
「Diffusersをもっと使いこなしたい!」
「DiffusersでControlNetを使えるって聞いたけど、どうすればいいかわからない…」
今回の記事では、DiffusersでのControlNetの使い方について徹底的に解説しています!
記事で紹介されている手順に従えば、簡単にDiffusersでControlNetを使うことができます。
ぜひとも最後まで読んで、DiffusersでのControlNetを使いこなしましょう!
内容をまとめると…
ControlNetはプロンプトだけでは伝えきれないポーズや構図を参照画像から指定できるStable Diffusionの拡張機能
DiffusersライブラリとControlNetを組み合わせると、Google Colab上でOpenposeなどの姿勢検出から高精度な画像生成が可能
SD 1.5向けに13種類、SDXL向けに2種類のControlNetモデルが公開されており、用途に応じて使い分けられる
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

ControlNetとは?
ControlNetは、Stable Diffusionの画像生成プロセスにおいて、細かなイラストの描写を可能にする革新的な拡張機能です!
プロンプトだけでは伝えきれないポーズや構図の指定が可能になり、これまでにない精度での画像生成を実現します。
ControlNetを使えば、キャラクターの特徴を維持しながら、色や画風を変えることができるのです。
また、線画に色を塗ったり、写真からイラストを作ったりすることも可能です。
ControlNetを利用することで、高品質な画像を生成することができるため、クリエイティブな作業がさらに楽しく、効率的になります!
※「ControlNet」については以下の記事で詳しく解説しています。

Diffuserとは?
Diffusersは、画像や音声、さらに分子の3D構造を生成することができる最先端技術のDiffusion Model(拡散モデル)を使えるライブラリです。
Diffusersは、生成物を簡単に作りたい人から、自分で拡散モデルを訓練してみたいと考えている人まで、幅広いニーズに応えます。
特に、「使いやすさを重視」、「直感的なシンプルさ」、「カスタマイズの自由度の高さ」に焦点を当てて設計されている点が魅力です!
このライブラリは以下の3つの主要な構成要素を持っています。
- 最先端の拡散パイプライン:数行のコードで動かせる多様なパイプラインがあり、これらが解決する課題についての情報が整理されています。
- 交換可能なノイズスケジューラ:作成するコンテンツの品質と生成速度のバランスを取るためのツールです。
- 事前学習済みモデル:これらを組み合わせて、始めから終わりまでの拡散モデルを構築することができます。
さらに、このライブラリでは、出力の生成、オリジナルの拡散システムの構築、拡散モデルの訓練に必要な基本スキルを学ぶためのチュートリアルやガイド、リファレンスが充実しています。
Diffusersを初めて使う場合には、これらのリソースからスタートすることをお勧めします。
※「Diffusersの立ち上げ方」については以下の記事で詳しく解説しています!

ControlNetのモデル一覧
ControlNetは、「Stable Diffusion」モデルにおいて、新たな条件を指定することで生成される画像をコントロールする機能を実現できます。
これにより、プロンプトだけでは表現しきれないポーズや構図の指定が可能になります。
特に、Stable Diffusion 1.5とSDXL用のモデルに焦点を当てて、その詳細を見ていきましょう!
Stable Diffusion 1.5
Stable Diffusion 1.5用には、以下のControlNetモデルが提供されています。
これらのモデルは、特定の技術やアプローチに基づいて学習されており、より精度の高い画像生成が可能です。
- lllyasviel/control_v11p_sd15_canny:Canny Edge検出で鮮明なエッジを描出
- lllyasviel/control_v11p_sd15_mlsd:マルチレベル線分検出で細かい線を捉える
- lllyasviel/control_v11f1p_sd15_depth:深度推定で立体感を表現
- lllyasviel/control_v11p_sd15_normalbae:表面法線推定で質感を再現
- lllyasviel/control_v11p_sd15_seg:画像セグメンテーションで細部まで区別
- lllyasviel/control_v11p_sd15_lineart:線画生成でイラスト風の画像を作成
- lllyasviel/control_v11p_sd15_openpose:人間の姿勢推定で自然なポーズを実現
- lllyasviel/control_v11p_sd15_scribble :落書きベースで自由な発想の画像を生成
- lllyasviel/control_v11p_sd15_softedge : ソフトエッジでやわらかな雰囲気の画像を作成
- lllyasviel/control_v11e_sd15_ip2p :ピクセルからピクセルへの指示で細かい操作を実現
- lllyasviel/control_v11p_sd15_inpaint : 画像修復で傷や欠陥を修正
- lllyasviel/control_v11e_sd15_shuffle : 画像シャッフルで新たな構成を試行
- lllyasviel/control_v11p_sd15s2_lineart_anime : アニメ風の画像を作成
これらのモデルは、様々な視覚的特徴に基づいた生成物のカスタマイズを可能にし、画像のセグメンテーションや線画生成、人間の姿勢推定など、特定のニーズに合わせた使用が可能です。
SDXL
SDXL用に提供されているControlNetモデルは、以下の2つです。これらのモデルも、特定の技術に焦点を当てており、SDXLの能力を最大限に引き出すために設計されています。
これらのモデルにより、SDXLでも高度な画像制御が可能になり、よりリアルで詳細な画像生成を実現します。
- diffusers/controlnet-canny-sdxl-1.0 : Canny Edge検出で鮮明なエッジを描出
- diffusers/controlnet-depth-sdxl-1.0 :深度推定で立体感を表現
ControlNetのモデル一覧には、画像生成の精度と表現力を高めるために、多岐にわたる技術が応用されています。
これにより、ユーザーは単に美しい画像を作成するだけでなく、具体的なビジョンやイメージを現実に変換することが可能になります!
