
画像生成AIの台頭により、誰でも簡単に画像を生成できるようになりましたが、今では画像生成に続いて動画生成も進歩しています。
今回は、簡単に動画を生成することができるStable Diffusionの拡張機能『modelscope text2video Extension』について説明します。
「Stable Diffusionで画像生成は出来るけど、動画生成の仕方がわからない」「簡単に1から動画を作成したい」そんな方に本記事はオススメです。
内容をまとめると…
modelscope text2video Extensionはテキストプロンプトから直接動画を生成できるStable Diffusionの拡張機能
拡張機能のインストールに加え、HuggingFaceから4つのモデルファイルをダウンロードしてModelScope/t2vフォルダに配置する事前準備が必要
動画の長さは「フレーム数 ÷ フレームレート」で計算され、フレームレートを下げれば滑らかさと引き換えに動画を長くできる
Width・Heightの解像度設定はVRAM容量に合わせて調整し、GPUスペックが低い場合は小さめに設定する
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

拡張機能「modelscope text2video Extension」とは
『modelscope text2video Extension』とは、テキストから簡単な動画を作成できるStable Diffusionの拡張機能です。
※Stable Diffusionの導入がまだの方は、以下の記事を参考にしてください。

以下の公式ページには、『text2video Extension』について詳しい内容が載っています。
拡張機能「modelscope text2video Extension」の導入方法
『modelscope text2video Extension』は、以下の手順に従って導入しましょう。
手順1:“Extensions”→“Install from URL”タブを開き、「https://github.com/kabachuha/sd-webui-text2video.git」を入力し、“Install”ボタンをクリック
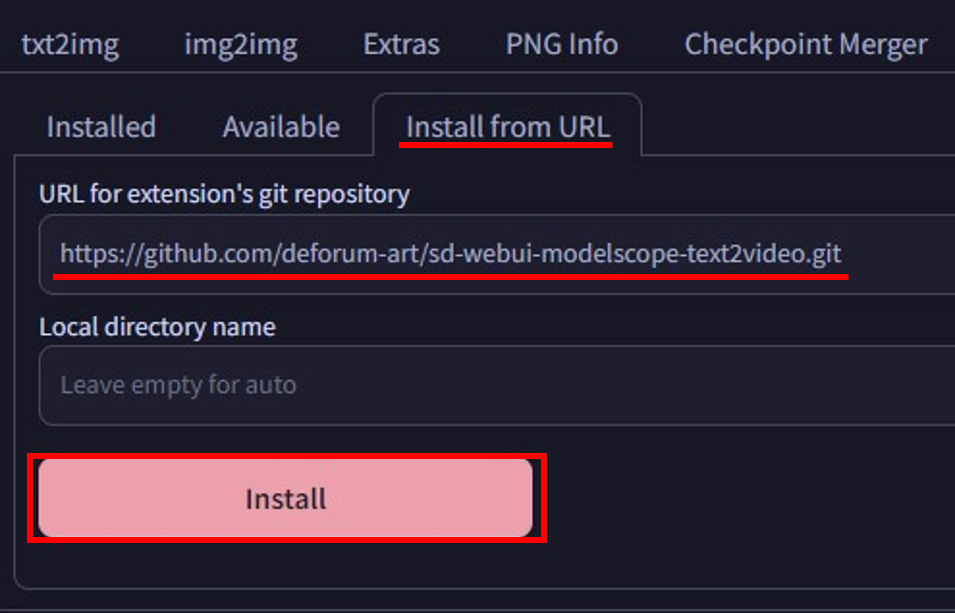
手順2:“Installed”タブを開き、“Apply and restart UI”をクリックし、Stable Diffusionを再起動

