
LocateAnything-3Bが話題でも、『GUIエージェントに本当に効くのか』『YOLO系と何が違うのか』『そのまま本番に入れられるのか』が曖昧なままだと、触るべきか判断しにくいはずです。
このモデルの価値は、GUIや文書の細かな対象を自然言語で見つける視覚部品として、computer-useの弱点だった定位を強化できる点にあります。一方で、ベンチの強さだけ見て導入すると、ライセンスやservingの制約で期待を外しやすいのも事実です。
この記事を読めば、LocateAnything-3Bがどこで強く、なぜ速く、どの制約を先に見るべきかまで一気に整理できます。自分のagent基盤で試す価値があるかを、hypeではなく判断材料ベースで見極められるようになります。
内容をまとめると…
LocateAnything-3BはGUIや文書の細かな対象を自然言語で拾える視覚グラウンディング基盤
ScreenSpot-Proで前に出た強みは、GUI agentの取りこぼし削減に直結しやすい
PBDが位置特定の待ち時間を削り、multi-stepなcomputer-useと噛み合う
非商用ライセンス とserving未成熟があるため、本番投入よりR&D評価向き
生成AIを「少し触って終わり」にせず、業務効率化・副業・AIエージェント活用までつなげたい方向けに、基礎から実践まで整理できる無料資料を用意しています。
記事とあわせて、AIに作業を任せる考え方や長く使える活用スキルを確認しておきたい方は受け取っておいてください。

LocateAnything-3Bは何が違う?
LocateAnything-3Bは、NVIDIAが公開した汎用視覚グラウンディングモデルです。単に物体を検出するモデルというより、画像や画面を見ながら自然言語で指定した対象の位置を返せる土台モデルだと考えると分かりやすくなります。
公式モデルカードでも、LocateAnything-3BはGUI grounding、文書理解、OCR、物体検出、ポイント指定までまたぐ設計として説明されています。つまり、ボタンやアイコンを指したい場面、文書内の特定領域を見つけたい場面、細かな物体位置を返したい場面を、1つのモデル系統で扱おうとしているわけです。
ここが、YOLOやGrounding DINOのような特化型の検出器と混同しやすいポイントでもあります。NVIDIA自身も、LocateAnything-3BはSAM3やYOLOの直接的な置き換えではなく、より広い自然言語クエリを扱うVLM型の位置特定モデルとして設計したと説明しています。まずは『GUI agentが画面上の何を見るべきかを理解し、その位置を返すための視覚部品』として読むと、役割をつかみやすくなります。
