触って終わり」にせず、業務効率化・副業・AIエージェント活用までつなげたい方向けに、基礎から実践まで整理できる無料資料を用意しています。
記事とあわせて、AIに作業を任せる考え方や長く使える活用スキルを確認しておきたい方は受け取っておいてください。

ChatGPTが間違いやすい3つの状況
ChatGPTは、AIの言語モデルとして非常に優れた能力を持っていますが、時として誤った情報を生成してしまうことがあります。この現象は「ハルシネーション」と呼ばれ、AIが学習データにない情報を生成したり、文脈に合わない回答を提供したりすることを指します。
ここでは、ChatGPTが誤った回答を生成しやすい場合について解説します。
リアルタイムの出来事や最新ニュースについての回答
ChatGPTは、一定の期間までのデータを学習していますが、そのカットオフ以降の最新情報については学習していない可能性があります。
そのため、リアルタイムの出来事や最新のニュースについては情報が不足しており、現在進行中の事象や直近のニュースに関する質問に対しては、誤った回答や古い情報を提供してしまうことがあります。
例えば、カットオフ以降に発生した大きな事件や災害、新しい技術トレンドなどについて尋ねられても、正確な情報を提供できないことがあります。
ChatGPTを使用する際は、その限界を理解し、最新の情報が必要な場合は他の信頼できる情報源も参照することが重要です。
特定の専門領域に関する回答
ChatGPTは幅広い知識を持っていますが、特定の専門領域に関する深い知識や最新の情報を持ち合わせていない場合があります。これは、ChatGPTの学習データが特定の期間に限定されており、全ての専門分野の情報を網羅していないためです。
例えば、医療や法律、科学技術などの専門的な質問に対して、ChatGPTが詳細かつ正確な回答を提供できない可能性があります。これは、専門用語の理解不足や、最新の研究成果や事例に関する知識の欠如によるものです。
デジタル化されていない情報の回答
ChatGPTは、インターネット上で公開されているデジタルデータを基に学習されています。そのため、書籍や雑誌、古い文書など、デジタル化されていない情報については、正確な回答ができない場合があります。
例えば、絶版になった古い本の内容や、地方の図書館にしか所蔵されていない資料の詳細などは、ChatGPTの知識の範囲外である可能性が高いです。また、特定の地域や組織に固有の情報、非公開の情報なども、ChatGPTが学習していないデータである可能性があります。
こうした情報が必要な場合は、図書館や専門家に相談するなど、他の手段を検討する必要があります。
ChatGPTは本当に嘘をつくの?実際に検証
ここでは、具体的なプロンプトを使ってChatGPTが誤った情報を生成しやすい状況を実際に検証してみましょう!
検証①:「量子テレポート通信株式会社」の代表取締役の名前を教えて
これは架空の会社名です。ChatGPTがこの質問に対してどう回答するかで、ハルシネーションが起こるか確認できます。

結果、「確認できない」と正しい情報が出力されました。
検証②:渋谷駅前にある「有名な銅像」の名前を教えて
地理的な情報について質問をしてみました。これは渋谷にある「忠犬ハチ公像」についての質問です。

結果、「忠犬ハチ公」という正確な回答が出力されました。
しかし、住所については「東京都渋谷区道玄坂2-1-1」というのが正しい情報のようであり、「1丁目」というのや誤りであると考えられます。
また、飼い主の名前や由来、建てられた年については正しい情報が出力されているようです。
検証③:347×83-1,256÷8の答えを教えて
複数の演算を含む複雑な計算問題です。

結果、正しい回答が出力されました。
これらの検証はGPT-5のモデルを使用して行ったため、比較的正しい情報が出力されたということができるかもしれません。
ChatGPTが嘘をついたり間違えたりする4つの理由
ChatGPTを使っていて「あれ?これ、なんか違うな…」と感じたこと、ありませんか?