DiffusersでのControlNet使い方
それではここからはDiffusersでのControlNetの使い方を解説していきましょう!
今回は、openposeを使ってみます。
以下の手順に従い、コードを実行してみてください。
1. パッケージのインストール
必要なPythonパッケージをインストールしています。
# 必要なパッケージのインストール
!pip install diffusers accelerate controlnet_aux omegaconf2. 初期画像の準備
生成の基になる初期画像を読み込み、適切なサイズにリサイズしています。
# diffusersから画像をロードするためのユーティリティ関数をインポート
from diffusers.utils import load_image
# 初期画像をロードしてリサイズする
init_image = load_image("ここに初期画像のパスをペースト") # 画像をロード
init_image = init_image.resize((512, 512)) # 512x512にリサイズ
# 初期画像の確認(ノートブック上で表示)
init_image初期画像はこちら

※初期画像のアップロードのやり方は以下の手順で行えます!
1. Google Colabの左側のフォルダーアイコンを開きます。
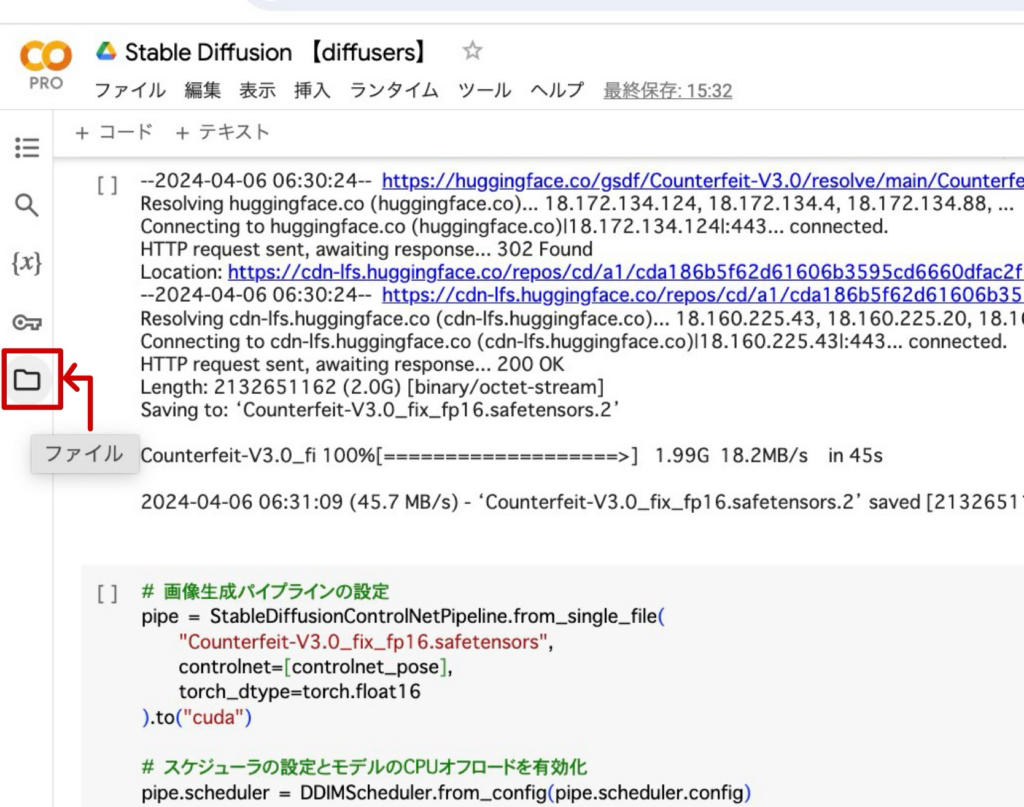
2. 画像のアイコンをクリックし、画像をColab上にアップロードします。
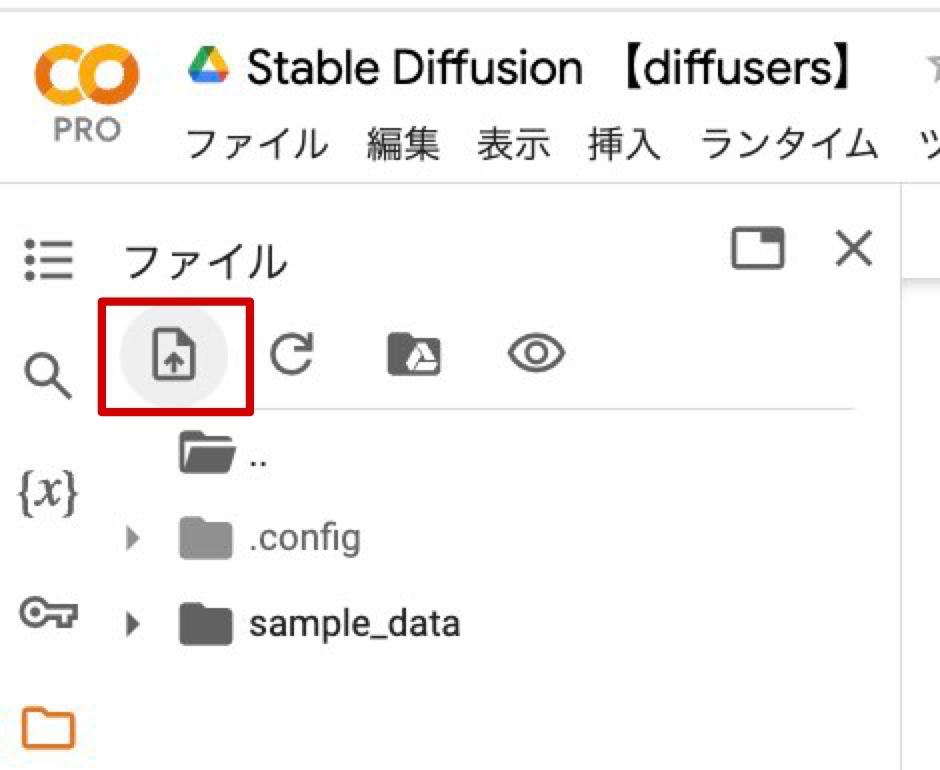
3. 画像のパスをコピーしてコード内にペーストします。
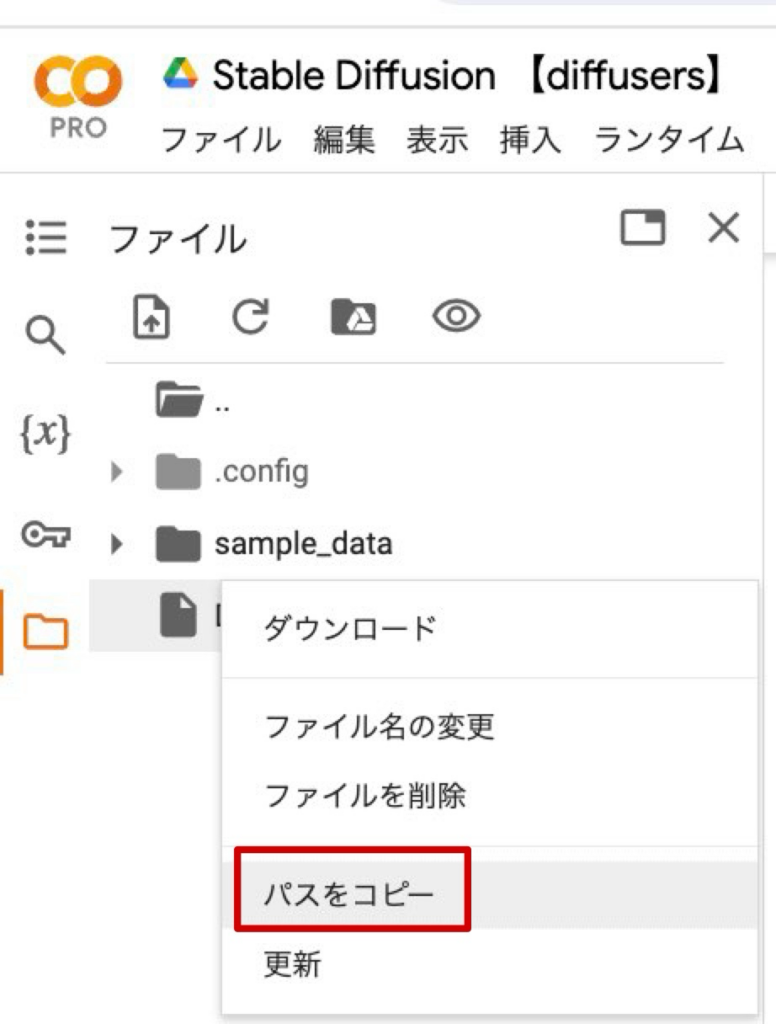
3. コントロール画像の準備
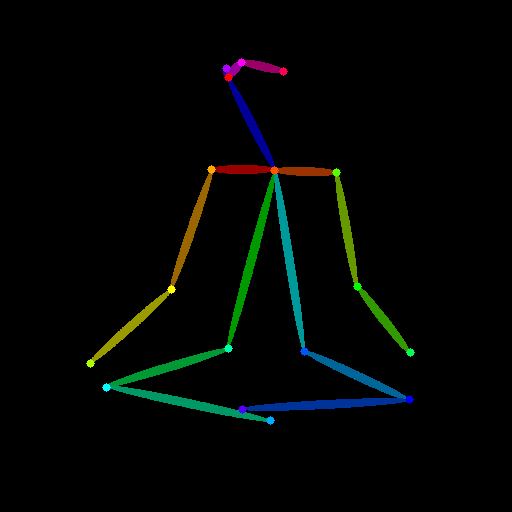
OpenposeDetectorを使用して、初期画像からポーズ情報を抽出し、それをコント画像として利用します。
# コントロールネットワークの検出器をインポートし、事前学習モデルを使って初期化
from controlnet_aux import OpenposeDetector
openpose_detector = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
