
Z-Image-Turbo で LoRA を作ろうとして、普段の Stable Diffusion や FLUX と同じやり方が通用せず、手が止まっていませんか。速さを保とうとすると画像がボケ、品質を直そうとすると今度は生成が遅くなる。しかも ostris の training adapter や DistillPatch、Differential LoRA と似た用語が次々に出てきて、結局どれをいつ使えばいいのか判断できない。
この記事は、その迷いを「自分の目的と手元の GPU で選ぶ」一点に絞って解きほぐします。執筆時点で実用的な4つの学習方法を速さとVRAMの2軸で並べ、まず自分に合う1つを選べるようにしました。その上で AI Toolkit を使い、学習ステップ数・学習率・rank・解像度といった具体的な数値まで示して、読みながらそのまま再現できる形に落とし込みます。
読み終えるころには、12GB クラスの環境でも OOM させずに回す設定の見当が付き、学習後に速さを取り戻す仕上げまで、迷わず手を動かせる状態になります。
内容をまとめると…
普段の SD/FLUX と同じ感覚で当てると、速いと画像がボケて直すと遅くなる蒸留モデル特有の詰まり
学習方法は4つ、選ぶ軸は「速さを残すか」と「手元のVRAM」の2つだけ
迷ったら標準学習に DistillPatch を重ねるのが扱いやすい
道具は学習時(training adapter)と生成時(DistillPatch)で役割が別物
現実的なVRAM下限は12GB、8GBで回せるかは執筆時点では未確定
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Z-Image LoRAでつまずく理由
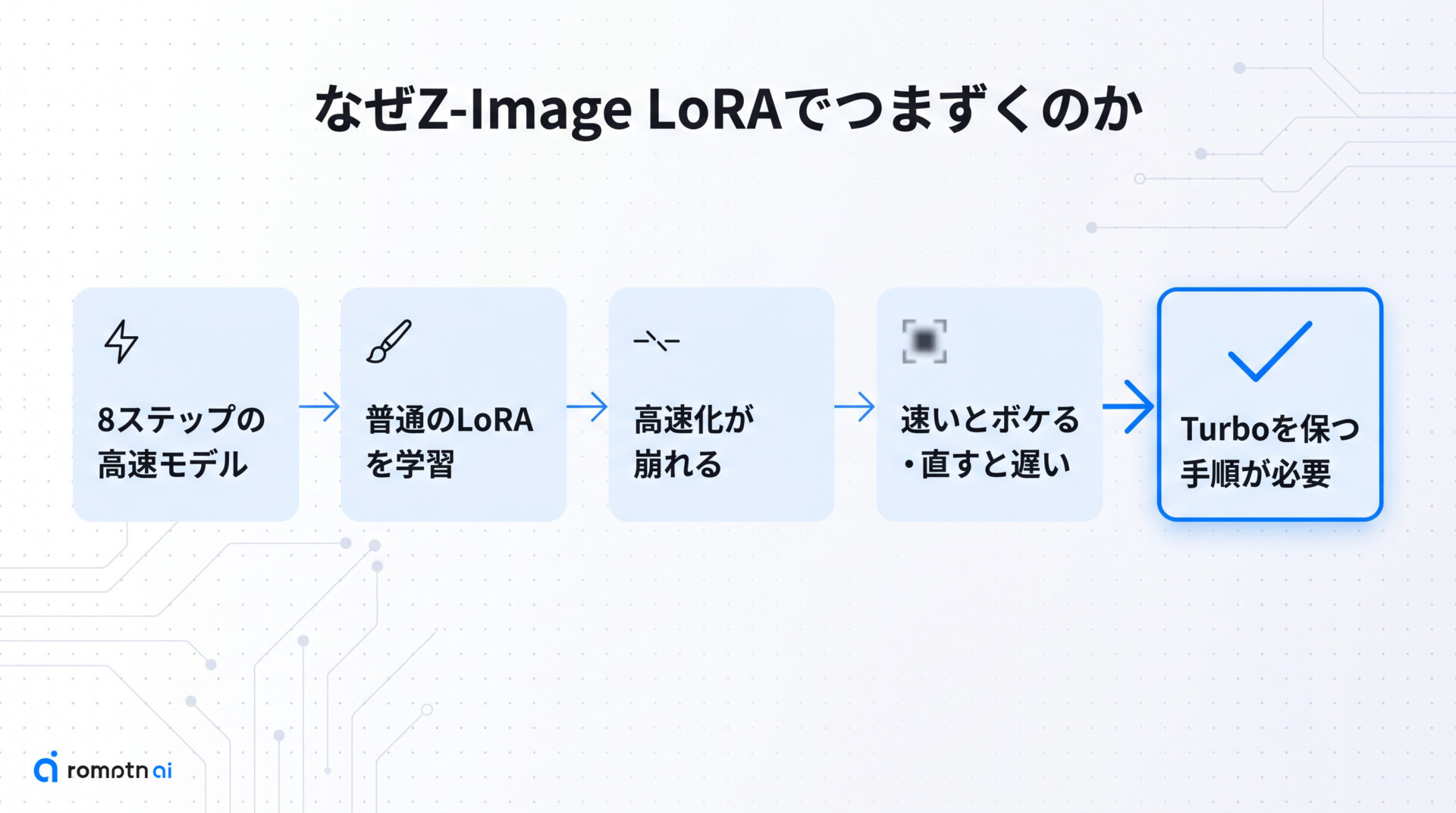
Z-Image-Turbo は、わずか8ステップで生成できるように調整された高速モデルです。そこへ普通の Stable Diffusion や FLUX と同じ感覚で LoRA を当てると、特有のつまずきが起きます。
代表的なのが、8ステップの高速設定で画像がボケてしまう症状です。ぼやけを直そうと生成ステップを増やすと今度は元の速さを失い、Turbo を使う意味が薄れます。
これは Z-Image-Turbo が「高速化のための学習」を一度仕込まれたモデルだからです。普通の追加学習を重ねると、その高速化の働きが少しずつ崩れていきます。
つまり問題は腕前ではなく、Turbo を保ったまま LoRA を学習する手順を知っているかどうかにあります。この記事を読み終えると、自分の目的と手元の GPU に合った学習方法を選び、再現できる数値で実際に回せるようになります。
前提となるZ-ImageとLoRAの基礎
本題に入る前に、この記事で前提とする2つの言葉を合わせておきます。
1つ目は Z-Image-Turbo です。これは少ない生成ステップで動くように高速化された画像生成モデルで、執筆時点では8ステップ前後での生成を想定して作られています。
2つ目は LoRA です。モデル本体はそのままに、小さな追加ファイルだけを学習させて、特定の人物や絵柄を後付けで覚えさせる仕組みです。
