
Stable Diffusionで生成した人物を、Stable Diffusion上で動画化し、喋らせることができたら便利なのになと感じることはないでしょうか?
実は、『SadTalker』という拡張機能を使うことで、Stable Diffusionを使ってAIの人物に喋らせることが可能になります。
そのため、今回は、『SadTalker』という拡張機能のインストール方法や、使い方などについて詳しく解説していきたいと思います。
内容をまとめると…
SadTalkerは1枚の人物画像と音声データを組み合わせて、AIキャラクターに喋らせることができる拡張機能
専用モデルのダウンロード・checkpointsパスの設定・FFmpegの導入という3つの事前準備が必要
使い方は画像と音声をアップロードしてGenerateを押すだけで、表情やポーズなど7つの設定項目で細かい調整も可能
expression scaleで表情の大きさ、preprocessで画像サイズ、Still Modeで動きの安定化など、生成結果を細かくコントロールできる
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

拡張機能「SadTalker」とは?
まずは、「SadTalker」という拡張機能が一体どのようなものなのかについて、詳しく解説していきたいと思います。
「SadTalker」とは、1枚の画像と音声データを結びつけて、画像に3次元的な動きをさせることができる拡張機能です。
音声データから顔の動きを予測し、AIで生成した人物の表情を変化させ、喋らせることができるという原理になっています。
拡張機能「SadTalker」の導入方法
続いて、「SadTalker」の導入方法について解説していきたいと思います。
「SadTalker」のインストール手順は、以下のとおりです。
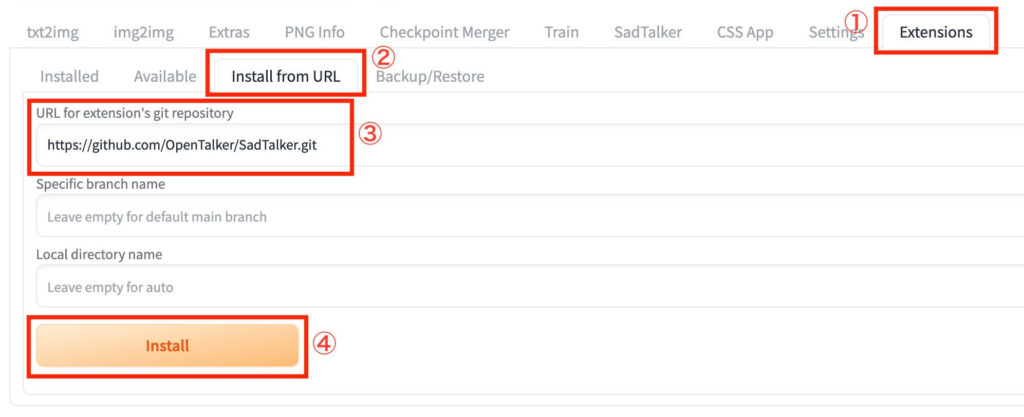
- Stable Diffusionを起動し、「Extensions」タブを開く
- 「Install from URL」をクリックする
- 「URL for extension’s git repository」に「https://github.com/OpenTalker/SadTalker.git」と入力する
- 「Install」をクリックする
インストールが完了したら、Stable Diffusionを再起動してください。
ただし、「SadTalker」は拡張機能のインストールの他にも、いくつか準備しなければならない項目があります。
そのため、以下ではそれらの項目の準備方法について1つずつ解説していきます。
モデルのダウンロード方法
まず、「SadTalker」を使用するには、専用のモデルをダウンロードする必要があります。
モデルファイルのダウンロードなどの手順は以下のとおりです。
