
今回はStable Diffusionの『Dreambooth』で追加学習をさせる方法についてご紹介します。
LoRAとの違いについてもご紹介してるので、ぜひ参考にしてください!
内容をまとめると…
Dreamboothは数枚の画像から既存モデルに追加学習させて新しいモデルを作成できるStable Diffusionの機能
LoRAと比べて画像枚数が少なくても高精度な学習ができるが、VRAM 12GB〜24GBが必要で学習時間も長い
Google Colab上で「others3」ノートブックを使えば、zipファイルにまとめた正方形画像から手軽に学習できる
学習データを増やす・画像サイズを正方形に統一する・max_train_stepsを画像枚数×100に設定するのが品質向上のコツ
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

『Dreambooth』とは?

「Dreambooth」とは、既存モデルに数枚の画像を記憶させることで、新しいモデルが作成できる機能です。
内容はLoraと似てますが、以下のような違いがあります。
| Dreambooth | LoRA |
|---|---|
| ・学習精度が高い ・画像枚数が少なくても学習できる ・高スペックPCが必要 ・学習時間が長め | ・PCスペックが低めでも使用できる ・学習時間が短い ・画像の枚数が最低でも20枚ほど必要 ・Dreamboothと比べると学習精度が怠る |
Dreamboothは、画像枚数が少なくても精度の高い学習ができるというメリットがあります。
しかし、VRAM容量が最低でも12GB~24GB必要・学習時間が長い傾向にあるため、低スペックPCだと利用するのは難しそうです。
Dreamboothを利用する際は、事前にPCスペックしておくことをおすすめします。
『Dreambooth』のインストール方法
ここからは、Dreamboothの追加学習方法をご紹介していきます!
まずは「Dreambooth」のインストールをしましょう。
