
2024年10月に突如リリースされたStable Diffusion 3.5。前作のSD3が期待に応えられなかったことから、Stability AIは大幅な改良を加え、コミュニティからのフィードバックを取り入れた最新モデルを発表しました。
本記事では、Stable Diffusion 3.5のローカル環境での使い方から各モデルの特徴、インストール方法、さらには他モデルとの比較まで、あらゆる疑問に答える完全ガイドをお届けします!
この記事では、初心者でも理解できるように段階的に説明していくので、画像生成AIをこれから始めたい方にも、すでに使っていて最新モデルに移行したい方にも役立つ内容となっています。
- Stable Diffusion 3.5とは?
- Stable Diffusion 3.5のローカル環境での導入方法
- Stable Diffusion 3.5の使い方とプロンプトのコツ
- Stable Diffusion 3.5とFLUX.1/SD3との比較
- LoRAとファインチューニングについて
- Stable Diffusion 3.5のライセンスと商用利用
※Stable Diffusionの使い方については、下記記事で詳しく解説しています!

内容をまとめると…
Stable Diffusion 3.5はLarge(80億パラメータ)・Large Turbo(4ステップ高速版)・Medium(26億パラメータ)の3モデル構成
前作SD3の失敗を受けてカスタマイズ性を重視し、改良版MMDiT-Xアーキテクチャでプロンプト忠実度と画質を両立
ローカル導入はComfyUIが最安定で、MediumならVRAM約10GBで動作するが、Largeは24GB以上が必要
年間収益100万ドル未満なら商用利用も無料で、生成画像の著作権はユーザーに帰属する
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Stable Diffusion 3.5とは?

Stable Diffusion 3.5は、Stability AIが2024年10月22日に発表した最新の画像生成AIモデルです。前作のStable Diffusion 3 Mediumで失敗した反省から、カスタマイズ性を重視して開発されました。SD3.5は以下の3つのモデルで構成されています。
①Stable Diffusion 3.5 Large
- パラメータ数: 80億
- 特徴: Stable Diffusionファミリーの中で最強の性能
- 解像度: 1メガピクセル(1024×1024など)対応
- 用途: プロフェッショナルな使用に最適
- 必要VRAM: 24GB以上推奨
このモデルはプロンプト(指示文)への忠実度が非常に高く、細部まで正確に再現します。様々なスタイルの画像生成が可能で、特に複雑な構図や細かいディテールが求められる場合に力を発揮します。
②Stable Diffusion 3.5 Large Turbo
- パラメータ数: 80億
- 特徴: Largeモデルの高速版
- ステップ数: わずか4ステップで高品質な画像生成
- 速度: SD3.5 Largeより大幅に高速
- 必要VRAM: 24GB以上推奨
通常のLargeモデルは20〜30ステップかかる処理をわずか4ステップで実行でき、素早いイテレーションが必要な場面で大きな威力を発揮します。画質やプロンプト忠実度もLargeに近い水準を維持しています。
③Stable Diffusion 3.5 Medium
- パラメータ数: 26億
- 特徴: 改良されたMMDiT-Xアーキテクチャ採用
- 解像度: 0.25〜2メガピクセル対応
- 用途: 一般消費者向けハードウェアでの使用に最適
- 必要VRAM: 9.9GB程度(NVIDIA GeForce RTX 3080以上推奨)
2024年10月29日に後発でリリースされたMediumは、一般的なゲーミングPCでも快適に動作するよう最適化されています。カスタマイズ性と画質のバランスが取れており、効率的な画像生成が可能です。
各モデルの共通点として、前バージョンと比較して大幅な品質向上が見られ、3D、写真、絵画、線画など幅広いスタイルの画像を生成できる柔軟性を備えています。
Stable Diffusion 3.5のローカル環境での導入方法
SD3.5をローカル環境で使うには、いくつかの選択肢があります。ここでは主要な方法を紹介します。
ComfyUIでの導入方法(初心者向け)
ComfyUIは現在SD3.5を使うための最も安定した方法です。以下の手順で導入しましょう。
必要なファイルのダウンロード
- Stability Matrixをダウンロード・インストール
- Stability Matrixの公式サイトからダウンロード
- インストール後、ComfyUIをインストール
- SD3.5モデルファイルのダウンロード
- Hugging Faceにアカウント登録(初回のみ)
- 以下のファイルをダウンロードしましょう。
- SD3.5 Large (16.5GB)
- SD3.5 Large Turbo (16.5GB)
- SD3.5 Medium (5.11GB)
- CLIPファイル(テキストエンコーダー)のダウンロード
- clip_g.safetensors (1.39GB)
- clip_l.safetensors (246MB)
- t5xxl_fp8_e4m3fn.safetensors (4.89GB)
ファイルの配置
- モデルファイルの配置
- Stability Matrix使用時:
StabilityMatrix\Data\Models\StableDiffusionフォルダ - ComfyUI単独使用時:
ComfyUI\models\checkpointsフォルダ
- Stability Matrix使用時:
- CLIPファイルの配置
- Stability Matrix使用時:
StabilityMatrix\Data\Models\CLIPフォルダ - ComfyUI単独使用時:
ComfyUI\models\clipフォルダ
- Stability Matrix使用時:
ワークフローの設定
- ComfyUI_examplesからSD3.5ワークフロー用のサンプル画像をダウンロード

- ComfyUIを起動し、ダウンロードした画像をドラッグ&ドロップしてワークフローをインポート

- 「Load Checkpoint」ノードで使用したいSD3.5モデルを選択
- 「TripleCLIPLoader」ノードで3つのCLIPファイルを選択(clip_g.safetensors、clip_l.safetensors、t5xxl_fp8_e4m3fn.safetensors)
- SD3.5 Large Turboを使用する場合は「KSampler」ノードで、
- stepsを「20」から「4」に変更
- cfgを「5.5」から「1.2」に変更
- Queue Promptボタンをクリックして画像生成開始

