
Stable Diffusionで画像生成をする際、Loraを使用することで、画像生成の自由度を大幅に向上させることができます。しかしながら、既存のLoraではちょっとした不満があったり、物足りないという方もいるでしょう。
そのような方向けに、今回は自分の好きなように学習させたLoraをStable Diffusion Web UIで生成できる拡張機能『sd-webui-train-tools』について紹介します。
※Stable Diffusionの立ち上げ方・使い方については、以下の記事で詳しく解説しています。

内容をまとめると…
sd-webui-train-toolsは画像をドラッグ&ドロップするだけでLoRAを自作できるStable Diffusion拡張機能
10枚程度の画像を用意すれば、画像サイズの調整やタグ付け不要でLoRA学習が始められる
繰り返し数・エポック数・Optimizer typeなどのパラメータを調整することで学習品質をコントロールできる
VRAM 8GB以上(推奨12GB以上)のGPUが必要で、低スペックPCでの学習は難しい
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

拡張機能「sd-webui-train-tools」とは?
Loraを自作できるStable Diffusionの拡張機能になります。
画像サイズの調整やタグ付けをする必要もなく、10枚程度の画像をドラッグ&ドロップするだけで簡単にLoraを作ることができます。
拡張機能「sd-webui-train-tools」の導入方法
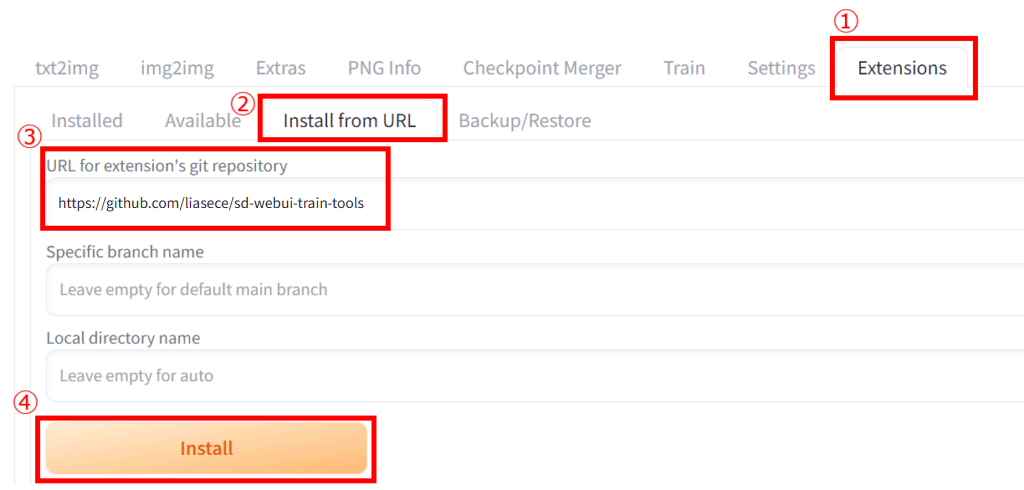
Stable Diffusionに『sd-webui-train-tools』をインストールする手順は以下になります。
- トップ画面で「Extensions」タブをクリック
- 「Install from URL」をクリック
- 該当欄に下記.URLを入力
- 「Install」タブをクリック
- 「Installed」タブの中にある「Apply and quit」をクリックしてStable Diffusionを再起動
入力するURLは以下です。

