
ChatGPTの画像生成は、「こんな画像を作りたい」と話しかけるだけで、AIがすぐに形にしてくれる機能です。操作はとても簡単で、専門的なスキルやデザイン知識がなくても始められます。
この記事では、ChatGPTで使える画像生成の最新情報を、初心者にもわかりやすくまとめています。4o Image GenerationとDALL·E 3の違い、実際の使い方、比率や透過設定の指定方法、英語プロンプトのコツ、商用利用時の注意点などを順を追って解説します。
さらに、Nano BananaやGrok Imagine、Midjourneyといった他の主要AIモデルとの比較も行い、同じ指示を与えたときにどんな違いが出るかを実例で紹介しています。ChatGPTの画像生成をまだ使ったことがない人でも、この記事を読めば、すぐに自分のアイデアを画像として形にできるようになるはずです。
📖この記事のポイント
- ChatGPTの画像生成は専門知識がなくても誰でも簡単に手軽に使えるのが最大のおすすめポイント!
- プロンプトのコツは短く具体的に。テキストを入れる場合は短い英単語で指定。キャラやスタイルを保つには「the same character」など一貫した表現を使うと安定
- 実写編集に強いNano Banana、表現力の高いGrok Imagine、芸術的なMidjourneyといった他社モデルも用途に応じて使い分けが有効!
- 制限やエラーが出たら時間をおき、長文指示は短く整理。日本語の文字崩れはローマ字化、人体の崩れは具体的修正指示で対応
- AI画像生成を極めて、収益に繋げる実践的な活用方法を学ぶならまずは実際に収益化しているAIのプロに無料で教わるのがおすすめ!
- たった2時間の無料セミナーで会社に依存しない働き方&AIスキルを身につけられる!
- 今すぐ申し込めば、すぐに月収10万円UPを目指すための超有料級の12大特典も無料でもらえる!
\ 累計受講者10万人突破 /
無料特典を今すぐ受け取る
ChatGPTの画像生成モデル
最近、「GPT-5で画像生成ができる」と説明しているメディアを目にすることがありますが、これは誤った情報であり、生成AIについて知識のない人が書いている、という裏付けになります。GPT-5はあくまでテキスト理解や推論を担う言語モデルであり、実際に画像を描いているのは別の画像生成モデルです。
ChatGPTで画像を生成できるのは、GPT-4oに統合された「4o Image Generation」、もしくは従来のDALL·E 3(専用の「DALL·E GPT」経由)のいずれかです。
ここでは、この2つの仕組みと使い分けについて整理します。
4o Image Generation がデフォルト
ChatGPTの標準の画像生成は、GPT‑4oにネイティブ統合された「4o Image Generation」です。プランによって制限はありますが、全てのユーザーでChatGPTで「画像を作成」と頼むと基本的にこの系統が使われます。
4o Image Generationは、テキストの正確な描画(看板やレイアウト文字など)、プロンプトの厳密な追従、会話コンテキストやアップロード画像の活用を重視して設計されています。これにより、資料用図版やUIモック、ロゴ案のような意味の厳密さが求められるビジュアルでも狙い通りに作りやすくなりました。
使い方は簡単で、チャットで依頼するか、マイク横の「すべてのツール」→「画像を作成」を選ぶだけです。指示が複雑な場合は生成に最大で約2分かかることがあります。
DALL·E 3 は「DALL·E GPT」で継続提供
DALL·E 3は、いまも専用の「DALL·E GPT」から利用できます。OpenAIはDALL·Eを「レガシー(旧来)系の画像生成モデル」と位置づけ、最新の画像生成はメインチャット(=4o Image Generation)を案内しています。
公式ヘルプでも、全ての各ユーザーはDALL·E GPT経由でDALL·E画像を作れること、そしてDALL·Eで生成された画像には「Created with DALL·E」という表示が付くことが明記されています。
たった2時間の無料セミナーで
会社に依存しない働き方&AIスキル
を身につけられる!
今すぐ申し込めば、すぐに
月収10万円UPを目指すための
超有料級の12大特典も無料!
仕組みと進化の歴史
ChatGPTの画像生成は、この数年で大きく進化してきました。初期は「DALL·E」という独立した画像生成AIを使っていましたが、今ではChatGPT本体に組み込まれ、テキスト理解と画像生成が一体化した形で動作しています。
つまり、ChatGPTが文章を理解し、その流れの中で自然に画像を作れるようになったということです。この変化によって、以前よりも会話に沿った柔軟な画像生成ができるようになりました。
アーキテクチャの変化(拡散→オートレグレッシブ)
かつてのDALL·E 2やDALL·E 3では「拡散モデル」と呼ばれる仕組みが使われていました。これは、最初にノイズのかかった画像を作り、少しずつ形を整えていくことで最終的な絵を完成させる方法です。
芸術的で雰囲気のある画像を得意とする一方で、看板の文字や構図など、細かな要素を正確に描くのは難しいという弱点がありました。
その後登場したGPT-4oでは、言語理解と画像生成を同じ仕組みの中で扱えるようになりました。この方式では、ChatGPTが文章の意味をそのまま画像生成に反映できます。
たとえば「青い空に赤いバラが咲いている庭園」と指示した場合も、言葉の順番や関係を理解したうえで正確な構図を作ります。文字やロゴなども読み取りやすく描けるようになり、より実用的な画像が生成できるようになりました。
ChatGPT内での生成・編集フロー
現在のChatGPTでは、画像生成が会話の中に完全に組み込まれています。ユーザーが「この内容を絵にして」と入力すると、ChatGPTがまず意図を理解し、内部で画像生成モデルに適した形に変換します。その後、画像モデルが実際の絵を生成し、結果がチャット画面に表示されます。
画像が表示されたあとも、追加で「もう少し明るくして」「背景を変えて」などと指示すれば、そのまま編集ができます。すでにある画像をアップロードして、一部だけを変更することも可能です。このように、ChatGPTでは文章での指示から生成、そして修正までを一つの会話の流れで完結できる仕組みになっています。
この進化によって、以前のように複雑な操作やツールの切り替えを行う必要がなくなりました。文章を入力するだけで、AIが理解し、考え、形にしてくれる――まさに会話で創作できる時代が到来したと言えるでしょう。
たった2時間のChatGPT完全入門無料セミナーで ChatGPTをフル活用するためのAIスキルを身につけられる!