学習率(lr)・ステップ数・rank といった一般的な学習用語や、LoRA そのものの基礎は、ここでは深追いしません。はじめて LoRA を学習する方は、先に基礎を扱った記事に目を通しておくと、この後の手順がすんなり頭に入ります。
以降は「Z-Image-Turbo の素体に、自作の LoRA を当てて使う」ことを前提に話を進めます。
4つの学習方法を目的とVRAMで選ぶ
Z-Image-Turbo 向けの LoRA 学習には、執筆時点で大きく4つのやり方があります(この4分類はDiffSynth-Studio の学習戦略ガイドの整理に沿っています)。選ぶ基準は「速さを残したいか」と「手元の VRAM がどれくらいか」の2点です。
はじめての方や多くの用途には、4つ目の 標準学習+DistillPatch がおすすめです。普通に学習したあと、生成するときに加速用の追加ファイルを重ねるだけで、再学習なしに速さを取り戻せるためです。
速さより仕上がりを最優先するなら標準学習のみ、低めの VRAM で速さも残したいなら学習時に専用アダプタを使う方法が向きます。
4つの違いと、速さ・VRAM・向いている人を次の表にまとめます。なお速い生成は8ステップ・cfg=1、速さを使わない生成は30ステップ・cfg=2 が目安です。
| 学習方法 | 速い生成 | 必要 VRAM の目安 | 向いている人 |
|---|---|---|---|
| ①標準学習のみ | 使わない(30ステップ・cfg=2) | 標準的 | 速さより仕上がり最優先 |
| ②学習時アダプタ併用 | 残せる(8ステップ・cfg=1) | 低めでも可 | 軽く速く作りたい |
| ③二段学習 | 残せる(8ステップ・cfg=1) | 多め | 速さと仕上がりを両立したい |
| ④標準学習+DistillPatch(おすすめ) | 残せる(8ステップ・cfg=1) | 標準的 | 多くの人・再学習を避けたい |
②の「学習時アダプタ併用」は、別名で Differential LoRA とも呼ばれます。各方法の道具の使い分けは、次の章で詳しく切り分けます。
学習時と推論時の道具を切り分ける
混乱の元になりやすいのが、似た名前の道具がいつ使うものなのかが分かりにくい点です。判断の軸はシンプルで、学習時に使う道具か、生成時に使う道具かで分けると整理できます。
学習時に使うのが ostris の training adapter です。高速化の働きが学習中に崩れるのを遅らせる役割で、学習対象だけを覚えさせやすくします。
生成時に使うのが DistillPatch です。普通に学習した LoRA と並べて2枚目の追加ファイルとして読み込み、失われた速さを取り戻します。
前の章の②(学習時アダプタ併用)が training adapter を使う方法、④が DistillPatch を使う方法、と対応づけると迷いません。
AI Toolkitでの学習手順
ここからは、選んだ方法を実際に手を動かして再現していきます。この記事では学習ツールに AI Toolkit を使う前提で進めます。
