
「Z-Image-Turbo を自分のPCで動かしたいけれど、どのファイルをどこに置けばいいのか、設定でつまずいて最初の1枚にたどり着けない」——そんな悩みは、つまずきポイントさえ押さえれば一気に解消できます。
Z-Image-Turbo は、わずか8ステップで画像を生成できる高速モデルです。RTX 3060 / 4060 クラスのGPUでも、正しく導入すれば手元で快適に画像生成を楽しめます。
この記事では、必要な3ファイルのダウンロードと配置先、最大のハマりどころである「CLIP の type を Lumina 2 にする」設定、そして KSampler を8ステップで動かして最初の1枚を出すまでを、順番どおりに進めていきます。低VRAM環境での FP8 / GGUF の選び方や、黒画像が出たときの対処までカバーするので、この記事をなぞるだけで導入を完了できます。
内容をまとめると…
Z-Image-Turboは8ステップ・Apache 2.0で、RTX 3060/4060クラスでもローカル生成できる
必要なのは拡散モデル・qwen_3_4b・VAEの3ファイルで、置くフォルダが決まっている
最大のつまずきはCLIPのtypeをLumina 2にすること、KSamplerはsteps=8・cfg=1.0が基本
6〜8GBの低VRAMならBF16ではなくFP8やGGUFに切り替える
黒画像はCLIP設定の確認とBF16からFP8への切り替えで直ることが多い
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Z-Image-Turboとは?まず押さえる3つの特徴
Z-Image-Turbo(ゼットイメージ ターボ)は、Alibaba の Tongyi Lab が開発した画像生成モデルです。難しい用語を使わずに言うと、「文章を入力すると、その内容の画像をローカル(自分のPC)で作れる」モデルで、しかも生成がとても速いのが特徴です。
まず押さえておきたいポイントは次の3つです。
- わずか8ステップで生成できる:通常の画像生成は数十ステップかけますが、Turbo は蒸留という技術で8ステップ前後まで短縮されています。そのぶん1枚あたりの待ち時間が短く済みます。
- 6Bパラメータでも品質が高い:オープンソースの画像モデルを評価するランキングでもトップクラスに位置づけられており、軽量ながら実用的な仕上がりが期待できます。
- 日本語環境でも扱いやすく、ライセンスも明快:英語と中国語の文字描画に強く、ライセンスは Apache 2.0 で、個人利用から商用利用まで幅広く使えます。
細かい数値は次の表のとおりです。なお、Z-Image そのものの概要や料金プランを先に知りたい方は、概要記事のほうがまとまっています。
| 項目 | 内容 |
|---|---|
| 開発元 | Alibaba Tongyi Lab(Tongyi-MAI) |
| モデル規模 | 6B(60億)パラメータ |
| 生成ステップ | 8ステップ(Turbo は蒸留版) |
| ライセンス | Apache 2.0(商用利用可) |
| 公開時期 | 2025年11月下旬 |
この記事では、この Z-Image-Turbo を画像生成ツール「ComfyUI」に組み込み、最初の1枚を出すところまでを順番に進めていきます。
導入前の準備とPCスペックの目安
導入を始める前に、2つだけ準備を確認しておきましょう。これがそろっていれば、後の手順でつまずきにくくなります。
