
Mellum2が気になるものの、"12Bなのに2.5B active"と言われても、自分のローカル環境でどこまで実用になるのかは見えにくいものです。特に、コード生成の本命として使うべきか、それとも軽い補助役として使うべきかで判断が大きく変わります。
Mellum2は、大型モデルの代わりを丸ごと担うより、routingやRAGの前後処理、sub-agent補助のような中間工程で置いた方が強みが出やすいモデルです。軽さと長文脈の設計がどこで効くのかを先に押さえるだけで、試す価値があるかどうかはかなり判断しやすくなります。
InstructとThinkingの使い分け、ローカル運用で期待しすぎないための見方、向く用途と向かない用途まで整理しておくと、話題先行で飛びつく失敗を避けやすくなります。手元で小さく試すべきモデルなのかを見極めたい人は、まず全体像から確認していきましょう。
内容をまとめると…
Mellum2は大型モデルの代替より、速い補助役で真価が出る
12B total・2.5B activeのMoE設計で、長文脈でも待ち時間を抑えやすい
向くのはrouting、RAG前後処理、sub-agent補助のような中間工程
万能なコード生成の本命として期待しすぎると評価を誤りやすい
豪華大量特典無料配布中!
romptn aiが提携する完全無料のAI副業セミナーでは収入UPを目指すための生成AI活用スキルを学ぶことができます。
ただ知識を深めるだけでなく、実際にAIを活用して稼いでいる人から、しっかりと収入に直結させるためのAIスキルを学ぶことができます。
現在、20万人以上の人が収入UPを目指すための実践的な生成AI活用スキルを身に付けて、100万円以上の収益を達成している人も続出しています。












\ 期間限定の無料豪華申込特典付き! /
AI副業セミナーをみてみる
Mellum2は何に向く?
ここでは、Mellum2を「何でもできる新しい大型モデル」としてではなく、どの作業の補助役に置くと価値が出るかに絞って見ていきます。
Mellum2は、コード生成の本命を丸ごと置き換えるより、速さが効く中間工程で力を発揮しやすいモデルです。JetBrainsはrouting、Q&A、sub-agents、private AI useを主要用途として挙げており、重い推論よりも軽快な制御や要約、補助的なコード支援に寄せています。
もともとのMellumはコード補完寄りの文脈が強いモデルでしたが、Mellum2では自然言語とコードの両方を扱う前提になりました。ローカルで巨大モデルを常時回すのが重い人ほど、まずは「どこに置くと速さが効くか」という視点で見ると判断しやすくなります。
試しやすさの土台は?
この章では、Mellum2が「手元で試したい読者」にとってどこから入りやすいかを整理します。
まず大きいのは、Mellum2がApache 2.0で公開されていることです。利用条件の見通しを立てやすく、Hugging Face経由でモデル群や派生チェックポイントにも触れやすいため、個人検証から社内の閉域運用まで入り口を作りやすくなっています。
JetBrains自身もprivate deploymentを前提にした説明をしているので、「クラウド前提の黒箱サービスをそのまま使う」のではなく、ローカルや自前基盤に寄せて試したい読者と相性がよいテーマです。導入前に細かな実測を詰めるより、まずは公開形態と用途の相性から見ると迷いにくくなります。
軽さの理由を整理する
ここでは、Mellum2が「軽そう」に見える理由を、専門用語を崩して押さえます。
Mellum2は総パラメータが12Bですが、1トークンごとに常時すべてを動かすわけではありません。MoEという仕組みで必要な専門家だけを呼び出すため、実際に動くのは2.5B activeです。JetBrainsの技術レポートでは64 expertsのうち8 expertsを有効化する設計とされており、総量を確保しつつ計算量を抑える狙いが見えます。
