
OpenAIが2025年4月に発表した最新AIモデル「GPT-4.1」。従来のGPT-4oから劇的な進化を遂げ、コーディング能力やプロンプト追従性の向上、さらに驚異の100万トークンという超ロングコンテキスト対応で話題を呼んでいるんです。
本記事では、GPT-4.1の基本情報から性能、料金プラン、そして具体的な使い方まで徹底解説します。「最新AIモデルを使いこなしたい」「GPT-4.1とGPT-4oの違いを知りたい」というあなたに、必要な情報をすべてお届けします!
- GPT-4.1とは?
- GPT-4oや他のモデルとの性能比較
- GPT-4.1の料金プラン
- GPT-4.1の使い方

新世代モデル「GPT-4.1」とは?
OpenAIが2025年4月14日に発表した「GPT-4.1」は、同社の最新AI言語モデルファミリーです。今までの「GPT-4o(omni)」より全面的に性能が向上し、特に開発者のニーズに応えるべく設計されています。知識のカットオフ日は2024年6月に更新され、それまでの情報を学習しています。
GPT-4.1の最大の特徴は、コーディング能力の大幅な向上、より正確なプロンプト追従性、そして100万トークンという圧倒的なロングコンテキスト対応にあります。これにより、大規模なコードベースや長文ドキュメントの処理、複雑な指示にも正確に対応できるようになりました!
2025年4月15日時点では、GPT-4.1シリーズはAPI経由でのみ利用可能で、ChatGPTのウェブアプリやモバイルアプリでは利用できません。ただし、GPT-4.1での多くの改善点は、ChatGPTで利用できるGPT-4oに段階的に組み込まれていく予定とのことです。

GPT-4.1ファミリーとは?3つのモデルの違いと特徴
GPT-4.1シリーズには、用途や予算に応じて選べる以下の3つのモデルが用意されています。
- GPT-4.1(フラッグシップモデル)
- GPT-4.1 mini
- GPT-4.1 nano
それぞれの性能比較をしてみました!
| GPT-4.1 (フラッグシップモデル) | GPT-4.1 mini | GPT-4.1 nano | |
|---|---|---|---|
| 種類 | 最高レベルの性能を持つメインモデル | 知能とスピード、コストのバランスに優れた中間モデル | OpenAIの最速・最も低コストなモデル |
| 特徴 | ①複雑なコーディングタスクや高度な指示追従が必要な場面に最適 ②コンテキスト理解力、推論能力が最も高い | ①GPT-4.1の約半分の応答時間でありながら、多くのベンチマークでGPT-4oを上回る ②コスト効率が高い(GPT-4oより83%コスト削減) ③特にマルチモーダルタスクで高いパフォーマンスを発揮 | ①低レイテンシが重要なタスク(テキスト分類、オートコンプリート等)に最適 ②100万トークンのコンテキスト対応を維持しながら超高速レスポンス |
| こんな利用に最適 | 大規模プロジェクトやエンタープライズ向け | 一般的な開発や日常的な利用に最適 | 大量リクエスト処理や基本的なタスク自動化 |
3つのモデルはそれぞれ特性が違いますが、いずれも100万トークンのコンテキスト対応という特徴を共有しています。利用目的や予算、パフォーマンス条件に応じて最適なモデルを選択しましょう!

GPT-4oや他のモデルとの性能比較
GPT-4.1シリーズは、今までのGPT-4oシリーズと比較してどれほど進化したのでしょうか?
各種ベンチマークの結果を見てみましょう!