ChatGPTが間違った情報を提供してしまうのには、いくつかの明確な理由があります。これを理解しておくことがChatGPTを活用する上で非常に重要です。
理由①事前学習の問題:ランダムな事実には弱い
ChatGPTをはじめとする言語モデルは、「次に来る単語を予測する」ことで文章を生成します。これは人間が文脈を理解して話すのとは異なり、過去の膨大なテキストの統計的パターンをもとにもっともらしい次の言葉を選ぶという仕組みです。
この原理は、文法や語彙の一貫性、一般的な知識の再現には非常に強力ですが、同時に「ランダム性を含む事実」に対しては構造的に弱いという限界を持っています。
たとえば、モデルは「猫」と「犬」を見分けることは得意でも、「その猫の誕生日」を当てることはできません。誕生日のような情報はパターンではなく偶然によって決まるため、どれほど優秀な学習をしても誤りを避けられないのです。
OpenAIの分析によれば、この「パターンから外れる事実」こそがハルシネーションを生む原因となります。
言語モデルがほとんどスペルミスをしないのは、正しい綴りに一貫したパターンがあるからです。しかし、世界中のあらゆる誕生日や住所、製品価格といった情報は一定の規則性を持たず、学習データだけでは正確に予測できません。
その結果、モデルは「確率的に最も自然そうな答え」を提示し、自信ありげな誤答をしてしまうことがあります。
理由②事後学習の問題:評価手法が推量を促す
ChatGPTが自信満々に間違えるのは、学習後の評価の仕組みに原因があります。
モデル自体が「嘘をつこう」としているわけではなく、「当てずっぽうでも答えた方が高く評価される」という構造的な報酬設計が、推量を促してしまうのです。
これは、四択テストで「わからない」と空欄にするより、勘でマークした方が得点のチャンスがあるようなものです。AIモデルの評価でも、正答率のみを重視すると、「分かりません」と回答する慎重なモデルよりも、運よく正解することを狙うモデルの方が高スコアを得やすくなります。その結果、AIは「曖昧なときに答えを控える」よりも「自信ありげに答える」方向に最適化されてしまうのです。
OpenAIの内部テストでもこの傾向が確認されています。たとえば、古いモデル(OpenAI o4-mini)は正答率がわずかに高くても、エラー率(ハルシネーション率)が75%に達していました。一方で、GPT-5は誤答を減らし、「わからない」と棄権する割合を増やす方向に進化しています。

つまり、現在の評価方法は「慎重さ」よりも「当て推量」を評価してしまう傾向があります。OpenAIはこの仕組みを見直し、誤った回答には減点を、不確実な場合に正直に「わからない」と伝える姿勢には部分的な評価を与える設計を提案しています。
AIが本当に信頼されるためには、すべてを知っているふりをするのではなく、知らないことを正直に認められることが大切なのです。
理由③学習データの限界
ChatGPTは大量のテキストデータを学習していますが、それでも学習データには限界があります。ChatGPTが学習に使用したデータは、主にインターネット上で公開されている情報であり、非公開の情報や最新の情報は含まれていない可能性があります。
また、学習データの中には誤った情報や偏った情報も存在するため、ChatGPTがそれらの情報を真実として学習してしまう可能性もあります。そのため、ChatGPTの回答が常に正確とは限らず、嘘をついたり間違えたりすることがあるのです。
さらに、ChatGPTは最新のデータを学習していないため、直近の出来事や新しい知見について正確な情報を提供できない可能性があります。以下は、GPTモデルごとのデータ学習時期です。各モデルのカットオフ日については、OpenAIの公式サイトに記載されています。
| モデル | データ学習時期 |
| GPT-3.5 | 2021年9月まで |
| GPT-4 | 2023年12月まで |
| GPT-4o | 2023年10月まで |
| GPT-5 | 2024年9月まで |
理由④質問解釈が不十分
ChatGPTは、ユーザーからの質問を正しく理解することが重要ですが、常にそれが可能とは限りません。特に、曖昧な表現や文脈に依存した質問など、明確でない質問に対しては、ChatGPTが質問の意図を誤って解釈してしまう可能性があります。