1つ目は ComfyUI 本体です。ComfyUI はノードをつないで画像生成の流れを組み立てるツールで、Z-Image-Turbo はこの ComfyUI 上で動かします。まだ入れていない場合は公式サイト(https://www.comfy.org/)から導入し、起動できる状態にしておいてください。Z-Image-Turbo は比較的新しいモデルなので、ComfyUI は最新版に更新しておくと対応ノードが正しく読み込まれます。
2つ目は GPU と VRAM(ビデオメモリ)の容量です。どのモデル版を選ぶかが、ここで決まります。標準の BF16 版は16GBクラスのVRAMが前提ですが、RTX 3060 / 4060 のような6〜8GBの環境では、容量を抑えた FP8 版や GGUF 版を選ぶのが現実的です。
| VRAMの目安 | 選ぶモデル版 | ひとこと |
|---|---|---|
| 16GB以上 | BF16(標準) | 公式サンプルそのままで動かしやすい |
| 8GB前後 | FP8 / GGUF(Q8_0) | ファイルが軽く、メモリに収まりやすい |
| 6GB前後 | GGUF(Q4_K_M) | もっとも省メモリ寄りの選択肢 |
自分のVRAMが分からないときは、Windows ならタスクマネージャーの「パフォーマンス」タブでGPUのメモリ量を確認できます。まずはこの表で「自分はどの版か」をざっくり決めておけば大丈夫です。次の章で、実際のファイルをダウンロードしていきます。
必要な3ファイルのダウンロードと配置先
ここがこの記事の中心です。Z-Image-Turbo を動かすには、役割の違う3つのファイルを ComfyUI の決まったフォルダに置く必要があります。ファイル名と置き場所を1文字でも間違えると ComfyUI が認識しないので、下の表のとおりに配置してください。
3ファイルはいずれも公式の配布元(Hugging Face の Comfy-Org/z_image_turbo リポジトリ)にまとまっています。リポジトリ内の split_files フォルダから、それぞれ対応するファイルを取得します。
| 役割 | ファイル名 | 置くフォルダ |
|---|---|---|
| 拡散モデル本体 | z_image_turbo_bf16.safetensors | ComfyUI/models/diffusion_models/ |
| テキストエンコーダ | qwen_3_4b.safetensors | ComfyUI/models/text_encoders/ |
| VAE | ae.safetensors | ComfyUI/models/vae/ |
ポイントを補足します。テキストエンコーダの qwen_3_4b は、入力した文章を画像生成が理解できる形に変換する部品です。VAE の ae.safetensors は Flux 系と同じVAEで、最終的な画像の描き出しを担います。拡散モデルは、6〜8GBのVRAM環境なら前章のとおり FP8 版や GGUF 版に置き換えてかまいません(置くフォルダは BF16 と同じ diffusion_models です)。
3つとも正しいフォルダに入れたら、ComfyUI 側でファイルを読み込めるよう、次の章でワークフローを開きます。
ComfyUIでワークフローを読み込む
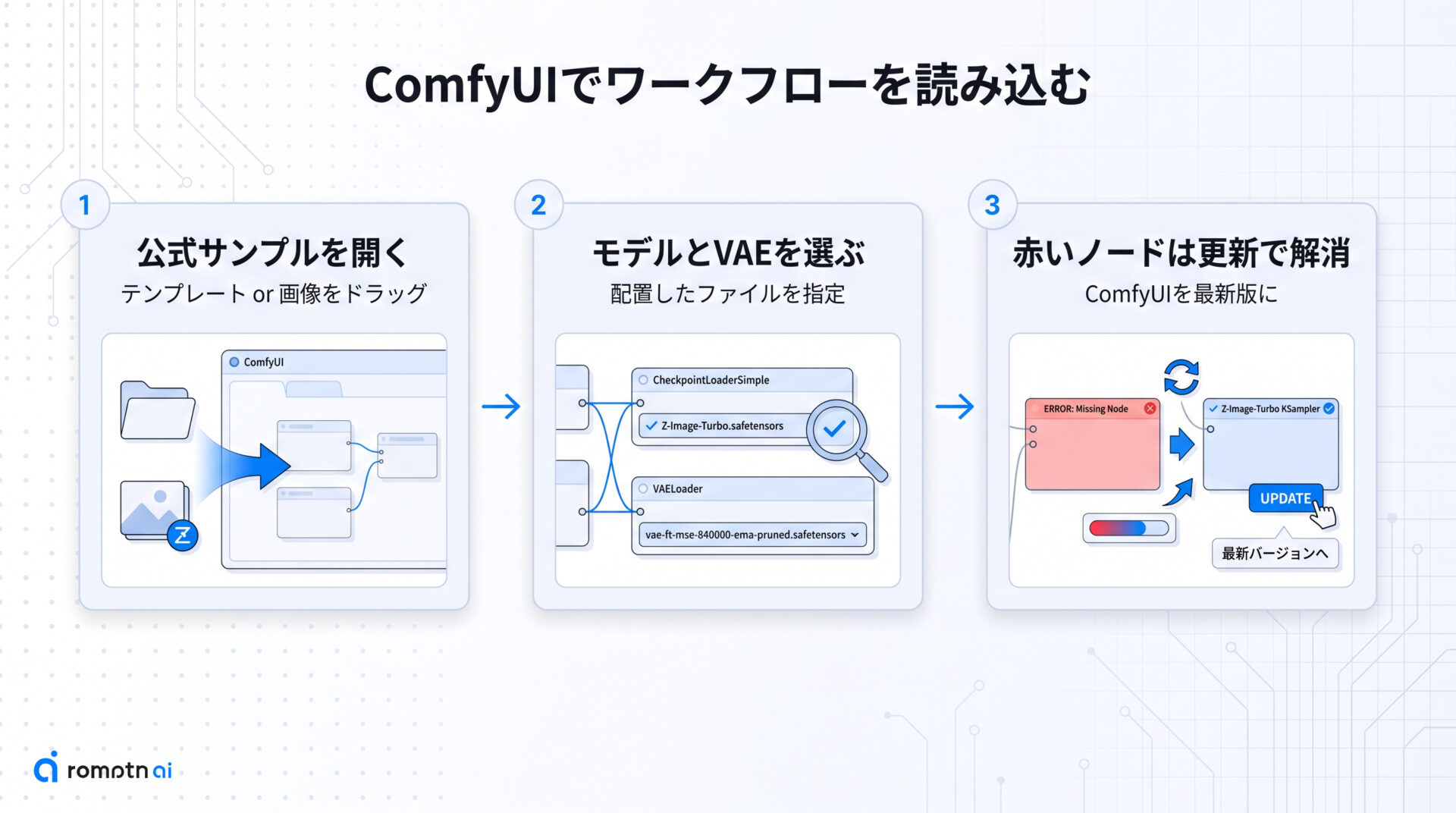
ファイルを置いたら、次はそれらをつなぐ「ワークフロー」を ComfyUI に読み込みます。ゼロからノードを組む必要はなく、公式が用意したサンプルをそのまま使うのが一番の近道です。