今すぐ申し込めば、すぐに
ChatGPTをマスターするための
超有料級の12大特典も無料!
ChatGPTで作ったAI生成画像の例
① スタバっぽいカフェでノートPCを使う柴犬
a realistic shiba inu sitting at a cafe table, typing on a laptop, wearing glasses, latte on the table, cozy lighting, realistic photo, 4k


② 原宿の交差点を歩く宇宙飛行士
a realistic astronaut walking across a Shibuya crossing, surrounded by people, neon lights reflecting on the helmet, cinematic photo, 16:9


③ ピンク色の髪の女子高生がAIと自撮り
a Japanese high school girl with pastel pink hair taking a selfie with a humanoid robot, cute modern style, realistic photo, soft lighting, 1:1


④雪の京都で走る真っ白なスポーツカー
a white sports car speeding through Kyoto streets covered in snow, traditional houses in the background, motion blur, realistic lighting, 4k


⑤タピオカを飲む侍
a samurai in traditional armor drinking bubble tea, standing on a modern Tokyo street, realistic photo style, funny yet beautiful, detailed armor reflections


ChatGPTの画像生成の使い方
ChatGPTでは会話の延長で画像を作れます。難しい操作は不要で、作りたい内容を自然な文章で伝えれば十分です。はじめての人は、まず小さな要素から指定し、徐々に細かくしていくと狙いが伝わりやすくなります。
画像生成の基本ステップ
ここでは、ChatGPTで画像を作るまでの流れを、実際の画面と一緒に説明します。
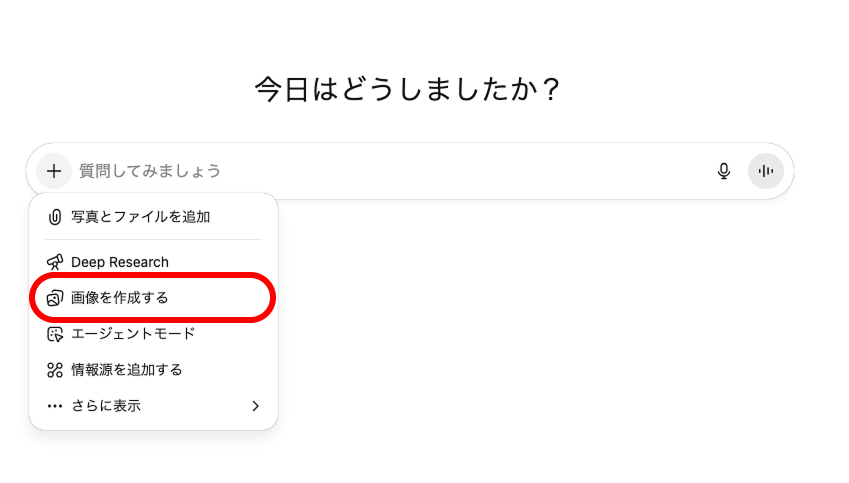
- 手順1「画像を作成する」を選ぶ
下記の画像のように「+」マークを選択して、「画像を作成する」を選択します。

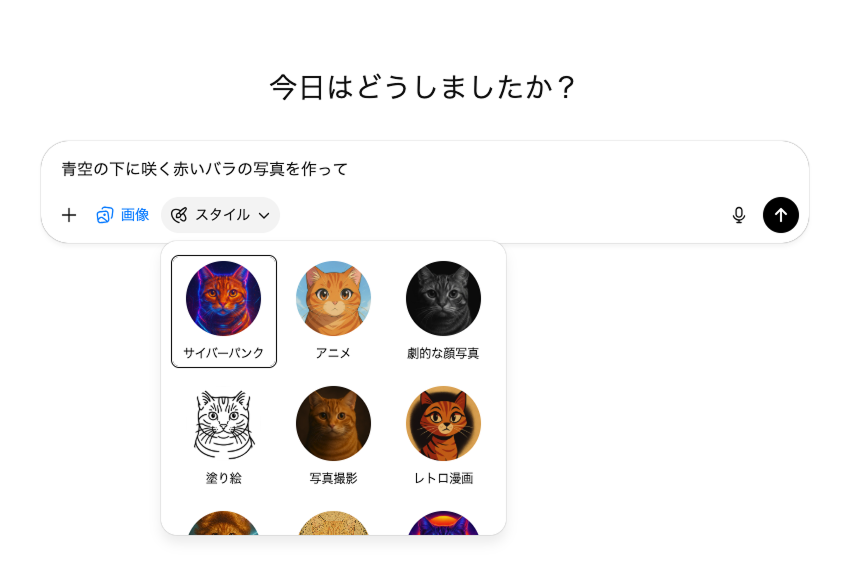
- 手順2プロンプトを入力
作りたい内容を自然な日本語で入力します。最初は難しい構文は不要です。もしある程度イメージがある場合は、それを詳細に書くと正確に伝わります。また、プロンプト入力の下の「スタイル」から好みのものを選択することもできます。

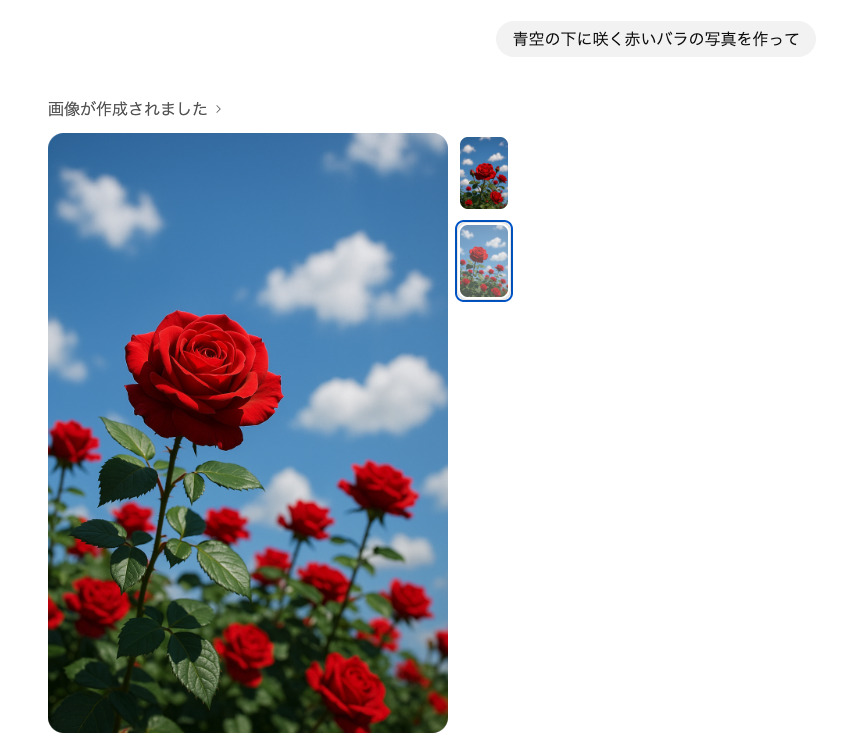
- 手順3画像の生成
送信後、数十秒から1分ほどで画像が表示されます。複数候補が生成されるので、好みのものを選びます。
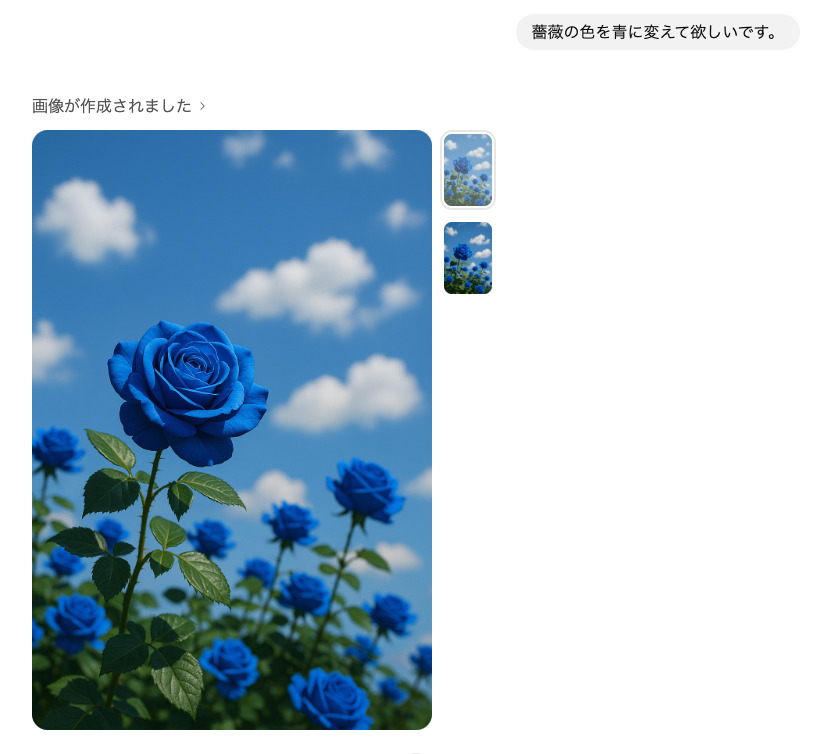
- 手順4修正
気になる点があれば、そのまま文章で修正依頼が可能です。構図や色味、背景変更などを自然文で伝えられます。今回は「薔薇の色を青に変えて欲しいです。」と指示してみます。
- 手順5ダウンロード
完成した画像をクリックすると拡大表示されます。画像をホバーして画像下に出てくるメニューから保存ができます。


出力サイズ・アスペクト比・透過(PNG)指定
ChatGPTでは、画像の縦横比や背景の透過なども文章で簡単に指定できます。最初に目的に合った形を考えてから、プロンプトに「縦長」「横長」「正方形」などのキーワードを添えるのがポイントです。
たとえば、プレゼン資料やウェブページのスライドに使うなら横長(16:9や4:3)がおすすめです。スマートフォンのサムネイルやSNS投稿向けなら、縦長(9:16)や正方形(1:1)のほうが画面に収まりやすく見栄えが良くなります。印刷物やポスター用のように細部まで見せたい場合は、「高解像度で」「細部までくっきり」などの表現を加えるときれいに仕上がります。
背景を透明にしたいときは、プロンプトの最後に「背景は透明にしてください」「透過PNGで出力してください」と書き添えます。背景透過を指定すると、ロゴやイラストを他のデザインに組み込みやすくなり、後から画像編集ソフトで使い回すのにも便利です。
