
Mellum2って結局どこで使うモデルなのか、12Bと聞くと重いのか軽いのか判断しづらいはずです。Mellum2は巨大なコードモデルを丸ごと置き換えるより、routing や RAG 前処理、sub-agents のような途中工程を速く回したい時に価値が出やすいモデルです。
この前提を外すと、「最強のコード生成モデルではない」という不満だけが先に立ちます。反対に、重い本命モデルを呼ぶ前の分類、要約、検証を軽くしたい人には、2.5B active の MoE 設計と checkpoint の分かれ方がかなり噛み合います。
この記事を読めば、Mellum2 を試す価値があるのはどんな構成か、最初に触るべき checkpoint はどれか、ローカル運用でどこまでを公式情報として見ればいいかを短時間で判断できます.
内容をまとめると…
Mellum2は巨大モデルの代役ではなく、routing や RAG 前処理を速く回す補助モデル
12Bでも1トークンごとに動くのは2.5B active、長文コンテキストを扱いやすい軽量MoE設計
まず触るなら Instruct、深い planning や debugging まで見るなら Thinking、自前調整なら Base 系
ローカル運用は公開形態と serving 例を起点に判断し、VRAM や体感速度は自環境で検証
生成AIを「少し触って終わり」にせず、業務効率化・副業・AIエージェント活用までつなげたい方向けに、基礎から実践まで整理できる無料資料を用意しています。
記事とあわせて、AIに作業を任せる考え方や長く使える活用スキルを確認しておきたい方は受け取っておいてください。

Mellum2は補助モデル向き
ここでは、Mellum2をどこに置くと価値が出るのかを先に整理します。Mellum2は、巨大なコードモデルの代役というより、AIワークフローの途中で使う補助モデルとして考えると理解しやすいです。
JetBrains は Mellum2 を routing、RAG、sub-agents、private deployment 向けに打ち出しています。つまり「最終回答を全部任せる一軍」より、「まず分類する」「文脈を短く圧縮する」「次の処理を決める」といった高速ステップで効く設計です。ここを先に押さえると、12B という数字だけを見て重いか軽いかで迷いにくくなります。
