

生成AIの進歩は止まることを知りません。
キャラクターの同一性を保ったまま複数枚の画像を生成するAIジェネレーターが公開されました。
これをうまく使うことで、ストーリー性のある漫画を作る事が可能になります。
その名は「StoryDiffusion」
一体どんな生成AIなのでしょうか?
内容をまとめると…
StoryDiffusionはキャラクターの同一性を保ったまま複数枚の画像を一度に生成できる無料のAIジェネレーター
参照画像を読み込ませることでキャラクターの再現性が大幅に向上し、ストーリー性のある漫画制作が可能
日本語アニメ風やディズニー風など7種類のスタイルテンプレートが用意されている
Google ColabまたはHugging FaceのDemo版から誰でもすぐに試せる
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

StoryDiffusionとは?
キャラクターやストーリーの一貫性を保った状態で、10秒以上の動画を生成することのできる無料のAI動画ジェネレーターです。
まだ登場したての最新の技術の為、現在公開されている部分は動画生成に使用する複数枚の統一性を持った画像を生成する(Comic Generation)機能のみとなっています。
おそらく今後、画像を繋げて動画として生成する機能もリリースされる事と思います。
人物の画像を参照して再現性を高める機能を有しておりAI動画生成の主流となる可能性を持った技術ですので、まずは公開されている(Comic Generation)機能をしっかりと確認しておきましょう。
【StoryDiffusion】の詳細はこちらの公式ページよりご確認ください。