生成後は、実際の利用環境(スライドやSNSの比率)で表示を確認し、切れや歪みがないかチェックします。特に複数の画像を作る場合は、最初の1枚で比率が合っているか確かめてから量産すると、修正の手間を減らせます。
用途ごとのアスペクト比をまとめてみたので、参考にしてみてください。
| 用途 | 推奨アスペクト比 | ChatGPTへの指示例 | 備考 |
|---|---|---|---|
| プレゼン資料・スライド | 16:9 または 4:3 | 「16:9の横長構図で、会議資料に使う画像を作成して」 | 横に広く、PowerPointやKeynoteのスライドに最適。 |
| スマホ・SNSのアイキャッチ | 1:1 または 9:16 | 「スマホ向けの縦長構図で、Instagram投稿用の画像を生成して」 | スマホ画面で見やすく、SNSでの発信向き。 |
| ウェブバナー・広告 | 3:1 ~ 2:1 | 「横長バナーサイズ(3:1)で、Webサイトのヘッダーに使う画像を作って」 | テキストやロゴを配置しやすい横長デザイン。 |
| 印刷・ポスター | A4比率(約1.4:1) | 「A4縦構図で、高解像度のポスター用画像を作って」 | 細部がくっきり見えるように高解像度を指定。 |
| ロゴ・アイコン素材 | 1:1(正方形) | 「背景を透明にして、透過PNG形式でロゴ画像を作成して」 | 背景透過PNGなら他のデザインに重ねても自然。 |
よく使うプロンプト一覧
画像生成では、英語の単語をうまく組み合わせると狙い通りの雰囲気に近づきます。日本語だけでも動作しますが、以下のような英単語を添えると再現性が上がります。目的に合わせて使い分けましょう。
| 用途 | キーワード(英単語) | 意味・効果 | 使用例 |
|---|---|---|---|
| 写真風にしたい | realistic / photo / cinematic / detailed | 現実の写真のような質感になる | a realistic photo of a sunset beach |
| イラスト・アート風 | illustration / digital art / painting / anime style | 絵画やアニメのような雰囲気に変わる | digital art of a forest in anime style |
| 柔らかい印象に | soft light / pastel colors / dreamy / gentle tone | 明るく淡い色合い、優しい雰囲気 | a dreamy portrait in pastel colors |
| 高級・プロっぽく | studio lighting / sharp focus / premium / glossy | 商品写真や広告向けに高精細な質感 | product photo with studio lighting |
| 暗く雰囲気重視 | moody / dramatic / low key / cinematic lighting | コントラストが強く映画的な印象 | dramatic lighting portrait in moody tone |
| 背景指定 | plain background / white background / landscape / cityscape | 背景の種類を制御する | product on plain white background |
| カメラ構図指定 | close-up / wide shot / top view / portrait shot | 被写体の距離や角度を指定 | top view of a coffee cup on a table |
| スタイル指定 | minimalist / retro / futuristic / watercolor | デザインや時代感の指定 | minimalist poster with modern typography |
| テクスチャ・素材 | metallic / wood texture / fabric / glass | 質感や素材を追加する | wood texture background for packaging |
| 照明・色調 | warm light / cool tone / sunset lighting / neon | 光の色や雰囲気を調整 | city street at night with neon lights |
| 背景透過 | transparent background / PNG / isolated object | 背景を消して素材化 | isolated logo on transparent background |