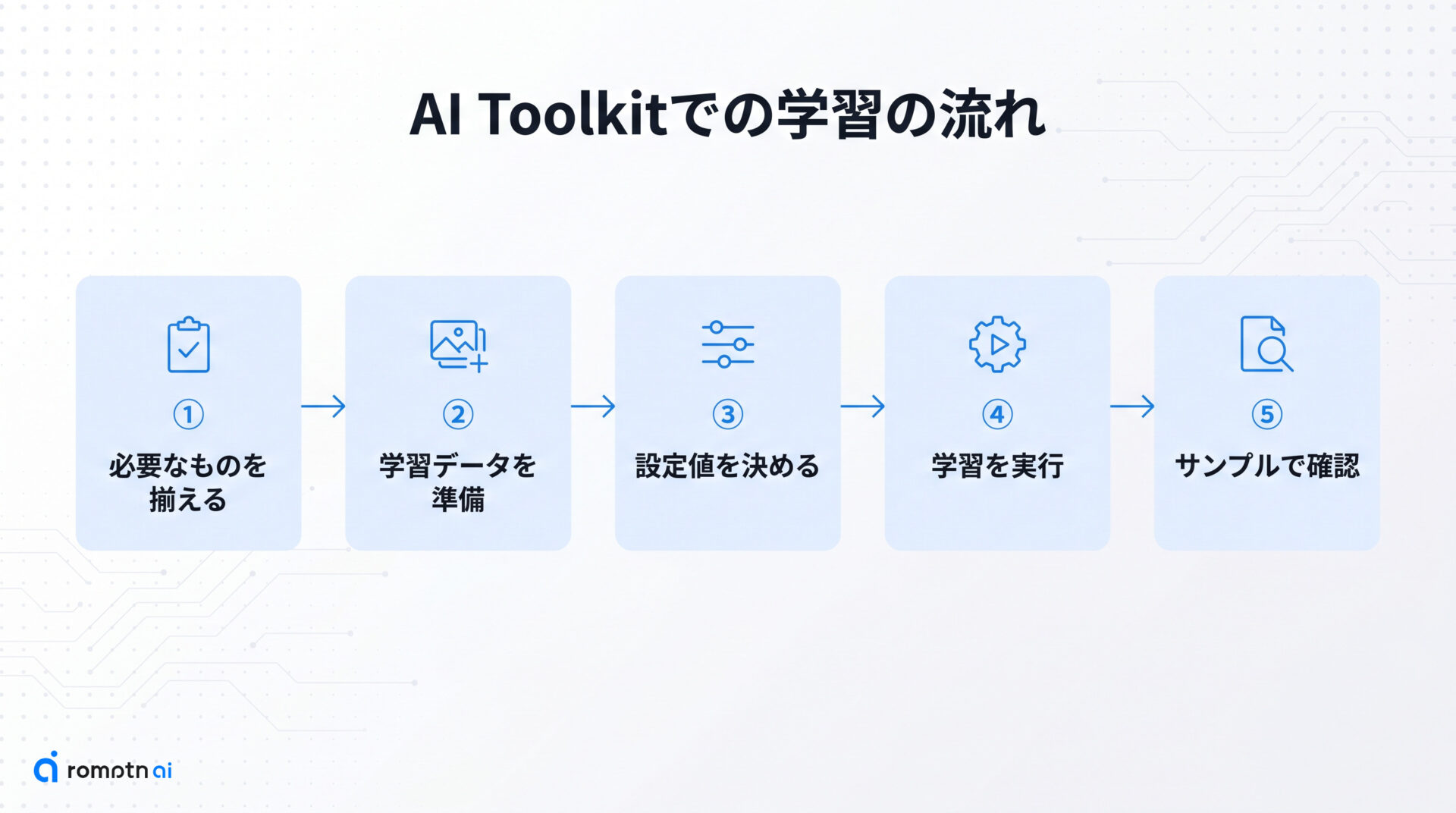
学習の流れは、次の5つの順番で進みます。
- ①必要なものを揃える
- ②学習データを準備する
- ③設定値を決める
- ④学習を実行する
- ⑤サンプルで仕上がりを確認する
各ステップでやることを、順番に具体的に見ていきます。順番に進めれば、はじめてでも一通り回せます。
①必要なものを揃える
まず、学習を始める前に手元へ用意するものを揃えます。
- 学習ツール: AI Toolkit
- 素体モデル: Z-Image-Turbo 本体
- 学習時アダプタ: ostris の training adapter(v1 または v2)
- GPU: 標準的には十分な VRAM、低めの環境では後ほどの省メモリ設定が前提
- 保存先: 学習ファイルやチェックポイント用の十分な空き容量
AI Toolkit は省メモリで動かすモードにも対応しており、後ほどの『12GB VRAMで回す設定』で低 VRAM 向けの調整に触れます。まずは上の5つが揃っているかを確認してから次へ進みます。
②学習データを準備する
次に、覚えさせたい対象の学習データを用意します。
枚数は意外と少なくて済みます。執筆時点の AI Toolkit ガイドでは、5〜15枚を目安として勧めています(9枚の1024×1024で対象を覚えさせられた例も報告されています)。
覚えさせるための合図として trigger word を1つ決めます。これは普通の言葉と衝突しない、辞書にない短い文字列にします(例: zchar_redhair のような造語)。
各画像には、同じファイル名の説明文(caption)を1つずつ添えます。説明文の中に、先ほど決めた trigger word を必ず入れておきます。
説明文の書き方は一貫させると、覚えさせたい対象が安定して定着します。
③設定値を決める
続いて、学習の設定値を決めます。執筆時点のAI Toolkit を使った LoRA 学習の実践ガイドが示す、再現しやすい数値のレンジは次のとおりです。
| 項目 | 目安の値 |
|---|---|
| 学習ステップ数 | 約3000(5〜15枚のデータ向け) |
| batch size | 1〜2 |
| 学習率(lr) | 1e-4 〜 5e-5 |
| LoRA rank | 4〜16(VRAM に余裕があれば8か16から) |
| 解像度 | 1024×1024 |
| 保存間隔 | 500ステップごと |
ステップ数が低すぎると覚え不足、高すぎると覚えさせすぎで指示が効きにくくなります。
学習時アダプタは、まず安定版の v1 を指定して回すのが無難です。より新しい v2 は学習の挙動や仕上がりが変わるため、v1 の結果と見比べてから採用を決めます。
④学習を実行する
設定が決まったら、学習ジョブを実行します。
学習中はチェックポイントが一定間隔で保存されます。先ほどの設定では500ステップごとに保存されるので、途中の状態にもいつでも戻れます。
所要時間は GPU 次第です。執筆時点の AI Toolkit ガイドでは、RTX 5090 でおよそ3000ステップの学習が約1時間と報告されています。VRAM が小さい環境ではこれより時間がかかります。
