
ComfyUIでAnimateDiffを利用すれば簡単にAIショート動画が生成できます!
さらに、すでに作成済みの画像を用いて動画を生成することも可能です!!
今回は、2枚の画像を使った動画生成の方法を設定から動画出力まで解説していきます。
※今回の記事は、以下の記事の派生となっております。ComfyUIやAnimateDiffの概要についてはこちらをご覧ください!

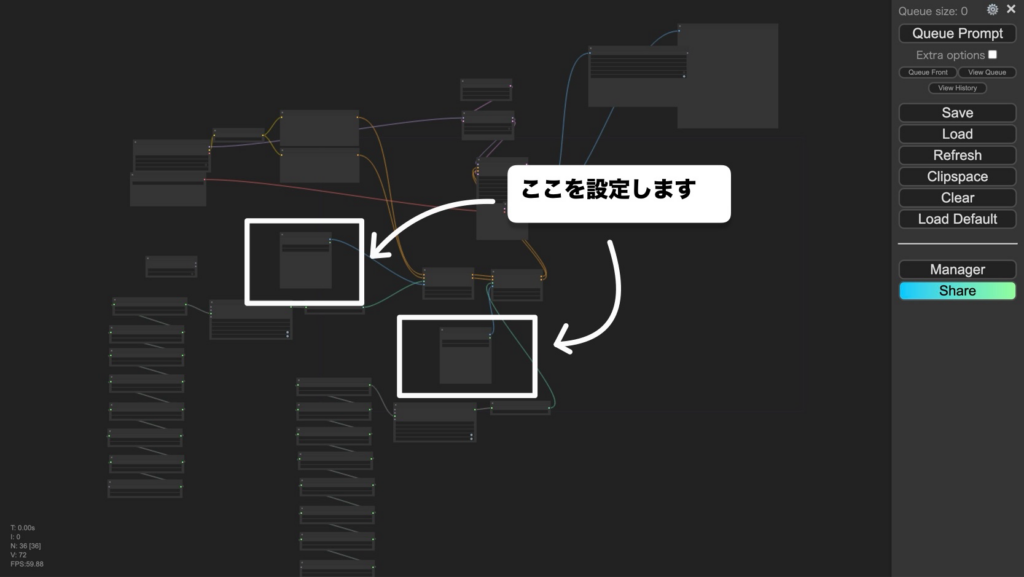
内容をまとめると…
ComfyUIのAnimateDiffを使えば、2枚の画像から中割りの動画(始点→終点)を自動生成できる
同じ顔の画像2枚はseed値の固定またはreference-onlyで用意する
ComfyUI-AnimateDiff-EvolvedとComfyUI-Advanced-ControlNetのインストールが必要
ControlNetはTileを選択し、出力フォーマットはgifやmp4から選べる
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

AnimateDiffで2枚の画像からAI動画を生成する方法
今回は、AnimateDiffを利用して2枚の画像から以下のような中割りの動画を生成する動画を紹介します。


AI画像を2枚用意する
動画を作成するには、始まりのコマとなる画像と終わりのコマとなる画像の2枚を用意する必要があります。
Stable DiffusionWebUIで先に画像を用意しておきましょう!
顔が同じ画像を生成する方法
Stable DiffusionWebUIを使用して同じ顔の画像を2枚用意しましょう。
同じ顔の画像を生成する方法は以下の2つがあります。
- seed(シード)値を固定する。
- 「reference-only」を利用する。
以下の記事で詳しく解説していますので、参考にしてください!

②ComfyUIを立ち上げる
ComfyUIを立ち上げる手順は、以下の通りです。
- ComfyUIのインストール
- モデル(チェックポイント)・VAEのダウンロード
- SDXL用のComfyUIを立ち上げる
以下の記事で詳しく解説していますので、参考にしてください!

