
ALE という名前を見ても、SWE-bench と何が違い、なぜ今そこまで話題なのかは掴みにくいはずです。ALE は AI agent を「コードが書けるか」だけでなく、「現実の仕事を最後までやり切れるか」で測ろうとする benchmark です。
だからこそ、スコアの高さだけで実務力を判断したくない人ほど、ALE を知っておく価値があります。評価軸がどこで切り替わっているのかがわかると、headline score の見え方がかなり変わります。
ここから、SWE-bench との違い、ALE の設計思想、なぜ今注目されるのか、数字の読み方までを順にたどります。読み終える頃には、benchmark の点数を鵜呑みにせず「仕事に近いか」で見る判断軸が持てるはずです。
内容をまとめると…
ALE は AI agent を現実の仕事に近い長時間タスクで測る benchmark
SWE-bench との違いは、仕事の広さ、タスクの長さ、採点の信頼性
低い pass rate は弱さの証明ではなく、実務条件の厳しさを映した数字
benchmark は点数よりも、業務への近さと採点設計で読む
生成AIを「少し触って終わり」にせず、業務効率化・副業・AIエージェント活用までつなげたい方向けに、基礎から実践まで整理できる無料資料を用意しています。
記事とあわせて、AIに作業を任せる考え方や長く使える活用スキルを確認しておきたい方は受け取っておいてください。

ALEとSWE-benchの違い
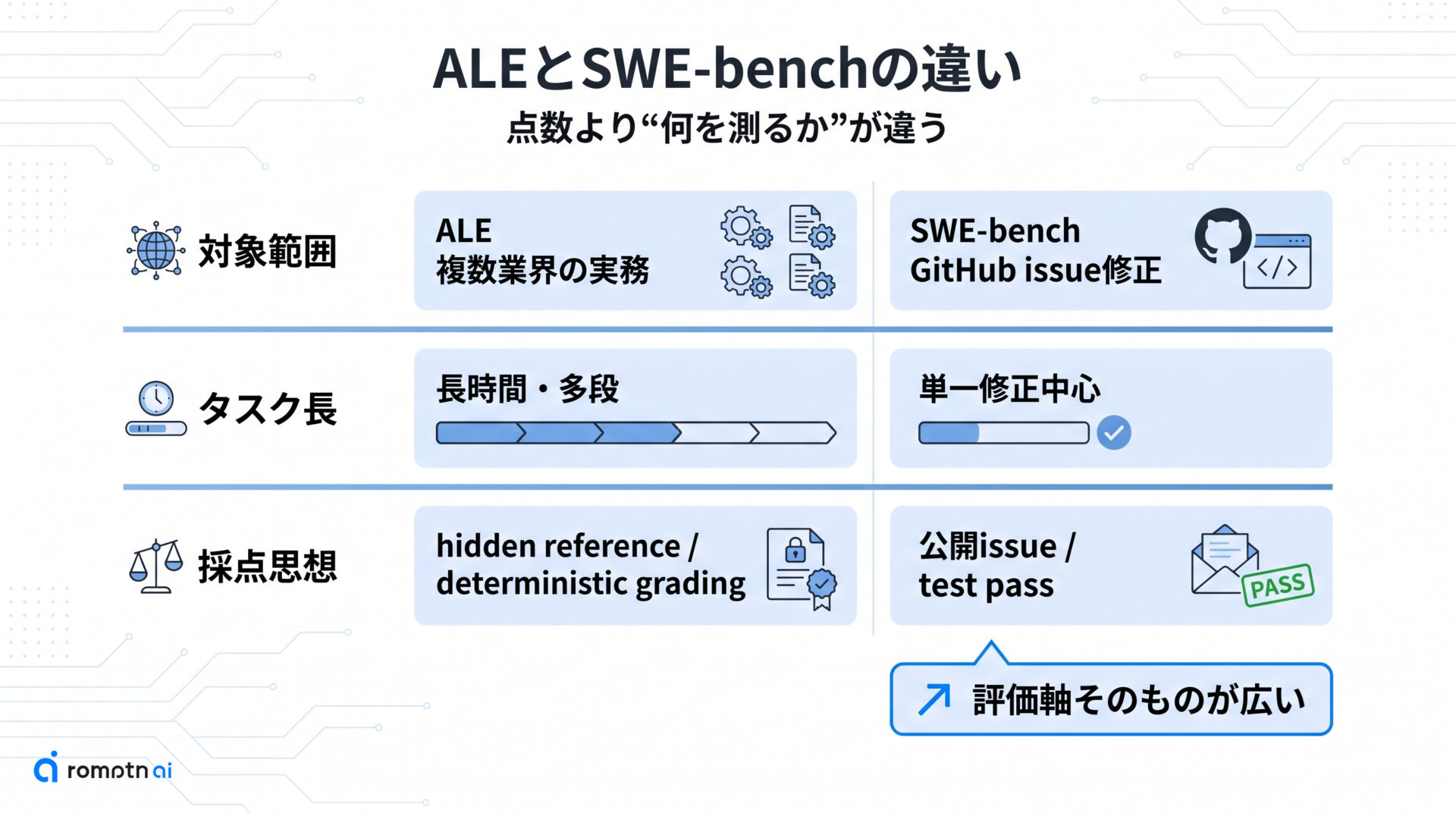
ここではまず、ALE が SWE-bench の延長線にある新スコアではなく、評価の物差しそのものを広げた benchmark だと押さえます。SWE-bench は GitHub issue を解けるかを見る設計ですが、ALE は複数の専門領域にまたがる仕事を最後までやり切れるかを見る設計です。
| 観点 | ALE | SWE-bench |
|---|---|---|
| 主な対象 | 複数業界の professional workflow | ソフトウェア開発の issue 解決 |
| タスクの長さ | 長時間で多段の作業 | リポジトリ単位の修正タスク |
| 評価の考え方 | hidden reference と deterministic grading を重視 | 公開 issue とテスト通過で評価 |
