
Stable Diffusionを使っていると「この画風でもっと別のイラストを生成したい」「同じキャラクターの姿勢や表情だけを変えたい」と思うことはありませんか?
せっかく気に入った画風のイラストが生成できても、次に生成すると全く異なる雰囲気になってしまうことがよくあります。
本記事では、Stable Diffusionで一度生成した画風やキャラクターの特徴を維持したまま、様々なバリエーションのイラストを生成する方法を解説します。画風の固定、キャラクターの特徴の維持、自分の絵を学習させる方法など、実際の画像や設定例を交えながら詳しく紹介していきます!
※Stable Diffusionの使い方については、下記記事で詳しく解説しています。

- Stable Diffusionで画風を固定する方法(Seed/LoRA)
- 画風固定のためにLoRAを学習する方法
- 自分の絵をStable Diffusionに学習させる方法
- Stable Diffusionで画風を指定するおすすめのプロンプト・モデル
内容をまとめると…
Stable Diffusionで画風を固定するにはSeed固定・LoRA学習・プロンプト工夫・モデル選択の4つの手法がある
Seed固定は同じ値を使うことで構図やキャラの基本特徴を維持できるが、プロンプトやモデルを大きく変えると効果が薄れる
LoRAは10〜30枚の画像から効率的に画風を学習でき、50〜300MBと軽量で複数併用も可能
Google ColabのKohya Trainerを使えば低スペックPCでもLoRAの追加学習ができる
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Stable Diffusionで画風を固定する方法


Stable Diffusionで画風やキャラクターの特徴を固定するには、主に以下の方法があります。
- Seedの固定: 同じSeed値を使用することで、構図やキャラクターの基本的な特徴を維持
- LoRAによる学習: 特定の画風やキャラクターを少量の画像から学習させる
- プロンプトの工夫: 画風を表現するキーワードを適切に使用
- モデルの選択: 特定の画風に特化したモデルを使用
- その他の学習手法: HyperNetwork、Textual Inversion、DreamArtistなど
それぞれの手法には特徴があり、目的に応じて使い分けることが重要です。この後、それぞれの手法について詳しく解説していきます!
Seedを活用して構図とキャラクターを固定する方法
Seedは「種」という意味で、画像生成の出発点となるノイズパターンを決定する数値です。同じSeed値、同じプロンプト、同じモデルを使用すると、基本的に同じ画像が生成されます。
Stable Diffusionでは、まず「ノイズ」からスタートして徐々に画像を作り上げていきます。このノイズのパターンを決めるのがSeed値なのです。
Seedの確認方法

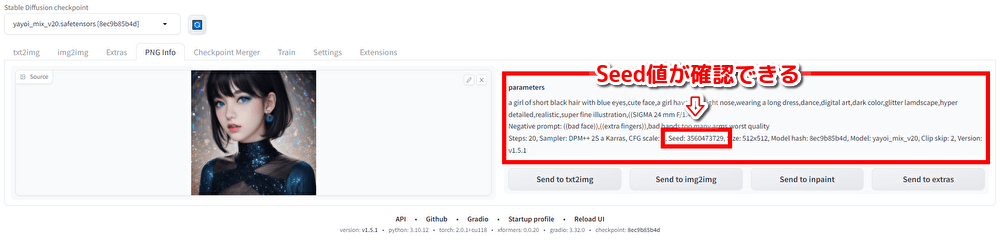
生成した画像のSeed値は以下の方法で確認できます。
- 生成直後の画像: 画像の下部に表示されるパラメータ情報にSeed値が記載されています
- 過去に生成した画像: Web UIの「PNG Info」タブで画像をアップロードすると、Seed値を含むパラメータが表示されます
Seedを固定して画像を生成する手順
①まずはじめに、ベースとなる画像を生成、または読み込みます。
今回は、このような画像を生成しました。