使い方のコツとして、複数の単語をカンマで区切って並べると自然な指示になります。
例):「a product photo, white background, soft light, high quality」
このように並べるだけで、より明確に意図が伝わり、安定した結果が得られます。
利用制限と安全設計
ChatGPTの画像生成機能には、ユーザーが不適切な画像を作成しないようにするための「安全設計」が組み込まれています。
この仕組みは、入力(プロンプト)と出力(生成画像)の両方をAIが自動で検査するもので、ポリシー違反や著作権侵害につながる可能性がある内容を未然に防ぐ役割を果たしています。
もし「この画像は生成できません」と表示された場合は、ChatGPTが内容を安全面でブロックした可能性があります。その場合は、言葉を少し柔らかく言い換えたり、目的を具体的に説明すると通ることがあります。たとえば「流血した人」ではなく「けが人の応急処置を説明するイラスト」と伝えると、教育目的として安全に生成されやすくなります。
無料/有料プランの利用制限と上手な回避
ChatGPTの画像生成には、プランごとに使用回数の上限があります。
無料プランでは短時間に数枚しか生成できない一方、有料プラン(Plus、Pro、Teamなど)では高速かつ多枚数の生成が可能です。
| プラン | 利用目安 | 特徴 |
|---|---|---|
| 無料(Free) | 1日あたり数枚まで | 試し使いに最適。生成速度はやや遅め。 |
| Plus | 3時間で最大50リクエスト程度 | 安定性が高く、画像生成も快適。 |
| Pro / Team / Enterprise | 制限ほぼなし | ビジネス・商用利用に向く。 |
もし「制限に達しました」と表示された場合は、時間を置くか、指示を短くして再試行します。
また、生成負荷が高い時間帯(日本時間の夜〜深夜)は混雑しやすいため、早朝や昼間に生成すると高速で安定します。
頻繁に使う予定がある場合は、無料よりもPlus以上のプランが現実的です。仕事で利用する場合は、レート制限のないTeamプランを選ぶとストレスなく運用できます。
禁止・制限されるコンテンツ
ChatGPTの画像生成では、以下のようなカテゴリの画像は原則として作成できません。これはDALL·E 3やGPT-4oの共通ポリシーとして明記されています。
| 分類 | 具体的な禁止・制限内容 | 補足 |
|---|---|---|
| 性的表現 | 裸体、性的行為、露出の多い描写など | 芸術・教育目的でも原則不可。曖昧な場合もAIが安全側に判断します。 |
| 暴力・残虐描写 | 流血・戦闘・拷問などの暴力的シーン | 医療・歴史文脈で必要な場合は「解説用イラスト」と明記します。 |
| 差別・ヘイト表現 | 特定の国籍・宗教・性別などへの侮辱 | 倫理的リスクを避けるため自動的に拒否されます。 |
| 違法行為 | 武器製造・犯罪行為・薬物の使用など | 教材目的であっても具体的な描写は避けます。 |
| 有名キャラクター・ブランド | 既存のアニメキャラや企業ロゴの再現 | 著作権・商標権を守るため生成できません。 |
これらに該当する場合は、ChatGPTが警告を出すか、まったく画像を生成しない仕組みになっています。
どうしても近いテーマを扱いたいときは、「一般化した説明」「架空の例」「教育的な意図」を明確に伝えると、許可される場合があります。
公的人物の扱いとオプトアウト
OpenAIは、著名人や政治家などの画像生成に対して特に慎重なポリシーを設けています。
成人の公的人物であっても、誤情報や風評被害につながるような画像生成は制限対象です。たとえば「大統領が泣いている写真」など、虚偽を生む可能性のあるリクエストは拒否されます。
一方で、報道や教育などの「正当な文脈」における人物描写は、限定的に許可されることがあります。
さらにOpenAIは2024年以降、**本人や遺族、権利者が申請すればモデル学習や生成対象から除外できる「オプトアウト制度」**を導入しています。これにより、公的人物やアーティストの肖像権・人格権への配慮が進みました。
基本的に、著名人の画像を必要とする場合は「似た雰囲気の架空人物」「政治家風の人物」などに置き換えるのが安全です。
多言語テキストの制約・日本語の崩れ対策
ChatGPTの画像生成は英語で最も安定しています。
特に画像内のテキスト描写は、アルファベットを中心に学習されているため、英単語は正確に描けても日本語は崩れたり意味不明な文字列になったりすることがあります。
日本語を含む画像を作る際は、次のような工夫で成功率を上げられます。
- 長い文章ではなく2〜3語の短い単語にする(例:「ラーメン」より「Ramen」)