読み込み方法は主に2通りです。
- テンプレートから開く:ComfyUI のメニューから Z-Image 用のサンプルワークフローのテンプレートを選ぶと、必要なノードが最初から並んだ状態で開きます。
- サンプル画像をドラッグする:公式が配布しているサンプル画像には、生成に使ったワークフローの情報が埋め込まれています。その画像を ComfyUI の画面にドラッグ&ドロップすると、同じワークフローが復元されます。
どちらの方法でも、読み込んだ直後にモデルやVAEを選ぶ欄が表示されるので、前の章で配置したファイルを選びます。
もし赤いノードが出たり「ノードが見つからない」と表示されたりした場合は、ComfyUI のバージョンが古いことが原因のことがほとんどです。ComfyUI を最新版に更新してから再起動すると、対応ノードが読み込まれて解消します。ここまでで土台は完成です。次の章から、初心者がもっとも引っかかりやすい設定を1つずつ潰していきます。
ハマりどころNo.1:CLIPのtypeをLumina 2にする
Z-Image-Turbo の導入で一番つまずきやすいのが、このテキストエンコーダ(CLIP)の設定です。ここを間違えると、エラーになったり、思ったような画像にならなかったりします。逆に言えば、ここさえ押さえれば大きな山は越えられます。
設定のポイントは次の2つです。
- CLIPローダーの type を「Lumina 2」にする:テキストエンコーダを読み込むノード(CLIPローダー)には、どの方式で読むかを選ぶ
typeという項目があります。Z-Image-Turbo ではこれを Lumina 2 に設定し、ファイルとして前章で置いたqwen_3_4bを指定します。初期値のままだと正しく動かないので、必ず切り替えてください。 - ModelSamplingAuraFlow を通す:Z-Image-Turbo は、サンプリングの調整に ModelSamplingAuraFlow というノードを組み合わせる構成が前提です。公式サンプルのワークフローには最初から含まれているので、サンプルを使っていれば自動的に満たせます。
この2つは、既存の Stable Diffusion や Flux の設定とは共有できません。「他のモデルでは動いていたのに」という場合でも、Z-Image-Turbo 専用にこの設定を見直す必要があります。
CLIP の type を Lumina 2 にできたら、いよいよ生成の設定に進みます。
KSampler設定と8ステップで最初の1枚を生成
設定の最後は、生成の進め方を決める KSampler です。Z-Image-Turbo は蒸留された高速モデルなので、通常のモデルとは推奨値が違います。下の表の値に合わせるのが基本です。
| 項目 | 推奨値 | 補足 |
|---|---|---|
| steps(ステップ数) | 8 | Turbo は8ステップ前提。増やしても伸びにくい |
| cfg | 1.0 | 蒸留モデルなのでガイダンスは効かせない |
| sampler_name | euler | まずは標準的な euler から |
| scheduler | simple | euler と組み合わせる |
| 画像サイズ | 1024×1024 | 公式が推奨する基本サイズ |
cfg を1.0にするのがポイントです。Z-Image-Turbo はガイダンス(cfg)を内部に取り込む形で蒸留されているため、通常のモデルのように cfg を高くする必要がありません。むしろ高くすると崩れやすくなります。ネガティブプロンプト(避けたい要素の指定)も、この構成では基本的に効きません。