今回はGoogleColabでの利用を前提として、GitHubの「others3」を使用していきます。
①こちらのリンクから「others3」に飛び、Open in Colabをクリックします。
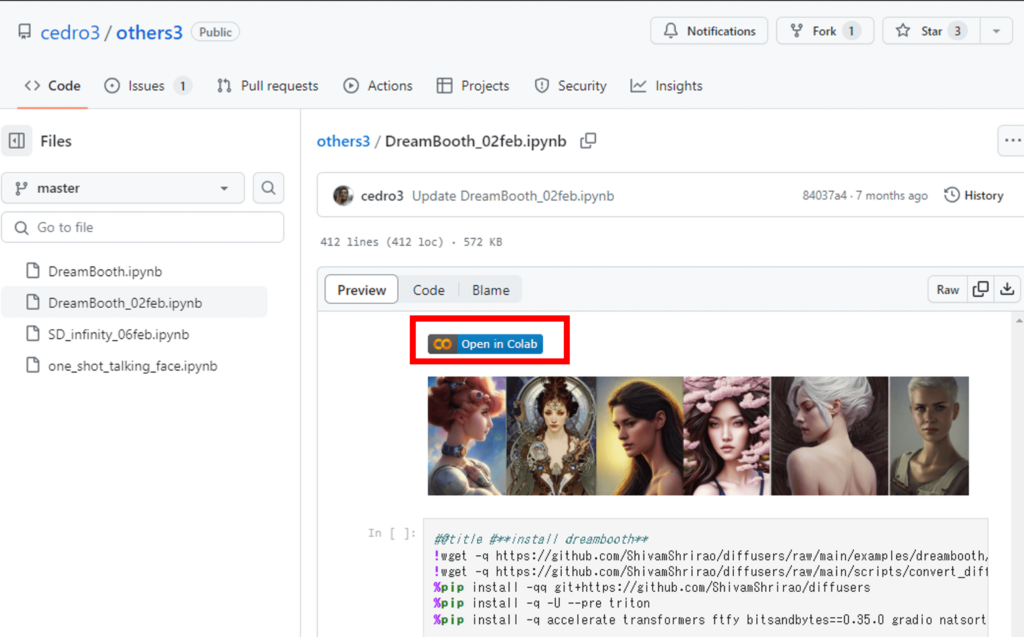
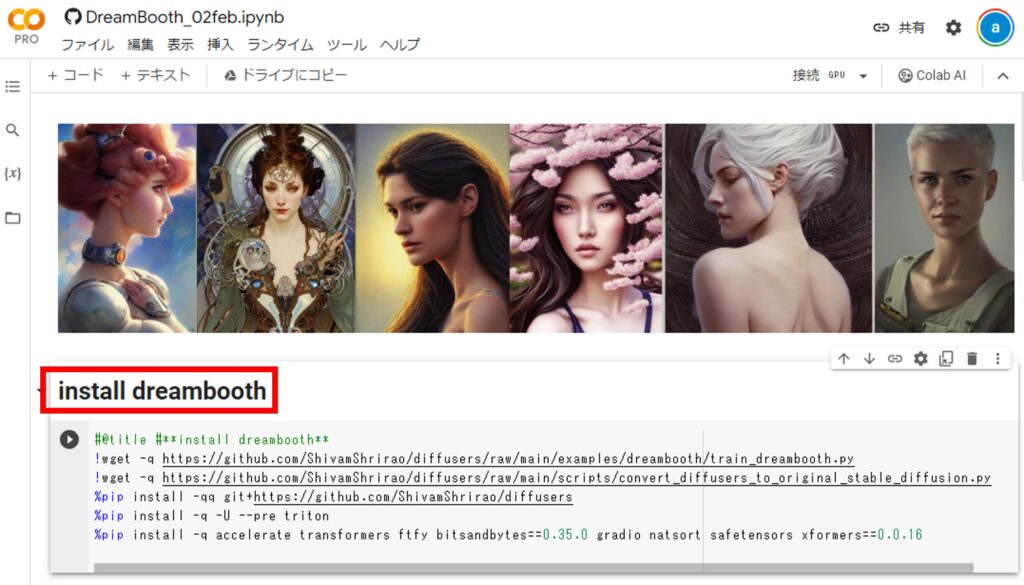
②「others3」のノートブックが開いたら、「install dreambooth」セルのコードを実行して「Dreambooth」をインストールします。
③「login to HuggingFace」のコードを実行して、「HuggingFace」にログインします。
『Dreambooth』の使い方
「Dreambooth」がインストールできたら、実際に使ってみましょう!
学習データの準備
まずは学習データの準備です。
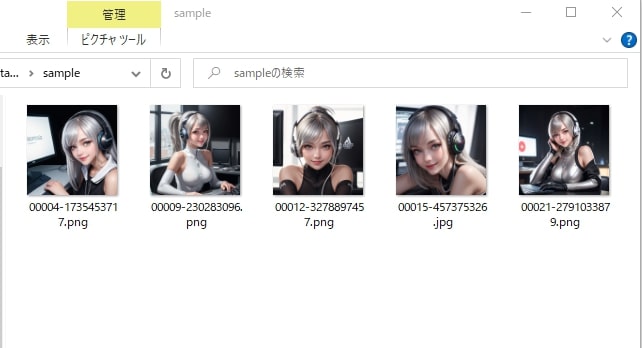