- ローマ字や英単語に置き換える(例:「祭」→「Festival」)
- 配置指示を入れる(例:「上部に文字を配置」「看板の中央に“OPEN”と表示」)
- 生成後に画像編集ソフトで文字を入れ直すのも実務的に有効
この制約は現在の最新世代のモデルでも完全には解消されていません。将来的には改善される可能性がありますが、現時点では「短い英単語中心+後から微調整」が最も安定した方法です。
商用利用と著作権
ChatGPTで生成した画像は、商用利用も可能です。ただし、生成した時点で自動的に「完全に自分の著作物」となるわけではなく、法律上の扱いや企業での利用には一定の注意が必要です。
ここでは、利用規約、技術的な来歴管理、そして日本における法的な位置づけを順に解説します。
ユーザーは出力を所有
OpenAIの利用規約では、ChatGPTやDALL·Eを使って生成された画像の「出力(Output)」について、利用者がその権利を所有すると明記されています。つまり、ChatGPTを通じて作成した画像は、基本的にユーザーの自由に使うことができます。
具体的には以下のような利用が許可されています。
- 自社サイトや広告素材への掲載
- SNSでの配信、キャンペーン利用
- 書籍・雑誌・映像作品での使用
- グッズ化や印刷物への転用
- クライアント案件での納品
ただし、権利を「所有する」とは言っても、法的には著作権が自動的に発生するとは限らない点に注意が必要です。
多くの国では、著作権は「人間による創作性」が要件とされています。したがって、AIが自動で生成した画像は、著作権の対象外と解釈されることがあります。
そのため、ビジネスでの運用では、以下のようなリスク管理を行うと安全です。
- 生成プロンプトや日時、利用目的を記録に残す
- 画像に人間による加工・編集(構図の調整や文字入れなど)を追加して“人の創作性”を加える
- 第三者が著作権や商標権を持つ素材に似ていないか確認する
これらを意識することで、実務的には「自社制作物」として扱いやすくなります。
また、OpenAIは生成物のクレジット表記や出典表示を義務づけていないため、“Made with ChatGPT”などの表記は任意です。透明性を重視する場合は、社内ガイドラインとして明示しておくとよいです。
C2PA等の来歴表示と配布時の実務
ChatGPTの画像生成機能では、C2PA(Content Provenance and Authenticity)規格に基づいた「来歴メタデータ」が自動的に埋め込まれます。
C2PAとは、AdobeやMicrosoftなどが中心となって策定した「コンテンツがどのように作られたか」を示す国際標準規格です。
このメタデータには以下のような情報が含まれます。
- 画像を生成したツール(例:ChatGPT / DALL·E 3 / GPT-4o)
- 生成日時
- 編集・加工が行われた履歴(差分生成・トリミングなど)
- 作成者や発行元(OpenAIの署名)
C2PA対応の画像は、Adobeの「Content Credentials」などのサイトで確認でき、AI生成物であることを証明するデジタル署名が付いています。
ただし、このメタデータはSNS投稿や画像圧縮の過程で削除される場合があります。したがって、オリジナルのPNGファイルは必ず保存しておくことを推奨します。
特に、企業で生成画像を納品・配布する際は次のような運用が実務的です。
- 納品用画像はC2PA付きのオリジナルデータを保管
- 外部公開版は再圧縮されることを前提に「AI生成物」である旨を明記
- 広告・販促素材では、不自然な誤解(実写に見せる偽装など)を避ける表現に留意
このように来歴を開示しておくことで、AIコンテンツの透明性を担保でき、社外・クライアントへの信頼性も高まります。
日本のAI生成画像関連の法律について
日本の著作権法では、著作物の定義を「思想または感情を創作的に表現したもの」と定めています。
この「創作的に表現した」という部分が、人間の関与を前提としており、AIが完全に自動で生成した画像は“著作物”として保護されないとされています。
文化庁も公式に「AI単独生成物には著作権は発生しない」との見解を示しています。
ただし、実務上は次のような扱いが一般的です。
| 状況 | 法的扱いの目安 | 補足 |
|---|---|---|
| AIが自動で生成した画像 | 著作物ではない(無権利状態) | 誰でも使えるが、逆に独占できない。 |
| 人間がプロンプト設計・編集で創意を加えた | 一部に著作性が認められる可能性 | 最終的な構成や加工部分に限り保護される。 |
| 他人の著作物・キャラクターに類似 | 著作権・商標権侵害のリスク | 類似判定や引用の範囲を慎重に確認。 |