途中経過は、200〜300ステップごとに固定の seed でサンプル画像を出して確認します。仕上がりが目標に近づいてきたかを、この途中サンプルで見守ります。
⑤サンプルで仕上がりを確認する
学習が終わったら、仕上がりをサンプル生成で確かめて、止めどきを判断します。
まず、固定した seed で何枚か生成します。同じ条件で出すことで、覚え込みが進んだかどうかを公平に見比べられます。
次に、適用の強さ(lora_scale)を振って試します。執筆時点のガイドでは、生成時に0.5〜1.2の範囲で振って確かめる運用が勧められています。
強さを上げないと対象が出てこない場合は覚え不足、強さを下げても崩れたり指示が効かない場合は覚えさせすぎのサインです。ちょうど良い手前で学習を止めるのが、扱いやすい仕上がりへの近道です。
12GB VRAMで回す設定
VRAM が少ない環境でも、設定を絞れば学習を回せます。執筆時点で現実的な下限は12GB で、主な調整は次のとおりです。
- モデルと文章エンコーダの両方を float8(8ビット)に量子化してメモリを節約する
- 解像度バケットは512と768だけを有効にし、1024は外す
- batch size は1に固定する
- 学習ステップは1500〜2200を目安にする(データが10枚未満のとき)
- 最適化アルゴリズムは AdamW8Bit を使う
ここで挙げた12GB 向けの具体値は、二次的な解説ガイドとコミュニティの報告に基づくものです。AI Toolkit や素体の一次情報そのものではない点に注意してください。
学習後の推論と仕上げ
学習が終わったら、いよいよ自作 LoRA を使って生成します。ここでのコツは、学習に使ったアダプタを生成時には外すことです。
まず、学習時に使った training adapter を読み込み解除し、Z-Image-Turbo 素体に自作 LoRA だけを当てます。アダプタは学習を助けるためのもので、生成では使いません。
前の章の④(標準学習+DistillPatch)を選んだ場合は、ここで DistillPatch を2枚目の追加ファイルとして一緒に読み込みます。これで失われていた速さが戻ります。
あとは8ステップ・cfg=1 の速い設定で生成すれば、仕上がりを保ったまま Turbo の速さで出力できます。速さが要らない場面では、生成ステップを増やした通常設定に切り替える選択もできます。
よくある失敗と対処
つまずいたときは、症状から原因をたどると早く直せます。よくある4つの詰まりと対処は次のとおりです。
- 速い設定でぼやける: 標準学習だけで速さの働きが失われた状態。生成時に DistillPatch を併用するか、学習時アダプタを使う方法に切り替える
- 直そうとすると遅くなる: 30ステップに戻せば直るが速さを失う。根本的には DistillPatch で速い設定のまま仕上げる
- 指示が効かなくなる: 覚えさせすぎ。学習ステップを減らすか、生成時の適用の強さ(lora_scale)を下げる
