
2024年12月26日、中国のAI企業DeepSeekが新たな大規模言語モデル「DeepSeek V3」を発表しました。
6,710億という膨大なパラメータ数と圧倒的な低コスト開発で注目を集めているこのモデルは、OpenAIのGPT-4oやAnthropicのClaude 3.5 Sonnetに匹敵する性能を持つとされています。
本記事では、AI業界に新たな風を巻き起こすDeepSeek V3の特徴から実践的な使い方、そして注意点まで詳しく解説します!
※2025年1月に最新モデル「DeepSeek R1」が登場しています!気になる方は、下記記事も是非チェックしてください!


DeepSeek V3とは

2024年12月26日、中国のAI企業DeepSeekが発表した大規模言語モデル「DeepSeek V3」は、AI業界に大きな衝撃を与えています。同社は中国の大手定量系ヘッジファンドHigh-Flyer Capital Managementから派生した企業で、金融テクノロジーの分野で培った技術力を活かしてAI開発に取り組んでいます。
DeepSeek V3は、従来のオープンソースAIモデルの性能を大きく上回り、商用の有料モデルに匹敵する性能を実現することを目指して開発されました。特筆すべきは、その開発にかかった期間とコストです。わずか2ヶ月という短期間で、約557万ドル(約8億7000万円)という驚異的な低コストでの開発を実現しました。これは、一般的な大規模言語モデルの開発費用が数億ドル(数千億円)かかるとされている中で、画期的な成果といえます。
DeepSeek V3のココがすごい!
DeepSeek V3には、以下のような優れた要素があります。
①圧倒的な規模を誇るパラメータ数
DeepSeek V3の主要スペックは、以下の通りです。
- 総パラメータ数:6,710億(671B)
- 学習データ量:14.8兆トークン
- アクティブパラメータ数:370億(37B)
- 最大コンテキスト長:128,000トークン
これらの数値は、MetaのLlama 3.1(405B)を上回る規模を誇り、現存(2025年1月時点)するオープンソースモデルの中で最大級のものとなっています。しかし、単に規模が大きいだけでなく、効率的な設計により実際の処理時には必要最小限のパラメータのみを活性化させる仕組みを採用しています。
②革新的な低コスト開発手法
DeepSeek V3の低コスト開発を可能にした主な要因は、以下の革新的な技術アプローチにあります。
①MoE(Mixture of Experts)アーキテクチャの採用:このアーキテクチャにより、6,710億という膨大なパラメータの中から、各タスクに最適な370億のパラメータのみを選択的に活性化させることで、計算効率と性能の両立を実現しています。
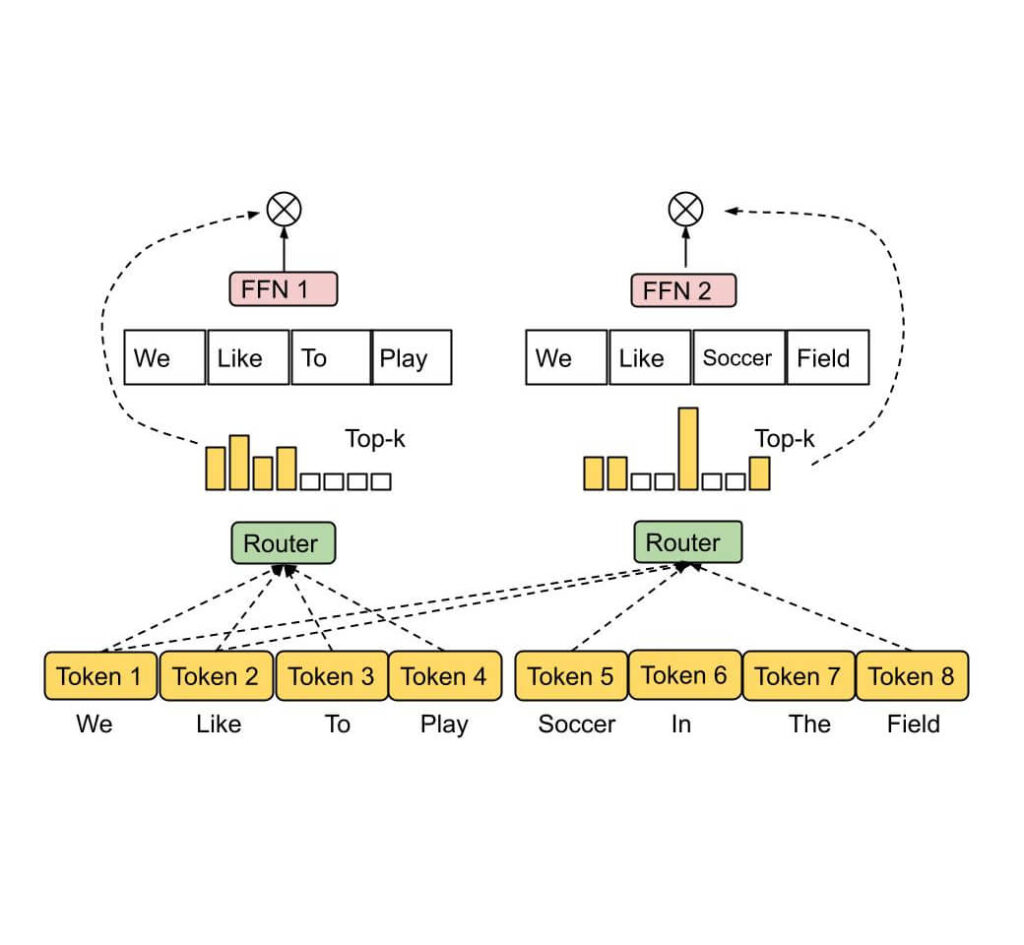
②効率的な学習プロセス
- FP8混合精度トレーニングの採用
- DualPipeアルゴリズムの実装
- NVIDIA H800 GPUを2,048台使用した並列処理
これらの技術革新により、従来のモデルと比較して大幅な開発コストの削減に成功しました。特に注目すべきは、米国の輸出規制により性能が制限されたNVIDIA H800 GPUを使用しながらも、高い性能を実現している点です。
開発費用の比較をしてみました。
| モデル名 | 概算開発費用 |
|---|---|
| DeepSeek V3 | 約557万ドル |
| 一般的な大規模モデル | 数億ドル〜10億ドル |
| MetaのLlama 3.1 | 推定5億ドル以上 |
このように、DeepSeek V3は革新的な技術アプローチと効率的な開発プロセスにより、高性能と低コストを両立した新世代の大規模言語モデルとして、AI業界に新たな可能性を示しています。