③カスタムノードを準備する
以下の3つのカスタムノードをインストールしましょう。
- ComfyUI-Manager
- ComfyUI-AnimateDiff-Evolved
- ComfyUI-Advanced-ControlNet
インストールの方法は以下の通りです!
メインメニューの「Mananger」→「Install Custom Nodes」→ノードを検索してインストール。
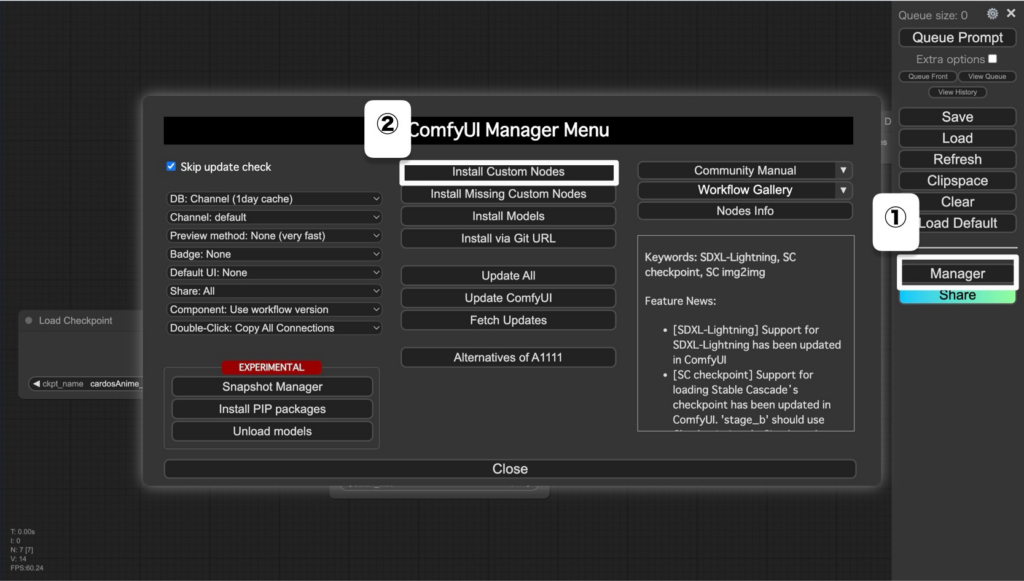
④ControlNetを準備する
1.Hugging Faceの公式ページから「LFS」と記載されているファイルをダウンロードします。
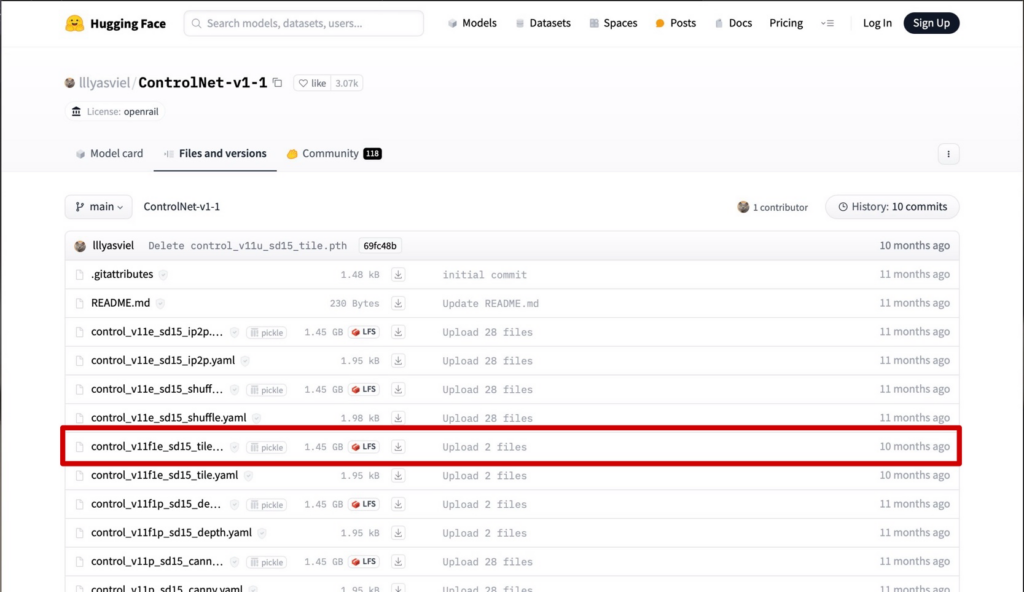
2.ダウンロードしたファイルをComfyUIのディレクトリの「ComfyUI」→「models」→「controlnet」に保存します。