つまり差は点数の高低ではなく、何を仕事能力とみなすかにあります。次の章では、この違いを仕事の広さ、タスクの長さ、採点の考え方という3つの観点に分けて見ていきます。
① 測る仕事の広さが違う
いちばん大きい差は、仕事の対象範囲です。SWE-bench はソフトウェア開発の issue 修正を中心に置く一方で、ALE は医療、法務、金融、営業、設計など複数の industry cluster をまたぐ professional workflow を集めています。
この違いは、agent をどこまで実務に近い形で試したいかに直結します。コードを書けるだけでは足りず、情報を読み、判断し、必要なツールを使い分けながら成果物までたどり着けるかを見るため、ALE は benchmark の守備範囲を大きく広げています。
そのため、ALE を読む時は「coding が強いか」より「どの種類の仕事まで任せられる設計か」を先に見ると理解しやすいです。
② タスクの長さが違う
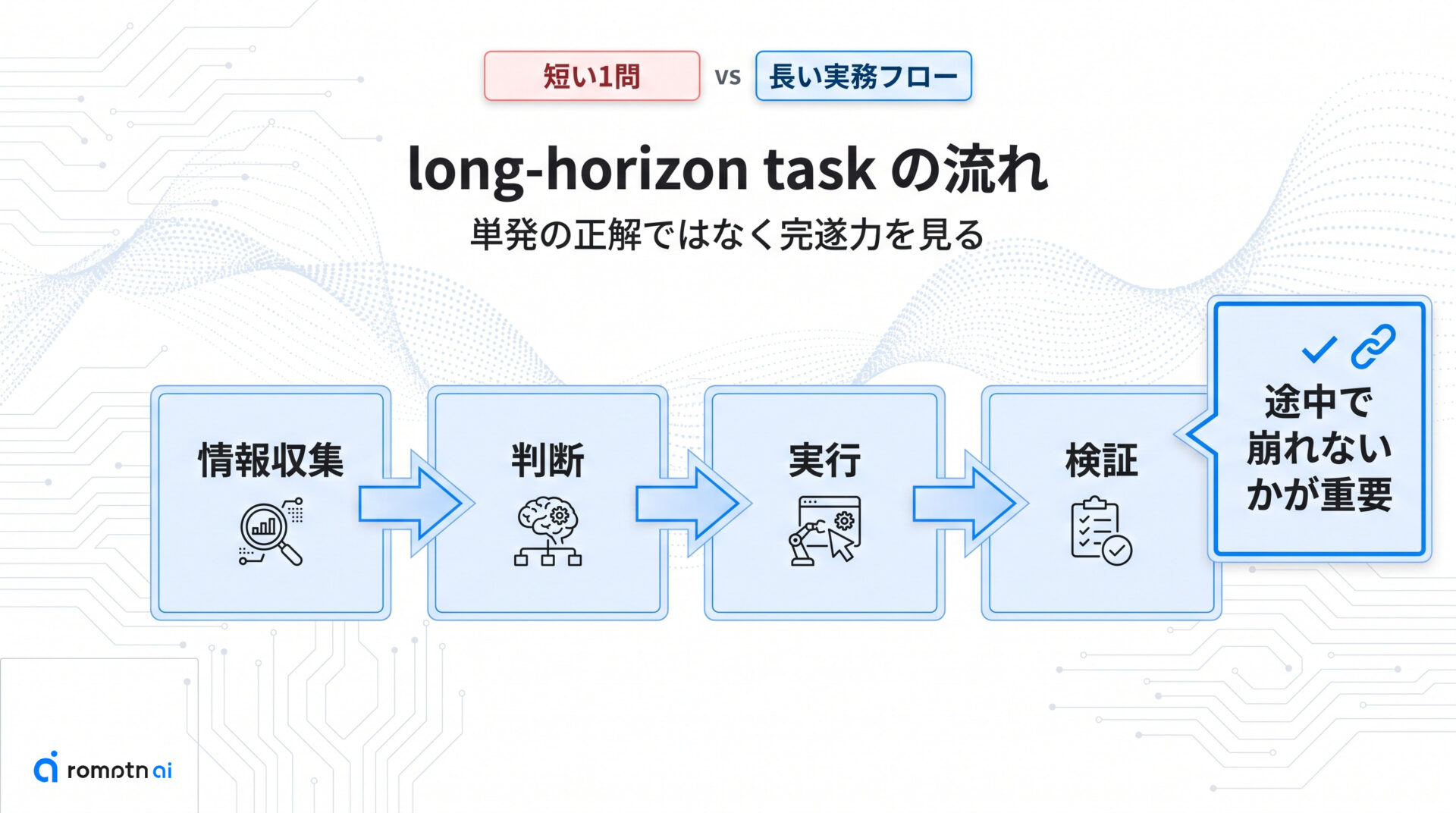
ALE は、短い1問を当てる benchmark ではなく、複数手順をまたぐ long-horizon task を完遂できるかを見る設計です。途中で必要な情報を集め、判断し、操作し、結果を検証する流れまで含めて評価するので、単発の正解より作業全体の持久力が問われます。
SWE-bench にも現実の issue を扱う強みはありますが、中心にあるのはリポジトリ上の修正タスクです。ALE はそこから一歩進み、実務で起きやすい『前提が揃っていない状態から最後まで進める力』を測ろうとしている点が新しいところです。
高スコアでも途中で段取りが崩れる agent は、長い仕事では失速しやすいです。ALE が見たいのは、まさにその失速しにくさだと考えると腹落ちします。
③ 採点の考え方が違う
ALE が重視しているのは、難しい task を並べることよりも、採点そのものを壊れにくくすることです。README では hidden references、deterministic graders、real OS sandboxes が前面に出ており、公開 benchmark に起きやすい暗記や抜け道を減らそうとしています。