①任意のフォルダを作成し、モデルに学習させたい画像を最低でも5枚保存します。
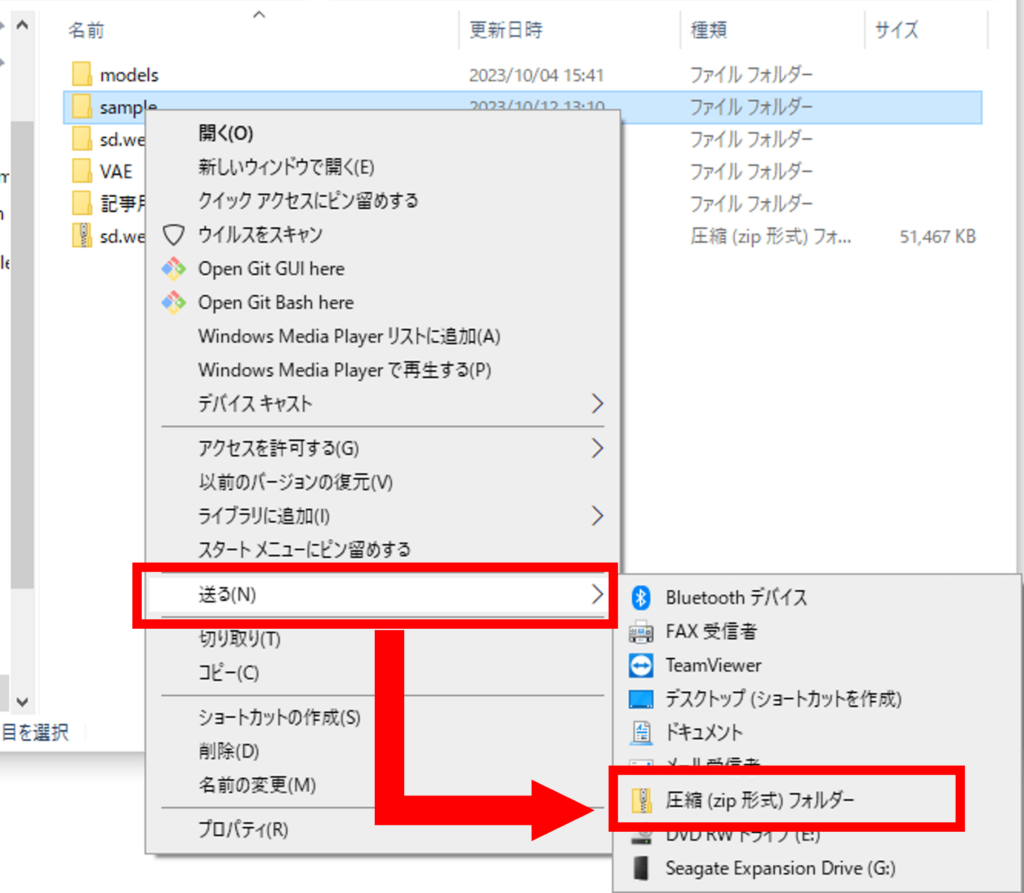
②作成したファイルを右クリック→送る(N)→圧縮(zip形式)フォルダーでzip形式に変更します。
③zipファイルを「Googleドライブ」内の任意の場所にアップロードしておきます。
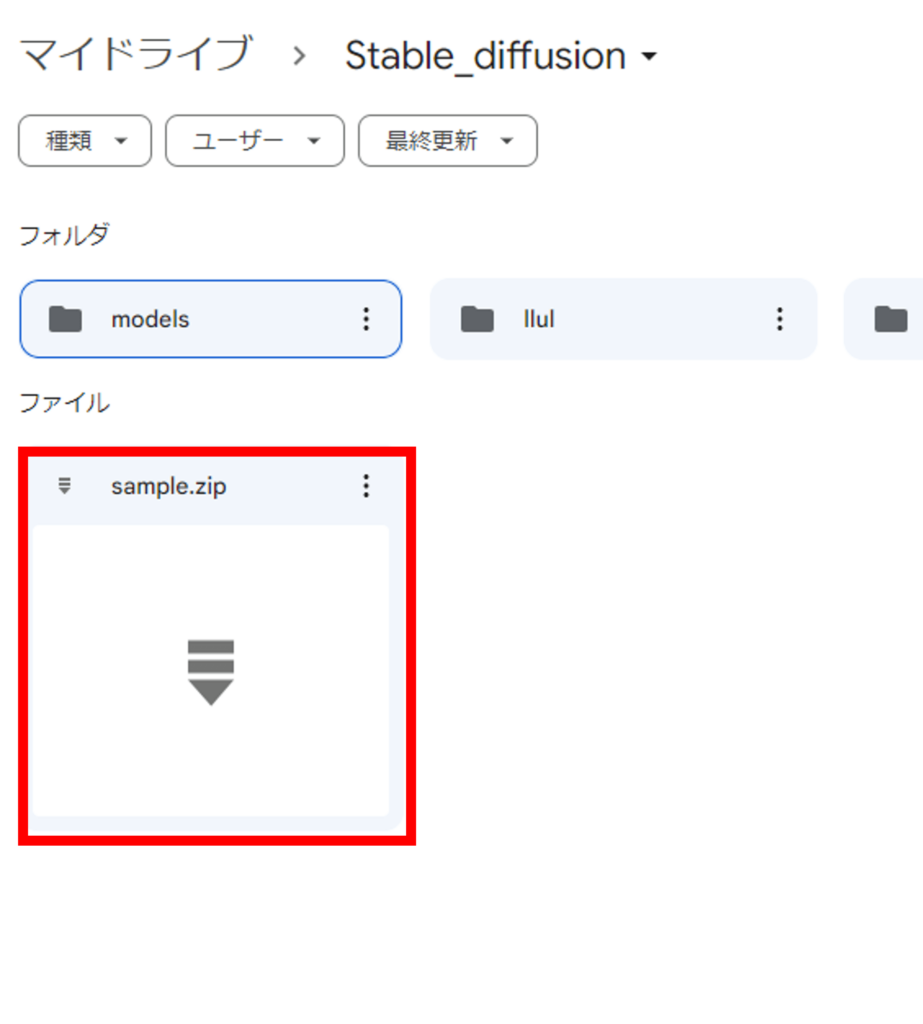
コードの実行
学習データの準備ができたら、コードを実行していきます。
①「others3」の「setting folder」セルにある「INSTANCE」と「CLASS」を設定します。
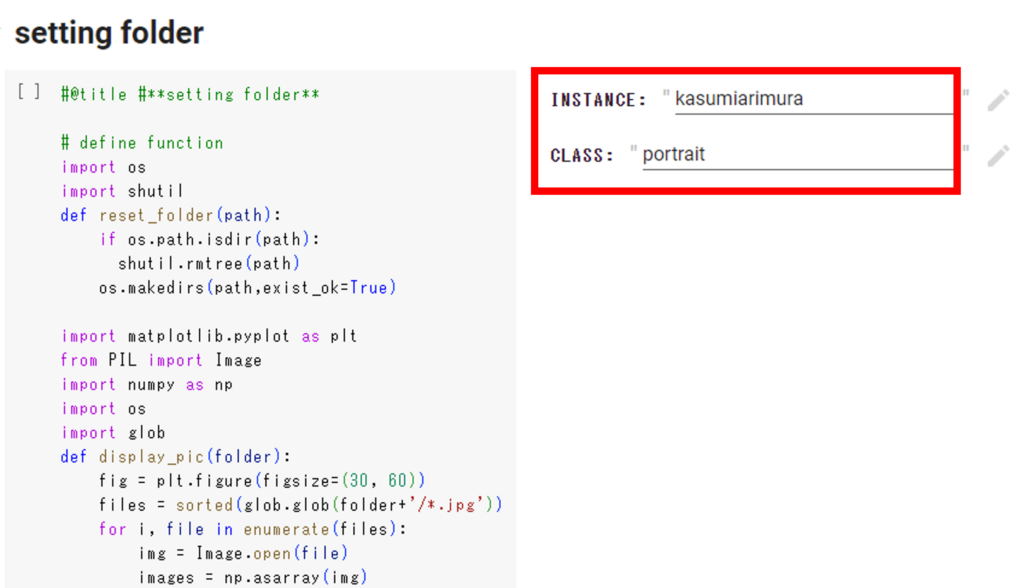
| INSTANCE: | オブジェクト名 (キャラの名前など、ユニークな名前を入力してください。) |
| CLASS: | クラス名 (一般的な名前を入力してください。) |