| 学術知識理解(MMLU) | GPT-4.1:90.2%(GPT-4o:85.7%) 多言語MMLU:87.3%(GPT-4o:81.4%) 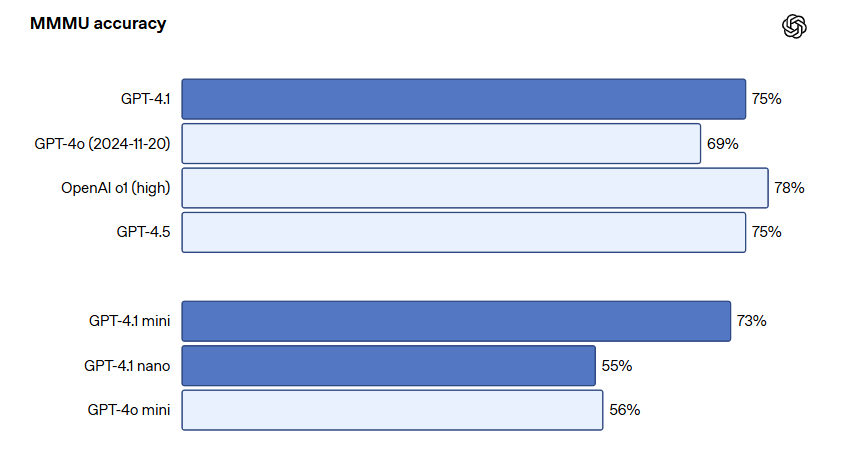 |
| 専門知識(GPQA Diamond) | GPT-4.1:66.3%(GPT-4o:46.0%) 専門分野の複雑な質問に対する理解度が大幅向上 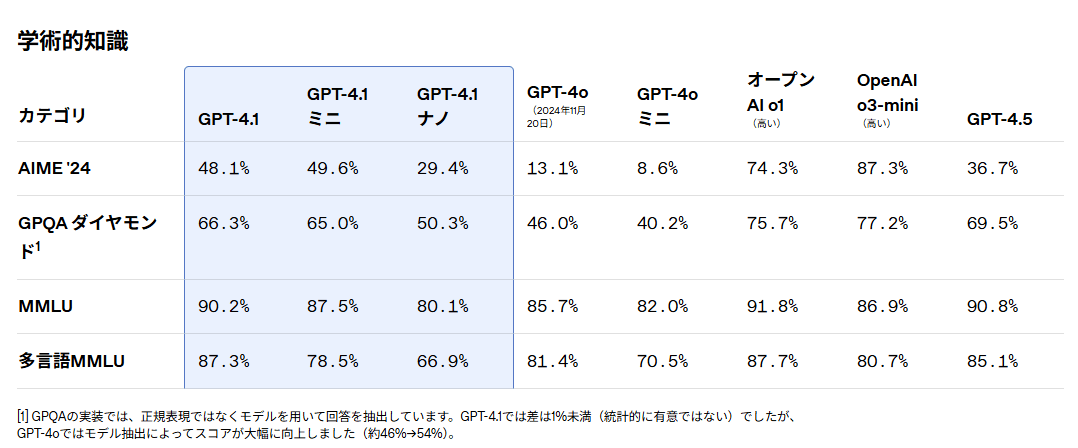 |
| コーディング(SWE-bench Verified) | GPT-4.1:54.6%(GPT-4o:33.2%、GPT-4.5:38.0%) GitHubイシューを解決する能力を測るベンチマークで大幅に向上 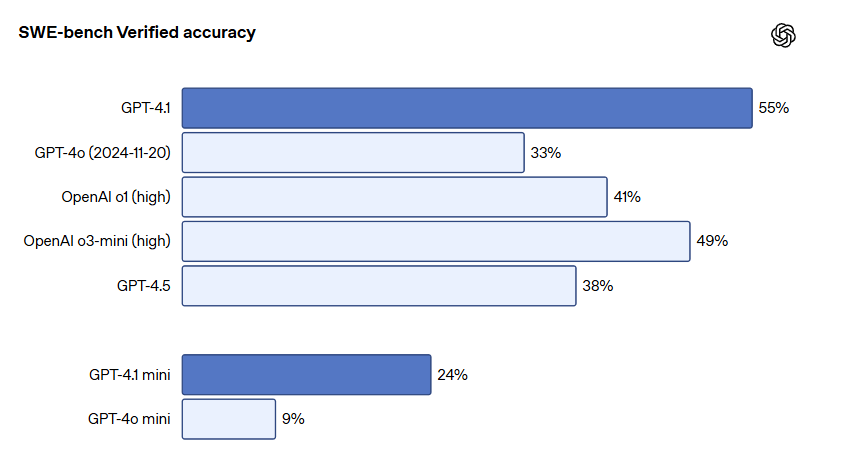 |
| 指示追従(MultiChallenge) | GPT-4.1:38.3%(GPT-4o:27.8%) 複数の会話で指示内容を維持する能力が向上  |
| 長文コンテキスト理解(Graphwalks BFS) | GPT-4.1:61.7%(GPT-4o:41.7%) 複数の論理ステップを必要とする長文脈内での推論能力が向上 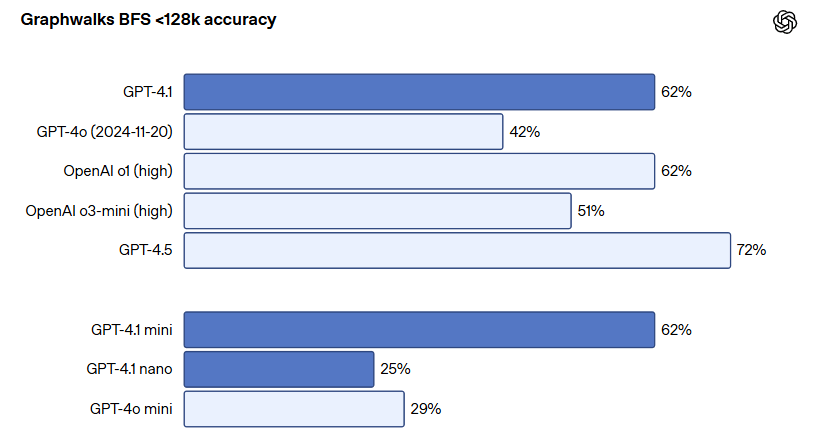 |
