
Mellum2は気になるものの、12Bなのに軽いと言われても、自分の環境や用途で現実的か判断しづらい人は多いはずです。結論から言えば、Mellum2は巨大モデルの代替として見るより、routingやRAG前後処理、軽いコード支援を速く回す補助モデルとして理解すると腹落ちしやすいです。
ここを先に整理しておくと、「ローカルで試せるのか」「InstructとThinkingはどう違うのか」「どこに置くと価値が出るのか」を、重そうなスペック表に振り回されず判断できます。話題の新モデルを追うだけで終わらず、自分のワークフローへ入れる価値があるかを短時間で見極めやすくなります。
本記事では、Mellum2の軽さの見方、向いている工程、主役にしない場面まで一続きで整理します。読み終えるころには、試すならどこから入るべきかを、無理なく決めやすい状態まで持っていけます。
内容をまとめると…
Mellum2 は巨大モデルの代替より、速さが効く補助役として見ると腹落ちしやすい
軽さの論点は12B表記そのものではなく、2.5B activeとMoE設計
Instructは回転数重視、Thinkingは複雑な分岐判断向き
最初から主役交代を狙わない。routingやRAG前後処理から試すと失敗しにくい
豪華大量特典無料配布中!
romptn aiが提携する完全無料のAI副業セミナーでは収入UPを目指すための生成AI活用スキルを学ぶことができます。
ただ知識を深めるだけでなく、実際にAIを活用して稼いでいる人から、しっかりと収入に直結させるためのAIスキルを学ぶことができます。
現在、20万人以上の人が収入UPを目指すための実践的な生成AI活用スキルを身に付けて、100万円以上の収益を達成している人も続出しています。












\ 期間限定の無料豪華申込特典付き! /
AI副業セミナーをみてみる
Mellum2は高速な補助モデル
まずは、Mellum2を「何の役割で置くモデルか」から整理します。
Mellum2は、重い主役モデルを丸ごと置き換えるというより、速さが必要な工程を受け持つ補助モデルとして見ると分かりやすいです。JetBrainsも、coding workflowの中でrouting、RAG前後の整形、sub-agentのような高頻度タスクに向く位置づけを前面に出しています。
つまり注目点は「全部を任せられるか」ではなく、「どこを速く回せるか」です。コード支援や長い文脈の整理を軽い役で分担させたい人には合いやすく、逆に最終判断まで一台で完結させたい人には、この後の章で触れるように役割の切り分けが必要になります。
何が軽いのか
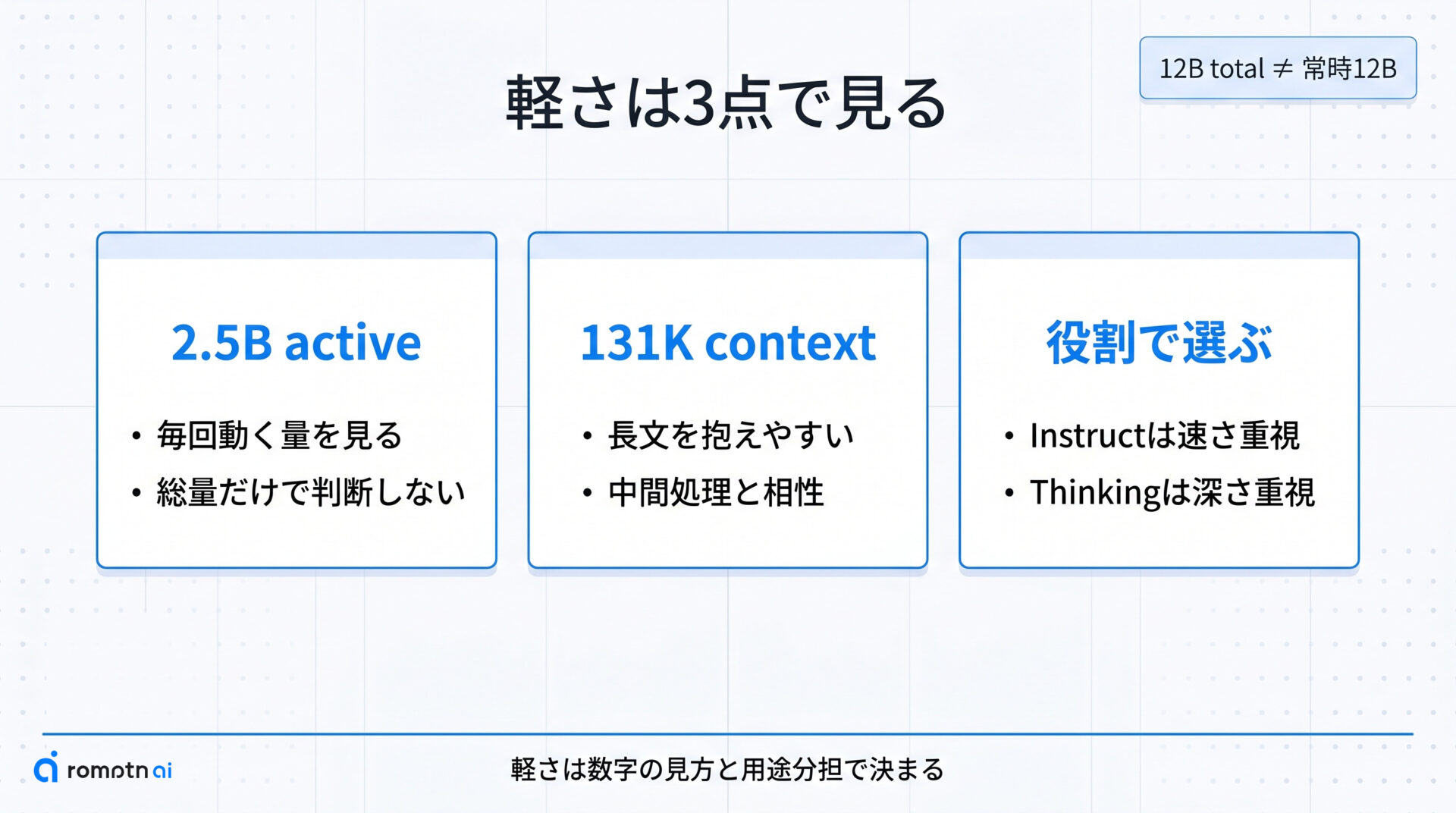