②「upload pics」セルの以下のコードの赤文字と青文字部分を、「学習データの準備」で作成したzipファイルを基に変更します。
gdown.download('https://drive.google.com/uc?id=1NqdBzYndW5mAm21MlOC6uP6gH61lWWZ5', 'kasumi.zip', quiet=False)
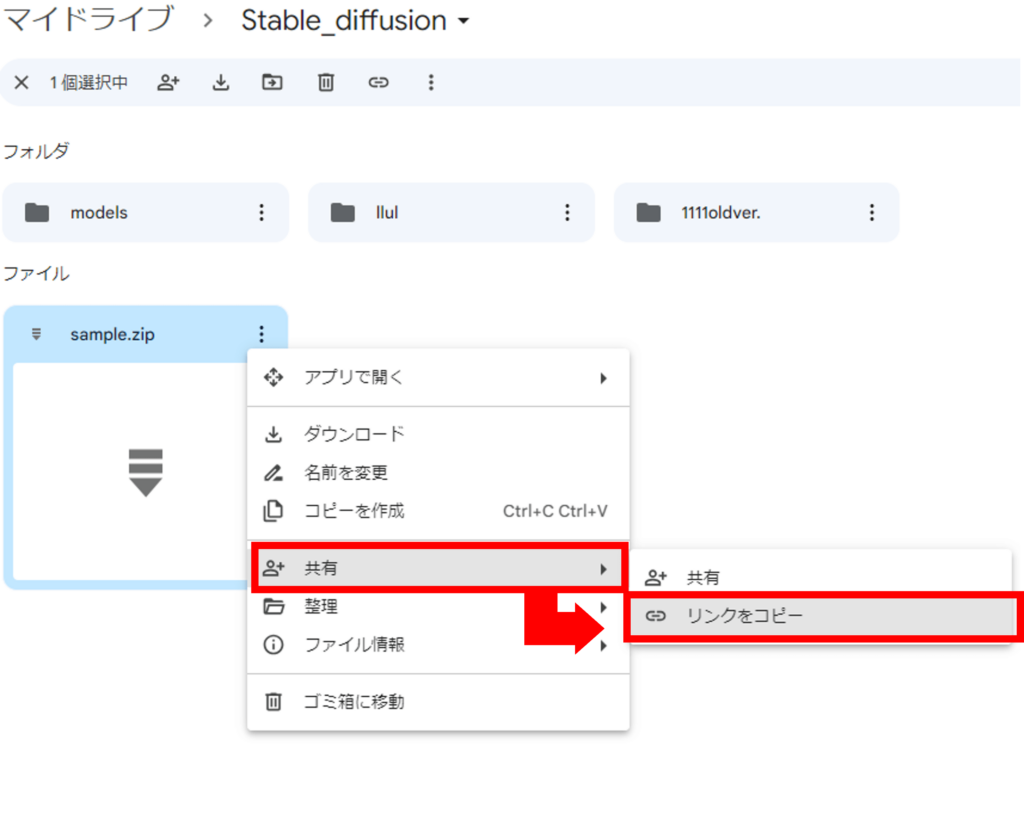
! unzip -d $INSTANCE_DIR kasumi.zip青文字:作成したzipファイルの名前に変更します。
赤文字:Googleドライブにアップロードしたzipファイルを右クリック→共有→リンクをコピーでファイルのリンクがコピーされるので、赤文字部分に貼り付けます。
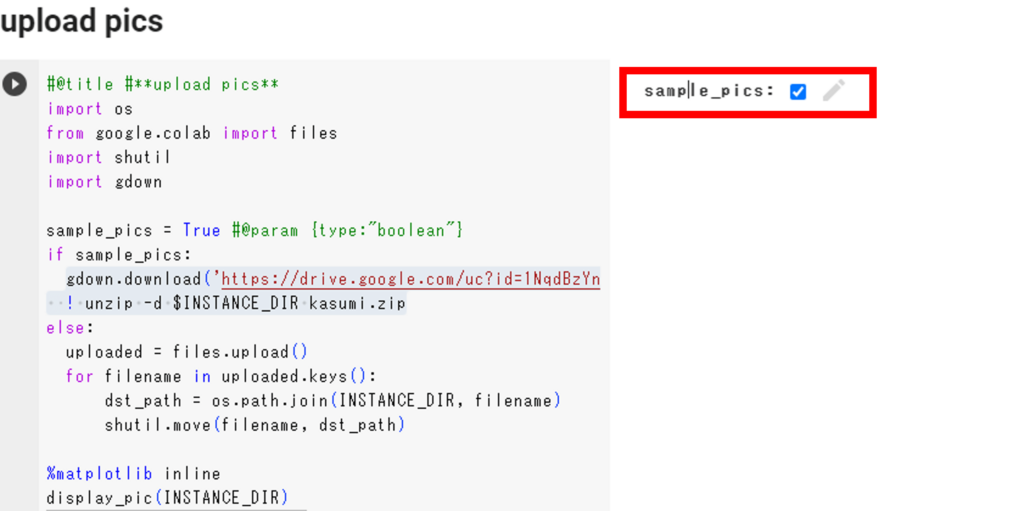
それぞれの変更が完了したら、セルの右側にあるsample_picsにチェックを入れてコードを実行します。
