
Stable Diffusionでの画像生成になれてくると、「自分でLoraを作成してみたい!」「同じ絵柄やキャラクターで、異なった背景・服装などの画像を生成したい!」と思う方は多いのではないでしょうか?
でも、自分で追加学習させるって難しそうに感じてなかなか手が出せないですよね。
そんな方のために、追加学習モデル『Lora』の作成方法を詳しく解説していきますので、是非参考にしてください!
内容をまとめると…
LoRA(Low-Rank Adaptation)は少ない計算量で既存モデルに追加学習させ、特定の画風やキャラクターを再現できる仕組み
Google Colabの「Kohya-Trainer」を使えば低スペックPCでもLoRA学習が可能で、12枚程度のJPG画像を用意すればOK
Waifu Diffusion Taggerでタグを自動付与・剪定し、学習させたい特徴だけを残してトレーニングする流れ
版権キャラのLoRAは商用利用を避けて個人利用にとどめることが重要
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

追加学習とは?
Stable Diffusionにはさまざまなモデルがあり、それらを使って呪文(プロンプト)を入力することによって、思い描いたようなAI画像を生成するという仕組みです。
しかし、そんな便利な画像生成にも限界があります。
例えば、版権キャラや既存の衣装・画風などを画像生成で表現させたい場合、呪文(プロンプト)だけではなかなか生成しづらくなってしまいますよね。
そんな時に大活躍してくれるのが、『Lora』という既存のモデルに対して、持ち合わせている画像(版権キャラや既存の衣装・画風などのもの)を追加学習させるモデルです。
『Lora』とは?
『Lora』とは、“Low-Rank-Adaptation”の略で、非常に少ない計算量で追加学習ができるモデルという意味です。
従来のAIの学習においては、ものすごい量の計算が必要で、高性能なパソコンと時間が必要不可欠な状態でした。
しかし、『Lora』が開発されたことでだれでも手軽に追加学習をすることができるようになりました!
※『Lora』の概要や使い方についてさらに詳しく知りたい方は以下の記事を参考にしてください。

『Lora』を利用するメリット
『Lora』を利用するメリットとして、以下が挙げられます!
①イラストの画風を調整することができる
②人物やキャラクターを指定して画像を生成することができる
③自分の好きな服装・髪型・背景・ポーズなどにできる
①イラストの画風を調整することができる
『Lora』を利用することで、生成される画像のスタイルをアニメ風やカートゥーン風、3D風などに調整することができます。
②人物やキャラクターを指定して画像を生成することができる
『Lora』を利用することで、同一人物・同一キャラクターの画像を複数枚生成できます。
③自分の好きな服装・髪型・背景・ポーズなどにできる
特定の服装・背景・髪型・ポーズなどを生成できる『Lora』もありますので、積極的に利用していくと効率的です!
【Lora】追加学習させる方法
では、追加学習させて『Lora』を作成する方法について詳しく説明していきます!
追加学習させる前に:学習させたい画像を準備する
今回は、2次元のイラストを学習させていきます。
フリー素材のイラストを何枚か用意しました。上半身の方が学習させやすいです。