さらに、文脈長は131,072 tokensです。長いコードベースや履歴を一度に扱いやすい一方で、速さはsliding window attentionや低めのKV head構成で支える形です。数字だけを見るより、「大きさを全部回さず、長文脈でも補助役として軽く動かすための設計」と理解すると実用像がつかみやすくなります。
InstructとThinkingの違い
ここでは、Mellum2を選ぶときに迷いやすいInstructとThinkingの役割を分けます。
Instructは、直接答える速さを重視したモデルです。公式もinteractive chat、code assistance、tool use、instruction followingを主な用途にしており、まず日常の補助役として触るならこちらの方が入りやすいです。
一方のThinkingは、複雑なdebuggingやmulti-step planning、agentic workflowsのように、途中の推論を明示しながら進めたい場面に向いています。普段の応答速度を優先するならInstruct、複数段の判断や計画まで含めて考えさせたいならThinking、という分け方を先に持っておくと試行錯誤が減ります。
活きる用途は3つ
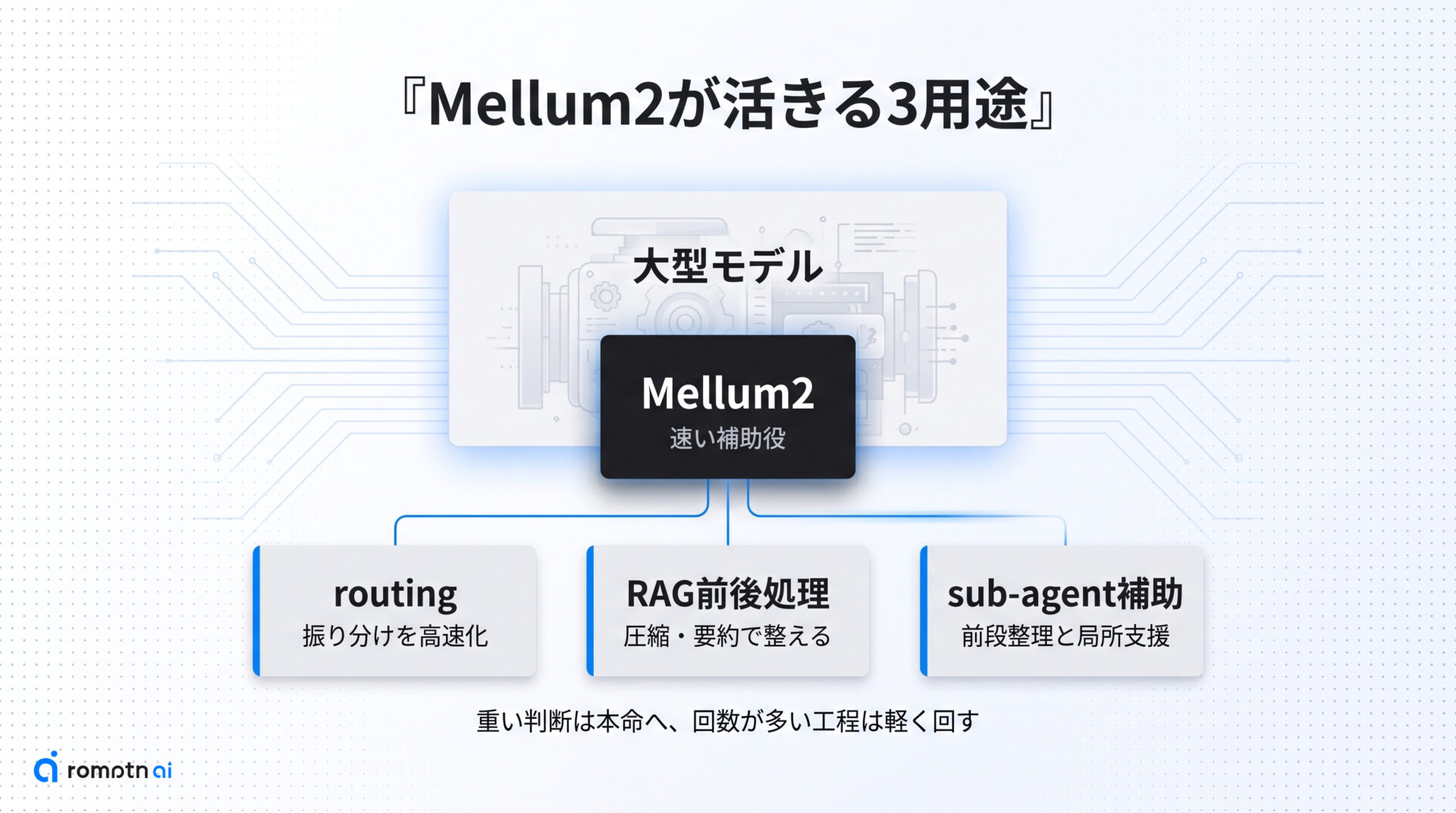
ここからは、Mellum2を実際のワークフローにどう置くと活きるかを3つに分けて見ます。
ポイントは、重い推論をすべて1台で背負わせる発想ではなく、回数が多い補助工程を速く回すことです。JetBrainsやHugging Faceが押しているrouting、RAG、sub-agentsの文脈も、この見方に揃っています。
次の3つを順に見ると、自分の作業でMellum2が前に出る場面と、後ろで支える場面の違いがはっきりします。
① routingと制御役
Mellum2が最もわかりやすく活きるのは、どのモデルやツールに処理を渡すかを決めるrouting役です。
たとえば、質問をそのまま大型モデルに投げる前に、要約が必要か、RAGが必要か、単純なコード補助で済むかを振り分ける工程は、精度だけでなく応答の軽さも重要になります。JetBrainsがcontrol-flowやtool selection寄りの使い方を前面に出しているのは、この工程ならMellum2の速さが無駄になりにくいからです。
「まず軽いモデルで流れを整え、本命モデルは重い判断だけに使う」という構成を考えている人には、Mellum2は入口として検討しやすい候補です。
② RAGの前後処理
RAGまわりでも、Mellum2は「答えを出す本体」より前後処理で使いやすいモデルです。
公式が挙げるcontext compressionやsummarizationはその典型で、取得した情報をそのまま長く渡すのではなく、必要な形に整えてから次の判断へつなぐ役割に向いています。長い文脈を扱えることも、この前後処理では効きやすいポイントです。
重いモデルを毎回フルで回すより、まずMellum2で情報を整え、その後で精度重視のモデルに渡す方が、全体の待ち時間やコスト感を抑えやすい場面があります。
③ sub-agentとコード補助
sub-agent構成や局所的なコード補助でも、Mellum2は扱いやすい立ち位置にあります。
たとえば、巨大な設計判断そのものは大型モデルに任せつつ、前段の論点整理、簡単なコード変換、要約、確認用の短い往復をMellum2に寄せると、全体のテンポを落としにくくなります。JetBrainsがsub-agentsやsoftware engineering workflowsを強調しているのも、この補助役としての置きやすさがあるからです。
ただし、難しい実装を一発で書かせる本命として期待しすぎると、評価がぶれやすくなります。Mellum2は「全部やる1台」より、「本命を支える軽い1台」として見る方が失敗しにくいです。
ローカル運用の限界も知る
この章では、ローカル運用への期待と、そこで見落としやすい限界を分けて押さえます。