特に相性がいいのは、入力を見て次に呼ぶモデルやツールを振り分けたい時、RAG で拾った長い文脈を整えてから本命モデルへ渡したい時、エージェントの planning や validation だけを速く回したい時です。反対に、「常に最高品質のコード生成を 1 モデルで完結させたい」という使い方とは少し発想が違います。Mellum2は、重いモデルを減らすというより、重いモデルを呼ぶ回数を減らすための選択肢だと捉えるのが自然です。
軽い理由は2.5B active
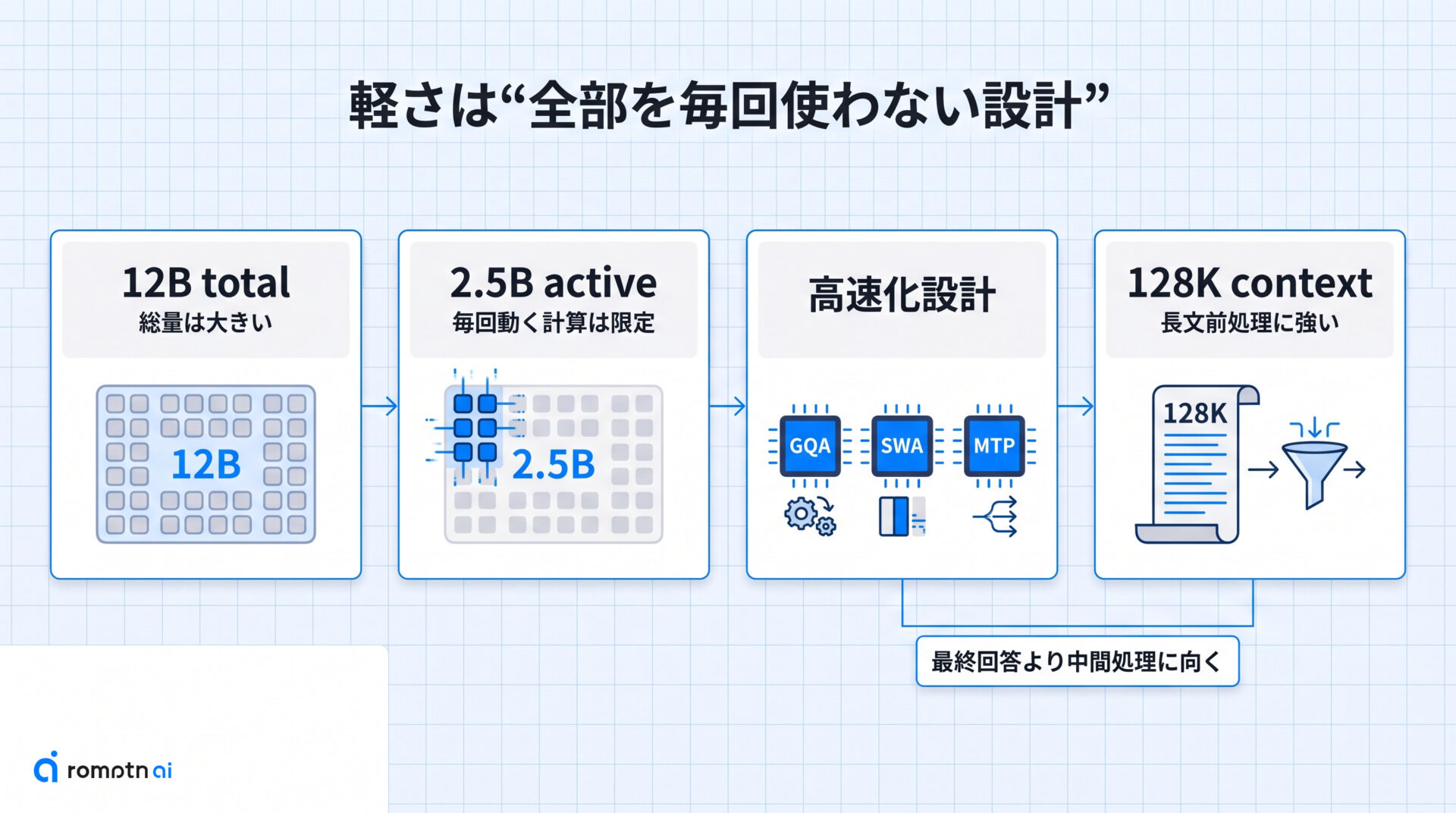
この章では、「12Bなのに軽い」と言われる理由を噛み砕きます。ポイントは、Mellum2 が 12B の総パラメータを持ちながら、1トークンごとに実際に動くのは 2.5B 相当だという点です。
つまり、容量の大きさと毎回払う計算コストを切り分けているわけです。さらに JetBrains は、4 KV heads の GQA、3 層中 4 層で使う Sliding Window Attention、補助的な MTP head など、推論を速く回す前提で設計を選んでいます。ここでいう「軽い」は、単にモデル名が小さいという意味ではなく、高速な中間処理に向くように計算の使い方を絞っているという意味です。
もう1つ大事なのが 128K context です。文脈を長く持てるので、長いログや取得済みコンテキストを扱う前処理でも使いやすい一方、常に大規模モデル並みの生成品質を約束する話ではありません。速さと守備範囲のバランスを、ワークフロー向けに最適化した設計だと理解するとズレません。
向く用途は3つある
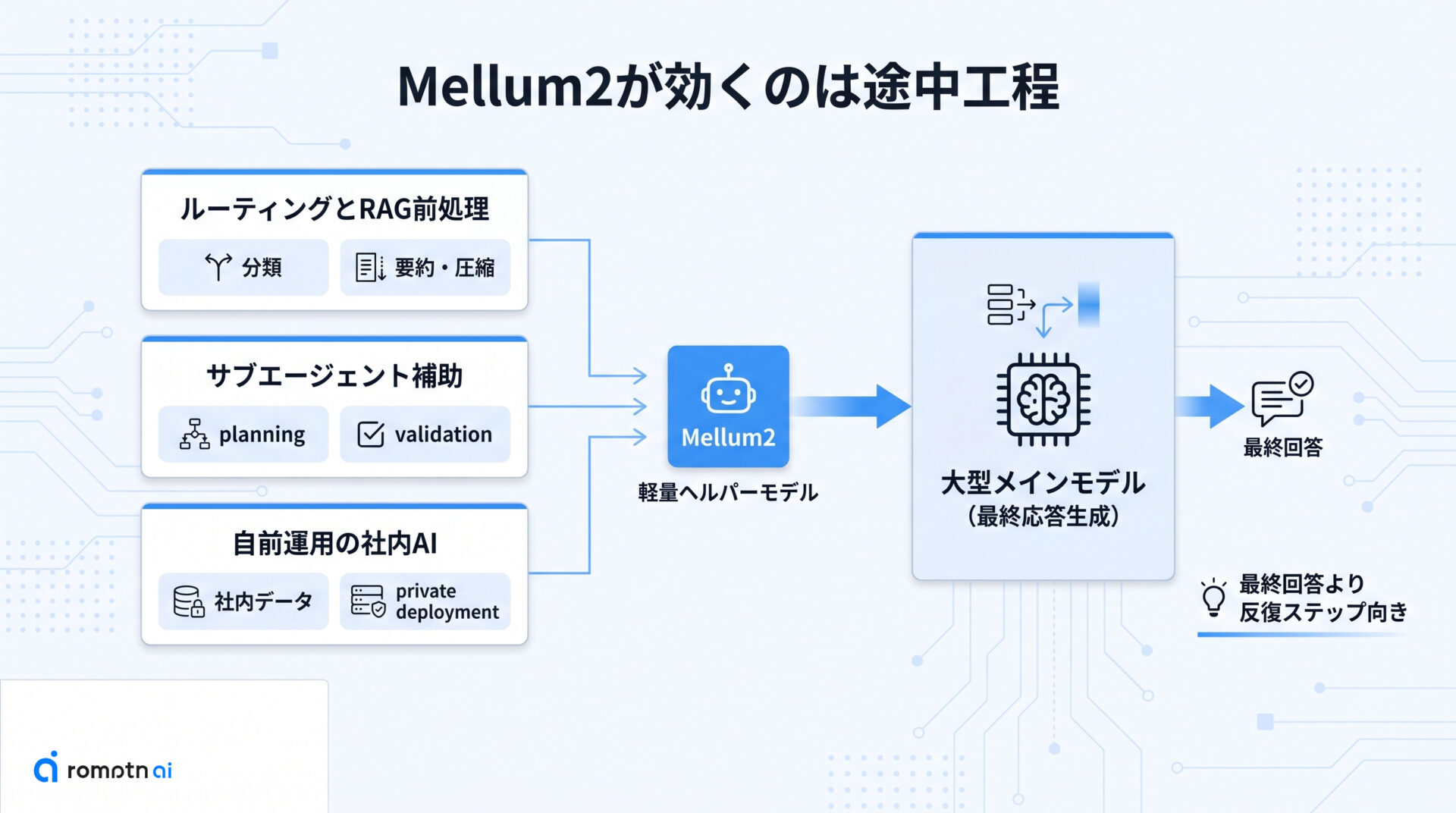
ここからは、Mellum2 を実際にどこへ置くと効果が出やすいかを3つに分けて見ます。大事なのは「コードが書けるか」だけで判断せず、処理のどの段階を速くしたいかで考えることです。
Mellum2 がはまりやすいのは、次の3パターンです。
- 入力の振り分けや要約など、最初の前処理を軽くしたい
- エージェントの planning や validation だけを別モデルで回したい
- 社内データやコードを自前環境で扱いたい
どれも共通しているのは、「最終成果物を1回で出す」より「途中工程を何度も回す」場面だという点です。次の3つの小見出しでは、それぞれの使い方がなぜ Mellum2 と相性がいいのかを具体化します。
① ルーティングとRAG前処理