これらの画像をzipファイルにまとめて、Googleドライブにアップロードします。

追加学習させる方法①:Google Colab用の「Kohya-Trainer」をコピー

上記のリンク先にアクセスし、1番上の「Kohya Lora Dreambooth」の「Open in Colab」リンクをクリックします。

そうするとノートブックが表示されますので、「ドライブにコピー」をクリックして、マイドライブに保存しておきましょう。
新しいタブで開かれますが、そちらを使うようにしてください!
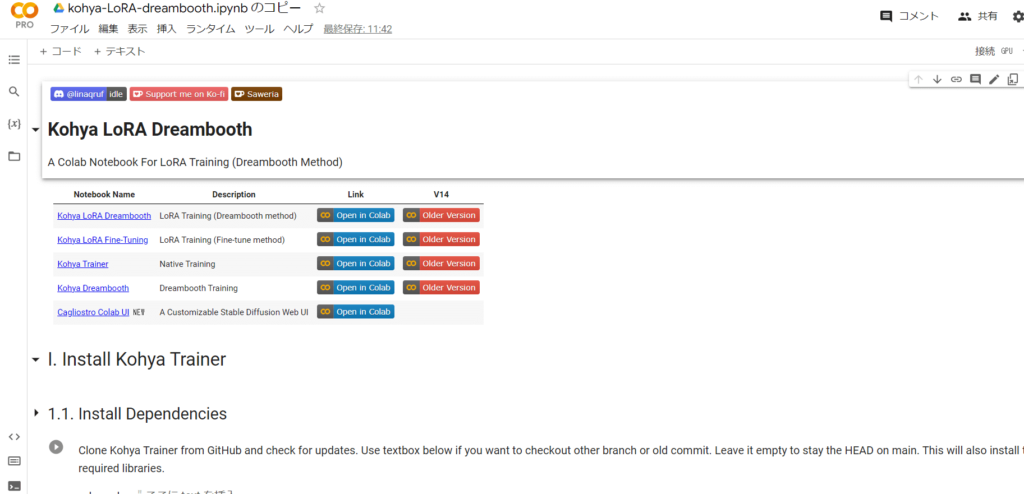
いつも通り、ランタイムに接続して上から実行ボタンを押していきましょう。
※Google Colabの使い方については、以下の記事を参考にしてください。