設定した呪文(プロンプト)は、以下の通りです。
呪文(プロンプト)
a girl of short black hair with blue eyes,cute face,a girl have a straight nose,wearing a long dress,dance,digital art,dark color,glitter lamdscape,hyper detailed,realistic,super fine illustration,((SIGMA 24 mm F/1.4))ネガティブプロンプト
((bad face)),((extra fingers)),bad hands,too many arms,worst quality画像の準備ができたら、Seed(シード)値の「サイクルボタン」を押します。
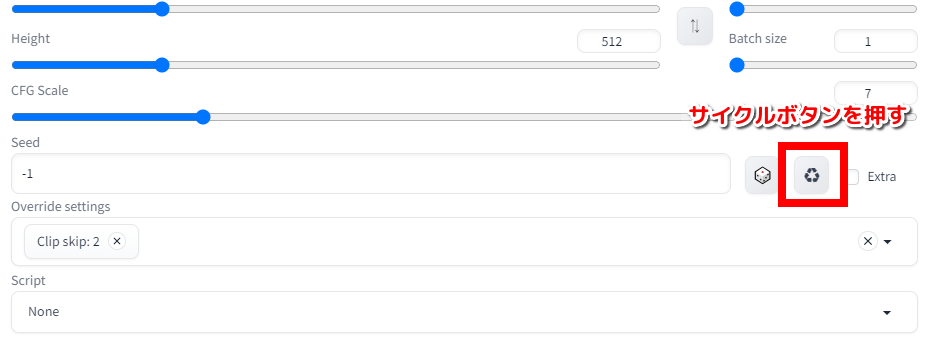
サイクルボタンを押すことで、Seed(シード)値が固定される=画像の設定が固定されるため、この画像を元に画像生成することができます。
(ランダム生成に戻したいときは、「サイコロボタン」を押します。)
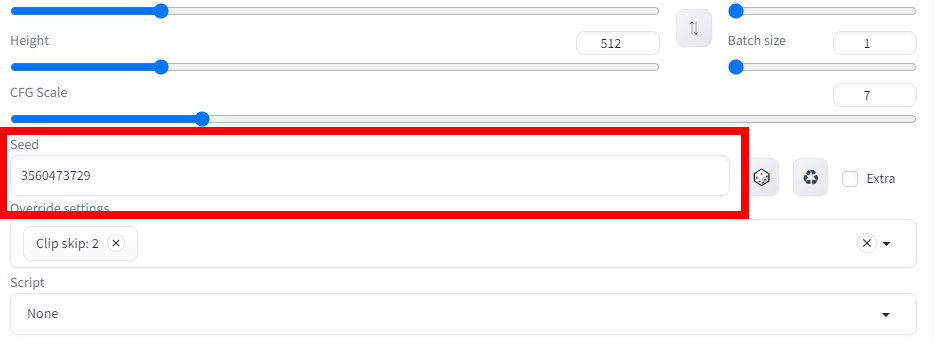
ベースとなる画像の設定が完了したので、早速同じ人物が生成できるか試してみましょう。
今回は冠をかぶせてみます。
呪文(プロンプト)に、冠という意味の「crown」を追加しました。
呪文(プロンプト)
a girl of short black hair with blue eyes,cute face,a girl have a straight nose,wearing a long dress,dance,digital art,dark color,glitter lamdscape,hyper detailed,realistic,super fine illustration,crown,((SIGMA 24 mm F/1.4))ネガティブプロンプト
((bad face)),((extra fingers)),bad hands,too many arms,worst quality生成された画像がこちらです。

元の画像と比較してみると、画風が固定されて生成されているのが分かりますね!

さらに詳しい情報は、下記記事で解説しています。

Seedの固定で変更できる範囲と注意点
Seedを固定しても、以下の場合は画像が大きく変わることがあります。
- プロンプトの内容を大幅に変更した場合
- モデル(Checkpoint)を変更した場合
- 画像の縦横比(アスペクト比)を変更した場合
また、部分的な変更だけを行いたい場合は、inpaintやControlNetの方が適している場合もあります。
※Inpaint機能やControlNetについては、下記記事で詳しく解説しています。