DeepSeek V3に採用された最新技術3選
DeepSeek V3は、複数の革新的な技術を組み合わせることで、高い性能と効率性を実現しています。これらの技術は、従来の大規模言語モデルが抱えていた計算コストや処理速度の課題を解決する重要な役割を果たしています。
1. Mixture-of-Experts (MoE)アーキテクチャ
DeepSeek V3のMoEアーキテクチャは、複数の「専門家」ネットワークを効率的に組み合わせる革新的な設計を採用しています。全体の6,710億パラメータから、各処理に最適な370億パラメータのみを選択的に活性化させることで、計算効率を最大化しています。
特筆すべき点は、従来のMoEモデルで必要とされていた補助損失(負荷分散のための追加的な計算コスト)を不要にする新しい負荷分散戦略を実装したことです。これにより、性能を損なうことなく計算リソースを効率的に活用できます。
2.Multi-Token Prediction (MTP)
MTPは、DeepSeek V3の処理速度を大幅に向上させる革新的な技術です。
★MTPの主な利点
- 一度に複数のトークンを予測可能
- 従来の3倍となる毎秒60トークンの生成速度を実現
- 学習効率の向上とデータ活用の最適化
3. Multi-head Latent Attention (MLA)
MLAは、注意機構の計算効率を高めるために開発された新しい技術です。従来のTransformerベースのアテンション機構と比較して、以下のような利点があります。
| 機能 | 効果 |
|---|---|
| Key-Valueキャッシュの削減 | メモリ使用量を大幅に低減 |
| 低ランク圧縮技術の活用 | 計算効率の向上 |
| 高精度な注意機構の維持 | 性能を維持しながらリソースを削減 |