# 初期画像からコントロール画像(ポーズ情報)を生成
openpose_image = openpose_detector(init_image)
# コントロール画像の確認
openpose_image初期画像から抽出した画像
4. ControlNetモデルの準備
ControlNetモデルをロードし、CUDA上での計算に設定しています。これは、画像生成時にポーズ制御を行うために使用されます。
# 必要なライブラリをインポート
import torch
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, DDIMScheduler
# ControlNetモデルをロードし、GPUに移動
controlnet_pose = ControlNetModel.from_pretrained(
"lllyasviel/control_v11p_sd15_openpose",
torch_dtype=torch.float16
).to("cuda")5. モデルのダウンロード
画像生成に使用する具体的なモデルファイルをインターネットからダウンロードしています。今回は、「Counterfeit-V3.0」を使用します。
# 必要なモデルファイルをダウンロード
!wget https://huggingface.co/gsdf/Counterfeit-V3.0/resolve/main/Counterfeit-V3.0_fix_fp16.safetensors6. パイプラインの準備
ここでは、ダウンロードしたモデルファイルを使用して、画像生成パイプラインを構築しています。
また、DDIMスケジューラを設定し、モデルの一部をCPUにオフロードしてGPUメモリを節約するオプションを有効にしています。
# 画像生成パイプラインの設定
pipe = StableDiffusionControlNetPipeline.from_single_file(
"Counterfeit-V3.0_fix_fp16.safetensors",
controlnet=[controlnet_pose],
torch_dtype=torch.float16
).to("cuda")
