
Stable Diffusionで画像を生成していると、初めて聞く言葉にしばしば遭遇します。
モデルとかLoraとかhypernetworksとか・・・・
EasyNegativeを使う時に「Textual Inversion」って書いてありますが、いったい何なのでしょうか?
今回はそんな「Textual Inversion」のお話です。
内容をまとめると…
Textual Inversionは特定の視覚的コンセプトを調整できる学習手法で、生成した学習データは「embedding」と呼ばれる
テキストエンコーダー部分で作用するためファイルサイズが小さいが、モデル自体の学習が弱い部分の再現は苦手
Stable Diffusion標準搭載の「train」機能を使えば、数枚の画像からembeddingを自作できる
自作が大変な場合はCIVITAIで配布されているembeddingをダウンロードして使うのもおすすめ
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

「Textual Inversion」とは?
特定の視覚的なコンセプトを調整できる画像生成お助けツールです。
生成画像のクオリティーを高めてくれるEasyNegativやLoraと同じように特定のキャラクターや画風に寄せるものがあります。
「Textual Inversion」は日本語では「テキスト反転」と訳されている通り、テキストエンコーダー部分で特定のベクトルを与えるように作用しています。
そのためファイルサイズは小さいですが、モデル自体の学習が弱い部分については再現が苦手です。
「Textual Inversion」と「embedding」どっちで呼ぶか問題があります(笑)
「Textual Inversion」= 作り方(製造方法)
「embedding」= 「Textual Inversion」の手法で製造した学習データ
のような認識でいいかと思いますので、正直どっちで呼んでも意味が通じれば良しです。
Githubに「Textual Inversion」について詳しく書かれているものがりますので、詳しく知りたい方はこちらを参考にしてください。
参考:https://textual-inversion.github.io
「Textual Inversion」の作り方
拡張機能を使う方法もありますが、今回はStable Diffusionに標準搭載されている機能「train」を使って「Textual Inversion」の手法で「embedding」を作っってみます。
「embedding」の枠を作る
「train」のタグを開き「Create embedding」の「Name」欄に embeddingの名前、initialization に特徴として指定したい要素を書き込みます。
「Number of vectors per token」はトークンのサイズです。今回は「3」にします。
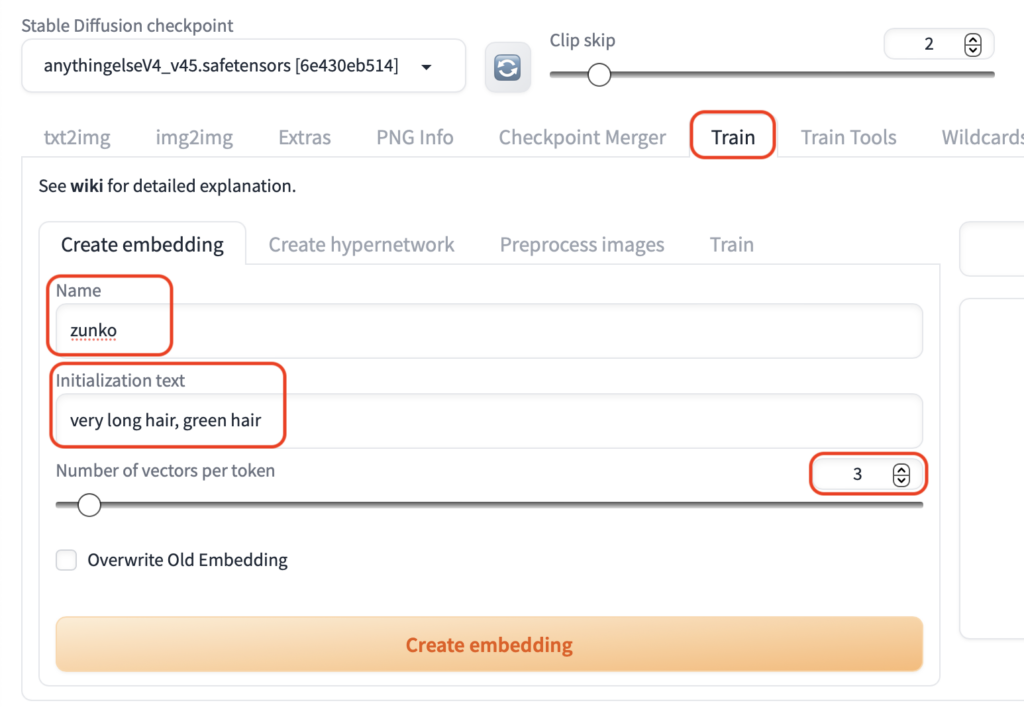
下の「Create embedding」を押すと「embedding」の枠がstable-diffusion-webui/embeddings内に作成されます。
画像とテキストファイルを用意する
画像は縦横が同じサイズでなくてはいけません。今回は512 x 512 に加工した以下の3枚の画像を使用します。



東北ずんこさんです。
テキストファイルの名前は画像と同じ名前で拡張子だけ .txt として、中身は学習して欲しい要素は書きません。

このような感じでテキストも3枚分用意します。
画像3枚とテキストファイル3つを一つのフォルダにまとめて入れてください。
Trainする
「Train」のタグを開きパラメーターを設定していきます。
Embeddingに先ほど作成したzunkoを選択
Embedding Learning rateは学習速度です。今回0.0003にしました。
Dataset directoryに用意した画像とテキストを入れたファイルのパスを記入
Prompt templateは人や物を学習させたいときは subject.txt を使います。
Max stepsはとりあえず5000にします。途中で中断したり、追加でtrainすることもできるので、今回はこのくらいにします。
Choose latent sampling methodにdeterministicを使ってみます。これは潜在空間の平均からサンプリングする方法だそうで、使うのは初めてです。
-904x1024.png)
設定したら Train Enbeddingを押すとtrainが始まります。
環境によってはかなり時間がかかるので、夜中寝ている間にtrainする方が良いかもしれません。
「Created: stable-diffusion-webui/embeddings/zunko.pt」このコメントが出たらtrain終了です。
txt2timgで画像を生成してみましょう。
画像を生成してみる
作成したEnbeddingを使って生成した画像がこちらです。



ずんこ自体は特徴が出ていますが、若干プロンプトが効きにくいです。プロンプトに書いた(woman walking in the forest)があまり表現されません。
CFG Scaleを少し下げてみると少しマシになりました。



ずんこの特徴である緑の髪色や黄色がかった目もプロンプト無しで再現できているのでまずまずの出来です。
おすすめの「Textual Inversion」!
「Textual Inversion」は自分で作ることもできますが、結構時間がかかります。
現在多くの効果的な「Textual Inversion」がCIVITAIにアップされていますので、時間が取れない方はこちらの記事を参考にしてお好みの物を探すのも良いでしょう。

まとめ
いかがでしたでしょうか?
Stable Diffusionの『Textual Inversion』とは?おすすめや作り方を紹介!について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 『Textual Inversion』はテキストエンコーダー部分で働く特定の視覚的なコンセプトを調整できる画像生成お助けツール
- 「train」を使って自分で作ることも可能
- すぐ使いたい方はCIVITAIからダウンロードする
今回の「embedding」作成、画像を3枚しか用意していません。
パラメーターの調整で数回trainしていますが、それでこれだけ再現できるのはすごいですよね。
皆さんもこの記事を参考に、ぜひご自身で「embedding」を作成してみてください。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