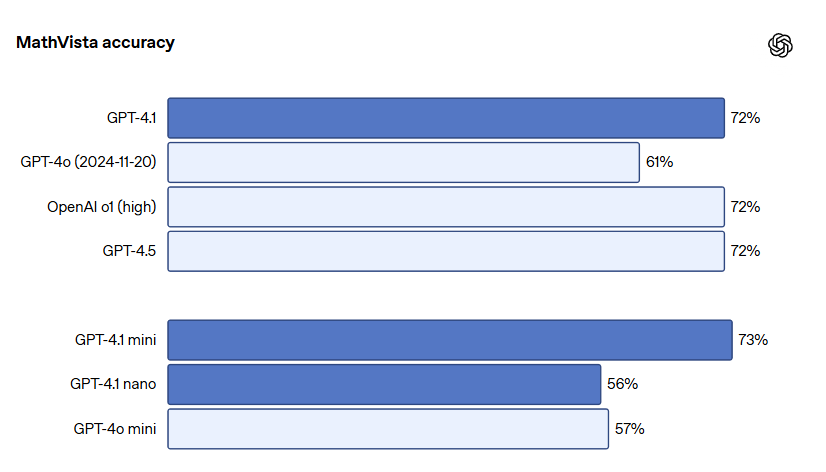
| マルチモーダル(MathVista) | GPT-4.1:72.2%、GPT-4.1 mini:73.1%(GPT-4o:61.4%) 画像を含む数学問題の解決能力が向上  |
それぞれの賢さを比較した表が以下の通りです。
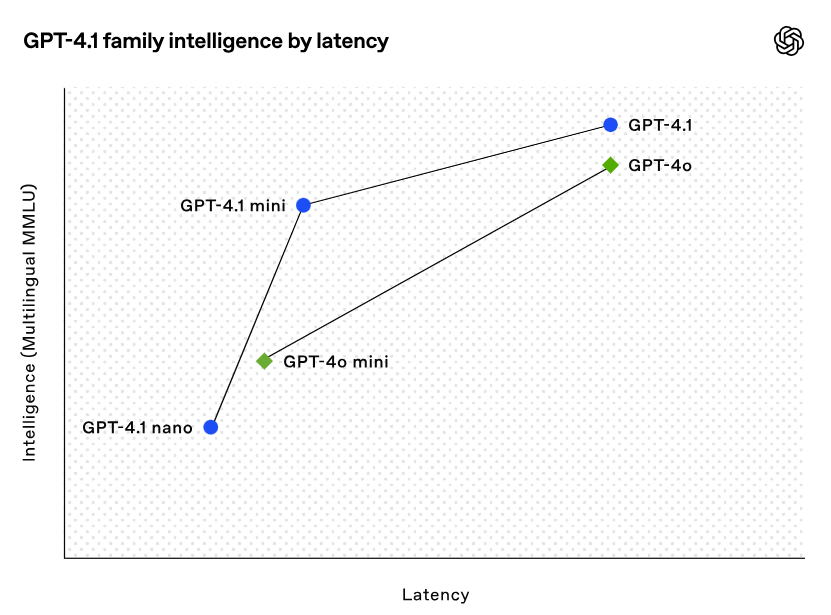
特筆すべきは、GPT-4.1 miniが多くのベンチマークでGPT-4oを上回っているという点です。また、競合モデルとの比較してみると、特にコーディングにおいてGoogleのGemini 2.5 ProやAnthropicのClaude 3.7 Sonnetが上回っていますが、総合的なバランスとコスト効率においてGPT-4.1シリーズはかなりの優位性を持っていると言えます。
GPT4.1の特徴①:圧倒的なコーディング能力の向上
GPT-4.1シリーズの最も大きな特徴のひとつが、コーディング能力の飛躍的向上です。ソフトウェアエンジニアリングスキルを測定するSWE-bench Verifiedでは、GPT-4.1は54.6%のタスク完了率を達成し、GPT-4oの33.2%から21.4%ポイントも向上したんです!