- VRAM が足りずに止まる: float8 量子化・解像度512/768・batch1 など、先ほどの『12GB VRAMで回す設定』の章のように絞る
どの詰まりも、学習時と生成時のどちらの道具を使うかの選択に戻ると整理できます。自分の症状に近い行から手を打ってみてください。
Z-Image LoRA学習のよくある質問
- Q4つの学習方法のうち、初めてならどれを選べばいいですか?
- A
標準学習に DistillPatch を組み合わせる4つ目の方法がおすすめです。普通に学習したあと、生成するときに加速用の追加ファイルを重ねるだけで速さを取り戻せます。
再学習が不要で扱いやすく、執筆時点では多くの用途に向く実用的な選び方です。
- Qtraining adapter は v1 と v2 のどちらを使うべきですか?
- A
まずは安定した定番である v1 から始めるのが無難です。v2 は新しめで実験的な位置づけのため、学習の挙動や仕上がりが変わります。
作者は両方を自分のデータで試し、結果の良い方を選ぶことを勧めています。
- Q8GB の VRAM でも Z-Image-Turbo の LoRA 学習は回せますか?
- A
8GB で回せるかは執筆時点では未確定です。現実的な下限は12GB で、確実に始めたいなら12GB 以上を見ておくと安全です。
12GB の場合も、float8 量子化や解像度を512・768に絞るなどの省メモリ設定が前提になります。
- Qostris の training adapter と DistillPatch は何が違うのですか?
- A
使うタイミングが違います。training adapter は学習時に当て、高速化の働きが崩れるのを遅らせる道具です。
DistillPatch は生成時に2枚目の追加ファイルとして読み込み、失われた速さを取り戻す道具です。
- Q学習した LoRA を使うと画像がボケるのはなぜですか?
- A
普通の追加学習で、Z-Image-Turbo が持っていた高速化の働きが崩れるためです。その状態だと、8ステップ・cfg=1 の速い設定でぼやけが出ます。
生成時に DistillPatch を併用するか、学習時にアダプタを使う方法へ切り替えると直ります。
Z-Image LoRAの作り方まとめ
Z-Image-Turbo の LoRA 学習は、速さを保つ手順さえ押さえれば再現できます。要点を振り返ります。
- 学習方法は4つあり、速さを残すか・手元の VRAM がいくつかで選ぶ
- 迷ったら標準学習+DistillPatch が扱いやすい
- 道具は学習時(training adapter)と生成時(DistillPatch)で切り分ける
- 設定値は AI Toolkit の参考レンジに沿えば再現しやすい
- VRAM が少なければ float8 量子化と解像度を絞って12GB から
次の一歩は、自分の目的に合う方法を1つ選んで実際に手を動かすことです。まずは少ない枚数のデータで一度回し、サンプルで仕上がりを確かめながら調整していきましょう。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