⑤モデル(checkpoints)・VAEを準備する
モデル(checkpoints)はStable Diffusionのときと同様にCivitaiやHugging Faceから入手します。
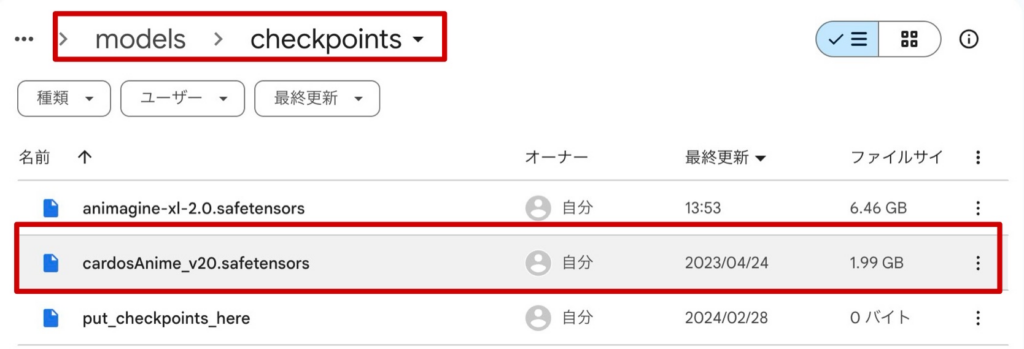
1.CivitaiやHugging Faceからモデルをダウンロードします。
2.ダウンロードしたファイルをComfyUIのディレクトリの「ComfyUI」→「models」→「checpoint」に保存します。
次にVAEをダンロードしましょう
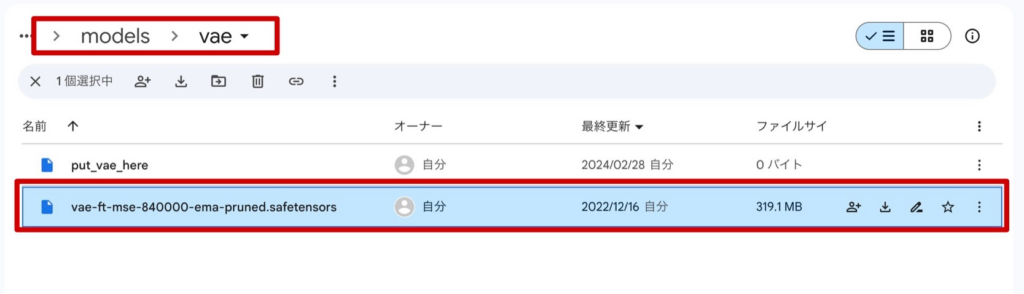
1.CivitaiやHugging Faceからモデルをダウンロードします。
2.ダウンロードしたファイルをComfyUIのディレクトリの「ComfyUI」→「models」→「vae」に保存します。
⑥モーションモジュールを準備する
AnimateDiff用のモーションモジュールをインストールしましょう。
1.以下のページからモデル「mm_sd_v14.ckpt」をダウンロードンします。


2.ダウンロードしたデータをComfyUIのディレクトリの「ComfyUI」→「custom_nodes」→「ComfyUI-AnimateDiff-Evolved」→「models」に保存します。