具体的にどのような点が改善されたかと言うと、
- コードリポジトリの探索能力:大規模コードベースを効率的に理解し、必要な箇所を見つけられるように
- タスク完了能力:複雑なコーディングタスクを最後まで実行可能に
- 実行可能なコード生成:より正確に動作し、テストにパスするコードを生成
- diff形式の精度向上:コード差分の形式に従う能力が2倍以上に向上(Aider’s polyglot benchmarkで実証)
- 不要な編集の減少:GPT-4oと比較して不要なコード編集が9%から2%に減少
このような点がGPT-4oから進化しました。
そして、ウェブアプリ開発においても大きな改善が見られています。OpenAIの評価では、同じプロンプトに対してGPT-4.1が生成したWebサイトが、GPT-4oのものより80%のケースで優れていると評価されました。HTML/CSS/JavaScriptを駆使したUIの生成能力が大幅に向上しています。
- Windsurf社:内部コーディングベンチマークでGPT-4oより60%高いスコアを記録。ユーザーからは、ツール呼び出しが30%効率的になり、不要な編集の繰り返しが約50%減少したと報告
- Qodo社:実際のGitHubプルリクエストのコードレビューで55%の改善を確認
このような大幅な性能向上によって、開発者の生産性向上や、これまで難しかった複雑なコード生成タスクの自動化が現実のものとなりました!
GPT4.1の特徴②:指示追従性能と複雑な命令への対応力
GPT-4.1シリーズのもう一つの大きな特徴は、与えられた指示に対してより正確に従う能力の向上です。特に複雑な指示や多段階の指示を理解し、実行する能力が大幅に改善されました!
OpenAIは開発者からのフィードバックに基づき、以下のカテゴリを含む内部評価セットを開発し、性能向上を確認しています。
- フォーマット追従:XML、YAML、Markdownなど指定されたカスタムフォーマットでの応答
- 否定指示:行うべきでない行動の指定への対応
- 順序指示:指定された順序で実行すべき一連の指示への対応
- 内容要件:特定の情報を含めるよう指示された内容の遵守
- ランキング:特定の方法での出力の並べ替え
- 過信抑制:不明な情報に対し「わからない」と適切に回答する能力
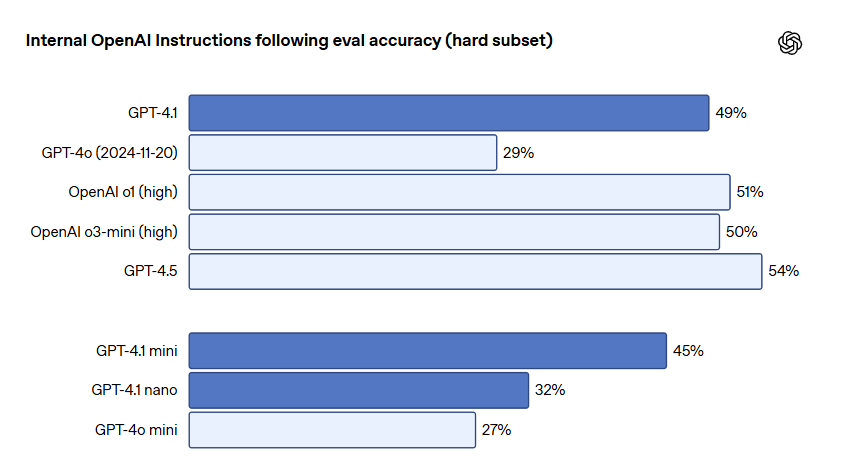
特に難しい(hard)プロンプトにおいて、GPT-4.1はGPT-4oと比較して大幅に改善しています(内部評価スコア: 49% vs 29%)。
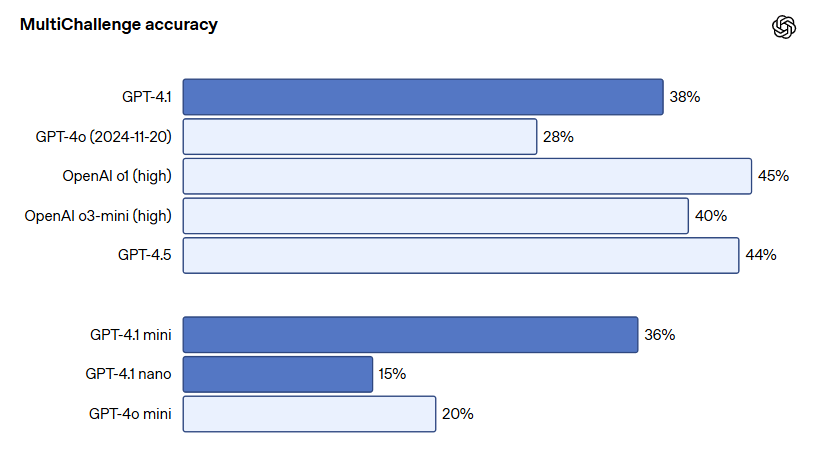
そして、複数回にわたる会話においても、過去の発言内容やプロンプトを記憶し、追従する能力が向上しています。Scale AIが提供するMultiChallengeベンチマークでは、GPT-4.1は38.3%のスコアを記録し、GPT-4o(27.8%)から10.5%ポイント向上しました。
また、応答の長さ、特定の単語やフォーマットの回避など、客観的に検証可能な指示への準拠能力を測るIFEvalベンチマークにおいても、GPT-4.1は87.4%と、GPT-4o(81.0%)から改善を見せています。

- Blue J社:最も難しい税務の内部ベンチマークで、GPT-4.1がGPT-4oより53%正確であることを確認
- Hex社:複雑なSQLクエリ評価セットで約2倍の改善を達成。特に大規模で曖昧なスキーマから正しいテーブルを選択する能力が向上
このような指示追従性の向上により、既存アプリの信頼性が高まるだけでなく、これまで難しかった新しい応用も可能になっています!