- こちらからモデルを全てダウンロードする
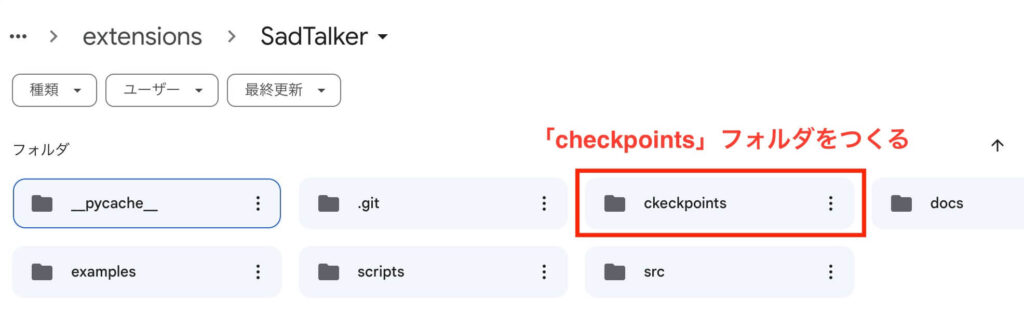
- ダウンロードが完了したら、「stable-diffusion-web-ui」フォルダ内の「Extensions」フォルダにある「SadTalker」フォルダを開く
- 「SadTalker」フォルダ内に「checkpoints」というフォルダを新しくつくる
- ダウンロードした専用モデルを、全てそのフォルダ内にアップロードする

Stable Diffusionにcheckpointsへのパスを教える方法
「SadTalker」の専用モデルを全てダウンロードし、「checkpoints」へのアップロードが完了したら、次は、Stable Diffusionに「chekpoints」へのパスを教える必要があります。
パスを教えるための手順は、以下のとおりです。
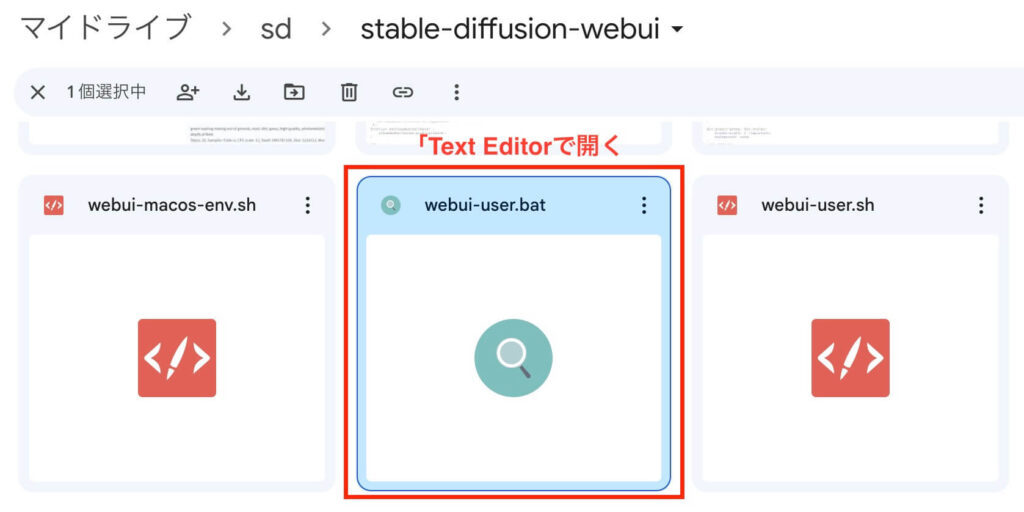
- 「stable-diffusion-web-ui」フォルダ内の「webui-user.bat」というファイルを「Text Editor」で開く
- 「PYTHON=」の下に新しく行をつくり、「set SADTALKER_CHECKPOINTS=」と入力する
- 「set SADTALKER_CHECKPOINTS=」の続きに「checkpoints」フォルダのパスを入力する
- 変更を保存する

「FFmpeg」の導入方法
続いて、動画や音声を「SadTalker」を通じて再生するために、「FFmpeg」の導入が必要となります。
「FFmpeg」の導入方法は「Windows」、「Linux」、「MacOs」で異なっているため、1つずつ解説していきます。
「Windows」での導入方法
- 「FFmpeg」の公式ページから、「Download」ボタンをクリックする
- 「Windows」マークから「Windows builds by BtbN」にカーソルを合わせ、ダウンロードする
- ダウンロードした「zipファイル」を解凍する
- 「ffmpeg-N-99880-g8fbcc546b8-win64-gpl-shared」を開く
- 「bin」を開く
- アドレスバーをクリックし、「bin」のパスをコピーする
- システムの詳細設定を開く
- 詳細設定を開く
- 環境変数(N)…をクリックする
- ユーザー環境変数をクリックする
- 「Path」をクリックする
- 編集をクリックする
- 新規をクリックする
- 「bin」のパスを貼り付ける。
- 「OK」をクリックする
- 「cmd」を入力して「Enter」キーを押す
- 「ffmpeg -version」コマンドプロンプトにコピー&ペーストして「Enter」キーを押す
「Linux」での導入方法
- 「FFmpeg」の公式ページから、「Download」ボタンをクリックする