⑦公式で配布されているワークフローを読み込む
今回はこちらのワークフローを利用します。
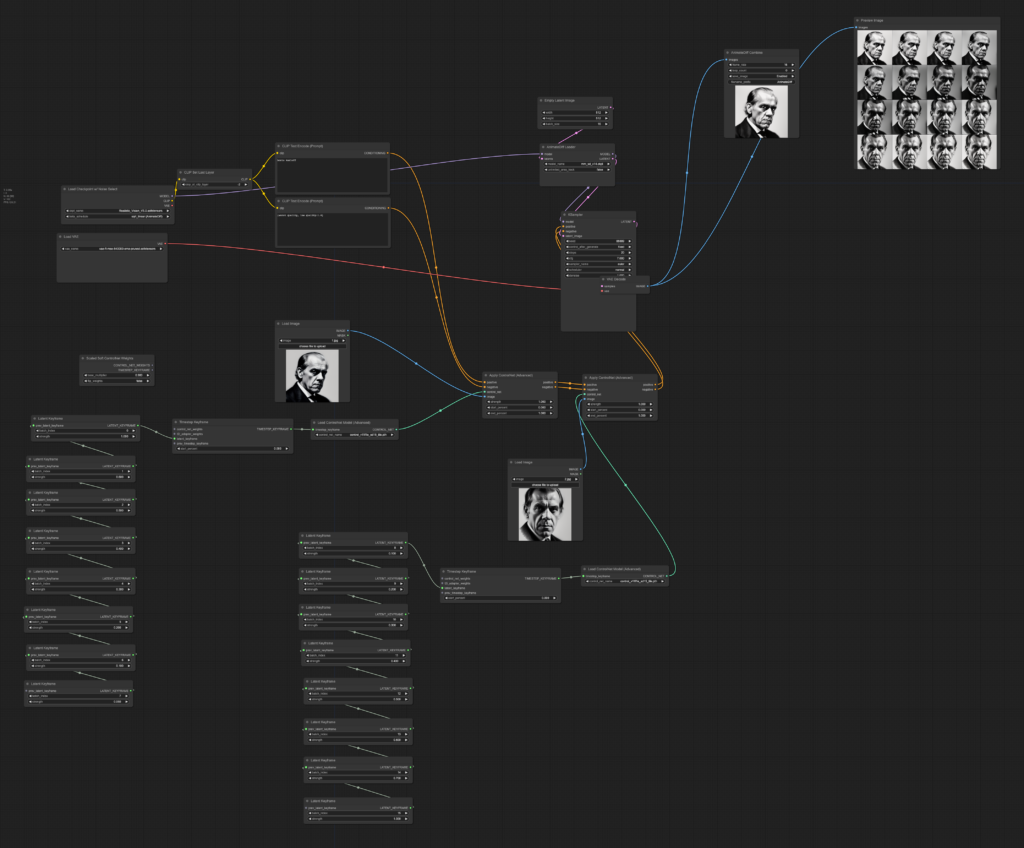
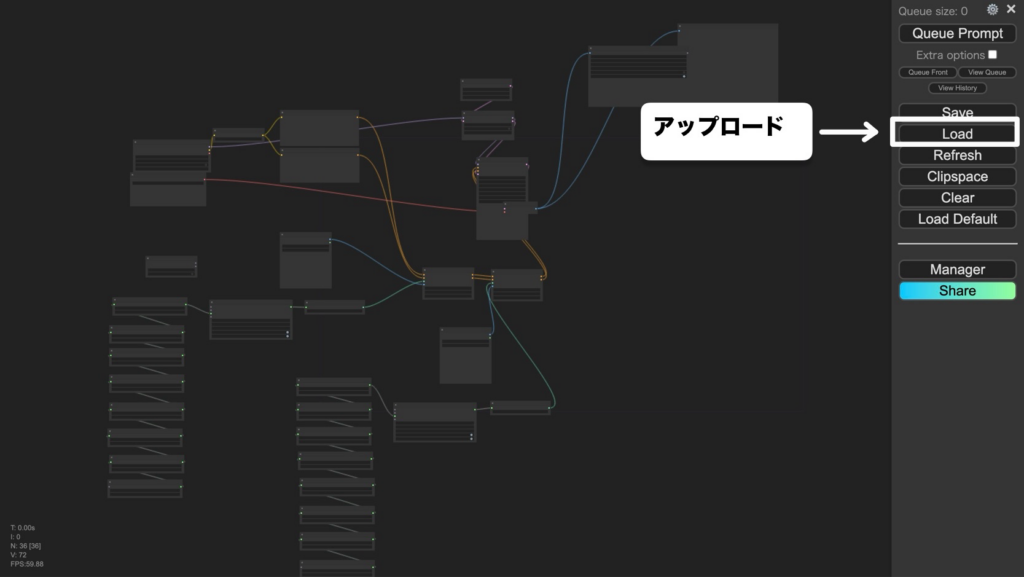
この画像をComfyUIの画面上にドラッグ&ドロップするかダウンロードして、メインメーニューの「Load」からComfyUIにアップロードしましょう。