ここでは、「12Bなのに軽い」と言われる理由を分解します。
Mellum2の軽さは、総パラメータ数だけで決まっているわけではありません。見るべきなのは、実際に各tokenで動くactive parameters、長い入力をまとめて扱える131K級の文脈長、そして用途を分けたInstructとThinkingの構成です。
数字だけ追うと重そうに見えても、実運用では「どの処理を、どれだけの計算で回すか」が重要です。次の3つの観点を押さえると、Mellum2がなぜ補助モデルとして扱いやすいのかが見えてきます。
① 12B / 2.5Bの意味

Mellum2で最初に見ておきたいのは、12Bが「全部いつも動く」という意味ではない点です。公開情報では、総パラメータは12Bでも、各tokenで実際に有効になるのは2.5B active parametersと説明されています。
このため、「12Bだから常に12B相当の重さで回る」とは読みません。MoEでは必要なexpertだけを使うので、読者が感じる軽さは総量よりもactive側の設計に左右されます。
ただし、ここをそのまま「4B級と同じ」と言い切るのも雑です。理解のしかたとしては、巨大モデルの代替というより、計算量を抑えながら役割分担させやすい設計だと捉えるのが安全です。
② 131K文脈とMoE構成
もう1つの見どころは、長い入力を抱えたまま中間処理を回しやすいことです。技術レポートとモデルカードでは、131Kの文脈長に加え、64 expertsのうち8つをactiveにするMoE構成が示されています。
この設計が効くのは、大きなrepo説明、RAGで集めた断片、複数のtool結果をいったん整理してから次に渡す場面です。長文を丸ごと保持しつつ、毎回最大級の計算を払わずに済むので、高頻度の前処理や橋渡し役と相性が出ます。
逆に、長文を読めること自体が最終品質を保証するわけではありません。文脈長は「抱えられる量」、MoEは「回し方の効率」と分けて見ると、用途判断を誤りにくくなります。
③ InstructとThinkingの違い
variantは「どちらが上か」ではなく、何を担当させるかで選ぶのが基本です。JetBrainsのモデルカードでは、Instructは低遅延の応答向け、Thinkingは複雑なデバッグやmulti-step planning向けとして分けられています。
| variant | 向く作業 | 先に意識したいこと |
|---|---|---|
| Instruct | 直接の応答、軽いコード支援、素早い整形 | 速さを優先したい時の入口に向く |