Mellum2 が最もわかりやすく効くのは、最初の振り分けや前処理です。たとえば、受け取った質問を「コード相談」「検索が必要」「そのまま回答できる」に分類したり、RAG で拾った長文を本命モデルに渡す前に短く整えたりする役目です。
こうした工程は、1回の品質より何度も速く回せることのほうが重要です。JetBrains も routing や retrieval post-processing、summarization を Mellum2 の主用途として挙げています。前処理が重いと本命モデルの前で待ち行列ができやすいので、ここを軽くするだけで体感速度が変わるケースは少なくありません。
もし今の構成で「長いコンテキスト整理に毎回大きいモデルを使っている」なら、まず Mellum2 に置き換える候補として考えやすい章です。
② サブエージェント補助
エージェント構成では、最終回答そのものより、途中の planning や validation が回数を食います。Mellum2 は、まさにその「何度も呼ばれる中間タスク」を受け持たせやすいモデルです。
たとえば、次の action を決める、入力を正規化する、取得した情報に抜けがないか確認する、といった処理は巨大モデルでなくても回せることが多いです。JetBrains も sub-agents の context gathering、planning、validation を代表例として挙げています。ここを軽いモデルに逃がせると、本命モデルは本当に重い判断だけに集中できます。
「全部を 1 モデルに任せる」構成でコストや待ち時間が気になるなら、まず切り出しやすいのがこの領域です。
③ 自前運用の社内AI
社内コードや独自データを扱うなら、モデルの公開形態も重要です。Mellum2 は Apache 2.0 で公開されており、JetBrains も private deployment や self-hosted 利用を前提の1つとして案内しています。
ここでの利点は、「軽い補助工程だけでも自前で閉じられる」ことです。最終回答は別の大きいモデルに任せるとしても、分類、要約、検証のような前段を社内側で処理できると、外へ渡す情報量を減らしやすくなります。とくにコード補助や社内ドキュメント検索では、この差が安心感に直結します。
外部APIを完全にやめる話ではなくても、まず中間工程を自前に寄せる一歩としては検討しやすいモデルです。
モデル選びは3系統で考える
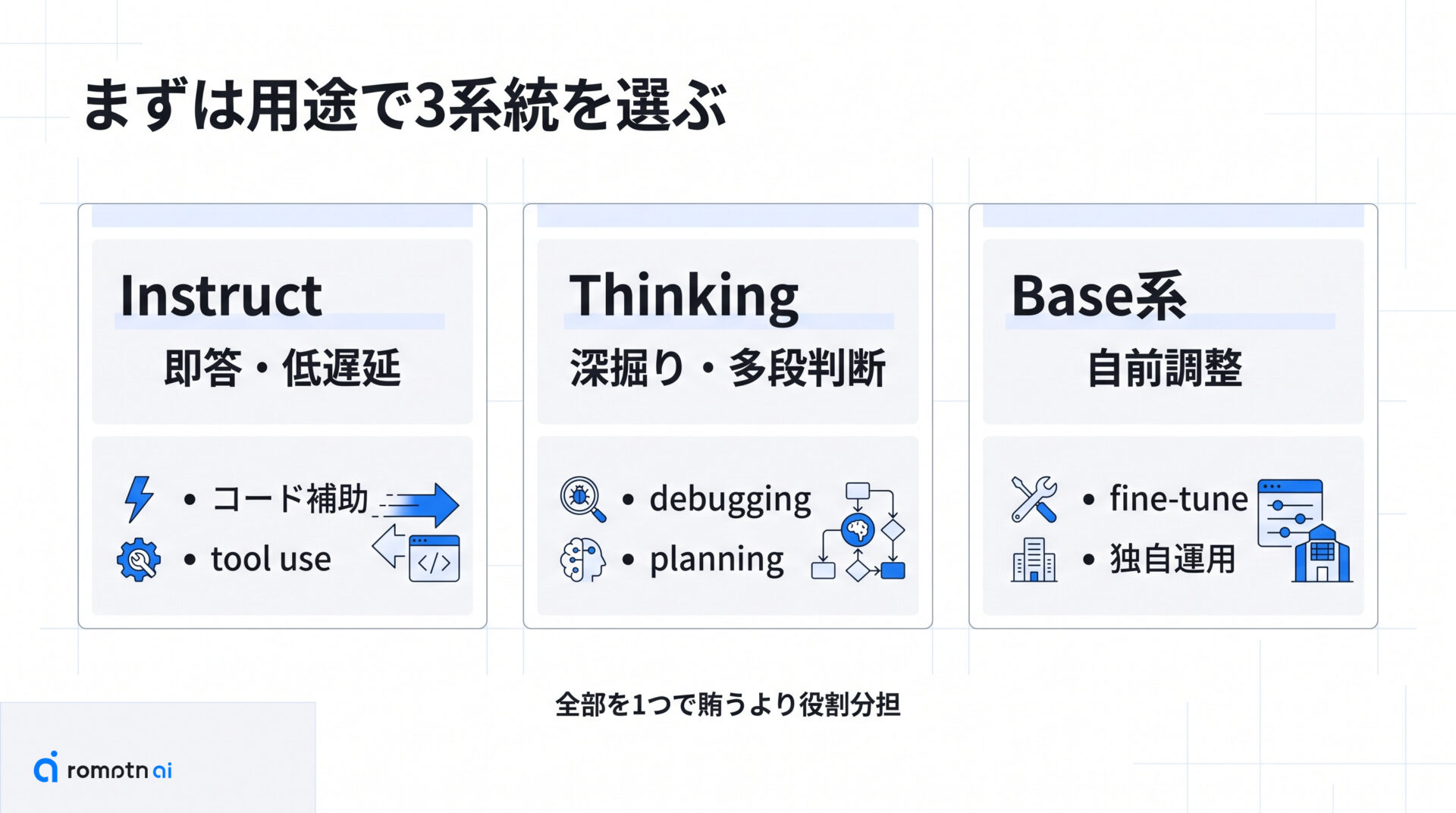