GPT4.1の特徴③:驚異の100万トークン対応
GPT-4.1シリーズの最大の特徴の一つが、100万トークン(約75万語に相当)という圧倒的なコンテキスト処理能力です。これは今までのGPT-4oの128,000トークンから約8倍もの拡張となり、大規模な文書やコードベース全体を一度に処理することが可能になりました!
100万トークン分の文書データのどこかにある短い文字列(Needle)を正確に検索・抽出できるかを評価するテストでは、GPT-4.1ファミリーはいずれも高い成功率を示しています。ドキュメントの先頭・中盤・末尾どこに配置しても問題なく情報を検索できることが確認されました。
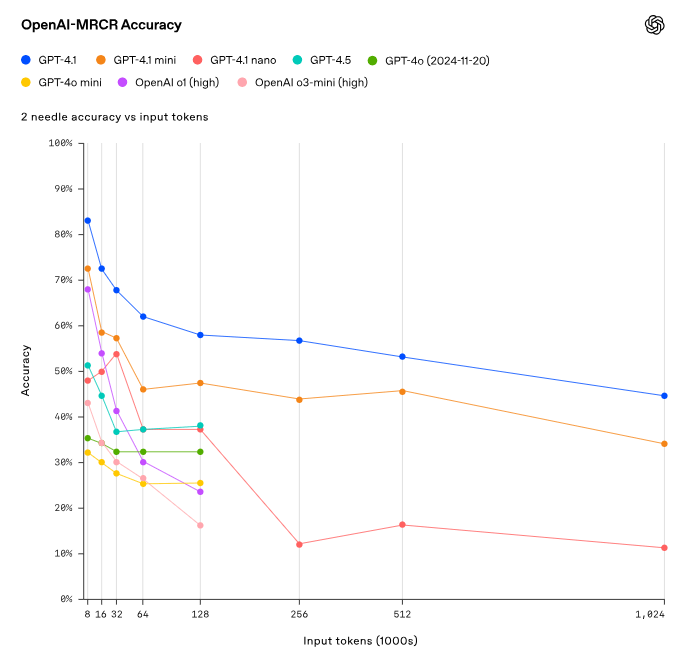
さらに複雑な長文コンテキスト処理能力を評価するOpenAI MRCRベンチマークでは、GPT-4.1は100万トークンのコンテキストでも46.3%という高いスコアを維持しており、長文での情報検索能力の高さを示しました。
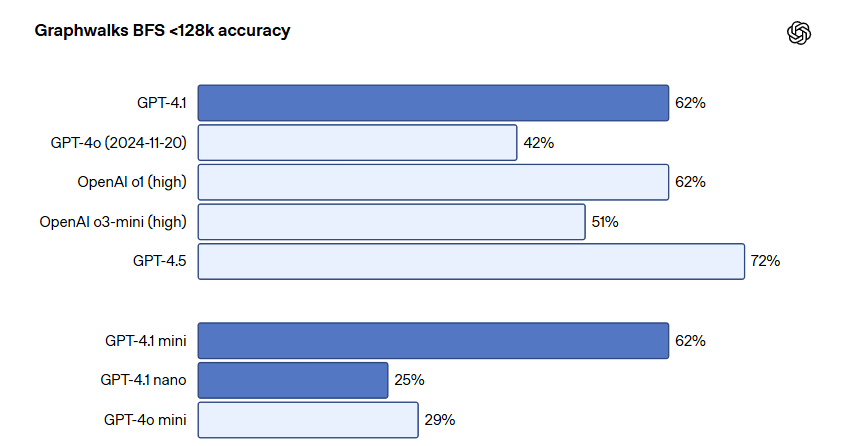
モデルが大きなグラフ内のランダムなノードからの幅優先探索(BFS)を実行する能力を測るテストでは、GPT-4.1は61.7%のスコアを達成し、GPT-4o(41.7%)から大幅に向上しています。
- Thomson Reuters社:法務AIアシスタント「CoCounsel」において、複数文書レビューの精度が17%向上。文書間の微妙な関係(矛盾する条項や補足的なコンテキストなど)を正確に特定できるように
- Carlyle社:長大で複雑な文書(PDF、Excelファイルなど)からの詳しい財務データ抽出が50%向上。「針の中の干し草」のような検索や「途中で迷子になる」などのエラーを克服
このように100万トークン対応は、法律文書の分析、大規模コードベースの処理、研究論文の理解など、これまで人間の介入が必要だった複雑なタスクの自動化を可能にしました!