その結果、質問に対する直接的な回答ではなく、関連性の低い情報を提供したり、質問の前提が間違っているにもかかわらず、そのまま回答を生成したりすることがあります。これは、ChatGPTが質問を十分に理解できていないために起こる現象だと言えます。
嘘をつかせないようにするためのプロンプトの工夫
プロンプトの書き方を少し工夫するだけで、ChatGPTが嘘をついたり間違いを起こしたりする可能性を大幅に減らすことができます。
ここでは、嘘をつかせない、より信頼性の高い回答を引き出すための実践的なコツをご紹介します。プロンプトの具体例も交えて解説していくので、すぐに実践できる内容になっています。
①明確・具体的に質問する
AIに質問する際は、曖昧な表現を避け、具体的な条件や文脈を明示することが重要です。「最近の〜」「良い〜」といった抽象的な言葉ではなく、時期や基準を明確に示すことで、AIが推測で答える余地を減らせます。
また、求める回答の形式(箇条書き、段落形式など)や範囲(国内限定、特定の業界など)を指定すると、より正確な回答が得られます。
プロンプト例:
2024年のStack Overflow Developer Surveyに基づいて、Web開発分野で使用率が高いプログラミング言語を上位5つ教えてください。
それぞれの特徴も簡潔に説明してください。②複雑な質問は段階的に分解する
一度に多くの情報を求めると、AIが部分的に正確でない情報を混ぜてしまうリスクが高まります。
複雑なトピックは、まず基本的な事実確認から始め、段階的に深掘りしていく方が精度が向上します。各ステップで回答を確認しながら進めることで、誤った前提に基づいた続きの回答を防げます。
プロンプト例:
【第1段階】
機械学習の主要なアルゴリズムの分類(教師あり学習、教師なし学習など)を説明してください。
【第2段階】(第1段階の回答を確認後)
教師あり学習の中で、分類タスクに使われる代表的なアルゴリズムを3つ挙げてください。
【第3段階】(第2段階の回答を確認後)
それぞれのアルゴリズムが適している具体的な使用場面を教えてください。③関連資料を参照データとして提供する
AIに記憶や推測に頼らせるのではなく、信頼できる資料を直接提供することで、ハルシネーション(誤った情報の生成)を大幅に削減できます。
文書、データ、URLなどを参照資料として与え、「この資料に基づいて」と明示的に指示することで、AIは提供された情報の範囲内で回答するようになります。
プロンプト例:
以下の売上データに基づいて分析してください。他の情報源からの推測は含めないでください。
[2023年度売上データ]
Q1: 1,200万円
Q2: 1,350万円
Q3: 1,180万円
Q4: 1,520万円
このデータから読み取れる傾向を3点挙げてください。
データに明示されていない事項については「データ不足のため不明」と回答してください。④不明点・知らないことは答えないように指示する
AIは質問に答えようとする傾向が強いため、明確に「知らない場合は正直に言う」よう指示することが重要です。この指示により、AIは推測や創作ではなく、確実な情報のみを提供するようになります。
また、「〜かもしれません」といった曖昧な表現を避け、確実性のレベルを明示するよう求めることも効果的です。
プロンプト例:
XYZ社の2026年5月発売予定の新製品について教えてください。
重要な指示:
- あなたの知識に含まれていない情報については「この情報は私の知識に含まれていません」と明示してください
- 推測や一般論で補わないでください
- 確実に知っている情報と不確実な情報を区別してください
- 知識のカットオフ日以降の情報の場合はその旨を伝えてくださいChatGPTの誤りを抑える他のコツ
ChatGPTをもっと正確に、もっと信頼できるツールとして使いたいですよね。実は、プロンプトの工夫以外にも、誤りを減らすための実践的なテクニックがいくつかあるんです。これらを知っているだけで、ChatGPTの精度がグッと上がります。
①ブラウジング機能の活用
ChatGPTの知識には期限があり、学習データのカットオフ日以降の情報は持っていません。
そこで活用したいのがブラウジング機能(Web検索機能)です。この機能を使うと、ChatGPTがリアルタイムでインターネット上の最新情報を検索し、それに基づいて回答してくれます。株価、ニュース、最新の製品情報など、日々更新される情報を扱う際は特に有効です。