「Train Tools」のタブが新たに表示されていれば、正常にインストールできています。

拡張機能「sd-webui-train-tools」の使い方
それでは「sd-webui-train-tools」の使い方について、解説していきます。
まずは学習させる画像を10枚程度用意します。もっと多くても構いませんが、学習元の画像が多くなるほどLoraの作成に時間がかかります。
学習元画像に関しては、特徴を覚えさせたいキャラクターの全身が映っており、様々な構図(ポーズ)や表情をしているものを選んだ方が良いと言われています。1つの構図だけで学習させるのは推奨されていません。
画像サイズは自動でリサイズされるのでこだわる必要はありません。ただし、1024×1024のサイズがおすすめされています。
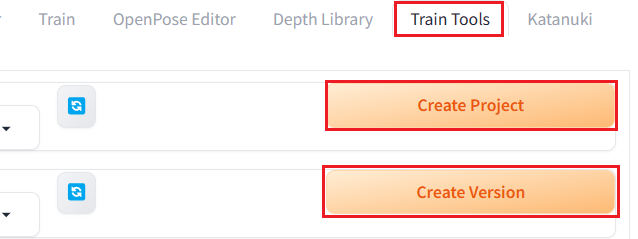
画像の準備が完了したら、Stable Diffusion WebUIの「Train Tools」のタブをクリックし、「Create Project」をクリックして作成するLoraのファイル名を設定します。
次いで、「Create Version」をクリックしてバージョンを入力します。ここは初期のv1のままで大丈夫です。学習元画像を変えるたびにv2、v3と更新していけば、簡単にバージョン管理ができます。
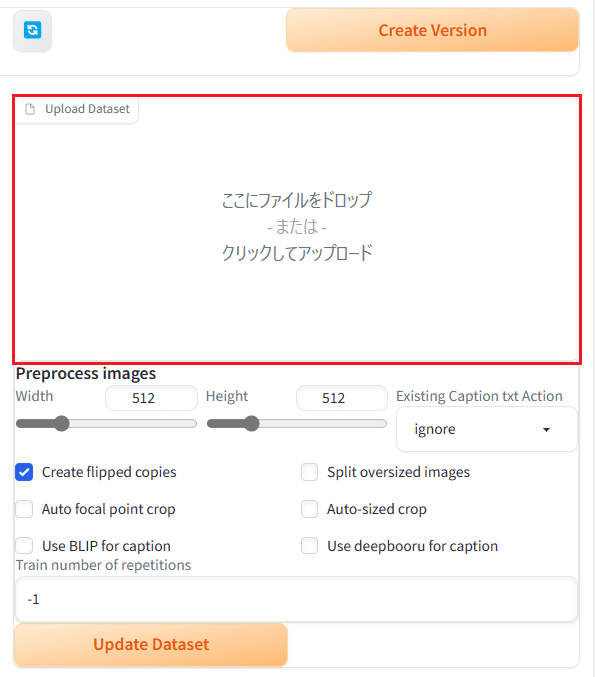
「Upload Dataset」の欄に、学習元画像をドラッグ&ドロップします。
次にデータセットの設定を行います。
Train number of repetitions(繰り返し数):10~20程度がおすすめです。この数値はLoRAを作成するのに必要な総ステップ数に影響してきます。数を大きくし過ぎると過学習になる恐れがあります。
Preprocess images:512×512の初期設定のままで大丈夫です。Create flipped copiesのチェックは外してください。
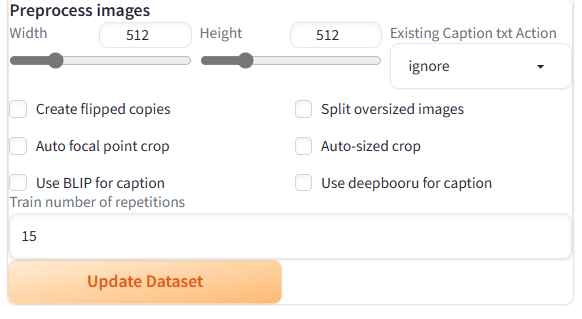
ここまで設定できたら、「Update Dataset」をクリックします。データセットの処理が終わると、左側に編集された学習元画像が表示されます。
次に、Loraファイルに作成に必要なトレーニングのパラメータを設定します。
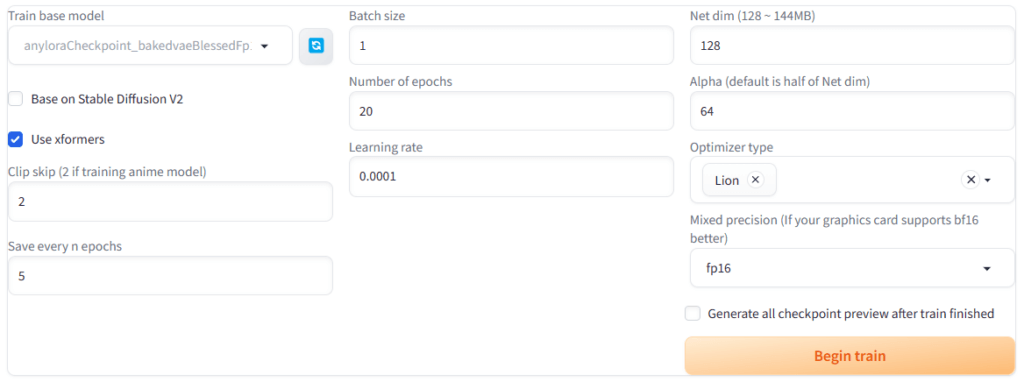
Train base model:学習で使用するモデルのデータを設定します。学習元画像の属性に合わせて決めましょう。例えばアニメイラストが素材なら、アニメイラスト系のモデルを設定しましょう。
Clip skip:アニメイラスト系のモデルを使用する場合は2が推奨されています。リアル系のモデルを使用する場合は1と2の両方を試し、結果が良い方を採用しましょう。
Save every n epochs:何エポック毎にLoraとして保存するかを設定します。(繰り返し回数)×(学習素材の枚数)が1エポックとなります。