何に使えるモデルか
LocateAnything-3Bの用途は、単一のデモに閉じません。公式モデルカードでは、GUI grounding、OCR、文書理解、物体検出、ポイント指定、さらにはロボティクスまで、かなり広いタスク帯を1系統で扱えるよう設計されたモデルとして整理されています。画面上の小さなUI要素を探す仕事と、文書内の特定領域を指す仕事を、同じ『自然言語で対象を特定する』問題としてまとめて扱えるのが特徴です。
この性質は、GUIエージェント文脈で特に効きます。エージェントがボタン、入力欄、タブ、通知、メニューを見つけたい時、従来はGUI専用モデルやルールベースの補助が必要になりがちでした。LocateAnything-3Bは、そうした対象を自然言語で指しながら位置を返す視覚部品として使えるため、computer-use系の構成に組み込みやすくなります。
同時に、これだけでエージェント全体が完成するわけではありません。実際には、何をクリックするかを決めるplanner、操作を実行するaction層、状態を見直すループが別に必要です。LocateAnything-3Bはその中で、『画面や画像の中から、今探すべき対象を高精度に見つける担当』として理解すると位置づけがぶれません。
GUIエージェントで注目される理由
LocateAnything-3BがGUIエージェント界隈で注目されているのは、単に新しいからではありません。高解像度の業務GUIで、自然言語の指示どおりに細かなUI要素を見つけるのは想像以上に難しく、従来モデルでは大きく取りこぼしやすかったからです。ScreenSpot-Proは、そうした現実寄りのprofessional GUIを集めたベンチで、GUI groundingの難しさをかなり厳しく測る指標として使われています。
このベンチの文脈では、従来系の最良モデルでもかなり低い水準にとどまっていた一方、LocateAnythingの技術レポートでは平均60.3という結果が示されています。重要なのは数字の大きさそのものより、『本当に細かいUIを当てるのが難しい場面で、既存より前に出た』ことです。画面の中の小さなボタンや入り組んだ業務UIを見失いにくいなら、computer-useの成功率に直結します。
GUIエージェントは、推論が賢くても視覚定位が外れると一手目から崩れます。クリック対象を1回外すだけで、その後の行動計画も連鎖的にずれていくからです。LocateAnything-3Bの価値は、巨大な万能モデルで全てを賄うことではなく、高解像度GUIで『どこを見るべきか』を強くする点にあります。
なぜ速いのか
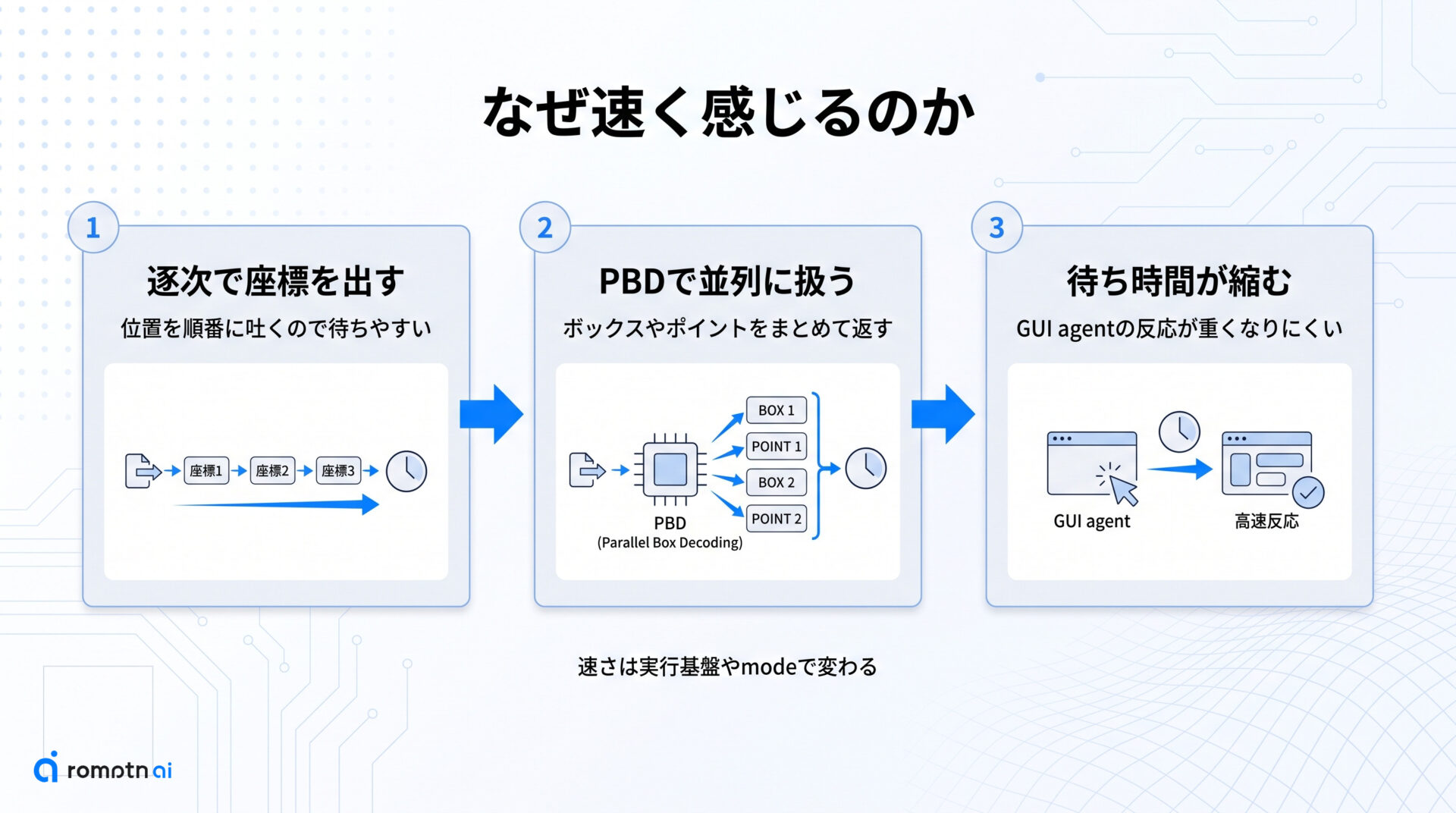