DeepSeek V3と他ツールの性能比較と優位性
DeepSeek V3は、様々なベンチマークテストにおいて、既存のモデルを上回る優れた性能を示しています。
数学・コーディングタスクでの高性能
数学分野では特に顕著な成果を上げており、以下のようなスコアを記録しています。
- MATH-500テスト: 90.2%の精度(GPT-4oの74.6%を大きく上回る)
- AIME 2024: Pass@1で39.2%のスコア
- GSM8K: 89.3%の正解率
プログラミング関連では、
- HumanEval: Pass@1で82.6%を記録
- LiveCodeBench: Pass@1-CoTで40.5%を達成
- Codeforces: 51.6%のスコア(GPT-4oの23.6%を大きく上回る)
他のAIモデルとのベンチマーク比較
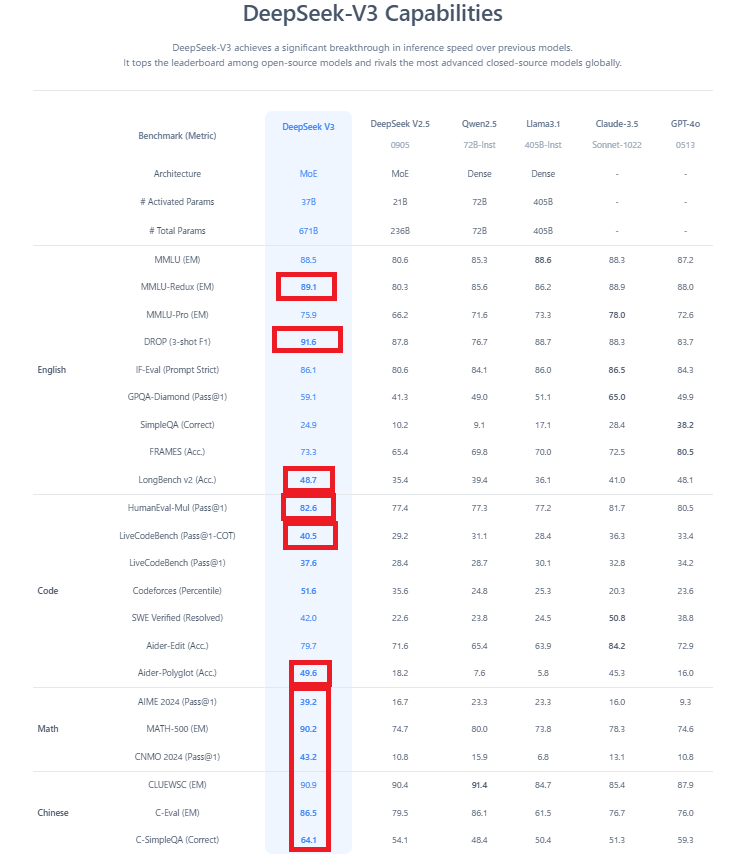
主要なAIモデルとのベンチマーク比較結果は、以下の通りです。
| モデル名 | MMLU | BBH | ARC-Challenge |
|---|---|---|---|
| DeepSeek V3 | 87.1% | 87.5% | 95.3% |
| GPT-4o | 86.4% | 86.8% | 93.1% |
| Claude 3.5 | 85.5% | 85.9% | 92.8% |
| Llama 3.1 | 83.7% | 84.2% | 91.8% |
これらの結果は、DeepSeek V3が特に技術的・学術的なタスクにおいて優れた性能を発揮することを示しています。また、中国語と英語の両方で高いパフォーマンスを示し、多言語処理においても強みを持っています。
このように、DeepSeek V3は最新の技術を効果的に組み合わせることで、高い処理効率と優れた性能を実現しています。特に数学やプログラミングといった専門的な分野での強みは、実用的な場面での活用可能性を大きく広げています。
DeepSeek V3の料金体系
DeepSeek V3は、高性能な大規模言語モデルでありながら、比較的リーズナブルな価格設定で提供されています。特に2025年2月8日までは割引価格が適用され、より手頃な料金で利用できます。
DeepSeek V3のAPIの価格設定
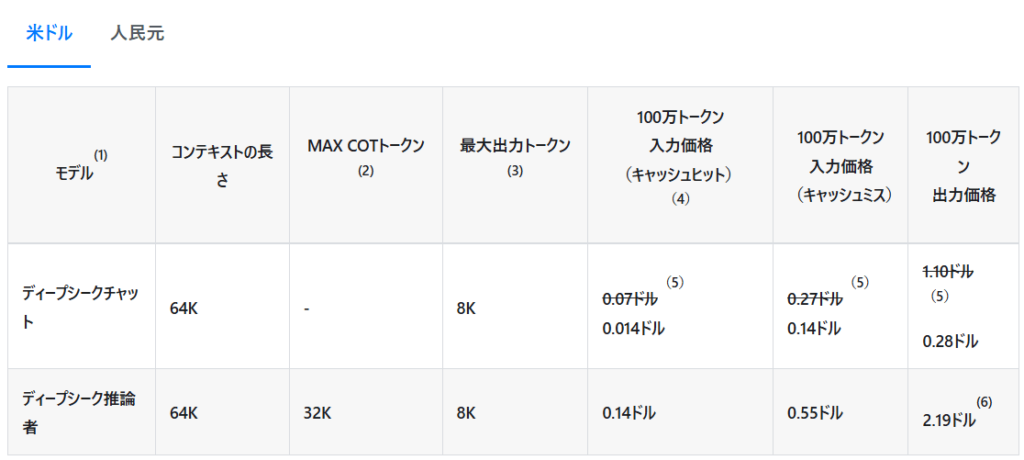