Batch size:大きいほどLoraファイルの生成速度は上がりますが、VRAM使用量も増えます。とりあえず初期設定の1で良いと思います。
Number of epochs:学習の総エポック数を設定します。(繰り返し回数)×(学習素材の枚数)×(エポック数)が最終的なsteps数となります。
Optimizer type:いろいろな種類がありますが、AdamWや初期設定のLionを使っている人が多いです。Optimizerとは、どうやってAIに素材画像を学習させるかという手法のことを指します。
Generate all checkpoint preview after train finished:Loraが生成されるエポック毎に、そのLoRAを使って画像を1枚生成してくれる機能です。特に必要が無ければチェックを外しましょう。
以上、設定が完了したら「Begin Train」をクリックします。Loraの学習がスタートします。学習にはかなりの時間を要します。
学習が終わると、「stable-diffusion-webui\outputs\train_tools\project\(設定したLora名)\versions\(設定したバージョン名)\trains」の中に、Loraファイルが保存されます。
自作LoRAを作成する際の注意点
ここでLoraを自作する際の注意点がいくつかありますので、紹介します。
①低スペックPCでは難しい
Loraの学習には、VRAMが8GB以上のGPU、可能であれば12GB以上のGPUが推奨されています。
使用しているGPUのスペックが低い場合は、Google Colaboratoryを使って学習した方が良いかもしれません。
②Google ColabでR18画像を学習させるのは危険
Google Colaboratoryを使ってLoraを自作する場合、素材にR18指定の画像(二次元画像も含む)を使用してしまうと、アカウントがBANされる恐れがあります。素材画像は適切なものを選びましょう。
自作LoRAを作成するほかの方法
今回紹介した「sd-webui-train-tools」以外にも、Loraを自作する方法はあります。詳しく知りたい方は、以下の記事を参考にしてみてください。

まとめ
いかがでしたでしょうか?
今回は自分の好きなように学習させたLoraをStable Diffusion Web UIで生成できる拡張機能『sd-webui-train-tools』について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 拡張機能「sd-webui-train-tools」を利用することで、Loraを自作することができる。
- Loraの学習には低スペックPCでは難しい。
「sd-webui-train-tools」を利用すれば、誰でも簡単にLoraを自作することができます。画像生成の幅が大きく広がると思いますので、ぜひ試してみてください。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