| Thinking | 複数段の推論、難しめのデバッグ、agent的な分岐判断 | 1回ごとの深さを取りたい時に向く |
迷ったら、まずはInstructで回転数が必要な工程を受け持たせ、詰まる箇所だけThinkingへ寄せると考えると扱いやすいです。
向いている使い方
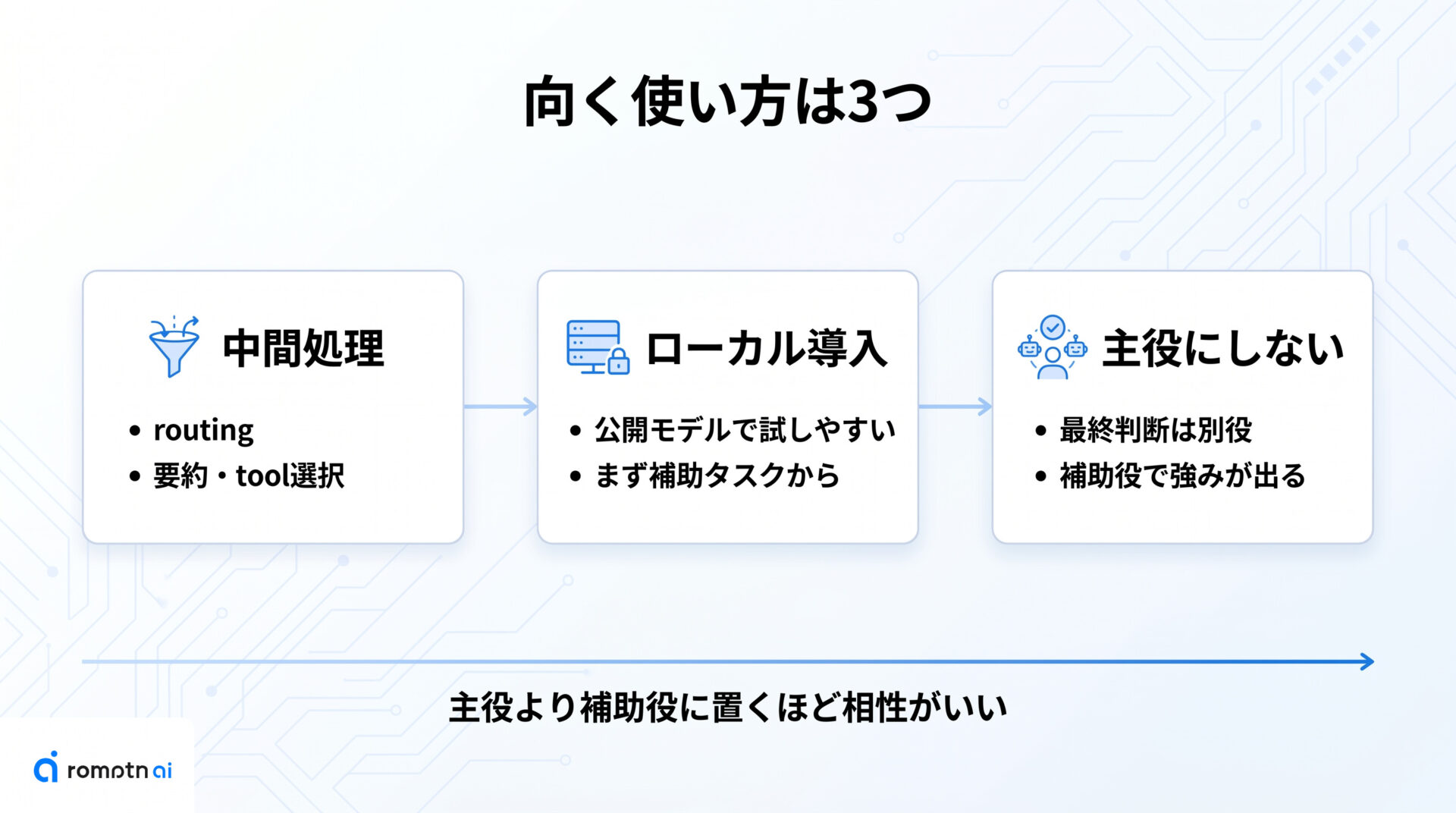
次は、Mellum2を実際のワークフローのどこに置くと効くかを見ます。
考え方はシンプルで、「最終回答の主役」より「何度も呼ぶ補助役」に寄せるほど相性が出ます。JetBrainsが示しているrouting、RAG、sub-agent、tool useの文脈も、まさにこの使い方に沿っています。
つまり、Mellum2は単体万能モデルとして構えるより、速さが価値になる工程へ差し込む方が活きます。以下の3パターンを自分の開発フローに重ねると、試す順番が決めやすくなります。
① 速さが効く中間処理
いちばん相性が分かりやすいのは、高頻度で回す中間処理です。たとえば、問い合わせをどのagentへ振るか決めるrouting、RAGで集めた断片の圧縮、使うtoolの選択、長い文脈を次のモデル向けに整える工程がここに入ります。
こうした処理は、1回ごとの天井性能より、待ち時間と回転数の方が効きます。Mellum2をここへ置くと、主役モデルの呼び出し回数や負荷を減らしやすくなります。
要するに、「答えを全部出させる」より「次の一手を素早く整える」用途で強みが出やすいということです。
② ローカル導入の入口
ローカルで試したい人にとっては、入口が公開されている点も大きいです。モデルカードではvLLMやDocker Model Runnerの起動例が示され、量子化モデルへの導線も用意されています。
まずはInstructを単体で立ち上げ、短いコード支援や整形処理から試すのが現実的です。重い主役置換として始めるより、補助工程から入る方が失敗しにくくなります。
③ 主役にしない場面
逆に、Mellum2だけで全部を済ませようとすると、期待値がずれやすいです。難しい設計判断、長い調査を踏まえた最終コード生成、万能な対話体験を主役1台で求める場面では、より大きいモデルや別役割のモデルを併用した方が自然です。
これは性能不足というより、役割設計の問題です。Mellum2の価値は「速くて軽い補助役」にあるので、主役まで背負わせると強みが薄れます。
迷ったら、下流の最終判断は大きいモデル、上流の整理や分岐はMellum2という分担で考えると、使いどころを外しにくくなります。
Mellum2のよくある質問
- QMellum2は個人のローカルPCでも使えますか?
- A