LocateAnything-3Bの中核は、Parallel Box Decoding、略してPBDです。従来のVLM系groundingでは、対象の座標をトークン列として順番に出していく方式が多く、この逐次生成が待ち時間のボトルネックになりやすい問題がありました。GUIエージェントのように『見る→判断する→また見る』を何度も繰り返す系では、この遅さがそのまま体感の重さになります。
PBDは、ボックスやポイントをより並列的に扱う発想で、その律速を崩そうとしています。NVIDIAのプロジェクトページと技術レポートでも、Hybrid Modeで最大2.5xのthroughput改善が示されており、単に精度を上げたというより、位置特定そのものを待たせにくくしたのが新しさです。高精度だけでは足りず、反応の速さも求められるGUI groundingと相性がよい理由はここにあります。
もちろん、どの環境でも無条件に同じ速度差が出るわけではありません。generation modeやattention実装、実行基盤の整い方で体感は変わります。それでも、座標を逐次で吐く前提から外しにいった設計は、GUI agent時代の視覚モデルとしてかなり筋がよいと見てよさそうです。
導入前に押さえる制約
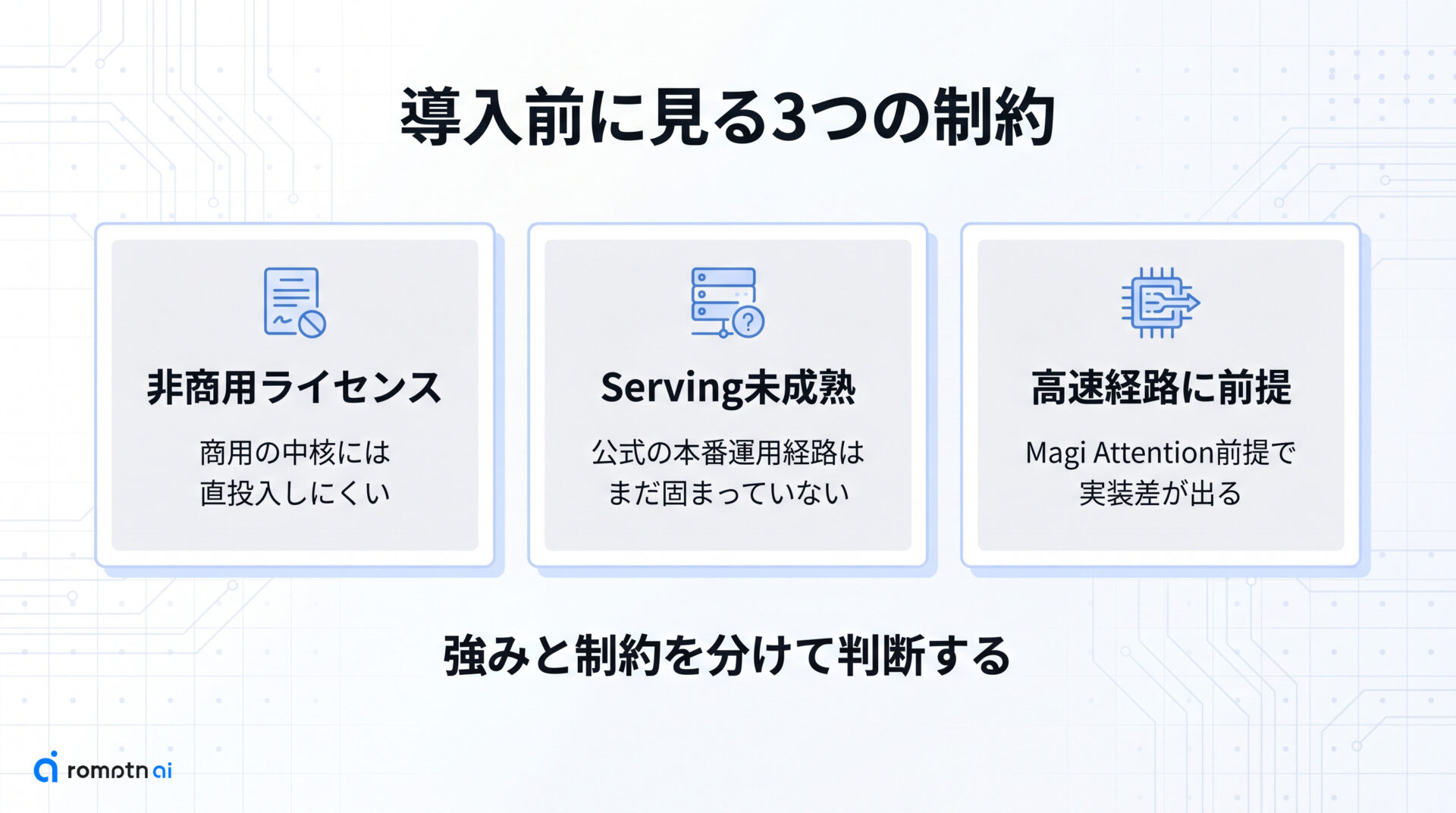
LocateAnything-3Bは、精度と速度の両面でかなり面白いモデルです。ただし、記事の前半で見た強みをそのまま『今すぐ本番投入できる基盤』と読んでしまうと危険です。少なくとも執筆時点では、ライセンス、servingの成熟度、高速経路の実装条件の3つに明確な注意点があります。
ここを曖昧にしたまま触り始めると、ベンチの印象と実装体験の差に戸惑いやすくなります。逆にいえば、次の3点を先に理解しておけば、LocateAnything-3Bを研究開発向けに試すべきモデルなのか、すぐ商用基盤に乗せるべきモデルなのかをかなり冷静に判断できます。
① 非商用ライセンス
まず大きいのはライセンスです。Hugging Faceのモデルカードでは、LocateAnything-3Bは研究開発向けの非商用ライセンスとして扱われています。つまり、試作や評価、技術検証の対象としては魅力的でも、そのまま商用サービスの中核に組み込む前提で読むべきモデルではありません。
ここを読み飛ばすと、『性能が高いならすぐ製品に入れたい』という判断を誤ります。もし商用導入を見据えるなら、まずは代替モデルや別ライセンスの選択肢も比較しつつ、LocateAnything-3BはR&D用途の検証軸として扱うのが現実的です。
② Servingはまだ発展途上