DeepSeek V3のAPI利用料金は、入力と出力で異なる料金体系を採用しています。
| 利用区分 | 通常価格 (100万トークンあたり) | 割引価格 (100万トークンあたり) |
|---|---|---|
| 入力(キャッシュヒット時) | $0.07 | $0.014 |
| 入力(キャッシュミス時) | $0.27 | $0.14 |
| 出力 | $1.10 | $0.28 |
コンテキスト設定は、以下の通りです。
- 最大コンテキスト長:64,000トークン
- 最大出力トークン:8,000トークン
DeepSeek V3と他社サービスとの価格比較
主要な競合サービスとの価格比較をしてみました。
| サービス名 | 入力価格 (100万トークン) | 出力価格 (100万トークン) |
|---|---|---|
| DeepSeek V3 | $0.14 – $0.27 | $0.28 – $1.1 |
| GPT-4 | $30 | $60 |
| Claude 3.5 Sonnet | $15 | $75 |
| Anthropic Claude 2 | $11.02 | $32.68 |
このように、DeepSeek V3は競合サービスと比較して大幅に低い価格設定となっています。特に注目すべき点は、同等の性能を持つGPT-4やClaude 3.5 Sonnetと比較して、約10分の1から100分の1程度の価格で利用できることです。
なお、これらの価格は2025年1月時点のものであり、今後の市場動向や技術革新によって変更される可能性があります。最新の価格情報については、DeepSeekの公式ウェブサイトで確認することをお勧めします。
DeepSeek V3の使い方
DeepSeek V3は、様々な方法で利用することができ、用途や目的に応じて最適な利用方法を選択できます。ここでは、主な4つの利用方法について詳しく解説します。
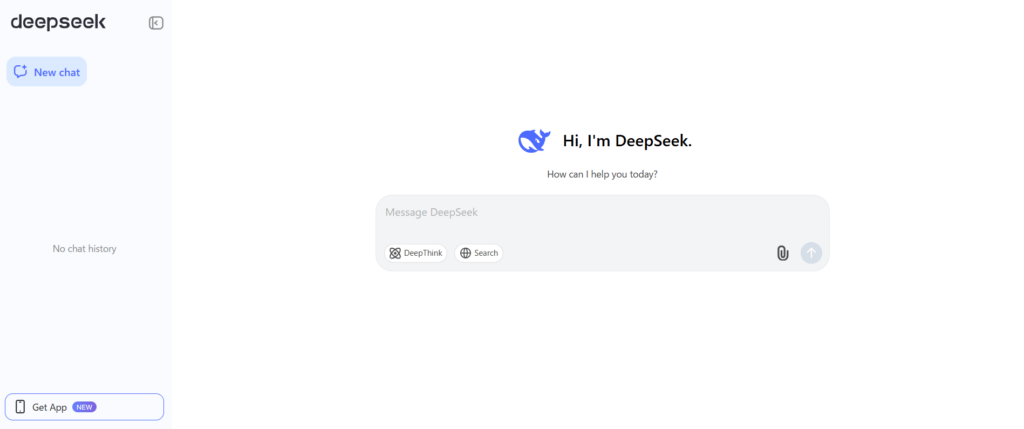
使い方①:Web版の利用方法
DeepSeek V3のWeb版は、最も手軽に利用できる方法です。以下の手順で簡単に開始できます。
- STEP1DeepSeek V3へのアクセスとログイン
①公式サイト(chat.deepseek.com)にアクセス
②Googleアカウントまたはメールアドレスで登録・ログイン