※より詳細に拡張機能のインストール方法を知りたい方は、以下の記事を参考にしてください。

拡張機能「modelscope text2video Extension」の使い方
『modelscope text2video Extension』を使用する前に少しだけ準備が必要です。事前準備ができていないと、こちらの機能が動かないこともあります。
まずは、こちらのサイトから必要なファイルをダウンロードしましょう。
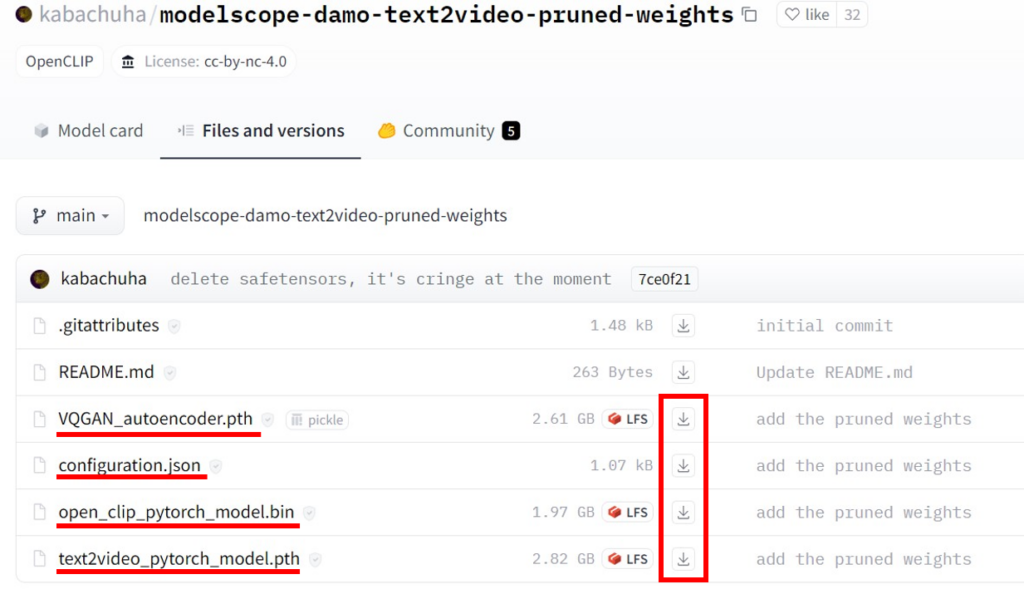
必要なファイルは、以下の4ファイルです。
- VQGAN_autoencoder.pth
- configuration.json
- open_clip_pytorch_model.bin
- text2video_pytorch_model.pth
これらをダウンロードできたら、『stable-diffusion-webui』→『models』→『ModelScope』→『t2v』のフォルダ内に4つのデータを格納しましょう。
※『ModelScope』及び『t2v』のフォルダは自分で作成する必要があります。
これで事前準備は完了です。続いて、『modelscope text2video Extension』の設定項目について説明します。
拡張機能が正常にインストールされていると、「text2video」タブが表示されるのでそれを選択しましょう。すると下のような設定画面が出てきます。
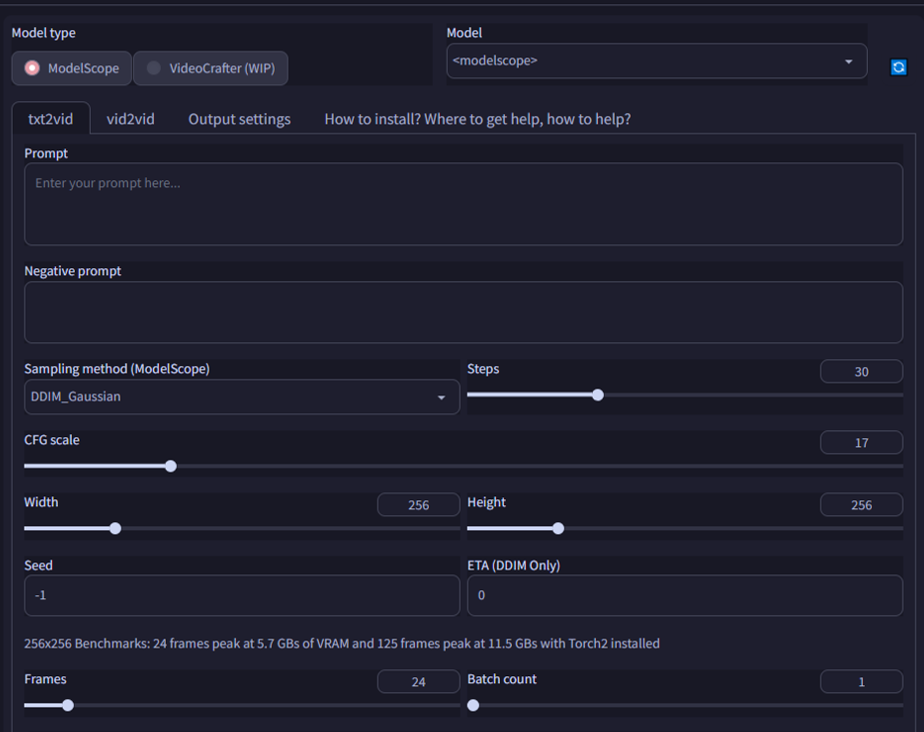
主な設定項目は次のとおりです。
- Model Type:
Modelscope, VideoCrafterのどちらを使うかを選択します。 - Prompt, Negtive prompt:
画像生成と同様に、動画の内容を指定します。複雑な内容は指定できないようです。 - Width, Height:
動画の解像度が決まります。GPUのVRAMが少ない場合は小さめにしましょう。 - Frames:
動画のフレーム数(=動画を構成する静止画の枚数)です。この値と、後述するフレームレートによって動画の長さが決まります。
txt2vidタブを設定したら、次はOutput Settingsタブを開いて、設定を行います。いくつか設定項目がありますが、とりあえず「Frame rate」だけは決めましょう。
動画の長さは下記の計算式で決まります。
動画の長さ=フレーム数 / フレームレート
例えばフレーム数=24、フレームレート=8のときは動画の長さは3秒になります。
動画の尺を少しでも長くしたい場合は、フレームレートを落とせば滑らかさと引き換えに動画の時間を長くすることができます。
設定項目を入力した後、オレンジ色の「Generate」ボタンを押すと動画の生成が始まります。GPUの性能や動画の解像度・長さにもよりますが、時間はそれほどかかりません。
また、生成した動画の出力先は下記のとおりです。
『stable-diffusion-webui』→『outputs』→『img2img-images』→『text2video』
このフォルダ以下に、静止画(PNGファイル)と動画ファイル(MP4)が出力されます。
まとめ
いかがだったでしょうか?
今回は、『modelscope text2video Extension』 について解説してきました。本記事のポイントをまとめると、以下のようになります。
- 『modelscope text2video Extension』とは、テキストから簡単な動画を作成できるStable Diffusionの拡張機能
- 『modelscope text2video Extension』を使用するには、拡張機能の導入と4つのデータのダウンロードが必要です。
- 動画の長さ=フレーム数 / フレームレートであり、フレームレートを落とせば滑らかさと引き換えに動画の時間を長くすることができます。
Stable Diffusionで画像生成できるようになった後は、動画生成にもぜひチャレンジしてみてください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