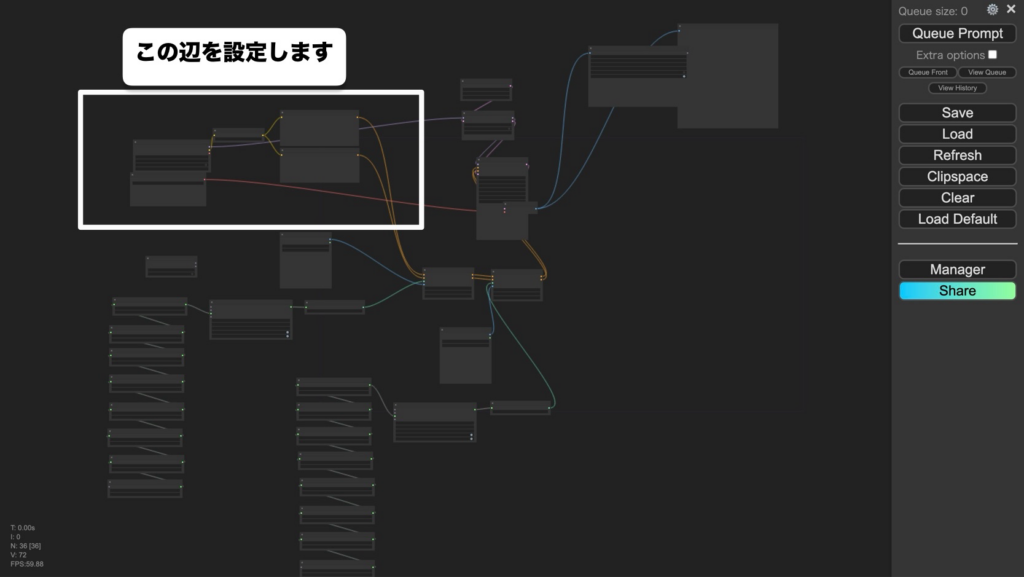
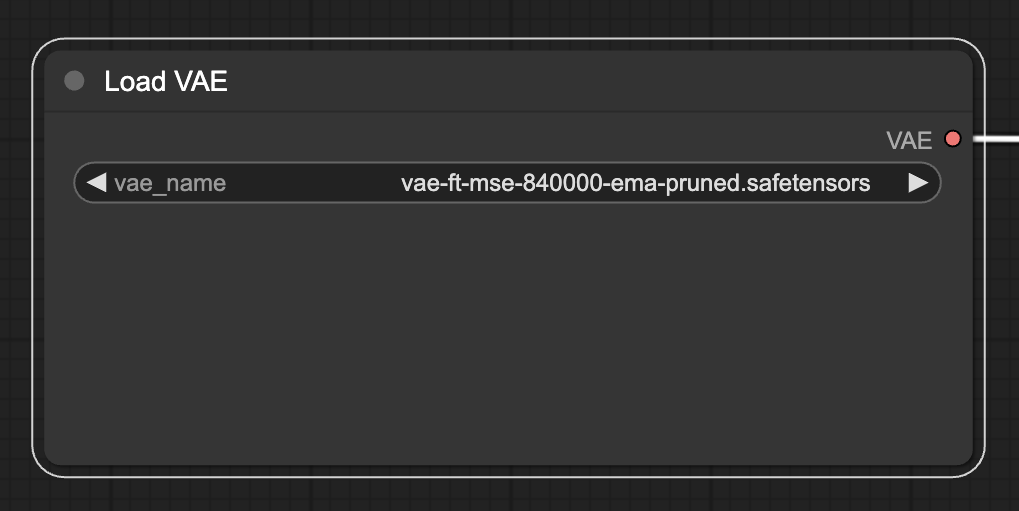
⑧モデル・VAEを選択する
ここからはアニメーションを実際に動画を生成してみましょう。
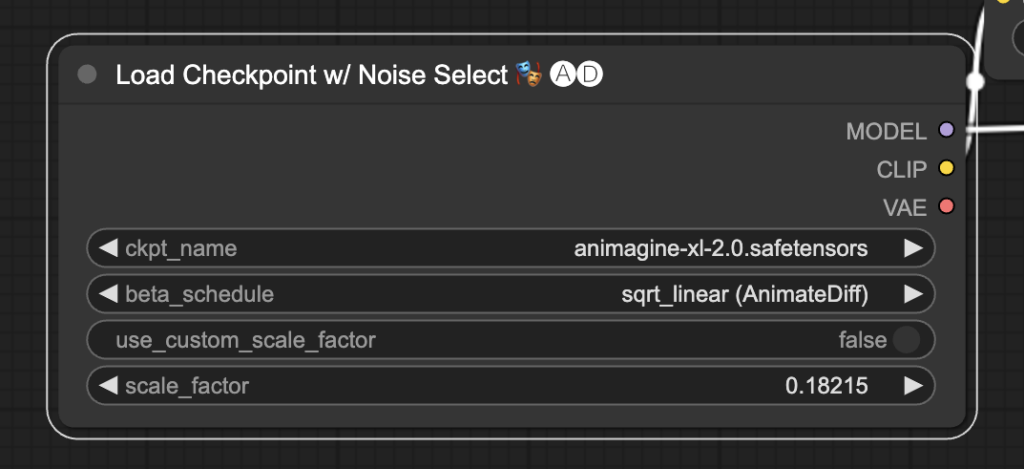
まずは、モデルを選択します。
次にVAEを選択します。
⑨プロンプトを指定する
ポジティブプロンプトとネガティブプロンプトを入力しましょう。