GPT4.1の特徴④:マルチモーダル能力
GPT-4.1シリーズはテキスト処理だけでなく、画像や動画といったマルチモーダルコンテンツの理解においても大きな進歩を遂げているんです!
マルチモーダル理解力を測定する各種ベンチマークでは、GPT-4.1シリーズが従来モデルを大きく上回る結果を示しています。
- MMMU:GPT-4.1は74.8%(GPT-4oは68.7%)

- MathVista:GPT-4.1は72.2%、GPT-4.1 miniは73.1%(GPT-4oは61.4%)
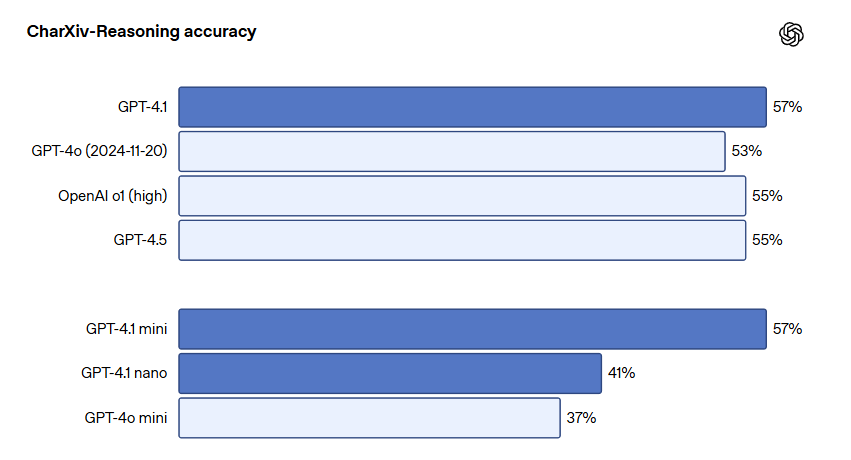
- CharXiv-Reasoning:GPT-4.1は56.7%(GPT-4oは52.7%)
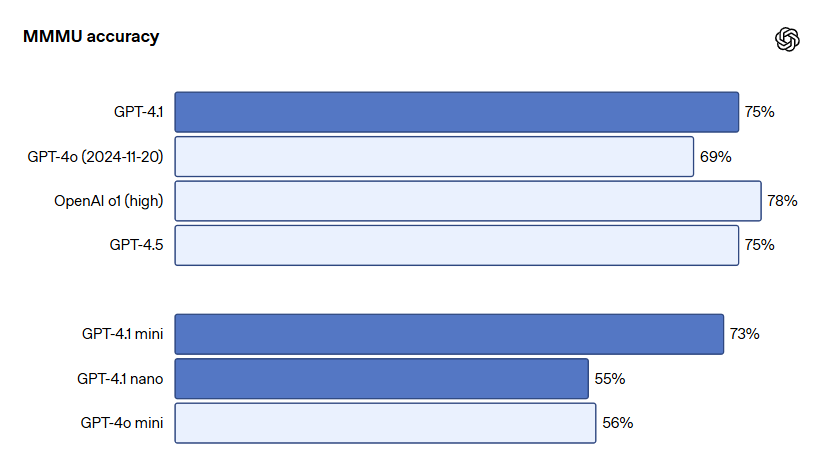
特に注目すべきなのは、GPT-4.1 miniが画像理解ベンチマークにおいてフラッグシップモデルを上回る場面もあるという点です。これは、中型モデルでもマルチモーダル処理に十分な性能を持つことを示していて、コスト効率の高い処理に向いています。
また、GPT-4.1は動画コンテンツの理解においても大きな進歩を遂げています。Video-MMEベンチマーク(字幕なしの30〜60分のビデオに基づく質問に回答)では、GPT-4.1は72.0%のスコアを達成し、GPT-4o(65.3%)を6.7%ポイント上回りました。

これによって、長時間の動画コンテンツから情報を抽出したり、時系列で展開される視覚情報を理解して質問に答えたりする能力が大幅に向上しています。教育コンテンツの分析や動画監視、メディアコンテンツの要約など、さまざまな応用が可能になりました!