つまり、「AIが作った画像」は著作権がないため、他人も自由に利用できる半面、自分の作品として独占することも難しいという立ち位置になります。
このため、商用利用では以下の対策を取ると安全です。
- 企業ロゴ・既存キャラ・人物の生成は避ける
- AI生成画像に人間の編集を加え“共同著作”に近づける
- AI生成であることを明示し、誤認や虚偽表示を避ける
- 重要案件では法務部・顧問弁護士に事前確認を取る
なお、2025年現在、日本政府は「AI生成物に関する権利保護の新制度」を文化庁で検討中です。
将来的に「AI生成物にも限定的な保護を与える」方向が議論されていますが、実際の施行までは時間がかかると見られています。
したがって、現段階では「AI生成物は原則著作権なし。ただし人の関与があれば部分的に保護対象」と理解しておくのが最も現実的です。
ChatGPT画像生成のメリット
ChatGPTの画像生成は、特別なスキルがなくても、会話を通じて誰でも簡単に高品質な画像を作れる点が魅力です。ここでは、初めて使う人でも理解しやすいように、具体的な強みを三つにまとめて紹介します。
会話するだけで理想の画像が作れる
ChatGPTの画像生成は、専門的なコマンドや難しい操作を覚える必要がありません。
「商品をきれいに撮ったような写真を作って」や「明るいオフィスで働く人のイラストを作成して」といった自然な言葉で伝えるだけで、AIが理解して画像を作ります。
さらに、「もう少し明るく」「背景を変えて」「中央に人を配置して」などの短い修正指示にもすぐ対応できます。
他の画像生成ツールのように毎回プロンプトを最初から書き直す必要がなく、会話の流れの中で理想のビジュアルに近づけていけるのが大きな特徴です。
生成から修正・再利用までがスムーズ
一度生成した画像をもとに、追加の指示を出して新しいバリエーションを作ることができます。
たとえば、
- 「このデザインの色違いを作って」
- 「同じ構図で季節を冬にして」
- 「前の画像の背景だけオフィスに変えて」
といった指示を出すだけで、元の画像を参考にした派生版が作れます。
これにより、複数案のデザイン比較やシリーズ制作(広告、SNS投稿、EC商品画像など)が非常に効率的になります。
また、作った画像を再アップロードして「この写真を使ってバナーを作って」と指示すれば、AIが構図を読み取り、新しい用途に合わせた加工もしてくれます。
誰でもすぐ成果を出せる実用性
ChatGPTの画像生成は、デザイン未経験者でも仕事や趣味で実際に使えるレベルの仕上がりになります。
特に次のようなシーンで活躍します。
- SNS投稿のサムネイルやバナーを手早く作りたいとき
- プレゼン資料に入れるイメージ画像が必要なとき
- 商品やサービスのコンセプトをビジュアル化したいとき
こうした場面では、ChatGPTに目的を伝えるだけで、数分以内にプロっぽい仕上がりの画像が得られます。
ツールの操作や画像編集ソフトに不慣れでも、ChatGPTなら自然な会話の延長で制作できるため、「伝える力」と「作る力」を同時に強化できるのが大きな魅力です。
主要AI画像モデルの比較と使い所
同じ「画像生成」でも、出てくる絵や作業のしやすさがかなり違います。ここでは実際に使ったときの手触りが分かるように、Nano Banana、Grok Imagine、Midjourneyを具体例ベースで整理します。
| モデル | 得意分野 | 苦手・注意 | 使い所の具体例 |
|---|---|---|---|
| Nano Banana(Gemini 2.5 Flash Image) | 写真の編集・合成、部分差し替え、色味調整 | ゼロからの独創的世界観づくりはやや弱い | EC商品の背景差し替え、人物写真の不要物除去、同一構図で季節だけ変更 |
| Grok Imagine | 派手なビジュアル、スタイル変換、静止画からのショート動画化 | 出力のブレが大きい、選別前提 | SNS映えの強い一枚、実験的な表現、動きのあるティザー |
| Midjourney(Niji系) | アート性の高い一枚、キャラクター表現、世界観づくり | 画像内テキストは苦手、細かい対話修正は非得意 | キービジュアル、キャラ案、雰囲気重視のキャンペーン |
下記の同じプロンプトで実際に生成してみた画像で、それぞれの違いを見てみましょう。
a person standing on a rainy street at night, neon signs in the background, cinematic lighting, detailed reflections, 16:9
○Nano Banana(Gemini 2.5 Flash Image)


○Grok Imagine


○Midjourney