LoRAによる画風・キャラクター学習
LoRA(Low-Rank Adaptation)は、大規模な言語モデルや画像生成モデルを効率的に微調整するために開発された手法です。
Stable Diffusionの場合、完全なモデルを再トレーニングする代わりに、元のモデルの一部のみを修正することで、少ないデータ量と計算リソースで効果的な学習が可能になります。
LoRAの特徴と効果
①少量の画像からの効率的な学習ができる
- 最適な画像枚数: 10〜30枚程度が一般的
- 画像の多様性: 同じキャラクターや画風でも、様々なポーズ・表情・構図があると、より柔軟なモデルになります
- 学習効率: 従来のファインチューニングよりも10〜100倍の効率で学習可能
②ファイルサイズの優位性
- 一般的なサイズ: 50MB〜300MB程度(従来の完全なモデルは2〜7GB)
- 次元数によるサイズ調整: ランク(dimension)の値を変更することでサイズと品質のバランスを調整可能
- 軽量性のメリット: 多数のLoRAを組み合わせて使用したり、簡単に共有したりできる
③元モデルを変更せずに適用できる柔軟性
- 複数LoRAの併用: 異なる特性を持つLoRAを同時に適用可能(例:キャラクターLoRA + 画風LoRA)
- 強度の調整:
<lora:モデル名:0.7>のように数値を変えることで影響の強さを調整可能 - 異なるベースモデルとの互換性: 基本的に同じバージョンのStable Diffusionであれば、異なるモデル間でも使用可能
これらの特徴から、LoRAは画風を固定するのにピッタリなものとなっています。
画風固定のためにLoRAを学習する方法
では、追加学習させて『Lora』を作成する方法について詳しく説明していきます!
追加学習させる前に:学習させたい画像を準備する
今回は、2次元のイラストを学習させていきます。
フリー素材のイラストを何枚か用意しました。上半身の方が学習させやすいです。

これらの画像をzipファイルにまとめて、Googleドライブにアップロードします。

追加学習させる方法①:Google Colab用の「Kohya-Trainer」をコピー

上記のリンク先にアクセスし、1番上の「Kohya Lora Dreambooth」の「Open in Colab」リンクをクリックします。

そうするとノートブックが表示されますので、「ドライブにコピー」をクリックして、マイドライブに保存しておきましょう。
新しいタブで開かれますが、そちらを使うようにしてください!
いつも通り、ランタイムに接続して上から実行ボタンを押していきましょう。
※Google Colabの使い方については、以下の記事を参考にしてください。