Mellum2 は 1 つの checkpoint だけを触れば終わり、という family ではありません。執筆時点では Instruct、Thinking、Base 系が公開されているので、まずは「どう答えてほしいか」と「どこまで自前で触るか」で選ぶのが近道です。
ざっくり分けると、すぐ使うなら Instruct、深い reasoning を重視するなら Thinking、細かく調整したいなら Base 系です。ここを曖昧にしたまま試すと、「思ったより遅い」「欲しい出力と違う」というズレが起きやすくなります。
次の3節では、それぞれがどんな場面に向いていて、どこで期待値を上げすぎないほうがいいかを順番に整理します。
① Instructは即答向け
Instruct は、まず Mellum2 を触ってみたい読者が入りやすい選択です。公式モデルカードでも、low-latency な direct answer、code assistance、tool use、instruction following 向けだと案内されています。
要するに、「考え方を長く見せる」より「素早く返す」寄りの性格です。チャットでの確認、コードの補助、軽い実行ステップの受け皿としては扱いやすく、最初の検証コストも抑えやすいです。反対に、複雑な debugging や長い reasoning をそのまま任せたい場合は、次の Thinking のほうが考えやすいでしょう。
迷ったら、まず Instruct で体感速度と使いどころを確認し、そのうえで必要なら Thinking へ広げる順番が無難です。
② Thinkingは深掘り向け
Thinking は、「結論だけ速く返す」より、途中の reasoning を使って複雑な問題をほどきたい時に向く checkpoint です。公式モデルカードでも、complex debugging、planning、multi-step agentic flows のような場面では Thinking を選ぶよう案内されています。
そのぶん、常に最短で返るモデルとして期待しすぎないほうが安全です。中間 reasoning が役に立つタスクでは強みになりますが、単純な分類や要約まで全部 Thinking に寄せると、Mellum2 を軽い補助モデルとして使ううまみは薄れます。
「深い判断だけ Thinking、それ以外は Instruct や別の軽いステップ」という分担にすると、family の違いを活かしやすくなります。