値を入れたら、あとはプロンプト欄に作りたいものを書いて生成を実行するだけです。たとえば次のような短い指定から試すと、結果を確認しやすいでしょう。
a cute corgi sitting on a sofa, soft lighting, photo
実行ボタンを押し、数十秒ほどで1枚目が表示されれば導入は成功です。ここまで来れば、あとはプロンプトを変えて自由に試せます。
低VRAM(6〜8GB)で動かす:FP8とGGUFの選び方
RTX 3060 / 4060 のようにVRAMが6〜8GBの環境では、標準の BF16 版だとメモリが足りないことがあります。そのときは、容量を抑えた FP8 版か GGUF 版に置き換えます。どちらも「拡散モデルのファイルを軽くしたもの」で、置くフォルダは BF16 と同じです。
選び方の目安は次のとおりです。
| 環境 | おすすめ | 必要な準備 |
|---|---|---|
| VRAM 8GB前後 | FP8、またはGGUFのQ8_0 | FP8はそのまま、GGUFはノード追加が必要 |
| VRAM 6GB前後 | GGUFのQ4_K_M | ノード追加が必要 |
FP8 版は、拡散モデルのファイルを diffusion_models フォルダに置き換えるだけで使えるので、手軽さで選ぶならこちらです。
GGUF 版を使う場合は、ComfyUI に GGUF を読み込むためのノード(City96 氏の ComfyUI-GGUF)を ComfyUI Manager から追加してから、対応する読み込みノードに差し替えます。ファイル名の末尾にある Q8_0 や Q4_K_M は圧縮の強さを表し、数字が小さいほどファイルが軽く、省メモリになります。6GBならまず Q4_K_M、8GBなら Q8_0 から試すとバランスを取りやすいです。
自分のVRAMに合った版を選べば、低スペックのPCでも8ステップ生成を十分楽しめます。
黒画像・メモリ不足など詰まった時の対処
最後に、つまずいたときの対処をまとめます。代表的なトラブルは原因がだいたい決まっているので、上から順に確認すれば解決しやすいです。
- 画面が真っ黒のまま、何も映らない:まず CLIP の type が Lumina 2 になっているか、ModelSamplingAuraFlow がワークフローに含まれているかを確認します。それでも改善しないときは、BF16 版を FP8 版に切り替えると直ることがあります。BF16 は環境によって真っ黒になりやすく、FP8 のほうが安定するためです。
- メモリ不足(out of memory)で止まる:VRAMが足りていません。前章を参考に FP8 版や GGUF 版へ切り替え、画像サイズを1024×1024より大きくしないようにします。同時に開いている他のアプリを閉じるのも有効です。
- ノードが赤くなる・見つからない:ComfyUI のバージョンが原因のことが多いです。最新版に更新して再起動してください。GGUF を使う場合は、対応ノードの追加も忘れずに行います。
- 更新したら動きが変わった:ComfyUI はバージョンによって挙動が変わることがあります。安定して動いていたバージョンを覚えておくと、切り分けが楽になります。
トラブルの多くは、設定の確認とモデル版の切り替えで解決できます。落ち着いて1つずつ試してみてください。
よくある質問(FAQ)
- QZ-Image-Turbo は無料で使えますか?商用利用は可能ですか?