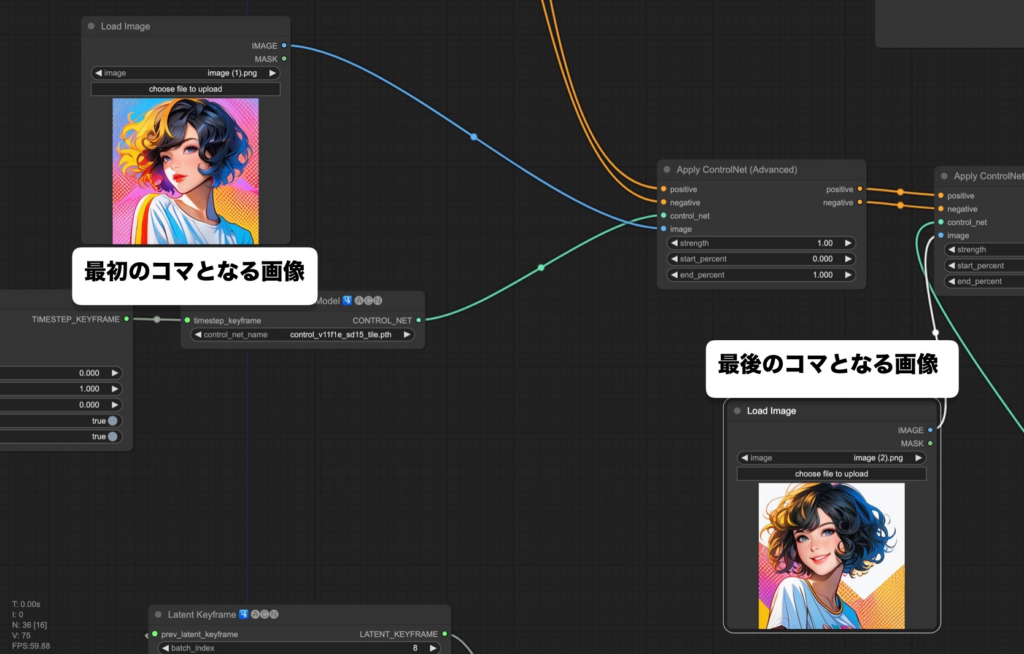
⑩用意した画像をアップロードする
ここで、最初に用意した2枚の画像を使用します。
最初とコマと最後のコマとなる画像を別々にアプロードしましょう。
⑪ControlNetを選択する
ControlNetのモデルを選択します。
ControlNetは2箇所選択する選択する場所があります。今回は「Tile」を選択しましょう。

