
「もっと高品質なアニメ生成モデルがあったらいいな…」
「Animagine XLの最新版が出たって聞いたけど、3.0?それとも3.1?」
このような疑問や希望をお持ちの方は、ぜひこの記事を最後までお読みください!
この記事では、「Animagine XL 3.0」と「Animagine XL 3.1」について、使い方から画像のクオリティの違いに至るまで詳しく解説しています。
最後まで読んで、あなたのクリエイティブな活動に少しでも役立てば幸いです!
内容をまとめると…
Animagine XL 3.0はSDXLベースのアニメ特化モデルで、手の描写改善やアニメ概念の深い理解が特徴
最新版の3.1では新たにAesthetic Tagsや年代タグが追加され、画像の再現性とクオリティが大幅に向上している
プロンプトは「性別→キャラクター名→作品名→その他」の順で書くと効果的
Fair AI Public License 1.0-SDのもとで商用利用が可能だが、改変時はライセンス継承が必要
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Animagine XL 3.0とは?
Animagine XL 3.0は、前作のAnimagine XL 2.0をベースにCagliostro Research Labによって開発された最新のオープンソースのアニメテキスト・ツー・イメージモデルです。
このAnimagine XL 3.0バージョンは、安定した拡散XL(Stable Diffusion XL)を基にしており、手の解剖学的な改善、効率的なタグ順序付け、アニメ概念に関する知識が強化されています。
前のAnimagine XL 2.0バージョンとは異なり、Animagine XL 3.0は美的なものではなく、コンセプトの学習に重点を置いています!
主な特徴
- 高品質なアニメ画像生成:テキストプロンプトから高品質のアニメ画像を生成するために設計されてる。
- 強化された手の解剖学:以前のバージョンよりも手の解剖学が改善されており、よりリアルで正確な描写が可能。
- 深い概念理解:アニメの概念を深く理解し、それに基づいた画像生成が行える。
- 迅速なプロンプト解釈:入力されたテキストプロンプトを迅速かつ正確に解釈し、意図した通りの画像を生成。
※Animagine XL 2.0については、以下の記事で解説しています。

現在は『Animagine XL 3.1』が公開済み!
Animagine XL 3.1は、前モデルのAnimagine XL 3.0をさらに進化させたアップデート版です。
この最新バージョンAnimagine XL 3.1は、より広範なアニメシリーズのキャラクターを含む最適化されたデータセットと新しい美的タグを採用し、アニメスタイルの画像生成を高品質に行うことができます。
Stable Diffusion XLを基盤とし、アニメファン、アーティスト、コンテンツクリエーターにとって価値あるリソースを提供することを目的として開発されました!
主な特徴
- 広範囲のキャラクター:より多くの有名アニメシリーズからのキャラクターが含まれている。
- 最適化されたデータセット:より高品質な画像生成のために、データセットが精密に最適化。
- 新しい美的タグ:画像生成の質を向上させるための新しいタグが導入。
- 進化した手の解剖学とコンセプト理解:以前のモデルよりも手の解剖学が向上し、コンセプトの理解が深い。
Animagine XL 3.0の使い方
Animagine XL 3.0の使い方は以下の2通りです!
- Gradioのデモ版で使用する
- 独自の環境で使用する
今回は、2の独自の環境で使用する方法を解説します。
1. ライブラリをインストールする
下記のコードを実行しライブラリをインストールします。
!pip install -q --upgrade diffusers invisible_watermark transformers accelerate safetensors2. モデルのダウンロード
次に、以下のコードを実行して、モデルのロード等を行いましょう。
import torch
from torch import autocast
from diffusers import StableDiffusionXLPipeline, EulerAncestralDiscreteScheduler
model = "linaqruf/animagine-xl"
pipe = StableDiffusionXLPipeline.from_pretrained(
model,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
pipe.to('cuda')3. 画像を生成する
最後に、以下のコードを実行することで、画像を生成します。
import matplotlib.pyplot as plt
from PIL import Image
prompt = "1girl, arima kana, oshi no ko, solo, upper body, v, smile, looking at viewer, outdoors, night"
negative_prompt = "nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name"
output = "/content/anime_girl.png"
image = pipe(
prompt,
negative_prompt=negative_prompt,
width=832,
height=1216,
guidance_scale=12,
num_inference_steps=28
).images[0]
image.save(output)
image = Image.open(output)
plt.imshow(image)
plt.axis('off') # to hide the axis生成された画像