GPT-4.1の料金プラン
GPT-4.1シリーズは、高性能でありながらも今までのモデルよりも低コストで提供されています!
| モデル | 入力料金 | キャッシュされた入力 | 出力料金 | ブレンド価格 |
|---|---|---|---|---|
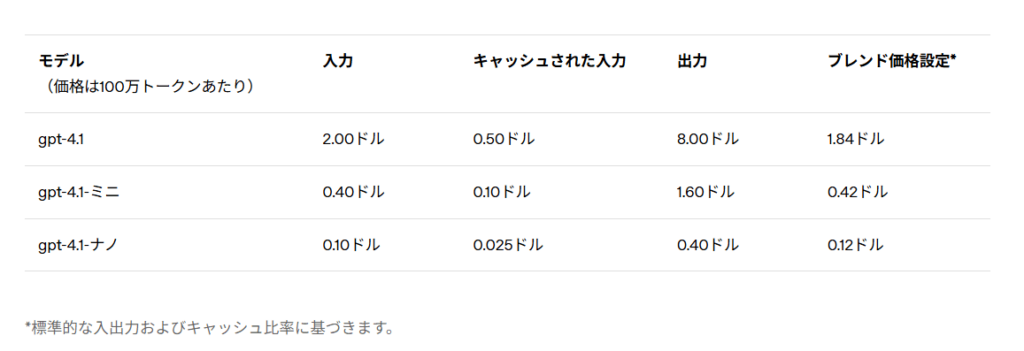
| GPT-4.1 | 2ドル | 0.5ドル | 8ドル | 1.84ドル |
| GPT-4.1 mini | 0.4ドル | 0.1ドル | 1.6ドル | 0.42ドル |
| GPT-4.1 mini | 0.1ドル | 0.025ドル | 0.4ドル | 0.12ドル |
GPT-4.1はGPT-4oと比較して平均26%のコスト削減を実現しています。特にGPT-4.1 miniは大幅なコスト削減(GPT-4oより83%減)を達成しながらも、多くのタスクでGPT-4oを上回る性能を発揮してくれます!
他の主要競合モデルとの価格も比較してみました。
| モデル | 入力料金(100万トークンあたり) | 出力料金(100万トークンあたり) |
|---|---|---|
| GPT-4.1 | 2ドル | 8ドル |
| Claude 3.7 Sonnet | 3ドル | 15ドル |
| Gemini 2.5 Pro | 1.25ドル(〜20万トークン) 2.5ドル(20万トークン超) | 10ドル(〜20万トークン) 15ドル(20万トークン超) |
| Grok-3 | 3ドル | 15ドル |
やはり他のツールと比べても圧倒的にコストパフォーマンスが良いです!
また、GPT-4.1シリーズではコスト削減のための特別機能も用意されているんです。
- プロンプトキャッシング:同じコンテキストを繰り返し使用する場合の割引が50%から75%に拡大
- 長文コンテキスト:100万トークンまでのコンテキスト対応に追加料金なし
- Batch API:一度に多くのリクエストを処理するバッチ処理では、さらに50%の追加割引
このような料金設定によって、GPT-4.1シリーズは高性能AIモデルへ利用をより安く、特にGPT-4.1 nanoは大規模なAI導入を計画する企業や開発者にとって画期的な選択肢となりますね!
GPT-4.1の使い方
GPT-4.1シリーズは2025年4月15日現在、API経由でのみ利用可能で、ChatGPTのウェブアプリやモバイルアプリでは直接利用できません。
以下の方法でGPT-4.1にアクセスできます。
- STEP1OpenAIのAPI Playgroundや、独自アプリケーションからAPIを呼び出して利用
- GPT-4.1:
gpt-4.1 - GPT-4.1 mini:
gpt-4.1-mini - GPT-4.1 nano:
gpt-4.1-nano
- GPT-4.1:
- STEP2主要開発ツールで使う
- GitHub Copilot:全プラン(無料プラン含む)でパブリックプレビューとして利用可能
- GitHub Models:Playgroundなどで他のモデルと比較試用可能
- Windsurf:発表後1週間、無料トライアル提供(レート制限あり)
- Cursor:全ユーザーが利用可能(当面は無料提供)
ChatGPTでは直接GPT-4.1を選択することはできませんが、GPT-4oモデルに以下のような改善点が段階的に組み込まれています。
- コーディング能力の向上
- 指示追従性の改善
- 推論能力の強化
この改善は常に行われていくそうで、ChatGPTユーザーも間接的にGPT-4.1の恩恵を受けることができます!
そして、特定のタスクや領域に特化したモデルを作成したい開発者向けに、ファインチューニングも提供されています。
- GPT-4.1 / GPT-4.1 mini:発表と同時にファインチューニングに対応済み
- GPT-4.1 nano:近日中にファインチューニング対応予定
ファインチューニングによって、特定のドメイン知識や専門用語、フォーマット要件に合わせたカスタムモデルを作成することが可能です!
GPT-4.1の導入事例3選
GPT-4.1の実力は、すでに複数の企業や組織での実証例によって裏付けられているんです。
ここでは、早期アダプターとしてGPT-4.1を導入した企業の事例を3つご紹介します!