③「train (takes 20〜30minutes)」セルを実行して学習を開始します。
20~30分ほどかかるため、しばらく待ちましょう。
④「make pipe for generating images」セルに任意のseed値を設定して、コードを実行してください。
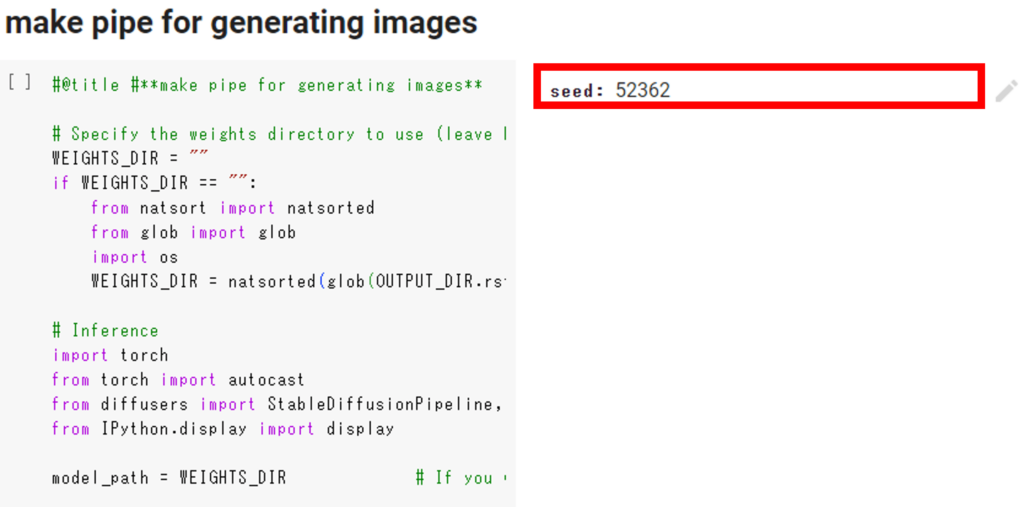
ここまでのコードを実行することで、学習モデルが完成します。
画像生成
⑤「manual generat images」セルで、作成した学習モデルを基に画像生成してみましょう。
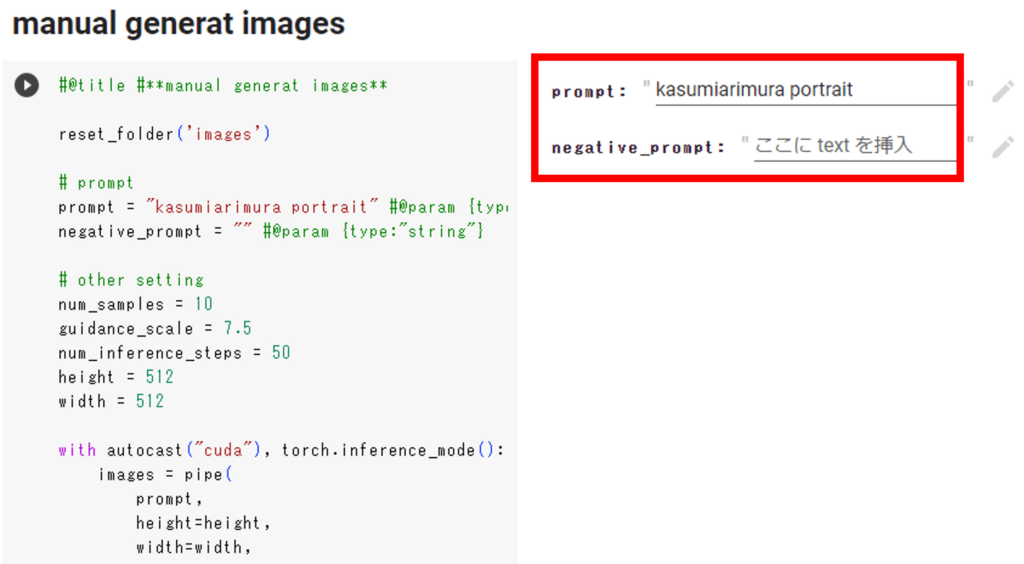
| promt | 手順①で設定したオブジェクト名とクラス名を入力 |
| negative_prompt | 任意で設定 |
コードを実行すると画像生成されます。
生成された画像を保存する場合は、「Download images」セルを実行することで保存できます。
『Dreambooth』でクオリティを上げるコツ!