この発想の背景には、既存 benchmark で contamination や exploit が問題になってきた流れがあります。公開 issue に近い課題は学習データに混ざりやすく、採点の穴を突かれると『実力より高いスコア』が出やすいからです。
要するに ALE は、task の中身だけでなく そのスコアをどこまで信じられるか まで設計し直そうとしている benchmark だと言えます。
ALEとは何か
ここでは、ALE そのものの定義をコンパクトに整理します。ALE は Agents' Last Exam の略で、AI agent が経済価値のある実務タスクをどこまで完遂できるかを測るために作られた benchmark です。
ポイントは、単なる static leaderboard ではなく living benchmark として運用されていることです。執筆時点では、論文では 1K+ tasks、公式サイトでは 1,500+ tasks を集めたと案内されており、公開後も task が増える前提で設計されています。
そのため ALE をひと言で説明するなら、現実の仕事に近い長時間タスクを、壊れにくい採点環境で測る benchmark です。この定義を先に持っておくと、後のスコア解釈もぶれにくくなります。
なぜ今 ALE が注目されるのか
ここでは、ALE がただの新 benchmark ではなく『今読む意味がある話題』になっている理由を整理します。注目の背景にあるのは、公開直後の新しさよりも、既存 benchmark の信頼性に対する不安が一気に表面化していることです。
OpenAI は SWE-bench Verified を frontier coding capability の代表指標として見なくなった理由を公表し、Berkeley RDI も主要 benchmark が exploit されうると指摘しました。つまり議論の中心が『誰が何点か』から『その点数をどこまで信じていいか』へ移っているわけです。
そのタイミングで、hidden reference や deterministic grading を前提にした ALE が出てきたため、Hugging Face Trending でも早い段階から共有されました。新しい benchmark というより、評価軸の更新候補として見られているのが現在の位置づけです。
ALE のスコアはどう読む?