プロンプトと画像生成のコツ
ChatGPTでできるだけ思い通りの画像を作るには、プロンプト(指示文)の書き方がとても重要です。短くても要点を押さえれば精度は上がります。この章では、初心者でもすぐ試せる具体的なコツを紹介します。
プロンプトは英語が基本
ChatGPTは日本語の指示にも対応していますが、画像生成モデルは英語で学習されているため、英語で書くと構図や雰囲気の再現度が高くなります。
たとえば「海辺の夕日を背景に立つ女性」という指示なら、
a woman standing on the beach at sunset, soft lighting, 16:9
と英語で書くと、構図や光の雰囲気が正確に伝わります。
英語が苦手な場合は、ChatGPTに「この内容を画像生成用の英語プロンプトにして」と頼むと自動で変換してくれます。短くシンプルな英語でも十分なので、まずは単語ベースから始めましょう。
プロンプトの構文(書き方)
画像生成の精度を上げるには、プロンプトを「情報の順序」に沿って整理します。おすすめの構文は次の通りです。
目的(何に使うか)+ 主体(誰・何を描くか)+ 構図(視点や距離)+ スタイル(雰囲気や画風)+ 条件(比率・照明・質感など)
for a presentation slide, a businesswoman standing near a window, wide shot, bright office lighting, 16:9
このように段階を踏んで書くと、AIが誤解しづらくなり、構図や色合いが安定します。
また、複数の要素を入れるときはカンマで区切ると分かりやすく伝わります。
| 要素 | 指示例 | 意味 |
|---|---|---|
| 目的 | for social media banner | SNS用の画像にしたい |
| 主体 | a cup of coffee on a table | テーマ・被写体 |
| 構図 | top view, centered composition | 真上からの構図 |
| スタイル | minimal design, soft light | 雰囲気・画風 |
| 条件 | 1:1 ratio, white background | 比率や背景の指定 |
テキスト埋め込みの書き方(短文・固有名詞・配置指定)
画像内に文字を入れる場合は、短い英単語を明示的に書くのがコツです。
ChatGPTは英字の描画が得意ですが、日本語の長文は崩れることがあります。
文字を正しく入れたいときは、以下のルールを意識しましょう。
- 短い単語にする(1~2語)
- 引用符で囲む(“text”)
- 配置を指定する(top, center, bottomなど)
- 背景とのコントラストを意識する
こうすると、ロゴやポスターのテキストも比較的正確に出力されます。
もし崩れた場合は、生成後にChatGPTにその画像を再アップロードし「文字部分を修正して」と伝えると、AIが補正して再生成してくれます。
反復・修正指示のテンプレ(同一キャラの一貫性維持)
キャラクターやシリーズものの画像を作る場合、一度決めた設定を会話の中で繰り返すのがポイントです。ChatGPTは文脈を記憶するため、「前と同じ人物」や「同じスタイル」といった表現で統一感を維持できます。
例)
- 1枚目:「a young woman with short hair and a blue jacket, smiling outdoors」
- 2枚目:「the same woman, now sitting at a café table, same hairstyle and jacket, warm lighting」
- 3枚目:「the same character walking through the city at night, neon lights, 16:9」
このように「the same woman」「the same character」などの表現を入れると、前回の人物を引き継いだまま新しいシーンを作れます。シリーズ広告やSNS投稿の連続デザインなど、トーンを揃えたい案件に向いています。
よくあるトラブル
ChatGPTの画像生成は手軽で高精度ですが、使っていると誰もが一度は「なぜか動かない」「思った通りにならない」という壁に当たります。
しかし多くの問題は原因がはっきりしており、少しの工夫で解決できます。ここでは、初心者から中級者までがよく遭遇する代表的なトラブルと、現実的な対処法を紹介します。
レート制限に達した/エラーが出る
○トラブル詳細
短時間で何度も画像を生成していると「生成上限に達しました」や「画像を作成できません」と表示されることがあります。これは、プランごとに設定された生成回数制限(レート制限)に到達している状態です。特に無料プランでは数回の生成で制限にかかる場合があります。
