
公開されて以来、無料で利用できるツールであるとは思えないほど便利であり、かつ、簡単に操作することができるAI画像生成ツールのStable Diffusionですが、その開発の裏にはどのような背景があったのかご存知ですか?
今回は、Stable Diffusionの開発の背景に存在しているモデルについて解説されている論文を3つご紹介していきたいと思います。
今回、ご紹介する論文は基礎的な内容であり、どれもStable Diffusionを利用している方ならぜひ知っておきたいものとなっておりますので、ぜひ最後までご覧ください!
内容をまとめると…
Stable Diffusionの基盤技術「拡散モデル」を理解するための必読論文はU-Net・ビジョントランスフォーマー・CLIPの3つ
U-Netはエンコーダーとデコーダーで画像の内容を変換するU字型ニューラルネットワーク
ビジョントランスフォーマーは画像を16×16ピクセルのパッチに分割してトランスフォーマーに入力し、高精度な画像分類を実現する技術
CLIPはテキストと画像の類似度を計算するモデルで、Stable Diffusionでは画像理解コンポーネントとして使われている
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

今回紹介するStable Diffusionの必読論文3選!
Stable Diffusionは「拡散モデル」という技術を応用して開発されたツールであることをみなさんはご存知ですか?
「拡散モデル」は3年ほど前からとてつもない速度で研究が進められている技術となっています。
この技術を応用するかたちで開発されたのが、自由にプロンプトを入力するだけで誰でも簡単にAI画像を生成することができるツールであるStable Diffusionとなっています。
しかし、この「拡散モデル」という技術自体は、理解することが非常に難しい技術です。
加えて、3年という短い期間の間に急速に研究が進められた技術ですので、「拡散モデル」について知りたいと思っても、どの論文から読んでいけばよいのかわからなくなってしまうことが多いという問題点もあります。
そこで今回は、Stable Diffusionの背景にある技術の「拡散モデル」について理解するために読む必要がある論文の中でも、基礎といえるものを3つご紹介していきます。
なお、今回ご紹介する論文はいずれも以下のリンクから原文を確認することができますので、合わせてご覧いただければと思います。
・U-Net:https://arxiv.org/abs/1505.04597?ref=ja.stateofaiguides.com
・ビジョントランスフォーマー:https://arxiv.org/abs/2010.11929?ref=ja.stateofaiguides.com
・CLIP:https://arxiv.org/abs/2103.00020?ref=ja.stateofaiguides.com
必読論文①:U-Net
まずは、「U-Net」というモデルについて解説されている論文の内容を説明していきたいと思います。
以下の文章が、この論文の内容について解説したものとなっております。
「U-Net」とは、ニューラルネットワークの1種であり、かたちがアルファベットの「U」のようになっているため、「U-Net」と呼ばれるようになりました。
また、この技術は、画像のサイズを変えずに、画像の内容を変更したいときにしばしば用いられるモデルとなっております。
かたちがアルファベットの「U」の字のようになっている理由は、エンコーダーとデコーダーという2つの技術が用いられているためです。
https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