追加学習させる方法②:Googleドライブのマウントとビルド設定
初期設定の状態では、マイドライブに読み書きすることはできなくなっています。
「mount_drive」にチェックを入れてから実行ボタンを押してください。
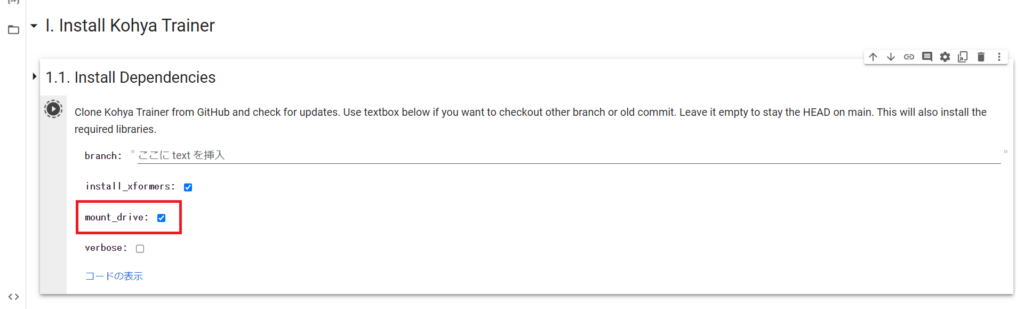
以下のような表示が出ますので、アカウントを選択して許可をしてください。
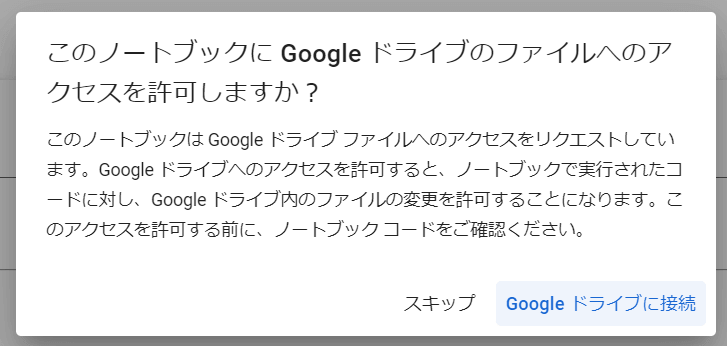
およそ5分ほどかかります。
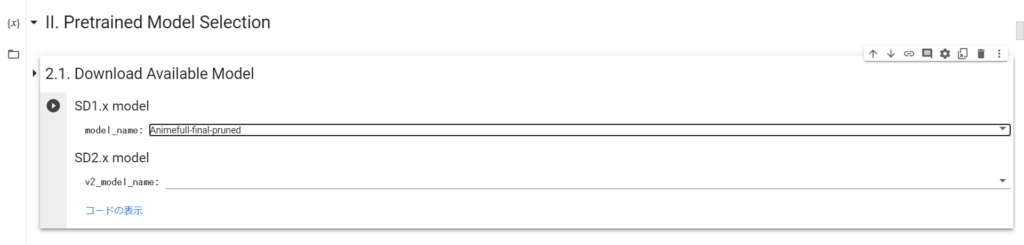
追加学習させる方法③:学習に使うモデルをダウンロード
今回は、デフォルトにある「Animefull-final-pruned」を使います。
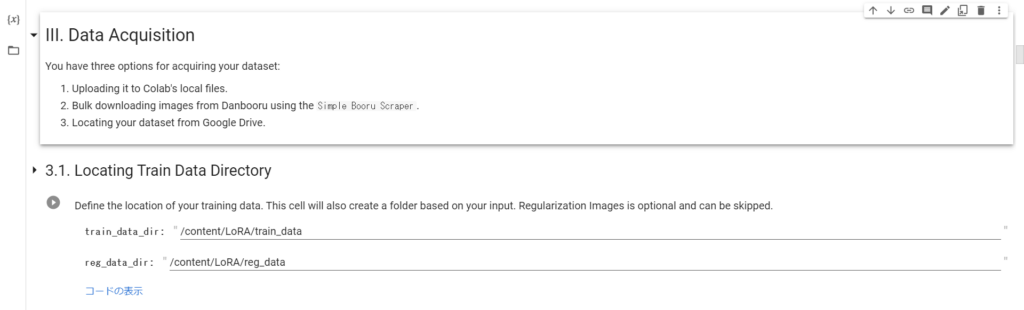
続いて「3.1.Locating Train Data Directory」を実行し、トレーニングデータが入るディレクトリを指定します。
追加学習させる方法④:zipファイルを解凍する
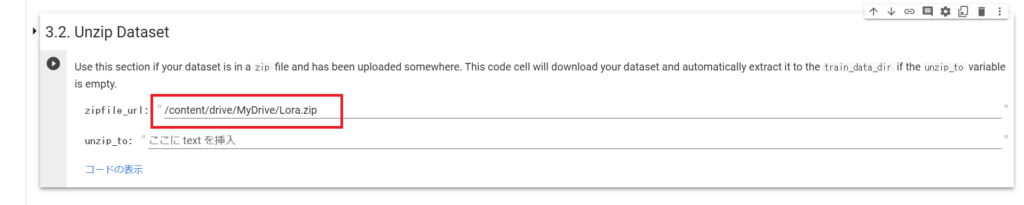
「3.2. Unzip Dataset」で、先程アップロードしたzipファイルを解凍します。