- A
はい。Z-Image-Turbo は Apache 2.0 ライセンスで公開されており、無料で利用でき、商用利用も認められています。モデル自体の料金はかからないので、ローカルで動かすぶんには追加費用なしで使えます。
- QRTX 3060(6GB)でも動きますか?どのモデル版を選べばいいですか?
- A
動きます。標準の BF16 版は16GBクラス向けですが、6GBなら GGUF の Q4_K_M、8GBなら FP8 や GGUF の Q8_0 を選べば現実的に動かせます。拡散モデルのファイルを置き換えるだけなので、まずは軽い版から試してください。
- Q生成した画像が真っ黒になります。どうすればいいですか?
- A
まず CLIP の type が Lumina 2 か、ModelSamplingAuraFlow が含まれているかを確認します。それでも直らない場合は、BF16 版を FP8 版に切り替えると改善することが多いです。BF16 は環境により真っ黒になりやすい傾向があります。
- Qステップ数やCFGはいくつにすればいいですか?
- A
steps は8、cfg は1.0 が基本です。Z-Image-Turbo は8ステップで生成できるよう蒸留されており、ガイダンス(cfg)も内部に取り込んでいるため、cfg を上げる必要はありません。むしろ上げると崩れやすくなります。
- Q既存の Stable Diffusion / Flux のモデルと同じ設定で使えますか?
- A
同じ設定では使えません。Z-Image-Turbo は CLIP の type を Lumina 2 にし、ModelSamplingAuraFlow を組み合わせる専用構成が必要です。VAE は Flux 系と共通ですが、テキストエンコーダやサンプリングの設定は Z-Image-Turbo 用に分けて用意してください。
まとめ:Z-Image-Turboをローカルで使いこなすために
Z-Image-Turbo を ComfyUI に導入し、最初の1枚を出すまでの流れを振り返ります。一度通してしまえば、あとはプロンプトを変えるだけで何枚でも高速に生成できます。
つまずかないための勘所は次の3点です。
- 3つのファイルを正しいフォルダに置く:拡散モデル・qwen_3_4b・VAE を、それぞれ diffusion_models / text_encoders / vae に配置する。
- CLIP の type を Lumina 2 にする:ここが最大のハマりどころ。ModelSamplingAuraFlow とセットで使う。
- KSampler は steps=8・cfg=1.0:Turbo 専用の推奨値。低VRAMなら FP8 や GGUF に切り替える。
まずは公式サンプルのワークフローを読み込み、この記事の表のとおりに設定して、短いプロンプトで1枚生成してみてください。うまくいったら、サイズやプロンプトを少しずつ変えて自分の用途に合わせていくのがおすすめです。Z-Image そのものの特徴や料金をあらためて知りたいときは、概要記事も合わせて確認すると理解が深まります。ComfyUI やモデルは更新が続く分野なので、動かなくなったときは本記事のトラブル対処を起点に、最新版へ追従していきましょう。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