この章では、headline score をそのまま能力ランキングだと思わないための見方を整理します。ALE の pass rate が低く見えても、それだけで『agent は使い物にならない』と読むのは早すぎます。
見るべきなのは、どれだけ長い task を、どんな採点条件で、どこまで再現よく完遂したかです。実務に近い workflow ほど途中で崩れやすいので、難しい benchmark ではスコアが低く出るのがむしろ自然です。
判断の軸としては、次の3点を意識するとぶれません。
- 自分の業務に近い task が含まれているか
- 採点が公開穴埋めではなく信頼しやすい設計か
- 単発のトップスコアではなく、継続して安定しているか
数字は便利ですが、最後に見るべきなのは『実務に近い条件でも崩れにくいか』です。その観点で読むと、ALE は単なる勝敗表よりずっと実用的な benchmark だとわかります。
ALE のよくある質問
- QALE は SWE-bench の完全な後継 benchmark ですか?
- A
いいえ、完全な置き換えというより守備範囲の違う benchmark です。SWE-bench は coding task を測る強みがあり、ALE はそれを否定するのではなく、複数業界にまたがる long-horizon task まで広げて評価しようとしています。
- QALE の pass rate が低いのは、今の agent が使い物にならないという意味ですか?
- A
そう単純には言えません。実務に近い task ほど途中で失敗する箇所が増えるため、難しい benchmark ではスコアが低く出るのが自然です。大事なのは数字の絶対値より、どんな条件でどこまで安定して完遂できたかです。
- Qbenchmark の数字を見る時、実務者は何を基準に判断すればいいですか?
- A
自分の業務に近い task が含まれているか、採点方法が信頼できるか、単発ではなく継続して再現できているかの3点で見ると判断しやすいです。数字だけで強弱を決めるより、業務条件への近さで読む方が実務判断に役立ちます。
ALE のまとめ
最後に、ALE をどう理解してどう使えばいいかを一度まとめます。ALE は新しい勝敗表というより、AI agent をどれだけ現実の仕事に近い条件で測れるかを問い直す benchmark です。
- SWE-bench との一番の差は、測る仕事の広さと長さにある
- hidden reference と deterministic grading により、スコアの信頼性まで設計し直している
- 低い pass rate は即座に無価値を意味せず、難しい実務条件を反映した結果として読むべき
- benchmark を比べる時は、業務への近さと採点の信頼性を先に見る
次に agent benchmark を見る時は、点数だけを追うのではなく、自分の業務に近い task をどこまで安定して完遂できるかを基準にしてください。その視点を持つだけで、ALE の数字はずっと実務的な情報に変わります。
ALE は『AI が仕事で本当に役立つか』を測る物差しを前に進める試みとして、今後も追う価値のある benchmark です。
AIを実務で使い続けるには、ツール名を覚えるだけでなく、目的を分解し、文脈を渡し、出力を評価する力が必要です。AI副業やAIエージェント活用の入口をまとめた資料セットを無料で受け取れます。
無料資料を受け取る