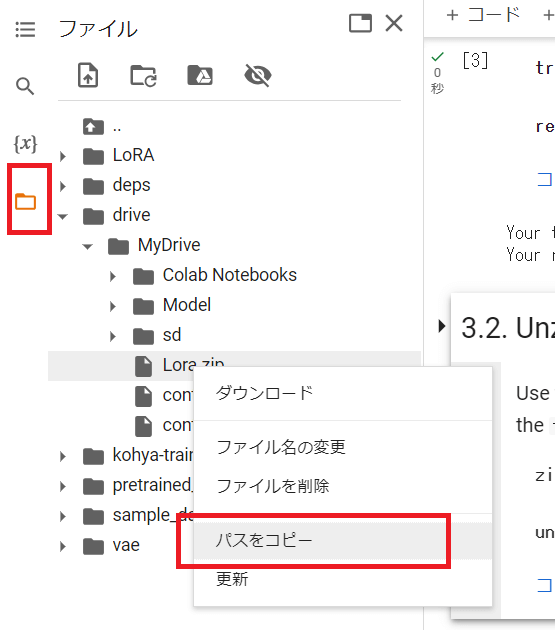
左側のファイルアイコンからzipファイルを探し、右クリックで「パスをコピー」して『zipfile_url』に張り付けてください。
追加学習させる方法⑤:タグを剪定する
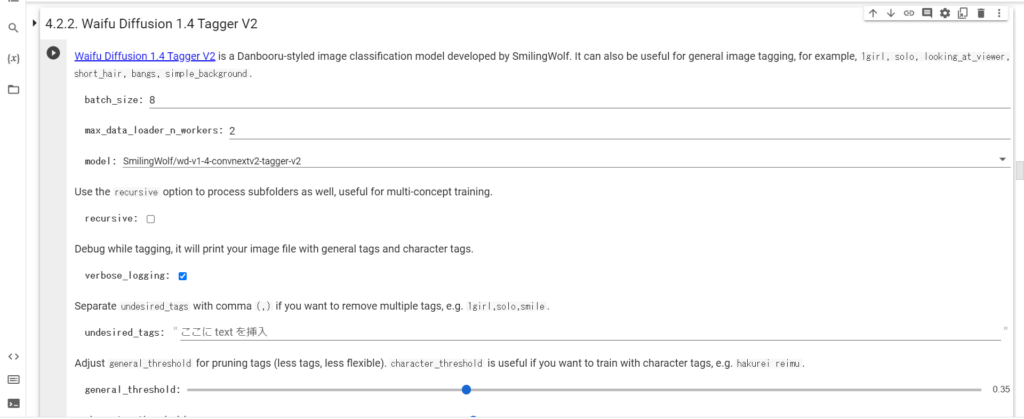
BLIPとWaifu Diffusionの2つがありますが、「Tagger」という機能でタグを整理していきます。
まず、「4.2.2.Waifu Diffusion 1.4 Tagger V2」をそのまま実行します。
それぞれの2次元イラストの説明・キャラクターの特徴・背景に関する英単語が並べられます。
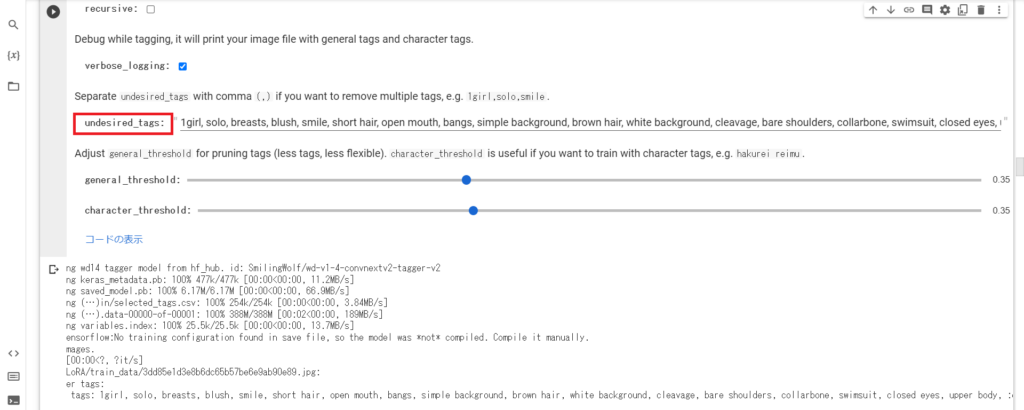
例えば、
1girl, solo, breasts, blush, smile, short hair, open mouth, bangs,…この中から学習させたい部分を「undsired_tags」に加えていきます。
そして、このセクションを再実行するとそれらのタグが削除されます。
「4.2.3. Custom Caption/Tag」の「custom_tag」にキャラクター名などの、トリガーワードになる名前を入れます。