次に、servingの現実です。Hugging Face discussionでNVIDIAのメンテナは、vLLMやSGLangのような高スループット基盤での運用について、まだ十分に成熟した公式統合や即使える推奨構成がある段階ではないと説明しています。ベンチの強さと、OpenAI互換エンドポイントとして安定運用できることは別問題だということです。
そのため、いまのLocateAnything-3Bは『触ればすぐproduction ready』というより、研究開発寄りの導入体験を想定した方が安全です。特に、既存のagent基盤へそのまま差し替えるつもりなら、推論性能だけでなく、周辺runtimeの整備コストまで含めて見積もる必要があります。
③ 高速経路の実装制約
速度面でもう1つ注意したいのが、高速経路の前提条件です。NVIDIAの案内では、推奨されるhybridやfast modeは現状Magi Attention前提で、Flash AttentionはLLM側でまだ正式対応していません。つまり、『論文で速い』と『自分の環境でそのまま速い』の間には、attention backendの実装差が挟まります。
もしMagi Attention前提の経路をそのまま再現できないなら、sdpaやeagerへ寄せる構成になり、VRAMや計算コストの感触も変わりやすくなります。最初から最高速を狙うより、まずは動く構成で評価し、その後にどこまで高速経路を寄せられるかを見る方が、実装では詰まりにくいはずです。
どんな場面で向くか
LocateAnything-3Bが特に向くのは、対象が細かく、自然言語での指定が必要で、取りこぼしが致命傷になる場面です。たとえばcomputer-use系のGUIエージェントで、業務アプリの小さなボタンや複雑なメニューを探す場面はかなり相性がよさそうです。『保存ボタン』『請求先タブ』『未読通知』のように、人が言葉で指す対象を画面上で拾いたい時に価値が出ます。
文書理解やOCR寄りの場面でも、単なる全文認識より『この欄だけ見つけたい』『この注記の位置を返したい』という要求に強みがあります。ロボティクスでも、物体そのものを分類するだけでなく、『机の右端の赤い部品』のような自然言語を含む位置特定で効く余地があります。対象の位置を正しく返すことが次の行動の質を決める系では、かなり使い道があります。
逆に、固定ラベルの狭い検出だけで足りる場面や、最初から商用制約が厳しい本番基盤では慎重に見た方がよいでしょう。LocateAnything-3Bは万能エージェント本体ではなく、自然言語付きの視覚定位を強くする部品として採用判断するのがいちばん失敗しにくい見方です。
よくある質問
- QLocateAnything-3BはYOLOやGrounding DINOの代わりになりますか?