こちらには画像以外に動画のサンプルも多数掲載されていますので、気になる方は是非チェックしてみてください。
StoryDiffusionの使い方
誰もが無料で使えるAI動画ジェネレーター「StoryDiffusion」
公式ページは今の所日本語への対応はなされていません。
これから使い方を説明していきますが英語に特に抵抗が無く、手っ取り早く触ってみたい方はStoryDiffusionが公式にComic Generation Demoを公開しています。
ここで使ってみるのが一番簡単です。
AI動画作成にはある程度性能の高いPCが必要となります。
いつの間にやらColabでNVIDIA製GPU A100が使えるようになっていました。
これによりAI画像生成では使いづらく敬遠されていたGoogle Colabが再び復権するかもしれません。
今後動画作成機能がリリースされた際にはPC環境によってはColabを使わざるを得ない方もいると思いますので、Colabを使う形で現在公開されている(Comic Generation)を起動して、実際に使用しながら使い方を解説していきます。
Demo版も同じ用に使えますので、そちらを使用する場合は”④サンプルを使ってみる”までジャンプして構いません。
①Google Colabでノートブックを作成する
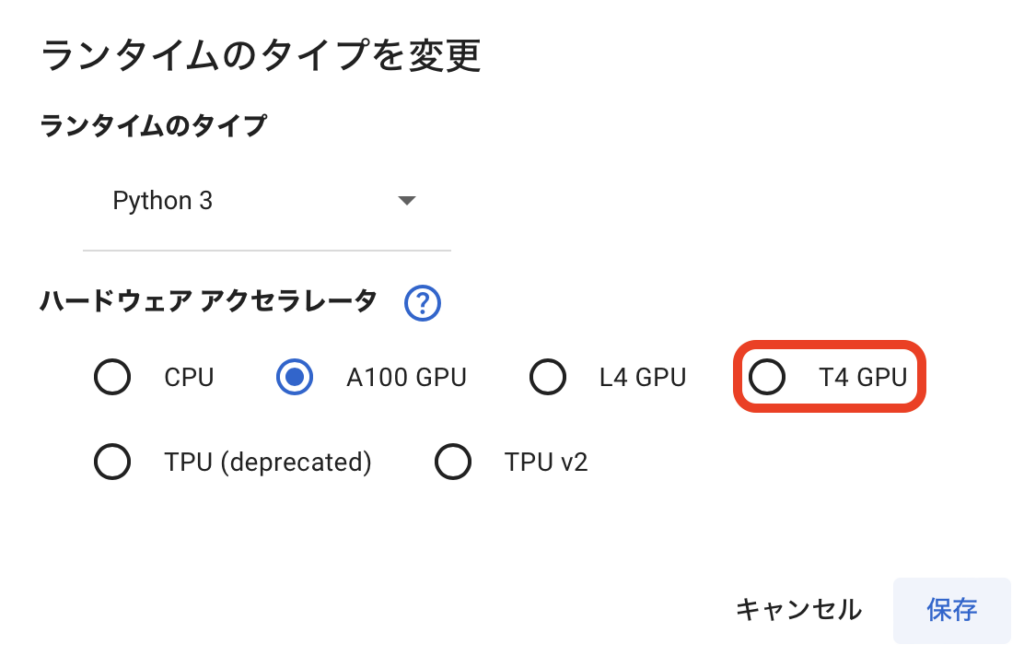
Colabでノートブックを新規作成してランタイムのタイプを「Python 3」、ハードウェアアクセラレータを「T4 GPU」に変更します。(私はコンピューティングユニットが余っているのでA100使っちゃいますが画像の生成はT4で十分動きます)
Google ColabをAI画像生成で使用する際は基本的に課金して使用しなくてはいけません。
無料の生成AIを使うのにGoogle Colabに課金するのはちょっと癪に障ります。