追加学習させる方法⑥:モデルの設定
「5.1. Model Config」の「project_name」に作成する『Lora』の名前を入力してください。これはファイル名になります。
「output_to_drive」にチェックを入れてから、実行します。

「5.2. Dataset Config」「5.3. LoRA and Optimizer Config」もそのまま実行してください。
追加学習させる方法⑦:学習の設定
「5.4. Training Config」をそのまま実行してください。

追加学習させる方法⑧:学習の開始
その前に、サンプル出力のための呪文(プロンプト)を変更しておく必要があります。
「sample_prompt」のリンクをクリックすると、右側にテキストが開くのでお好きな呪文(プロンプト)に書き換えてください。
今回は、以下の呪文(プロンプト)・ネガティブプロンプトを入力します。
masterpiece, best quality, 1 cute girl, kawaii onnanoko, solo, upper body --n lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry --w 512 --h 768 --l 7 --s 28
実行ボタンを押すと、1エポックごとにGoogleドライブの「/LoRA/output/sample/」フォルダに画像が出力されていきます。
これで『Lora』の作成は完了になります!

こんな感じで画像が生成できるようになります!少し難しいですが、1つ1つ丁寧に行えば簡単に追加学習させることができますので、ぜひ試してみてください。
このようにLoRAは比較的少ない労力で高い効果を得られる学習手法であり、Stable Diffusionで自分の理想の画風やキャラクターを生成するための便利なモデルとなっています。
もっと詳しい学習方法については、以下の記事も参考にしてください。