Mellum2は設計思想として低レイテンシ寄りですが、執筆時点では手元GPUごとの実測、量子化ごとの安定性、運用ツールごとの成熟度まで一次情報で出揃っているわけではありません。だからこそ、「軽いと聞いたから何でも快適に動く」と考えるより、まずは補助工程で試す前提に置いた方が現実的です。
また、長文脈やThinking variantがあるからといって、すべての難題で大型モデル並みの精度が出るとは限りません。ローカルで試しやすいモデルほど、期待値を上げすぎず、得意な役割に寄せて使う方が満足しやすくなります。
大型モデルを優先する場面
ここでは、Mellum2より大型モデルを優先した方がよい場面をはっきりさせます。
長い設計レビュー、複数ファイルにまたがる難しいコード生成、正確さを最優先にした深い推論では、より大きなモデルの方が安心なケースがあります。Mellum2は軽さと実用性のバランスが魅力ですが、その強みは「最終回答の絶対性能」より「補助工程を速く回せること」にあります。
そのため、重い判断まで1台で済ませたい人より、役割分担を前提にしたい人の方が相性はよいです。Mellum2を使うかどうかは、モデル単体の優劣より、あなたのワークフローが分業型かどうかで考えると失敗しません。
よくある質問
- QMellum2は初心者でもローカルで試せますか?
- A
試しやすさはありますが、いきなり本命のコード生成環境を丸ごと置き換える前提では考えない方が安全です。まずは要約、routing、短いコード補助のように役割を絞って触ると、モデルの軽さと限界をつかみやすくなります。
- QMellum2はコード生成の本命モデルとして使うべきですか?
- A
本命として常に最優先にするより、補助工程で使う方が相性は見えやすいです。高難度のコード生成や深い設計判断では大型モデルの方が安心な場面があるため、Mellum2は前段整理や局所支援から試すのがおすすめです。
- QInstructとThinkingはどちらから試すべきですか?
- A
普段の応答速度や日常のコード補助を見たいならInstructから入ると扱いやすいです。途中の推論を見ながらdebuggingや多段の計画まで試したい場合はThinkingが向いています。
- QMellum2はどんなワークフローで特に活きますか?
- A
複数モデルをつなぐrouting、RAGの前後処理、sub-agentの補助役のように、回数が多くて待ち時間が気になる工程で活きやすいです。大きな判断を本命モデルに任せつつ、軽い中継役を置きたい人ほど相性があります。
Mellum2のまとめ
Mellum2の要点をまとめると、次の3つです。
- 大型モデルの代替というより、速い補助役として見ると価値がわかりやすい
- 12B total・2.5B activeのMoE設計と131,072 tokensの文脈長が、軽さと扱いやすさの土台になっている
- routing、RAG、sub-agentsのような中間工程で試すと、得意な役割が見えやすい
まずはInstructかThinkingのどちらが自分の用途に近いかを決め、補助工程から小さく試すのが現実的です。逆に、最初から本命の巨大モデルを置き換えたい人は、大型モデルを優先した方が失敗しにくいでしょう。
Mellum2は「全部を任せる1台」ではありませんが、ローカル開発の流れを軽くする1台としては十分に検討する価値があります。
豪華大量特典無料配布中!
romptn aiが提携する完全無料のAI副業セミナーでは収入UPを目指すための生成AI活用スキルを学ぶことができます。
ただ知識を深めるだけでなく、実際にAIを活用して稼いでいる人から、しっかりと収入に直結させるためのAIスキルを学ぶことができます。
現在、20万人以上の人が収入UPを目指すための実践的な生成AI活用スキルを身に付けて、100万円以上の収益を達成している人も続出しています。
\ 期間限定の無料豪華申込特典付き! /
AI副業セミナーをみてみる

