
Stable Diffusionを提供しているStability AI社が、11月21日にテキストや画像から動画を生成するAIモデル「Stable Video Diffusion」のリサーチプレビュー版をリリースしたと発表しました。
一体どのような機能なのか詳しいことが気になる方も多いのではないでしょうか?
そんな方のために、『Stable Video Diffusion』の概要・使い方を徹底解説していきます!
内容をまとめると…
Stable Video DiffusionはStability AI社が公開した、画像やテキストから動画を生成できるAIモデル
14フレームと25フレームの2種類の動画生成に対応し、フレーム数が多いほど滑らかな動画になる
Google Colabのノートブックを使えば画像から動画への変換を試すことができるが、商用利用は不可
花火やキラキラした表現が得意で、人物描写はまだ改善の余地がある段階
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

『Stable Video Diffusion』とは?
先程も申しましたが『Stable Video Diffuison』とは、Stablitiy AI社が公開した、テキストや画像から動画を生成するAIモデルになります。
同社の画像モデル「Stable Diffusion」をベースにしており、コードはGitHubで公開されています。また、ローカルでモデルを実行するためのウェイトはHugging Faceで公開しています。
このモデルは、
- テキストから画像への事前トレーニング
- 低解像度の動画の大規模なデータセットによる動画の事前トレーニング
- 高解像度動画の小規模データセットを使った動画の微調整
という3フェーズでトレーニングされています。
リサーチプレビュー版では、2つの画像から動画を生成するモデルのみ公開されており、テキストから動画への変換は、現在ウェイティングリストに登録する状態になっているWebツールが必要となっています!
リサーチプレビュー版では、3~30フレーム/秒のフレームレートで14フレームと25フレームの2種類の動画を生成できるようになっています。
『Stable Video Diffusion』の用途の種類
まず、今わかる使い方に関する情報を簡単にまとめておくと、2種類の方法があります。
1つ目は、画像から動画を生成するものです。
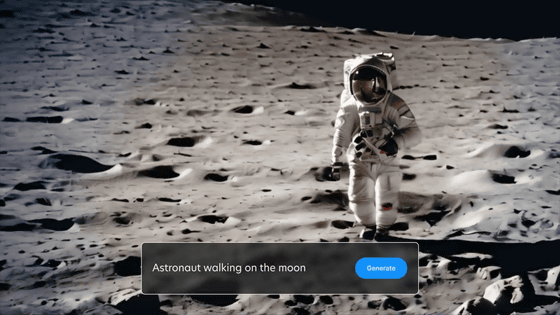
2つ目は、プロンプトから動画を生成するものになっており、詳しくはこちらの画像のようにプロンプトとして「Astronaut walking on the moon」と入力すると、『月面を歩く宇宙飛行士』の動画が生成されるという仕組みになっています。
Google Colab版『Stable Video Diffusion』の使い方!
そのノートブックが、こちらになります。

操作方法はいつもと同じく、ランタイムに接続して実行ボタンを押していくという形になります!
このとき、『ドライブにコピー』したノートブックを使うと良いですよ。
Google Colabの使い方が分からない方は、下記記事を参考にしてください!

『Download weights』について
上から順番にコードを実行していくのですが、途中『Download weights』という項目があります。
ここでは、動画のフレーム数を選択できるようになっています。

- svd…14フレーム数(1秒間に画像が14枚表示される)
- svd_xt…25フレーム数(1秒間に画像が25枚表示される)
つまり、パラパラ漫画のようなものでフレーム数が多いほうがより滑らかで綺麗な動画が生成できるということです。
ですので、『svd_xt』で生成することをオススメします!
こちらが選択できましたら、また実行ボタンをクリックして進めていきましょう。
『Do the Run!』について
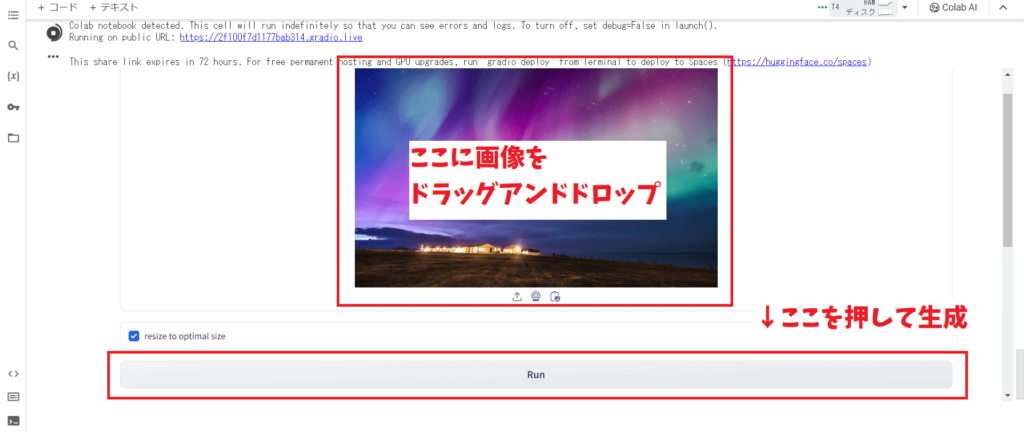
1番最後のコードまでたどり着くと、画像が挿入できるようになります。
こちらに動画化したい画像を挿入してください!
今回はフリー画像でいくつか動画を生成してみます。
①花火
元画像

そして実行ボタンを押すと動画の生成が始まります。(時間は10分ほどかかるので、出来るまで気長に待ちましょう…!)
そして出来上がった動画がこちらです!
どうでしょうか?
とてもきれいに花火が上がった動画が生成されていますね!
特に、花火などキラキラとしたものの表現が得意なようですね。
②走る犬
元画像

生成された動画がこちら
どうでしょうか?
元気に走っている姿が生成されましたね!
このようにいろいろ試してみましたが、人物の描写はあまり得意ではなさそうです…。ですが、改良されて人物も綺麗に動画化できるようになるでしょう。
では、イラストでも試してみましょう。
③船のイラスト
元画像

生成された動画はこちら
描写の細かさは下がりましたが、船が動いている様子はちゃんと動画化されています!
こんな感じで簡単に動画化できるので、ぜひ試してみてくださいね!
今後はプロンプトから動画も生成できるということで、公開が非常に楽しみな機能です。
まとめ
いかがでしたでしょうか?
テキストから動画が作れる『Stable Video Diffusion』について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 『Stable Video Diffuison』とは、Stablitiy AI社が公開した、テキストから動画を生成するAIモデル
- 2026年1月時点では、商用利用不可のモデルになります。
- 2026年1月時点では、研究用途のみの公開で一般公開を待っている状態
- Google colab版で画像から動画を生成できる機能を試すことは可能
ついにテキスト・画像から動画が生成できるとのことなので、一般公開が非常に楽しみですね!
ほかにもStable Diffusionで動画を生成する方法も紹介していますので、是非下記記事もあわせてチェックしてみてください!



画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