事例①:Windsurfでのコーディング支援強化
AI駆動のIDE(統合開発環境)を提供するWindsurf社は、GPT-4.1を内部コーディングベンチマークでテストし、GPT-4oと比較して60%性能が向上したと報告しています。
- ツール呼び出しの効率が30%向上
- 不要なファイルの読み込みが40%減少
- 不要なファイルの変更が70%減少
- 出力の冗長性が50%低減
これによって、開発者の生産性と作業効率が大幅に向上しました!
事例②:Thomson Reutersの法務AI強化
法務情報サービス大手のThomson Reutersは、法務AIアシスタント「CoCounsel」にGPT-4.1を導入し、複数文書レビューの精度が17%向上したことを確認しました。
- 文書間の矛盾点や補完関係の特定が正確に
- 大量の法律文書からの関連情報抽出が効率化
- 複雑な法的要件の理解と遵守が向上
これによって、法務専門家の作業効率化と、より正確な法的分析が可能になりました!
事例③:Carlyleの財務データ分析
投資会社Carlyleでは、GPT-4.1を使って複数の長文(PDF、Excelファイルなど)から詳細な財務データを抽出する作業を効率化。内部評価では、データ抽出精度が50%向上したとのことです。
- 大規模文書からのデータ検索が大幅に改善
- 文書間での複数ホップ推論(文書A→文書B→文書Cと情報をつなげる)が可能に
- 従来のモデルでは難しかった「針の中の干し草」型の検索タスクに成功
以上の3つの事例は、GPT-4.1が性能向上にとどまらず、実務における具体的な課題解決に大きく貢献していることが分かりますね!
GPT-4.1の活用方法
ここでは、X(旧Twitter)で「GPT-4.1はこんな活用方法があるよ」というポストをいくつか発見したので、みなさんの参考になればという思いでご紹介いたします!
①論文のサポート
冒頭でもお話しした通り、GPT-4.1はコーディングや長文に特化しているので、本格的な文章作成に向いています。論理的な思考もバッチリできるということなので、論文作成や分析にぴったりですね!
②開発者向けのプログラミングサポート
GPT-4.1は非推論モデルなので、開発者におすすめのモデルとなっています。何といっても指示への忠実さが向上しているということですので、指示通りに迷いなく素早く動いてくれるという点が魅力です。
GPT-4.5 Previewの廃止について
OpenAIは、GPT-4.1の発表に伴って、これまでAPI経由で研究プレビュー版として提供されていた「GPT-4.5 Preview」モデルの廃止を発表しました。
GPT-4.5廃止の理由と背景としては、
- GPT-4.1の優位性:GPT-4.1が多くの主要機能においてGPT-4.5と同等またはそれ以上の性能を、より低いコストとレイテンシで提供できるようになった
- リソースの最適化:需要の高いGPUリソースを、より広く利用されるGPT-4.1ファミリーや将来の研究開発に割り当てるため
以上の2点が考えられています。終了予定日は「2025年7月14日」となっており、移行期間として約3ヶ月の猶予期間を設定しています。
まとめ
いかがでしたでしょうか?
OpenAIが2025年4月に発表した最新モデル「GPT-4.1」シリーズの全容、活用法について詳しくご紹介しました!
この記事で紹介したことをまとめると次のようになります。
- 3つのモデルバリエーション:用途と予算に合わせてGPT-4.1、GPT-4.1 mini、GPT-4.1 nanoから選択可能
- 圧倒的なコーディング能力:SWE-benchで54.6%を達成し、GPT-4oから21.4%ポイント向上
- 正確な指示追従:複雑な指示や多段階の指示を的確に実行
- 100万トークン対応:大規模文書やコードベースの一括処理が可能に
- 優れたコスト効率:GPT-4oより平均26%のコスト削減を実現
- プロンプトキャッシング強化:同一コンテキストの再利用で75%のコスト削減
GPT-4.1シリーズは、特に開発者やエンタープライズ向けに設計されており、API経由でのみ利用可能です。ChatGPTを利用している方も、GPT-4.1の改善点がGPT-4oに段階的に組み込まれることで、その恩恵を享受できるのでご安心ください!
ぜひ、GPT-4.1シリーズの驚きの性能を試してみてくださいね。
romptn ai厳選のおすすめ無料AIセミナーでは、AIの勉強法に不安を感じている方に向けた内容でオンラインセミナーを開催しています。
AIを使った副業の始め方や、収入を得るまでのロードマップについて解説しているほか、受講者の方には、ここでしか手に入らないおすすめのプロンプト集などの特典もプレゼント中です。
AIについて効率的に学ぶ方法や、業務での活用に関心がある方は、ぜひご参加ください。
\累計受講者10万人突破/