- 「Linux Static Builds」欄の下にある 「32-bit and 64-bit for kernel 3.2.0 and above」をクリックする
- 「release」 から自分のOSに合ったものをダウンロードする
- コマンドラインから「$ unxz -c ffmpeg-release-amd64-static.tar.xz | tar xvf -」を使ってファイルを解凍する
- コマンドラインから以下のコマンドを使って、パスに追加する
$ export PATH=~/ffmpeg-4.3.1-amd64-static:$PATH
$ which ffmpeg ~/ffmpeg-4.3.1-amd64-static/ffmpeg
$ ffmpeg -version ffmpeg version 4.3.1-static https://johnvansickle.com/ffmpeg/ Copyright (c) 2000-2020 the FFmpeg developers「MacOS」での導入方法
- 「FFmpeg」の公式ページから、「Download」ボタンをクリックする
- 「Mac」マークから「static builds for macOS 64-bit」にカーソルを合わせ、クリックする
- 「FFmpeg-6.1 7z」の「zipファイル」をダウンロードする
- ダウンロードしたファイルを解凍する
- ターミナルを起動し、解凍したファイルをドラックする
- 「ffmpeg-h」を入力する
拡張機能「SadTalker」の使い方
続いて、「SadTalker」の具体的な使い方について解説していきます。
「SadTalker」の使用手順は、以下のとおりです。
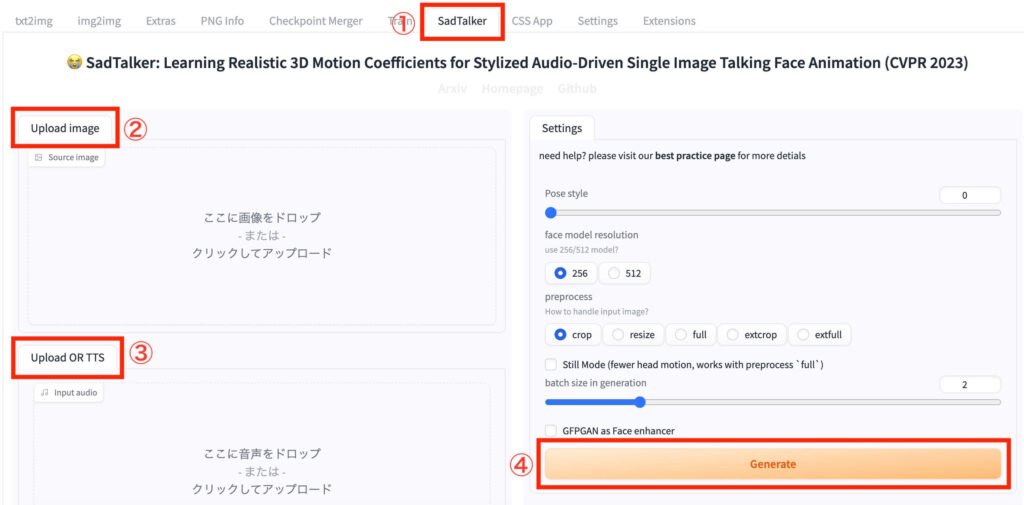
- Stable Diffusionを起動し、「SadTalker」タブを開く
- 「Upload image」に人物の画像をアップロードする
- 「Upload OR TTS」に音声データをアップロードする
- 「Generate」をクリックする
以上の手順を踏むことで、簡単に画像に喋らせることが可能となります。
それでは、実際にAI美女を生成して、「こんにちは。」と喋らせてみましょう。
今回使用する画像は以下です。

また、この画像を生成するために使用したプロンプトは以下です。
・プロンプト
1woman, 25 years old, green long hair
・ネガティブプロンプト
Easy negative, worst quality, poorly eyesまずは、上記の画像を「Upload image」にアップロードします。
次に、「こんにちは。」という音声データを「Upload OR TTS」にアップロードします。
そして「Generate」をクリックします。
すると、動画が生成されます!