しかしながら今後AI動画生成の時代に突入すると、おそらくA100が必須となってしまうでしょう。
動画の生成には莫大な計算能力が必要なので致し方ない部分ではあります。
しかしながらA100を自分で用意する事は多くの人にとってとてもハードルが高いです。
ですので、ユーザーが高性能のGPUを使える環境の整備がAI動画生成の隆盛に大きく関わってくると個人的に感じています。
はい、話が外れてしまいました。
本題を続けましょう。
②インストールコマンドを実行する
以下のコードを貼り付けてrunしてください。
%cd /content
!git clone -b dev https://github.com/camenduru/StoryDiffusion-hf
%cd /content/StoryDiffusion-hf
!pip install -q xformers==0.0.25 diffusers==0.25.0 accelerate omegaconf peft gradio
!python app.py環境構築が開始されます。
完了まで数分かかりますのでしばらくお待ちください。
③1番下のURLをクリックしてStoryDiffusionを立ち上げる
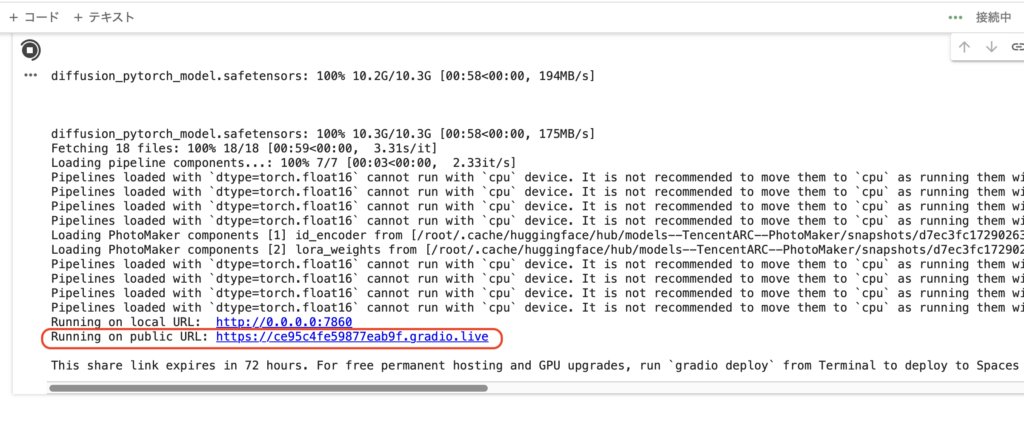
数分待っていると、
Running on public URL:〜 と表示がされますので、そのアドレスからStoryDiffusionの操作画面にジャンプしてください。
特にエラーが起きなければ、
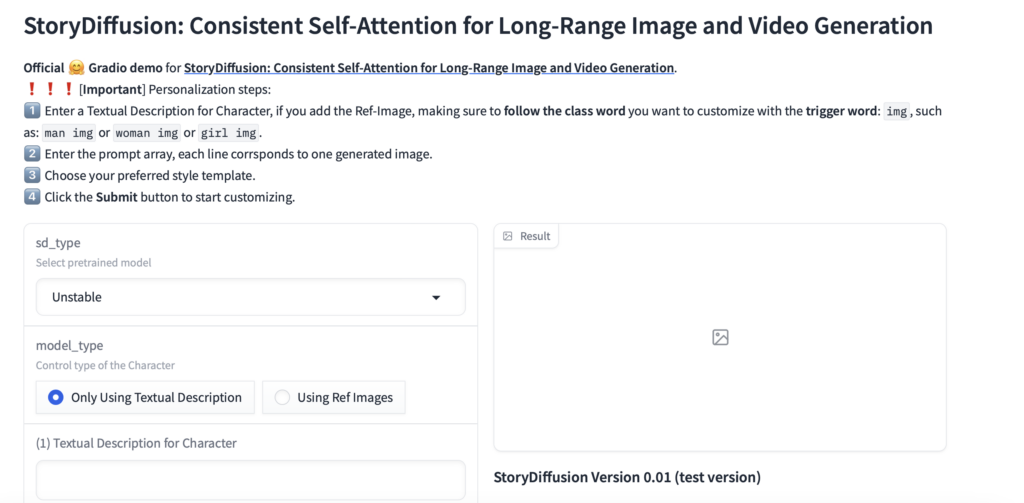
この操作画面に辿り着くはずです。
④サンプルを使ってみる
では操作方法を説明していきますが、とりあえず操作画面下部にサンプルが置いてありますので、それを一度動かしてみるのが感覚的にわかりやすいでしょう。
いくつかサンプルがあるので一つ選択すると、自動的に各パラメーターが入力されます。