自分の絵をStable Diffusionに学習させる方法
自分が描いた絵やお気に入りの画風をStable Diffusionに学習させる方法は、先ほどのLoRA以外にもいくつかあります。ここでは初心者にもわかりやすく、以下の4つの主な学習方法を紹介します。
- LoRA (Low-Rank Adaptation)
- HyperNetwork
- Textual Inversion / DreamArtist
- Dreambooth
LoRA (Low-Rank Adaptation)
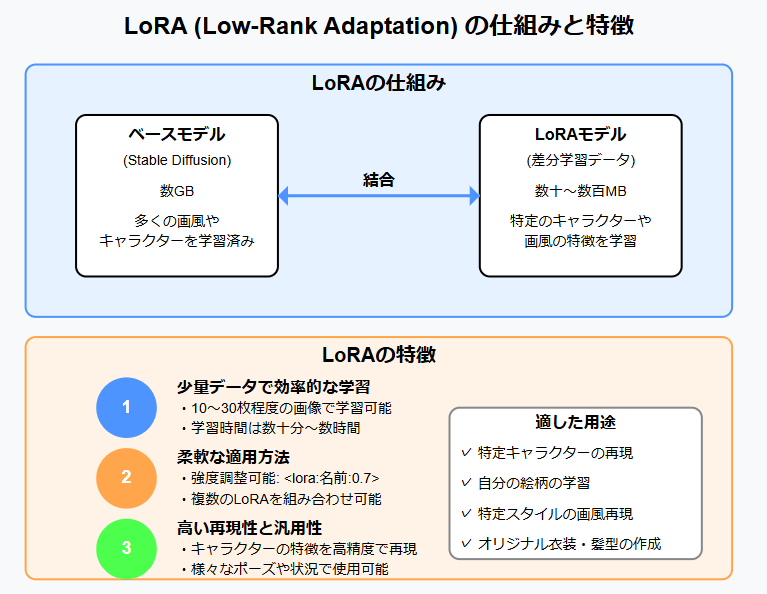
| 特徴 | 少ない画像(10枚程度)から効率的に学習できる、今最も人気の方法 |
| 得意なこと | キャラクターの顔や特徴的な髪型など、特定の要素の再現 |
| ファイルサイズ | 中程度(数十MB〜数百MB) |
| おすすめ度 | ★★★★★ (初心者にも比較的取り組みやすい) |
HyperNetwork
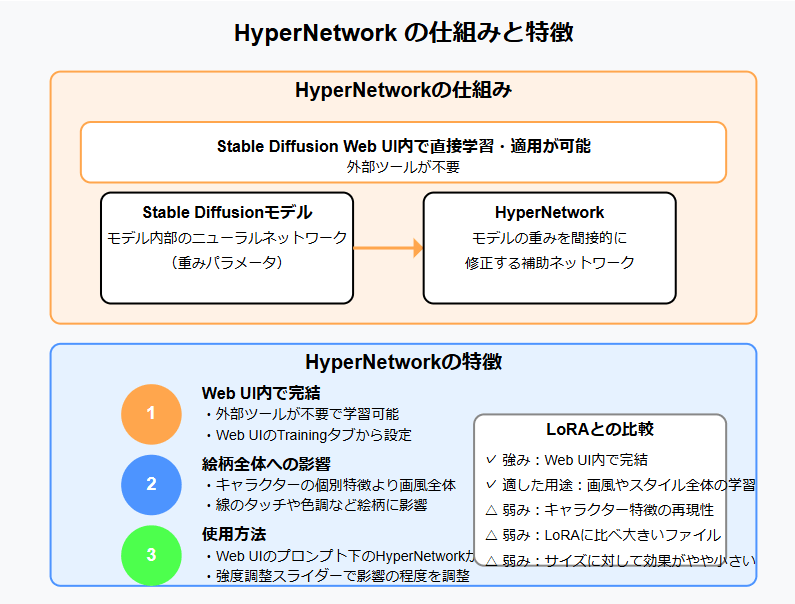
| 特徴 | Stable Diffusion Web UI内で直接学習できる |
| 得意なこと | 全体的な画風に影響を与える |
| ファイルサイズ | やや大きめ |
| おすすめ度 | ★★★☆☆ (Web UI内で完結するのが魅力) |
Textual Inversion / DreamArtist
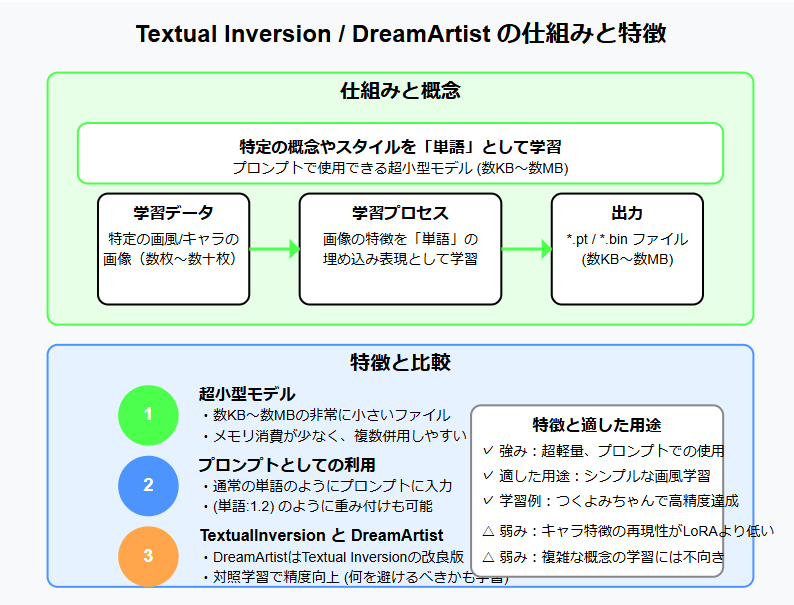
| 特徴 | テキストプロンプトのように使える小さなファイル |
| 得意なこと | シンプルな画風の再現 |
| ファイルサイズ | とても小さい(数KB〜数MB) |
| おすすめ度 | ★★★☆☆ (手軽だが再現度はやや低め) |
Dreambooth
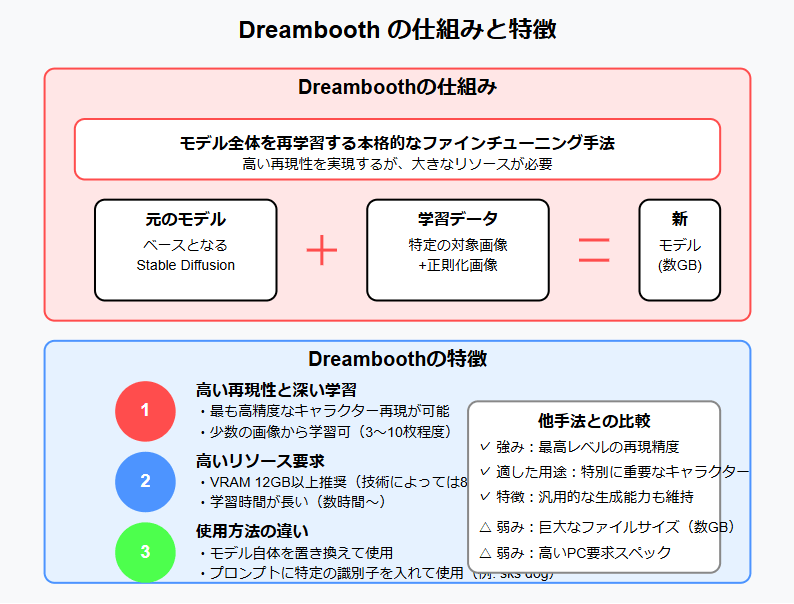
| 特徴 | 高い再現性だが学習に多くのリソースが必要 |
| 得意なこと | キャラクターの細かい特徴まで高精度に再現 |
| ファイルサイズ | 非常に大きい(数GB) |
| おすすめ度 | ★★☆☆☆ (上級者向け、PCのスペックが必要) |
学習に必要なもの
どの手法でも基本的に必要なものは共通しています。
- 学習用の画像: 自分が描いた絵や学習させたい画風の画像(10〜30枚程度)
- 適切なPC環境: できればグラフィックボード(GPU)搭載のPC
- 学習ツール: それぞれの手法に対応したツール(kohya_ssなど)
初心者におすすめの学習の流れ