明示的に「最新情報を検索して」と指示することで、推測ではなく実際のデータに基づいた回答が得られます。
またチャットの設定をオンにすることによってもブラウジン機能を有効にさせることができます。
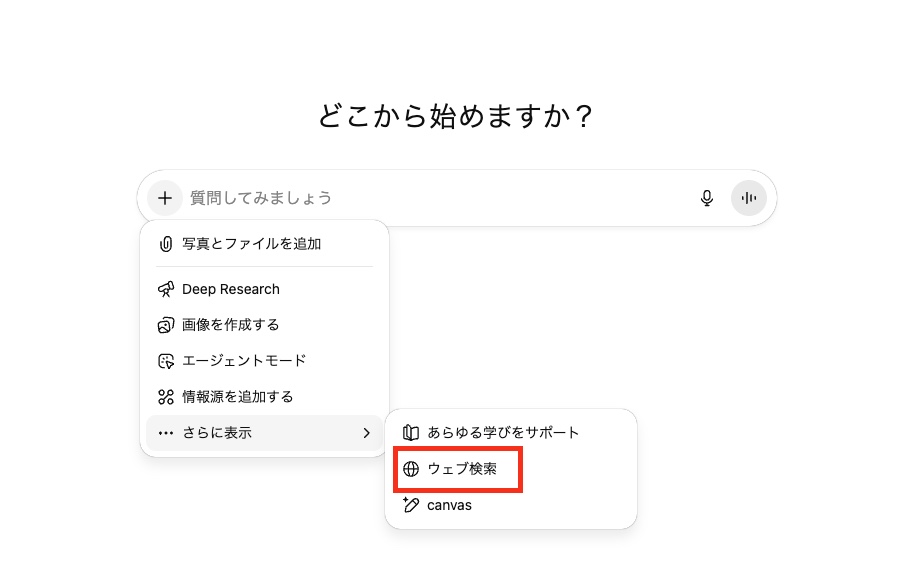
ブラウジング機能はかつて有料プランのみで使うことができましたが、現在では無料ユーザーでも使えるようになっているため、この機能を活用してハルシネーションのリスクを抑えることが可能です。
ブラウジング機能の詳細については公式ページでも解説されています。
②最新モデルの活用
ChatGPTは継続的に改良されており、新しいモデルほど精度が高く、誤った情報を生成する確率が低くなっています。
重要な判断材料となる情報を得る際や、専門的な内容を扱う場合は、なるべく最新の利用可能なモデルを選択しましょう。コストや速度よりも正確性を優先すべき場面では、迷わず最上位モデルを使うことをおすすめします。
③話題が変わったら新規チャットを作成
長い会話を続けていると、ChatGPTは以前のやり取りの文脈を引きずってしまい、新しい質問に対しても過去の話題を混同した回答をしてしまうことがあります。
特に異なるプロジェクトや全く別のトピックに移る際は、新しいチャットを開始することで、誤解や情報の混在を防げます。
「リセット」することで、ChatGPTはクリーンな状態から正確な回答を提供できるようになります。一つのチャットは一つのテーマに集中させるのが理想的です。
④ChatGPT自身にファクトチェックをさせる
ChatGPTの回答をChatGPT自身に検証させることで、矛盾や誤りを発見できる場合があります。最初の回答を得た後、「この情報は正確ですか?」「矛盾点はありませんか?」と問いかけることで、AIが自己点検モードに入り、より慎重な回答に修正されることがあります。
また、複数の角度から同じ質問をして回答の一貫性を確認する方法も有効です。特に重要な情報については、このダブルチェックのプロセスを挟むことをおすすめします。
自分自身での回答のファクトチェックは不可欠
AIツールの回答は便利ですが、それを「100%正しい」と思い込むのは危険です。ChatGPTをはじめとするAIは、時に事実と異なる情報を自信満々に回答することがあります。
特にビジネスの意思決定や学術的な内容、法的・医療的な判断など、重要な場面では必ず自分自身で情報を確認する習慣をつけましょう。
「AIが言ったから正しい」ではなく、「AIの回答を参考に、自分で裏付けを取る」という姿勢が大切です。検索エンジンで追加調査したり、公式サイトや信頼できる情報源で確認したり、専門家に相談するなど、複数の方法で検証することをおすすめします。
自身でのファクトチェックの方法:
- 公式統計サイトや企業の決算資料で最新データを照合
- 最低2〜3つの信頼できる情報源で同じ内容を確認
- 引用・参考文献の原文を確認
- 特に固有名詞、数値、専門用語、日付は慎重に確認
まとめ
いかがでしたでしょうか?ChatGPTが嘘をついたり間違えたりする理由から、それを防ぐための具体的な対策まで詳しくご紹介しました!
この記事で紹介したことをまとめると次のようになります。
- ChatGPTが嘘や間違いを起こす理由として、学習データの限界や質問の意図の誤解、不明点の推測での補完などがある
- 誤りを防ぐためのプロンプトの工夫として、明確・具体的に質問すること、段階的に分解して質問すること、関連資料を提供し不明点は答えないように指示することなどが挙げられる
- プロンプト以外の工夫として、ブラウジング機能の活用や最新モデルの使用、GPT自身にファクトチェックをさせることが有効
- 自分自身でのファクトチェックは不可欠!AIの回答を鵜呑みにせず、必ず検証する
ChatGPTの「完璧ではない」という特性を理解した上で使えば、業務効率化や学習支援に大いに役立つ強力なツールになります。
ぜひ、この記事で紹介したテクニックを活用して、ChatGPTからより正確で信頼性の高い回答を引き出してください!まずはプロンプトの工夫から、気軽に試してみてくださいね!
AIを実務で使い続けるには、ツール名を覚えるだけでなく、目的を分解し、文脈を渡し、出力を評価する力が必要です。AI副業やAIエージェント活用の入口をまとめた資料セットを無料で受け取れます。
無料資料を受け取る