⑫設定項目を入力して生成する
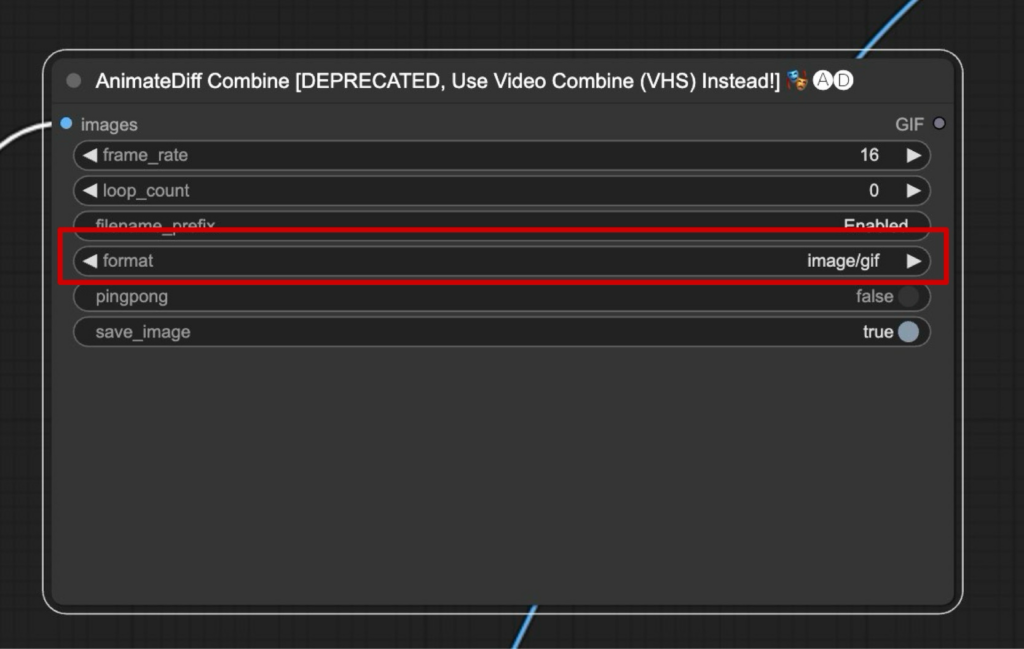
最後に出力値を設定します。
出力のフォーマット
「format」を選択します。デフォルトでは「animatediff」になっています。「gif」か「mp4」などお好きな形式を選択してください。
出力動画のサイズを選択する
「Empty Latent image」で動画のサイズを設定しましょう。

以上で設定が完了です。
準備が完了したらメインメニューの「「Queue Prompt」」をクリックして生成を開始しましょう!

生成された動画がこちららです。

まとめ
いかがでしたでしょうか?
【ComfyUI】AnimateDiffで2枚の画像からAI動画を生成する方法について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 同じ顔の画像を先に2枚用意する。
- モデルやControlNetの方法はStable DiffusionWebUIを変わらない。
- ワークフローを利用して動画を生成する。
AnimateDiffを利用し、始まりと終わりの画像を設定してから1つの動画を生成する方法を学びました。
このほかにもComfyUIやStable Diffusionに関する記事を扱っていますので、ぜいともご活用ください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