追加学習させる方法②:Googleドライブのマウントとビルド設定
初期設定の状態では、マイドライブに読み書きすることはできなくなっています。
「mount_drive」にチェックを入れてから実行ボタンを押してください。
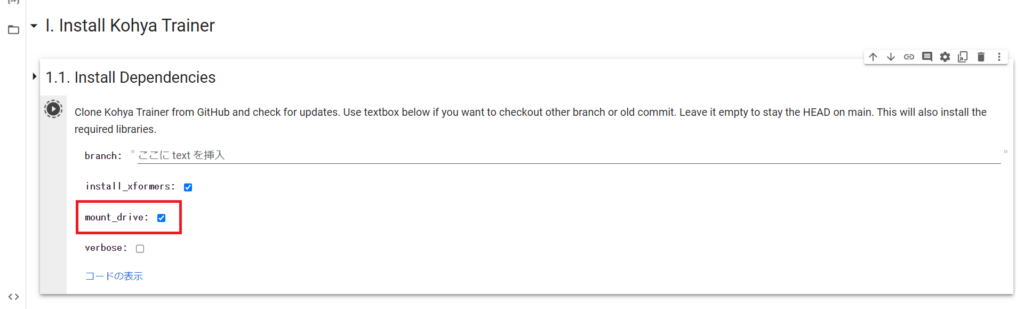
以下のような表示が出ますので、アカウントを選択して許可をしてください。
およそ5分ほどかかります。
追加学習させる方法③:学習に使うモデルをダウンロード
今回は、デフォルトにある「Animefull-final-pruned」を使います。
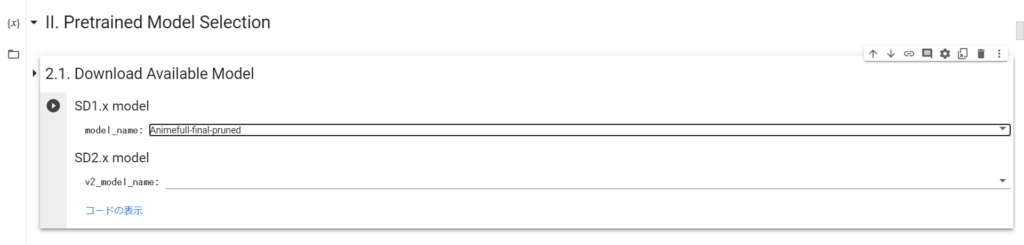
続いて「3.1.Locating Train Data Directory」を実行し、トレーニングデータが入るディレクトリを指定します。
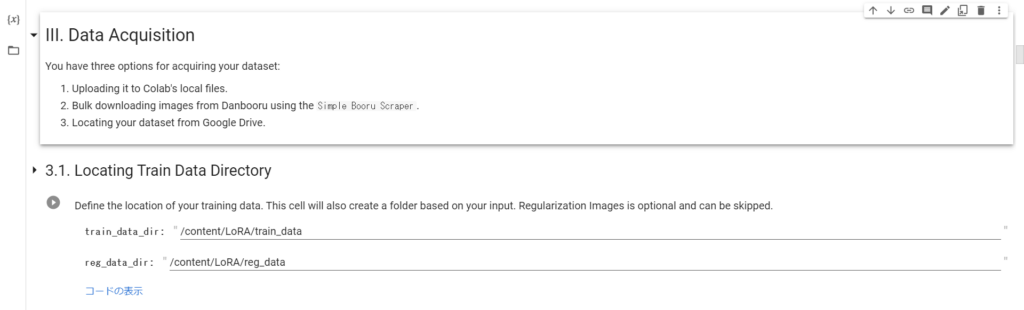
追加学習させる方法④:zipファイルを解凍する
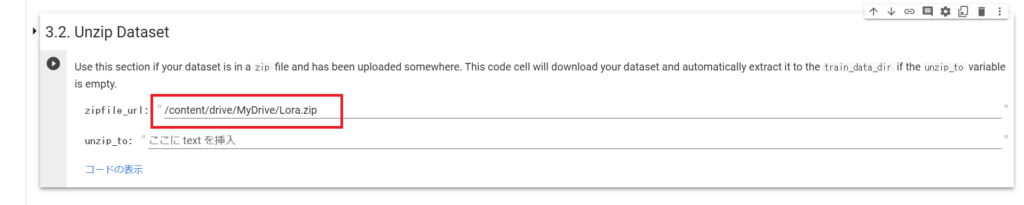
「3.2. Unzip Dataset」で、先程アップロードしたzipファイルを解凍します。
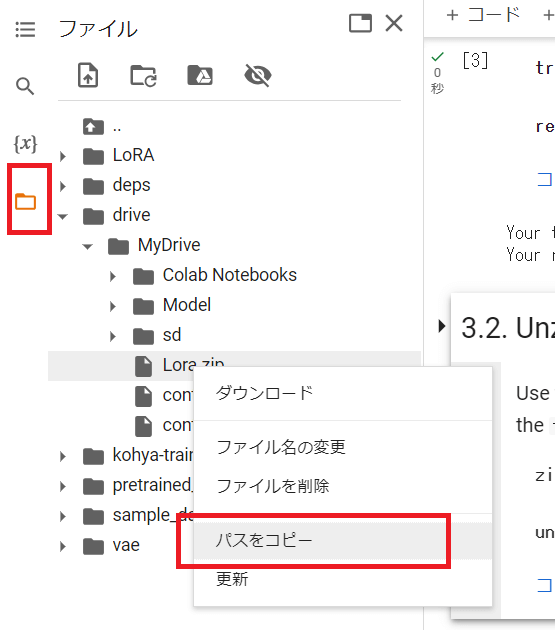
左側のファイルアイコンからzipファイルを探し、右クリックで「パスをコピー」して『zipfile_url』に張り付けてください。
追加学習させる方法⑤:タグを剪定する
BLIPとWaifu Diffusionの2つがありますが、「Tagger」という機能でタグを整理していきます。
まず、「4.2.2.Waifu Diffusion 1.4 Tagger V2」をそのまま実行します。
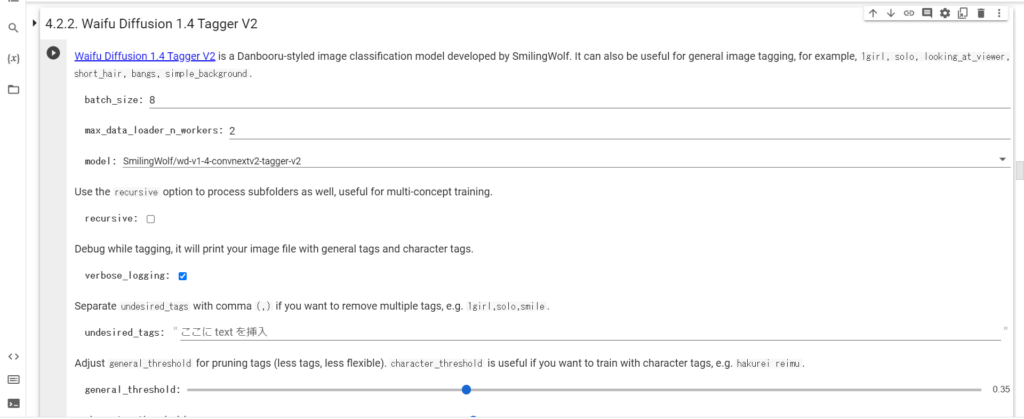
それぞれの2次元イラストの説明・キャラクターの特徴・背景に関する英単語が並べられます。
例えば、
1girl, solo, breasts, blush, smile, short hair, open mouth, bangs,…この中から学習させたい部分を「undsired_tags」に加えていきます。
そして、このセクションを再実行するとそれらのタグが削除されます。
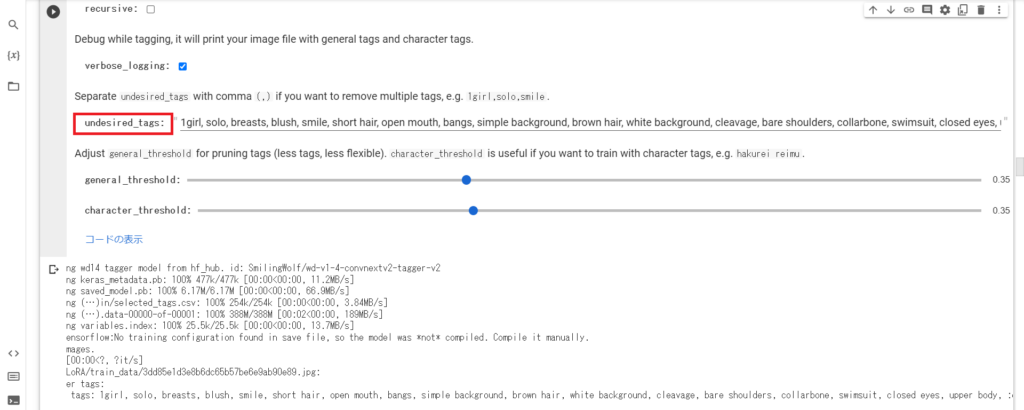
「4.2.3. Custom Caption/Tag」の「custom_tag」にキャラクター名などの、トリガーワードになる名前を入れます。