# スケジューラの設定とモデルのCPUオフロードを有効化
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()7. 画像生成
最後に、設定したパイプラインを使用して、任意のプロンプトを入力して画像を生成しましょう!
# 画像生成プロセスの実行
image = pipe(
prompt="A yoga posing anime woman, high detail, vivid colors", # 生成したい画像の内容
negative_prompt="(worst quality:1.4), (low quality:1.4), (monochrome:1.3)", # 除外したい内容
num_inference_steps=20, # 推論ステップ数
generator=torch.Generator(device="cpu").manual_seed(123), # 乱数生成器のシード固定
eta=1.0, # ETAパラメータ
image=[openpose_image], # コントロール画像の使用
).images[0]
# 生成した画像の確認
imageこちらが生成された画像です。

まとめ
いかがでしたでしょうか?
DiffusersでのControlNetの使い方について解説してきました。
今回のポイントをまとめると、以下のようになります。
- ControlNetはStable Diffusionの画像生成プロセスを細かくコントロールし、高精度のイラスト描写を実現します。
- Diffusersライブラリは幅広いニーズに応える最先端のDiffusion Modelを提供し、ControlNetと組み合わせることでその可能性をさらに拡大します。
- ControlNetの実装にはGoogle Colaboratoryを活用し、簡単なステップで初期画像から細かく調整された画像生成が可能です。
DiffusersでのControlNetを使うことにより、高度な画像とスピーディーな画像生成が可能になります。
この記事を読んでいただき、少しでもみなさんの疑問が解消されれば幸いです。
また、生成AIに関する更なる情報は、他の記事にて詳細に解説していますので、そちらの内容もぜひ確認してみてください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