初めての方は以下の流れで試してみることをおすすめします。
- STEP1まずは既存のLoRAモデルを使ってみる
- Civitaiなどのサイトには多くの無料モデルがあります
- 自分の好みの画風に近いモデルを試して感覚をつかみましょう
- STEP2学習してみたくなったらLoRA学習から始める
- 比較的少ない労力で効果が高いのが特徴です
- 最初は10枚程度の画像から始めてみましょう
- STEP3画像の準備とタグ付けがポイント
- 学習させたい特徴が明確な画像を選びましょう
- シンプルなタグ付けから始めるのがコツです
学習した結果は、自分の絵柄を維持しながらさまざまなポーズやシチュエーションのイラストを生成するのに役立ちます。他の技術(ControlNetなど)と組み合わせることで、より思い通りの画像生成が可能になります。
Stable Diffusionで画風を指定するおすすめのプロンプト・モデル
プロンプトやモデルだけでも、ある程度画風を指定することができます。
アニメ調画風のプロンプト例
アニメ風の画風を出すためのプロンプト例は以下の通りです。
| 呪文(プロンプト) | 意味 |
|---|---|
| flat color | フラットなアニメ塗り |
| anime coloring | アニメ塗り |
| watercolor | 水彩画風 |
| sketch | スケッチ風 |
| pastel color/pastelcolor | パステル調 |
実際のプロンプト例
girl, reading a book, indoor, anime, (flat color:0.8)
画風を固定するためのテンプレート作成方法
気に入った画風をすぐ作成できるように、プロンプトのテンプレートを作成しておくのも良いでしょう。
自分好みの画風テンプレートを作る方法は、以下の通りです。
- 作りたい画風のコンセプトを明確にする
- 基本となるプロンプトを作成
- ネガティブプロンプトも適切に設定
- 生成しながら微調整
例えば「モノクロの濃淡だけで感情を表現する画風」をコンセプトにした場合のプロンプト例と生成画像は、以下の通りです。
An evocative monochrome cityscape, stunning composition of shapes and lines, atmospheric interplay between light and shadow, poetic silhouettes, masterful chiaroscuro technique, rich textures, profound depth, timeless elegance, award-winning black and white photography, 8k resolution

アニメ調に特化したモデル5選!
①Shiitake-Mix: イラスト生成に特化したIllustriousベースのモデル
②MeinaMix: アニメ風イラストが得意
詳しくはこちらをご覧ください。

③: 表現力の高いアニメスタイル
詳しくはこちらをご覧ください。

④Anything: 多様なアニメ表現に対応
詳しくはこちらをご覧ください。

⑤Counterfeit: キャラクターの表情が豊か
詳しくはこちらをご覧ください。

まとめ
いかがでしたでしょうか?Stable Diffusionで画風を固定する方法から、おすすめモデル・学習方法・Seed活用など網羅的に解説してきました!
Stable Diffusionで画風を固定するには、以下の方法が効果的です。
- Seed固定: 構図やキャラクターの基本的な特徴を維持するのに有効
- LoRA学習: 特定のキャラクターや画風を少量の画像から学習できる
- 画風プロンプト: 適切なプロンプトで画風をある程度指定可能
- アニメ調モデル: 特定の画風に特化したモデルを使用
- その他の学習手法: 目的に応じてHyperNetwork、DreamArtistなどを使い分ける
これらの手法を組み合わせることで、Stable Diffusionでより自分好みの画風を安定して生成できるようになります。自分の目的に合わせて、最適な手法を選んでみてくださいね!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