使い始める入口はあります。モデルカードにはvLLMやDocker Model Runnerの例、量子化モデルへの導線があるため、自前環境で試すこと自体はしやすいです。ただし、実際の快適さはGPUや量子化方式で変わるので、まずは小さめの補助タスクから確認するのが安全です。
- QInstructとThinkingはどちらを選べばいいですか?
- A
最初はInstructから入る方が分かりやすいです。短い応答や軽いコード支援、整形処理のように回転数を重視する用途へ置きやすいからです。複雑なデバッグや複数段の推論が必要な場面で、Thinkingを追加で試すと役割差を判断しやすくなります。
- QMellum2はClaude Codeの代わりになりますか?
- A
そのまま代わりと考えるより、補助モデルとして組み込む方が実態に合います。コード支援の中間処理やagentの振り分け役としては相性がありますが、広い対話能力や最終判断まで一括で任せる前提では見ない方が安全です。
- QJetBrains IDEの中でもう使われていますか?
- A
執筆時点で前面に出ているのは、モデル公開とワークフロー上の用途整理です。IDE内での将来の製品統合を連想しやすい題材ですが、今回の公開資料だけで具体的なロードマップまで断定するのは避けるべきです。まずは公開モデルとしての役割を理解するのが先です。
Mellum2のまとめ
最後に、Mellum2をどう見るべきかを短く整理します。
- Mellum2の強みは、巨大モデルの代替よりも速い補助役として置けること
- 軽さは総パラメータ数だけでなく、active parametersやMoE設計で見ること
- まず試すなら、routing、RAG前後の整形、軽いコード支援のような中間処理から入ること
次に手を動かすなら、公開されているモデルカードを見てInstructを立ち上げ、自分のワークフローのどの中間工程を受け持たせるかを1つ決めるのがおすすめです。最初から主役交代を狙うより、補助役としての強みを確かめる方が、Mellum2の価値を正しく掴みやすくなります。
豪華大量特典無料配布中!
romptn aiが提携する完全無料のAI副業セミナーでは収入UPを目指すための生成AI活用スキルを学ぶことができます。
ただ知識を深めるだけでなく、実際にAIを活用して稼いでいる人から、しっかりと収入に直結させるためのAIスキルを学ぶことができます。
現在、20万人以上の人が収入UPを目指すための実践的な生成AI活用スキルを身に付けて、100万円以上の収益を達成している人も続出しています。
\ 期間限定の無料豪華申込特典付き! /
AI副業セミナーをみてみる