追加学習させる方法⑥:モデルの設定
「5.1. Model Config」の「project_name」に作成する『Lora』の名前を入力してください。これはファイル名になります。
「output_to_drive」にチェックを入れてから、実行します。

「5.2. Dataset Config」「5.3. LoRA and Optimizer Config」もそのまま実行してください。
追加学習させる方法⑦:学習の設定
「5.4. Training Config」をそのまま実行してください。

追加学習させる方法⑧:学習の開始
その前に、サンプル出力のための呪文(プロンプト)を変更しておく必要があります。
「sample_prompt」のリンクをクリックすると、右側にテキストが開くのでお好きな呪文(プロンプト)に書き換えてください。
今回は、以下の呪文(プロンプト)・ネガティブプロンプトを入力します。
masterpiece, best quality, 1 cute girl, kawaii onnanoko, solo, upper body --n lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry --w 512 --h 768 --l 7 --s 28
実行ボタンを押すと、1エポックごとにGoogleドライブの「/LoRA/output/sample/」フォルダに画像が出力されていきます。
これで『Lora』の作成は完了になります!

こんな感じで画像が生成できるようになります!少し難しいですが、1つ1つ丁寧に行えば簡単に追加学習させることができますので、ぜひ試してみてください。
まとめ
いかがでしたでしょうか?
追加学習モデル『Lora』の作成方法について解説してきました!
今回のポイントをまとめると、以下のようになります。
- 『Lora』とは、既存のモデルに対して、持ち合わせている画像を追加学習させるモデル
- 版権キャラの『Lora』を利用する際は、商用利用は避けて個人利用で楽しむ!
- Google Colabを使えば、簡単に追加学習させることが可能!
追加学習させたモデルを作成し、さらに自分好みの画像を生成したいという方にとって、今回の記事が参考になれば幸いです。
※関連記事


画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