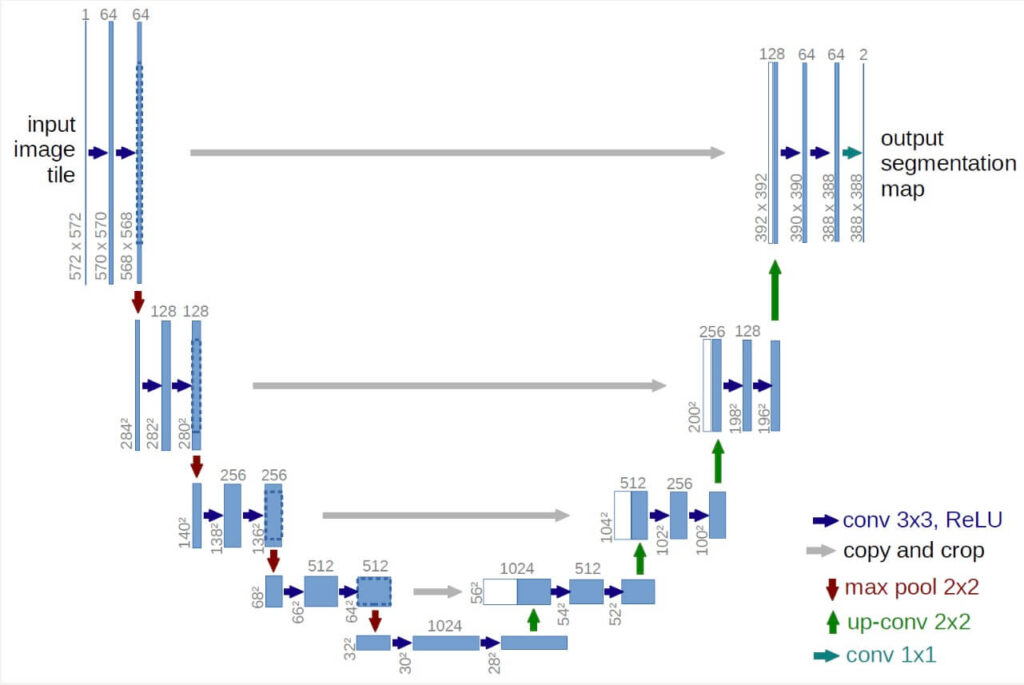
「U-Net」は、まず最初にエンコーダーを用いて少しずつ抽象度が高い情報や解像度の低い情報を取り出し、次にそれらの情報をデコーダーを用いて少しずつ元に戻していくという仕組みとなっております。
そしてこのモデルは、「pix2pix」という画像変換をする際に用いられるものや、他の数多くの画像セグメンテーションモデルでも使用されています。
必読論文②:ビジョン・トランスフォーマー
次に、「ビジョン・トランスフォーマー」というモデルについて解説されている論文の内容を説明していきます。
以下の文章が、この論文の内容について解説したものとなっています。
「ビジョン・トランスフォーマー」とは、トランスフォーマーという技術を応用して開発されたものです。
具体的には、画像を分類することができるタスクとして応用されています。
元となる画像を「16×16」ピクセルのパッチというものに分け、その上で、日本語で「文脈」を意味する「トークン」のようにトランスフォーマーに入力できるようにしたものが「ビジョン・トランスフォーマー」です。
このモデルが開発されたことで、分類の精度を非常に高めることに成功しました。
https://github.com/google-research/vision_transformer
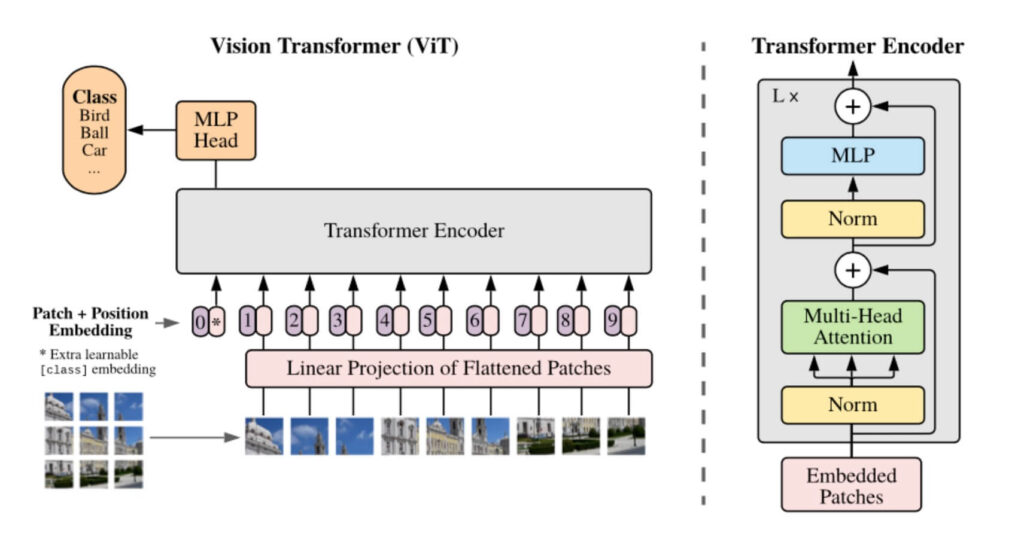
必読論文③:CLIP
最後に解説していくのは、「CLIP」というモデルについて書かれた論文の内容についてです。
以下の文章が、この論文の内容について解説したものとなっております。
「CLIP」とはテキストとそのテキストを元に生成された画像の類似度を計算することができるモデルです。
このモデルの仕組みは以下のとおりとなっております。
- まず、「テキスト・エンコーダー」というものと先ほどご紹介した「ビジョン・トランスフォーマー」もしくは、「ResNet」という画像・エンコーダーというものを用いて、両者が同じベクトルへと変換されます。
- その上で、どの程度テキストと生成された画像が似ているか計算されます
https://github.com/OpenAI/CLIP
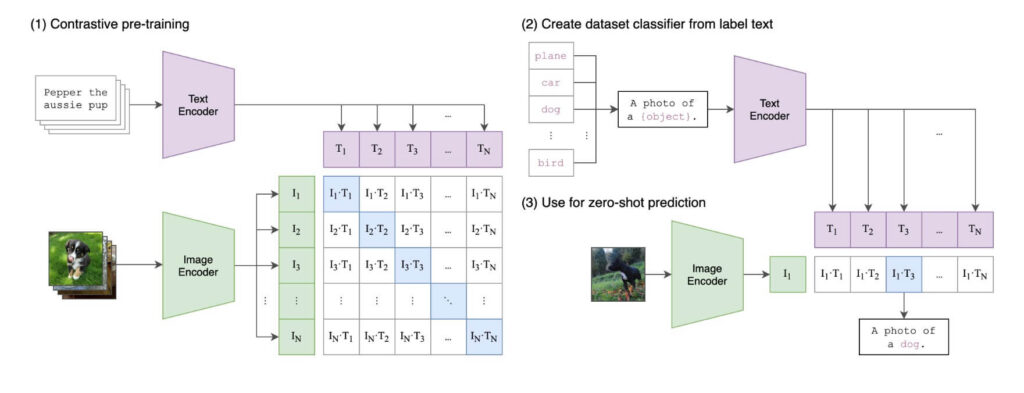
この「CLIP」というモデルは、Stable Diffusion上において、「画像理解コンポーネント」として用いられています。
まとめ
いかがでしたでしょうか?
今回は、Stable Diffusionの開発に使われた技術について説明されている3つの論文について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 「U-Net」は、エンコーダーを用いて抽象度が高い情報や解像度の低い情報を取り出し、その上で、それらの情報をデコーダーを用いて少しずつ元に戻していくという仕組みとなっている「U」字型のモデルである
- 「ビジョン・トランスフォーマー」とは、トランスフォーマーという技術を、画像を分類することができるタスクとして応用したモデルである。
- 「CLIP」とは、テキストとそのテキストを元に生成された画像の類似度を計算することができるモデルである
Stable Diffusionの必読論文に関する知識が深まったでしょうか?
Stable Diffusionの開発の背景に存在している技術は難しいものですが、基礎から学んでいくことで、少しずつ理解することができるようになっていきます。
ぜひ今回ご紹介した論文を読んでみてください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