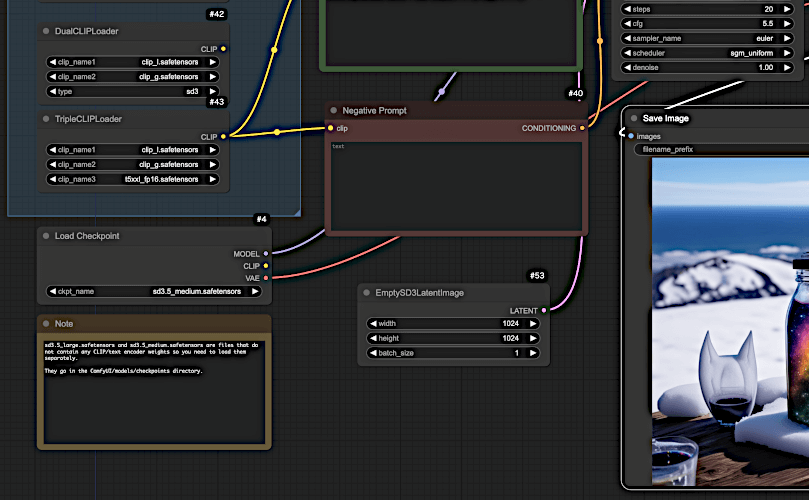
VRAM要件に関して、SD3.5 Mediumは約10GB程度で動作可能ですが、Largeモデルは24GB以上のVRAMを推奨しています。
Stable Diffusion 3.5の使い方とプロンプトのコツ
ここでは、SD3.5の性能を最大限に引き出すためのテクニックを紹介します。
基本的なプロンプト構成
SD3.5は以下の要素を含めることで、より精度の高い画像生成が可能です。
- スタイル指定: 「photorealistic」「oil painting」「3D render」など
- 主題と動作: 被写体とその動きを明確に
- 構図とフレーミング: 「close-up」「wide angle」など視点を指定
- 照明と色彩: 「soft lighting」「vibrant colors」など
- 技術的パラメータ: 「8K resolution」「shallow depth of field」など
※詳しくは、下記記事で解説しています!

ネガティブプロンプト活用法
SD3.5では特に指の表現やテキスト表示に課題があることがわかっています。ですので、以下のようなネガティブプロンプトが効果的です。
bad finger, distorted fingers, extra fingers, nsfw, ugly, normal quality, bad quality, blurry※詳しくは、下記記事で解説しています!

Stable Diffusion 3.5とFLUX.1/SD3との比較
SD3.5は他の主要モデルと比較して、どのような特徴があるのでしょうか?分かりやすく表にまとめてみましたので、参考にしてください!
| SD3.5 Large | FLUX.1 | SD3 | |
|---|---|---|---|
| プロンプト忠実度 | 最もプロンプトに忠実で、 細かい指示も再現 | 独自の解釈をする傾向あり、 芸術性が高い | SD3.5より大幅に劣る |
| 画質と美的センス | 細部の再現性は高いが、 独特の「SD感」がある | 全体的な美的センスと 自然な表現力が最も高い | 人物表現に大きな課題あり |
| 処理速度 | 4ステップという超速生成を実現 | 標準的な速度 | 比較的時間がかかる |
| 特殊な能力 | 多様な人種表現、テキスト表示の改善 | 芸術性の高い表現、独自の解釈力 | (特筆すべき強みなし) |
LoRAとファインチューニングについて
SD3.5ではLoRA対応が進んでおり、世界的に有名なKohya氏がLoRA学習スクリプト「sd-scripts」をSD3.5対応に更新しています。
LoRAの学習方法は、以下の通りです。
- Kohya_ssの最新版をダウンロード
- SD3.5対応設定でLoRA学習を実行
- 生成したLoRAファイルをComfyUIで使用
※詳しい作成方法については、下記記事で解説していますので参考にしてください!

そして、SD3.5はカスタマイズ性を高めるためにQuery-Key Normalizationをトランスフォーマーブロックに統合し、モデルのトレーニングプロセスを改善しています。これにより個人でもより簡単にファインチューニングが可能になりました。
Stable Diffusion 3.5のライセンスと商用利用
SD3.5は「Stability AI Community License」の下で提供されており、以下のルールが適用されます。
- 非営利目的: 個人・組織とも無料で使用可能
- 商用利用: 年間収益100万ドル未満の企業・クリエイターは無料
- 著作権: 生成した画像の著作権はユーザーに帰属
- 大企業向け: 年間収益100万ドル以上の企業はエンタープライズライセンスが必要
まとめ
いかがでしたでしょうか?
Stable Diffusion 3.5のローカル環境での使い方から各モデルの特徴、インストール方法、さらには他モデルとの比較まで詳しく解説してきました。
この記事で紹介したことをまとめると次のようになります。
- SD3.5は3種類のモデル(Large、Large Turbo、Medium)があり、それぞれ特徴が異なる
- ローカル環境での利用にはComfyUIが最も安定している
- SD3.5 Mediumは一般的なGPU(VRAM 10GB程度)でも動作可能
- プロンプト忠実度は高いが、指の表現などに課題がある
- 年間収益100万ドル未満なら商用利用も無料で可能
画像生成AIの導入を検討している方や、より高品質な画像を生成したいという方に、かなり役立つ情報だったのではないでしょうか?
ぜひ、SD3.5を使って画像を生成してみてください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