上から2つ目の「白いTシャツを着ている、ルーズな青髪の女性」を選択してGenerate!してみます。
しばらくすると、
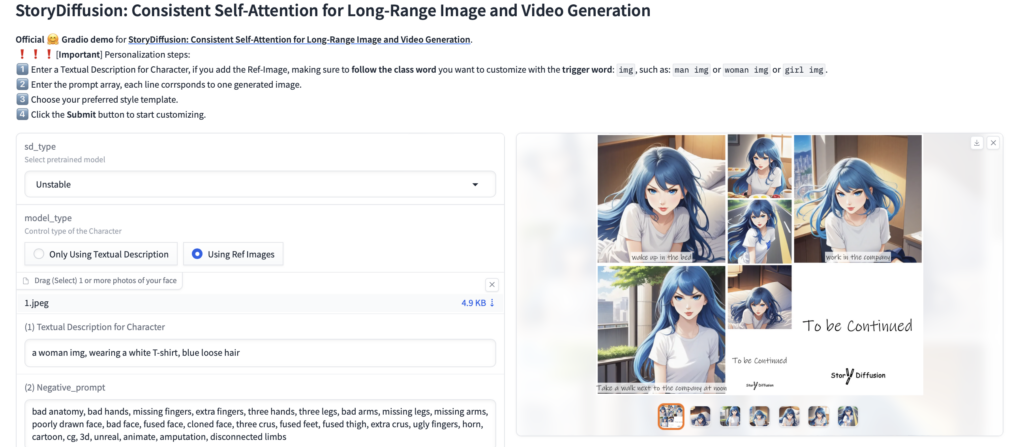
このように動画の元となる複数枚の画像を生成してくれます。
今後はこの画像の間を補完するような形で動画ジェネレーターを動かすのであろうと思われるのですがその前に、
このように複数枚の画像を生成してキャラクターの再現を保つ事は、今まではかなり難しい事でした。
それこそわざわざloraやembeddingなどのデーターを使用してかなり多めに生成して、そこから使える画像を選んでいく事が普通でした。
それが1発で生成できているのでどうなっているのかとても気になる所です。
各パラメーターがどうなっているのか詳しくみていきましょう。
⑤StoryDiffusionの各パラメータについて
① sd_type
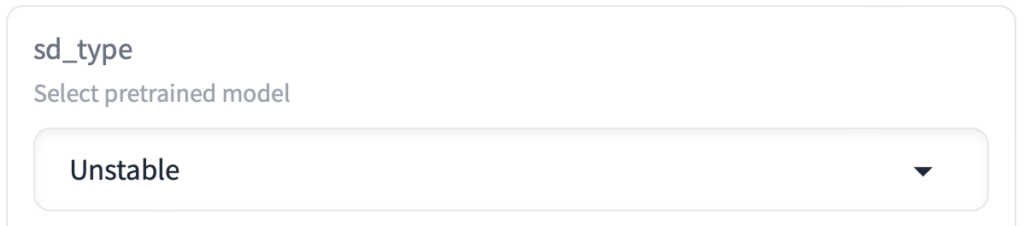
生成する画像のタイプを指定します。
RealVision は実写系 Unstableはイラスト系の画像を生成する事ができます。
② model_type
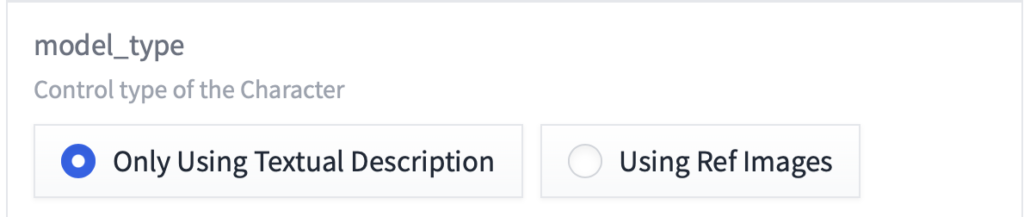
ストリーのメインとなるキャラクターの仕様を決めます。
Only Using Textual Description はテキストプロンプトのみを使用します。
Using Ref Images はテキストプロンプトと参照画像を併用します。
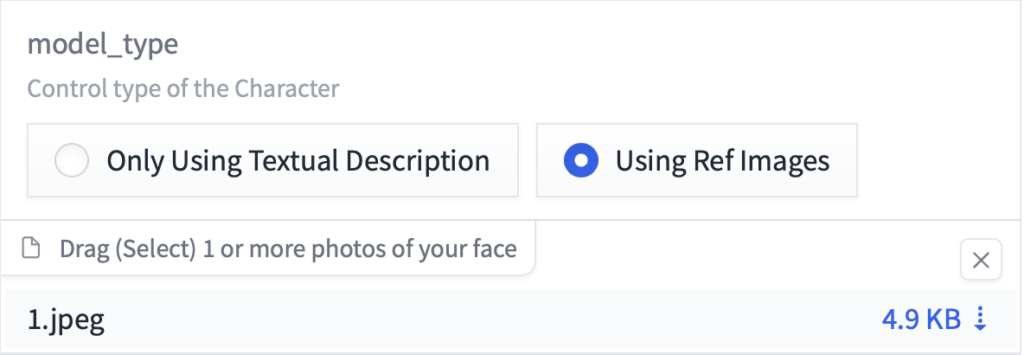
Drag(Select)1 or more photos of your face のエリアに画像をドロップして参照画像として使用する事が可能です。
ちなみに先ほどのサンプル作成ではこんな画像が仕込まれていました。