○原因
画像生成は通常のテキスト回答よりもサーバー負荷が高く、一定時間に使えるリクエスト数が厳しく制御されています。混雑時間帯(日本時間の夜〜深夜)は制限が早く発動する傾向があります。
○対処法
- 少し時間を空ける(30分〜1時間程度でリセットされることもあります)
- 指示を短くし、必要最低限の要素だけを残す
- 同じ内容の再生成を連続で行わない
- 夜間など混雑時間帯を避ける(早朝〜昼は比較的スムーズ)
- 安定して使うなら有料プラン(Plus以上)を利用する
有料プランでは3時間あたり最大50回程度生成できるため、実務利用でも十分な余裕があります。
日本語の文字が崩れる/指示が通らない
○トラブル詳細
看板やロゴなどに日本語を入れると、文字がぐにゃぐにゃに崩れたり、意味のない記号になったりします。また、日本語での説明が長いと、AIが正確に理解できず「違う構図」になることがあります。
○原因
ChatGPTの画像生成は英語データで学習されており、日本語の文字形(漢字・ひらがな)をうまく処理できないことがあります。また、長い文章や複雑な表現はAIの解釈がぶれて構図がずれる原因になります。
○対処法
- 文字を短い単語やローマ字に置き換える(例:「寿司」→「Sushi」)
- プロンプトをシンプルに分けて指示する(例:「人物を生成」→「背景を追加」→「テキストを配置」)
- 配置を具体的に伝える(例:「中央に“OPEN”と書かれた看板」)
- どうしても正確な日本語を入れたい場合は、生成後に画像編集ソフトで追加する
英字や数字はかなり高精度で描けるため、商用バナーやロゴ案では「英語ベースで作り、あとで日本語に差し替える」流れが最も効率的です。
人体の破綻・異形
○トラブル詳細
人の手や顔が崩れていたり、指が6本になっていたりすることがあります。特に「複数人」や「鏡」「反射」「複雑なポーズ」などを含む場合に起こりやすいです。
○原因
AIが複雑な人体構造や対象物の重なりを誤って解釈するため。これは画像生成AI全般に共通する現象です。
○対処法
- 問題箇所を名指しで修正指示する(例:「手の形を自然に直して」「顔の歪みを修正して」)
- 人物の数を減らす(最初は1人で生成し、構図を確定してから追加)
- カメラ距離を変える(例:「全身」より「腰上」や「バストアップ」にすると安定)
- 角度を変えた再生成(正面→斜め、上方→下方など)
- 「人物の姿勢を自然に」や「指の形を正確に」など、修正目的を明記して再依頼
生成が遅い → 仕様の目安と短縮テク
○トラブル詳細
「生成中…」のまま1分以上経っても結果が出ないことがあります。特に高解像度の画像や複雑なプロンプトを指定した場合に多発します。
○原因
サーバー混雑・高負荷のプロンプト・通信環境など複数要因があります。大量の要素(人物、背景、光、質感など)を一度に詰め込みすぎると時間がかかります。
○対処法
- 要素を分けて段階的に生成する(例:「背景だけ作成」→「人物を追加」)
- 装飾語を減らす(形容詞やスタイル指定が多いと処理が重くなる)
- シンプルな構成でベース画像を作ってから追加編集する
- 夜間や混雑時間を避ける(アクセスが少ない朝・昼は高速)
- 回線が安定した環境で実行する
一般的な目安として、通常の画像生成は20〜40秒、高解像度では最大2分程度が標準です。2分以上かかる場合は、プロンプトを整理して再試行しましょう。
まとめ
ChatGPTの画像生成は、専門知識がなくても誰でも簡単に使える“会話型デザインツール”です。
思いついたイメージを文章で伝えるだけで、AIが自動で構図・色・光まで考えた画像を作ってくれます。しかも、修正も同じチャット内で何度でもできるため、発想から完成までのスピードが圧倒的に早くなります。
ChatGPTの画像生成は、アイデア出しから本格的なビジュアル制作までを一気にこなせる、非常に汎用性の高いツールです。
はじめは簡単な一枚から始め、少しずつプロンプトの書き方や調整のコツを身につけていくと、想像以上に自由度の高いクリエイティブ体験ができます。
会話から生まれるデザインの新しい形を、ぜひ自分の手で試してみてください。
romptn ai厳選のおすすめ無料AIセミナーでは、AIの勉強法に不安を感じている方に向けた内容でオンラインセミナーを開催しています。
AIを使った副業の始め方や、収入を得るまでのロードマップについて解説しているほか、受講者の方には、ここでしか手に入らないおすすめのプロンプト集などの特典もプレゼント中です。
AIについて効率的に学ぶ方法や、業務での活用に関心がある方は、ぜひご参加ください。
\累計受講者10万人突破/