つぎに、「Dreambooth」でクオリティの高い学習モデルを生成するためのコツをご紹介します。
①学習データを増やす
「Dreambooth」は画像枚数が少なくても学習できますが、枚数が多ければ多いだけ学習精度があがります。
人間や動物であれば、正面・横・後ろ…。など様々な角度からの学習データを用意するとよいでしょう。
②学習データの画像サイズを正方形に統一する
「Dreambooth」で画像を学習する際、どのサイズでも正方形として扱われるため、正方形以外のサイズだと画像がうまく学習されない可能性があります。
事前にサイズ変更しておくなど、正方形に統一して保存しておきましょう。
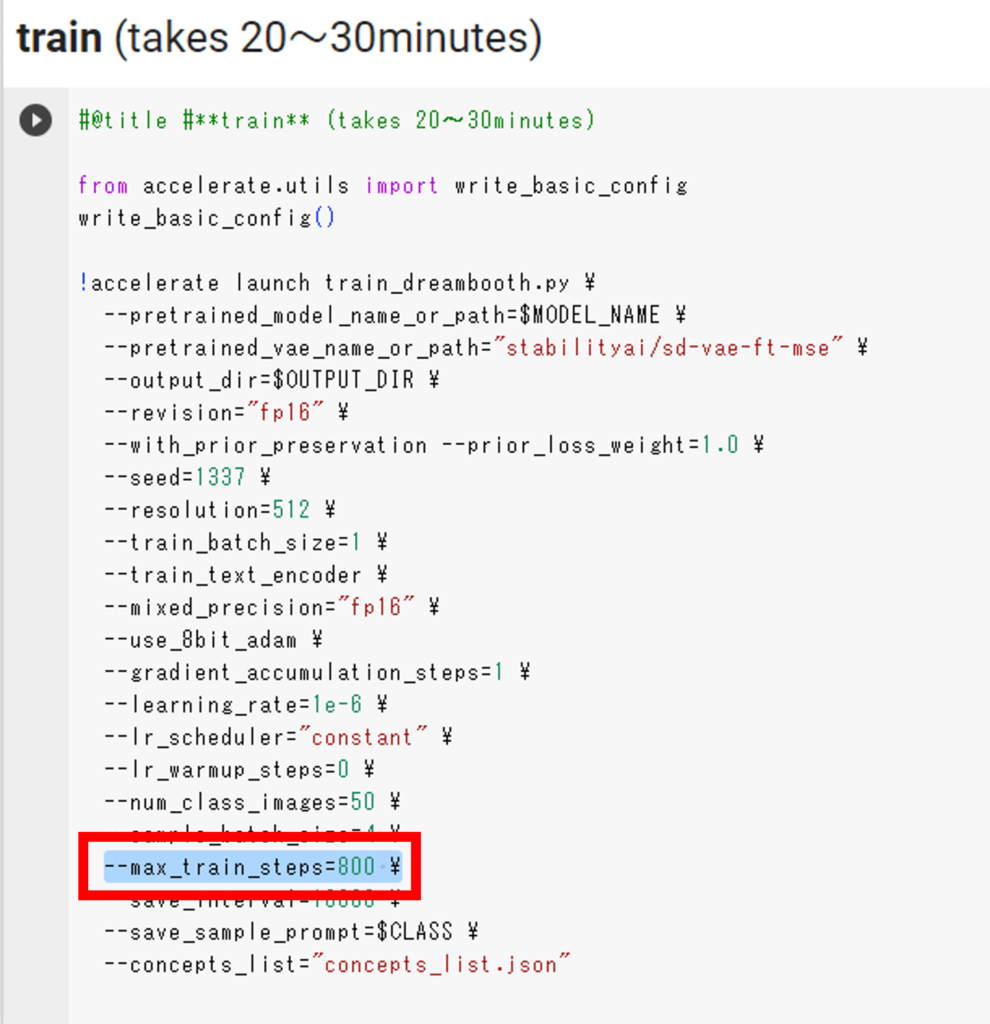
③「max_train_steps」を増やす
「max_train_steps」とは、画像の最大学習回数のことです。
学習データの枚数が多い場合は手順④で「--max_train_steps=800 \」というコードの「800」の値を、画像枚数×100を目安に変更してみてください。
まとめ
いかがでしたでしょうか?
Stable Diffusionの「Dreambooth」について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 「Dreambooth」とは数枚の画像を記憶させることで、新しいモデルが作成できる機能。
- 「Dreambooth」を利用するには、VRAM容量が最低でも12GB~24GB必要。
- 学習モデルのクオリティを上げるためには、学習データを増やす・データを正方形に統一する。
- 学習データが多い場合は、「max_train_steps」の値を画像枚数×100を目安に変更する。
一からモデルに学習させてしまえば、理想の画像が簡単に生成できるようになります。
ぜひ今回の記事を参考に、「Dreambooth」で学習モデルを作成してみてください!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