③ Base系は自前調整向け
Base 系は、「すぐに使える回答モデル」より、自前の serving や fine-tune を前提に触る層向けです。collection には Base と Base-Pretrain、さらに SFT 系も並んでいるので、既製品の挙動をそのまま使うより、土台として扱う発想に近いです。
この系統が向くのは、社内要件に合わせて回答スタイルを変えたい、独自の tool use ルールを作りたい、評価や量子化の前提を自分で握りたい場合です。逆に、「まず使いどころを試したい」段階なら、Instruct や Thinking から入ったほうが判断が早くなります。
Base 系は自由度が高いぶん、運用と検証の負担も増えます。便利そうだからではなく、調整したい理由が明確な時に選ぶのが基本です。
ローカル運用の判断軸
ローカル運用を考える時は、「公式が確認していること」と「自分で確かめるべきこと」を分けるのが大切です。公式に確認できるのは、Mellum2 が open weight で公開されていること、self-hosted を想定していること、そして Instruct には vLLM の serving 例が用意されていることです。
一方で、最小 VRAM や体感速度、どの量子化なら快適かといった話は、環境依存が大きく、公式が一律に保証しているわけではありません。ここをコミュニティの感想だけで断定すると、読者の判断を誤らせます。まず見るべきなのは、使いたい checkpoint、対応する serving stack、必要な context 長、そして自前で守りたいデータ境界です。
「ローカルで動くか」だけでなく、「どの工程をローカルに置きたいか」まで決めると、Mellum2 を試す優先順位がはっきりします。
Mellum2のよくある疑問
- QMellum2はメインのコード生成モデルとして使うべきですか?
- A
補助モデルとして置くほうが強みを活かしやすいです。公式も routing、RAG、sub-agents、private deployment のような中間工程を主用途に挙げており、「常に最高品質のコード生成を 1 モデルで完結させる」前提とは少し違います。
- Q最初に触るなら Instruct と Thinking のどちらが向いていますか?
- A
まずは Instruct から試すほうが判断しやすいです。低遅延の対話やコード補助、tool use を見たいなら Instruct が入り口になります。複雑な debugging や planning まで見たい時に Thinking を追加すると、違いを掴みやすくなります。