- A
完全な置き換えと考えるのは少し違います。LocateAnything-3Bは、NVIDIA自身が説明している通り、SAM3やYOLOのような特化モデルをそのまま置き換えるというより、より広い自然言語クエリを扱える汎用VLM型の位置特定モデルとして設計されています。
固定ラベルの狭い検出を高速に回したいだけなら、既存の特化型検出器が向く場面は残ります。一方で、GUI要素、文書領域、物体などを自然言語でまとめて指したいなら、LocateAnything-3Bの方が役割に合います。
- QLocateAnything-3Bは商用サービスにそのまま組み込めますか?
- A
そのまま商用サービスに入れる前提では読まない方が安全です。モデルカードでは非商用ライセンスとして扱われており、研究開発や検証用途には向いていても、商用提供の中心に据えるにはライセンス確認が先に必要です。
商用導入を考えるなら、まずは技術検証で価値を確かめつつ、並行してライセンス条件を満たせる代替案も見ておくのが現実的です。
- QLocateAnything-3BはvLLMやSGLangで本番運用できますか?
- A
執筆時点では、そこを即断できる段階ではありません。NVIDIAのコメントでも、vLLMやSGLangのような高スループット基盤での運用はまだ探索色が強く、即使える公式統合や推奨構成が固まっているわけではないと説明されています。
そのため、『ベンチで強いからそのまま本番APIにできる』とは考えず、研究開発向けの試行として扱う方が安全です。runtime整備まで含めた評価が必要になります。
- QLocateAnything-3BだけでGUIエージェントを完成できますか?
- A
できません。LocateAnything-3Bは、画面や画像の中から対象を見つける視覚部品としては強いですが、何をすべきかを決めるplannerや、クリックや入力を実行するaction層までは持っていません。
実際のGUIエージェントは、思考、視覚定位、操作、結果確認のループで成り立ちます。LocateAnything-3Bはそのうちの『どこを見るか』を強くするピースとして組み込むのが正しい使い方です。
まとめ
LocateAnything-3Bは、GUIエージェント時代に重要になる自然言語ベースの視覚グラウンディング基盤としてかなり注目に値するモデルです。単なる物体検出器ではなく、GUI、文書、OCR、ロボティクスまでまたぐ位置特定を1系統で扱い、高解像度GUIでの強さやPBDによる高速化も示しました。
要点を短くまとめると、次の3つです。
- GUIや文書のような細かな対象を、自然言語で指しながら見つけやすい
- PBDにより、位置特定の待ち時間を削りやすい設計になっている
- ライセンスとruntimeの制約があるため、まずはR&D用途で評価するのが安全
一方で、非商用ライセンス、servingの未成熟、高速経路の実装制約は軽くありません。だからこそ、『すぐ本番投入するモデル』としてではなく、まずはR&Dで価値を検証する対象として触るのが筋のよい入り方です。特にGUI agentを作っているなら、plannerやaction層は維持したまま、視覚定位だけを強化できるかを見ると判断しやすくなります。
最初の一歩としては、自分が扱う画面や文書で本当に細かな対象を拾えるかを確かめるのが有効です。性能の派手さだけでなく、ライセンスとruntime条件まで含めて見極められれば、LocateAnything-3Bを試す価値があるかどうかをかなり冷静に判断できるはずです。
AIを実務で使い続けるには、ツール名を覚えるだけでなく、目的を分解し、文脈を渡し、出力を評価する力が必要です。AI副業やAIエージェント活用の入口をまとめた資料セットを無料で受け取れます。
無料資料を受け取る