1boy/1girl, what character, from which series, everything else in random order*性別、キャラクターでどのアニメシリーズかを述べた後、その他の詳細をランダムに追加します。
一般的にStable Diffusionを使用する際は、画質を指定するプロンプトを先に書くことが多いですが、Animagine XL 3.0ではキャラクター関連の要素を先に配置することで、より効果的な画像生成が可能です。
Animagine XL 3.0を使うにあたって必要なスペック
Animagine XL 3.0を使うにあたって必要なスペックは以下の通りです。
Pythonのバージョン
- Python 3.8以上
必要なパッケージ
- diffusers
- invisible_watermark
- transformers
- accelerate
- safetensors
Animagine XL 3.1との生成画像の違い
Animagine XL 3.1は、前モデルAnimagine XL 3.0に基づいてファインチューニングされ、特にアニメスタイルの画像生成能力が向上しています。
Animagine XL 3.1バージョンでは、より広範なアニメキャラクターがデータセットに追加され、最適化されたタグが新たに導入されています。
これから紹介する3つの点により、アニメファンやクリエイターにとってさらに魅力的なツールとなっています。
1. Aesthetic Tags
Animagine XL 3.1では、クオリティタグや年代タグが更新され、「Aesthetic Tags」が新たに加わりました。これにより、より精密な画質管理が可能となっています。
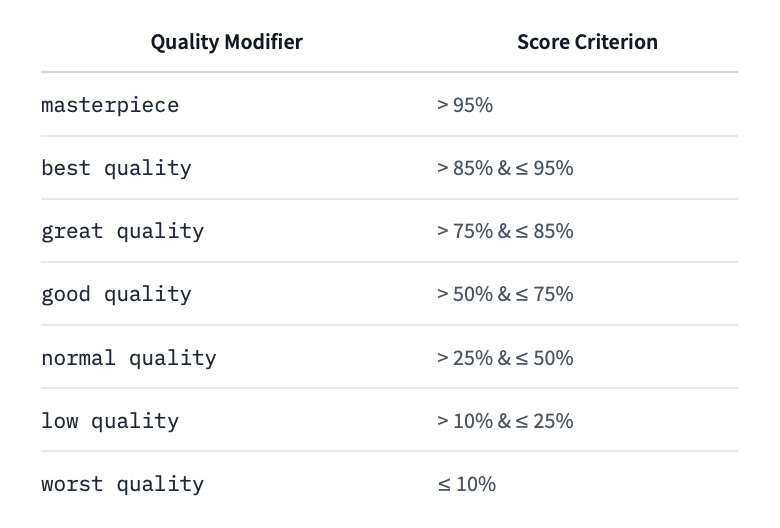
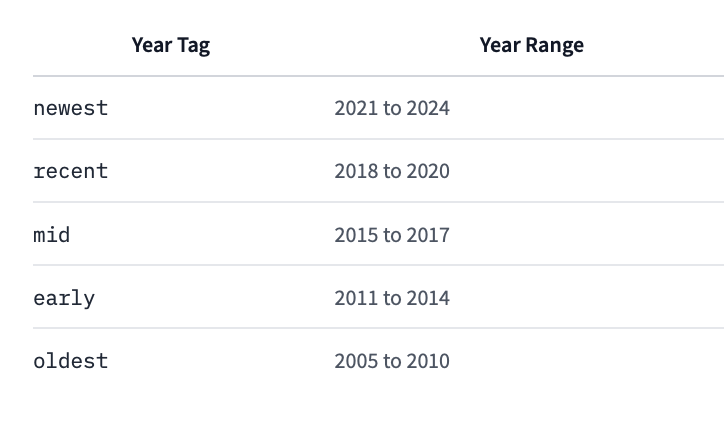
2. 年代タグの調整
年代ごとのタグが細かく調整され、「2024」が新たに追加され、「late」は「recent」に変更されました。これにより、特定の時代のアニメアートスタイルをより正確に反映できます。
3. 画像のクオリティ
Animagine XL 3.1では、目の形状や頬の色がやや抑えられ、露出度が低減されています。キャラクターの表現がより落ち着いた印象を与えます。
線が細く、はっきりとしており、厚塗りや立体感が減少し、平面的な印象が強まっています。
それでは、実際にバージョン別に画像を作成して比較してみましょう!
プロンプトは全く同じものを使用しています。
比較画像① 左:Animagine XL3.0 右:Animagine XL3.1