- Qローカル運用では何を先に確認すればよいですか?
- A
最初に見るのは、使いたい checkpoint と対応する serving 方法です。公式に確認できる self-hosted 前提や vLLM 例を起点にし、そのうえで自分の環境の VRAM、必要な context 長、どの工程をローカルへ寄せたいかを順番に確認すると迷いにくくなります。
向かない使い方もある
Mellum2 が合わない場面もあります。たとえば、「単体で最高品質のコード生成を出してほしい」「多モーダルまでまとめて扱いたい」「非公式ベンチだけで一番強いモデルを選びたい」という期待が中心なら、別の選択肢のほうが判断しやすいはずです。
JetBrains 自身も、Mellum2 を text and code に絞った focused model として説明しています。つまり、守備範囲を広げるより、速さと運用しやすさに寄せたモデルです。この性格を無視して「全部できるはず」と使うと、良さより不満が先に立ちます。
Mellum2 の評価は、「最強かどうか」ではなく「中間工程のコストと待ち時間をどれだけ下げられるか」で見るとぶれにくくなります。
Mellum2のまとめ
最後に要点を絞ると、Mellum2 は「大きいモデルを全部置き換える候補」ではなく、「途中工程を速くする候補」として見ると価値がはっきりします。
- routing や RAG 前処理、sub-agents のような反復ステップと相性がいい
- Instruct、Thinking、Base 系で役割が分かれているので、入口の選び方が大切
- ローカル運用は公開形態と serving 例を起点に考え、VRAM などの体感は自分の環境で確認する
まず試すなら、Instruct を動かして「分類・要約・補助タスク」に置いた時の体感を見てください。そのうえで reasoning が足りなければ Thinking、自前調整まで必要なら Base 系へ進むと判断しやすくなります。Mellum2 は、ワークフローの重さを減らしたい人ほど相性がわかりやすいモデルです。
AIを実務で使い続けるには、ツール名を覚えるだけでなく、目的を分解し、文脈を渡し、出力を評価する力が必要です。AI副業やAIエージェント活用の入口をまとめた資料セットを無料で受け取れます。
無料資料を受け取る