これによってキャラクターの再現性を高めることができるのですね。
とっても使える技術です。
素晴らしい!
③Textual Description for Character

メインとなるキャラクターの特徴をテキストで入力します。
サンプルは「白いTシャツを着たルーズな青髪の女性」となっています。
また、② model_typeで参照画像を使用する場合は「a woman img」のようにテキストと参照画像を結びつけるトリガーワードを使用することが推奨されていますので、少しだけ注意が必要です。
④Negative_prompt

ネガティブプロンプトとして描いて欲しくない物の情報をテキストで入力します。
サンプルで大体必要なものは書いてくれていますので、自分の制作時も基本このまま使えます。
⑤Style template

生成される画像のスタイルを決定します。
選択できるスタイルは
・(No style)
・Japanese Anime
・Cinematic
・Disney Charactor
・Photographic
・Comic book
・Line art
となっています。
色々なスタイルの画像を生成する事が可能です。
⑥Comic Description (each line corresponds to a frame)
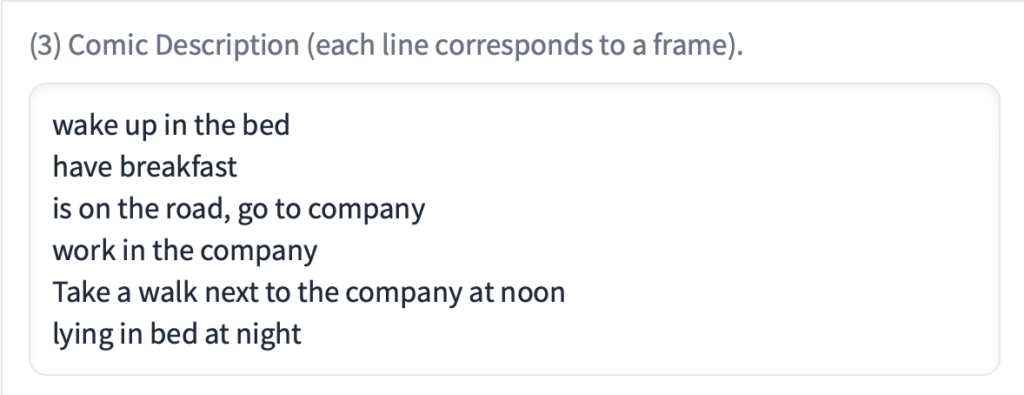
ストーリーをテキストで指定します。
サンプルを例にすると、
wake up in the bed – ベッドで目覚め
have breakfast – 朝食を摂り
is on the road, go to company – 道路の上、会社に向かっている
work in the company – 会社で勤務
Take a walk next to the company at noon – 正午に会社の隣を散歩する
lying in bed at night – 夜にベッドに横たわっている
このようなストーリーをもとに画像を生成してくれます。
また1列毎に1枚の画像のストーリーとなっていますので、ここの列数が最終的な画像の枚数となります。
⑥Tune the hyperparameters
細かいパラメーターの調整部分です。
サンプリングステップ数や画像サイズなど色々と変更する事が可能です。
項目数は多いですが特に変更しなくても画像が生成できます。
いじくりたい場合はご自身で色々と変更してみて使いながら調整していってください。
StoryDiffusionで物語を作ってみる
では大体の仕様を理解出来たところで、オリジナルを作成してみましょう。
皆さんも自由にキャラクターや物語を設定して実際に生成してみてください。
先ほどの説明の通り model_typeをUsing Ref Images にして参照画像を使うことでキャラクターの再現性を高める事が出来ますので、任意の画像を使ってみると良いでしょう。
私も4コマ漫画風で作品を作ってみました。(Style templateはDisney Charactorを使用しました)

「おーいみんなー、これからとっても大事な話をするぞー」
「ぜったいにやってはいけない事があるよ。それは」

「知らない人の前でパンツを脱ぐ事!」
「大人になってこれをやっちゃうと・・・」

「牢屋に入ることになるよ!牢屋に入れば自由な生活は送れない・・・」
「でももしそうなっても安心して!」

「美味しいチーズが毎日食べられるよ!」
こんなオチで若干の申し訳なさを感じつつ(汗っっ・・・)、補足説明をさせていただきますと、表情差分があまり得意ではないようで(参照画像に引っ張られる)、複数回Comic Description (each line corresponds to a frame)を色々と変更しながら画像を生成し、いい画像を選んで物語は後で付けました。
ただキャラクター自体の再現性はとても高いので、ストーリーのある漫画を作成する事は難しくはありません。
パラメーター部分も色々と調整可能ですので、皆さんも色々なストーリー性のある漫画を生成してみてください。
また実写風画像の生成も可能ですので、友達や家族の画像を元にしてちょっとした悪戯をしてみるのも面白いかもしれませんね。(でもちゃんと手加減を考えてやりましょうね)
まとめ
いかがでしたでしょうか?
【StoryDiffusion】ストーリー性のある漫画を簡単に生成する方法!について解説してきました。
今回のポイントをまとめると、以下のようになります。
- StoryDiffusionは10秒以上の動画を生成することのできる無料のAIジェネレーターです。
- 現在公開されている部分は動画生成に使用する複数枚の統一性を持った画像を生成する(Comic Generation)機能のみです。
- 参照画像を仕様する事で、キャラクターの再現性を高める事ができ、ストーリー性のある漫画を容易に作成する事が出来ます。
今後画像から動画を制作するフェーズになった時にどのような仕様になるかは今の所不明です。
それまでの間に画像生成部分についてもバージョンアップされていく事と思います。
動画作成機能のリリースがとても待ち遠しく感じますが、それまでの間にComic Generation機能をしっかりと使いこなせるようにしておきたいものです。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