プロンプト
1boy, male focus, ikari shinji, neon genesis evangelion, solo, holding mug, sitting, on chair, holding, serious face, looking at viewer, indoors, upper body, cinematic angle,, (masterpiece), (best quality), (ultra-detailed), very aesthetic, illustration, disheveled hair, perfect composition, moist skin, intricate details,ネガティブプロンプト
nsfw, longbody, lowres, bad anatomy, bad hands, missing fingers, pubic hair, extra digit, fewer digits, cropped, worst quality, low quality, very displeasing比較画像② 左:Animagine XL3.0 右:Animagine XL3.1


プロンプト
1girl, souryuu asuka langley, neon genesis evangelion, rebuild of evangelion, lance of longinus, cat hat, plugsuit, pilot suit, red bodysuit, sitting, crossed legs, black eye patch, throne, looking down, from bottom, looking at viewer, outdoors, masterpiece, best quality, very aesthetic, absurdresネガティブプロンプト
wings, nsfw, low quality, worst quality, normal quality,一目でわかる通り、圧倒的にAnimagine XL3.1が画像の再現性が高いです!
Animagine XL 3.0の商用利用の可否
Animagine XL 3.0は、Cagliostro Research Labによって開発された生成モデルであり、その使用にはいくつかのライセンス条件が適用されます。
Animagine XL 3.0モデルは、特にアニメ画像の生成に特化しており、広範囲の商用および非商用のアプリケーションで利用が可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ○ |
| 改変 | ○ |
| 配布 | ○ |
| 特許使用 | ○ |
| 私的利用 | ○ |
商用利用のガイドラインについて
オープンソースライセンスについて
Animagine XL 3.0は、「Fair AI Public License 1.0-SD」のもとで公開されています。このライセンスは、モデルを商用で利用する際にも、一定の条件の下で自由に使用することを許可しています。
改変と共有について
モデルを改変した場合、その変更を元のライセンスと共に共有する必要があります。これは、改良やカスタマイズを行った際に、コミュニティとその成果を共有することを奨励するためです。
ソースコードのアクセシビリティについて
改変したモデルがネットワーク経由でアクセス可能な場合、他者がソースコードを入手できるようにする必要があります。
配布の条件について
どのような形態であれ、配布されるすべての製品は、このライセンスまたは類似のルールを持つ他のライセンスの下で行う必要があります。
※もっと詳細を知りたい方は下記をご覧ください!

まとめ
いかがでしたでしょうか?
Animagine XL 3.0(3.1)の使い方について解説してきました。
今回のポイントをまとめると、以下のようになります。
- Animagine XL 3.0は、前作から技術的に進化し、より精緻なアニメ画像を生成します。
- Animagine XL 3.0は、GradioやGoogle Colabを通じて手軽に利用可能です。
- 商用利用は、「Fair AI Public License 1.0-SD」に基づき、改変後は共有が必要です。
Animagine XL 3.0(3.1)を使うことでより高品質なアニメ画像を再現性高く作成することができます。
この記事が少しでもみなさんのアニメ画像生成の一助になれば幸いです。
また、生成AIに関する更なる情報は、他の記事にて詳細に解説していますので、そちらの内容もぜひ確認してみてください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