拡張機能「SadTalker」の設定項目
また、先ほどご紹介した4つの手順を踏むだけでAI画像に喋らせることは可能ですが、以下の設定項目を編集することで、より詳細に生成結果を操作することができます。
①Pose Style
数値を変更することでポーズを46種類の中から選ぶことができます。
②expression scale
表情をどのくらい大きく動かすのかを調整することができます。
数値を大きく設定するほど、表情の動きが大げさになっていきます。
③face model resolution
画像の解像度を「256」と「512」のうちから選ぶことができます。
自分の使いたい数値の方を選んでください。
ただし、「512」を選択すると、解像度が向上するかわりに動きが崩れてしまう場合があります。
④preprocess
生成する画像のサイズを選ぶことができます。
「crop」は顔の部分のみを切り取って動画を生成することができます。
「resize」は元の画像のサイズを自動で再設定して動画を生成することができます。
「full」は元の画像のサイズをフルで使用して動画を生成することができます。
ただし、「full」を選択すると、肩から上の部分で動きが切れてしまうことがあります。
この問題については、次の「Still Mode」で解決することができるようになります。
⑤Still Mode
チェックを入れることで、手の動きが少なくなります。
「preprocess」で「full」を選択した場合のみ、効果が適用されます。
「Still Mode」をオンにすることで、肩から上の部分で動きが切れてしまう問題を解決することができます。
⑥batch size in generation
スライダーを動かすことで、生成した画像のバッチサイズを自由に選択することができます。
基本的にデフォルトの設定のままで問題ありません。
⑦GFPGAN as Face enhancer
生成に時間がかかるようになりますが、チェックを入れることで画像がぼやけるのを修正することができます。
まとめ
いかがでしたでしょうか?
今回は、Stable Diffusionを使ってAIの人物に喋らせることが可能になる拡張機能「SadTalker」について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 「SadTalker」は、1枚の画像と音声データを結びつけて、画像に3次元的な動きをさせることができる拡張機能である。
- 「SadTalker」の導入方法は、【「Extensions」タブを開く】→【「Install from URL」をクリックする】→【「URL for extension’s git repository」に「https://github.com/OpenTalker/SadTalker.git」と入力する】→【「Install」をクリックする】である
- 「SadTalker」を使うために必要な項目は、【モデルの導入】、【Satble Diffusionへ「checkpoints」へのパスを教える】、【「FFmpeg」の導入】である
- 「SadTalker」の使用手順は、【「SadTalker」タブを開く】→【「Upload image」に画像をアップロードする】→【「Upload OR TTS」に音声データをアップロードする】→【「Generate」をクリックする】である
- 「SadTalker」には、「Pose Style」、「expression scale」、「face model resolution」、「preprocess」、「Still Mode」、「batch size in generation」、「GFPGAN as Face enhancer」という7つの設定項目がある
「SadTalker」を使うことで、AI画像にさまざまな言語を喋らせることができるようになります。
ぜひ活用してみてください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