これで登録は完了です!

DeepSeekのWebインターフェースは、以下の機能を備えています。
- 直感的なチャットUI
- DeepThinkモード搭載(より詳細な分析が可能)
- 日本語を含む多言語対応
- 履歴保存機能
- STEP2チャットを始める
ChatGPTなどと同様質問したいことを入力することができます。

生成速度や回答精度も他ツールとそん色なく利用することが出来ました!


使い方②: APIを使った利用方法
APIを使用することで、独自のアプリケーションにDeepSeek V3を統合できます。
- APIキーの取得と設定
①Billing → API keysを選択
②「Create new API key」でキーを生成
③環境変数に設定
export DEEPSEEK_API_KEY=your_api_key_here④下記コードでリクエストを送信する
import requests headers = { "Content-Type": "application/json", "Authorization": f"Bearer {DEEPSEEK_API_KEY}" } data = { "model": "deepseek-chat", "messages": [{"role": "user", "content": "こんにちは"}] } response = requests.post( "https://api.deepseek.com/v1/chat/completions", json=data, headers=headers )
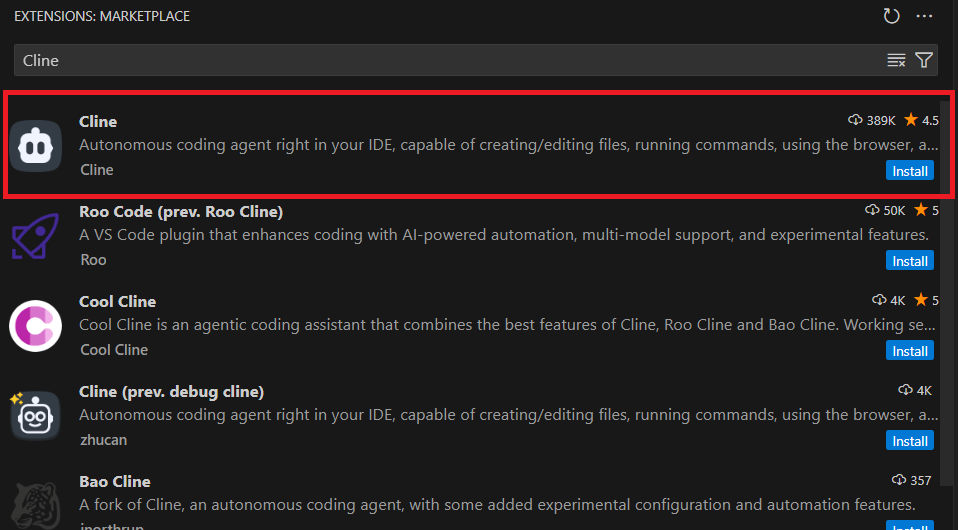
使い方③:VSCode拡張機能での活用方法
VSCode拡張機能「Cline」を使用することで、開発環境内でDeepSeek V3を直接利用できます。
- STEP1VSCodeの拡張機能マーケットプレイスから「Cline」をインストール

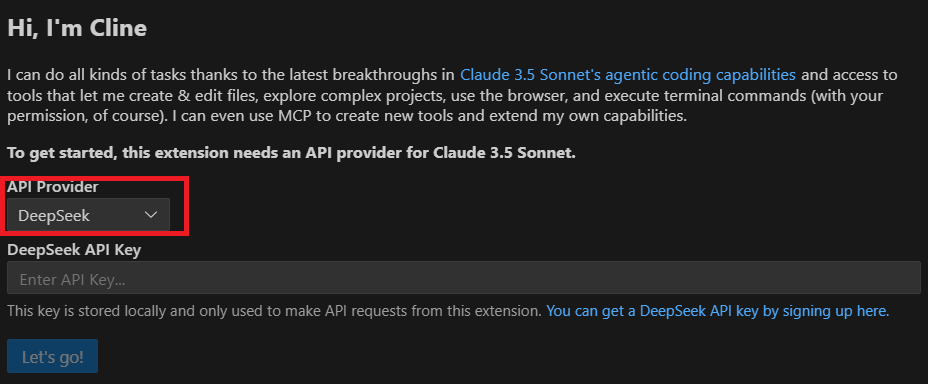
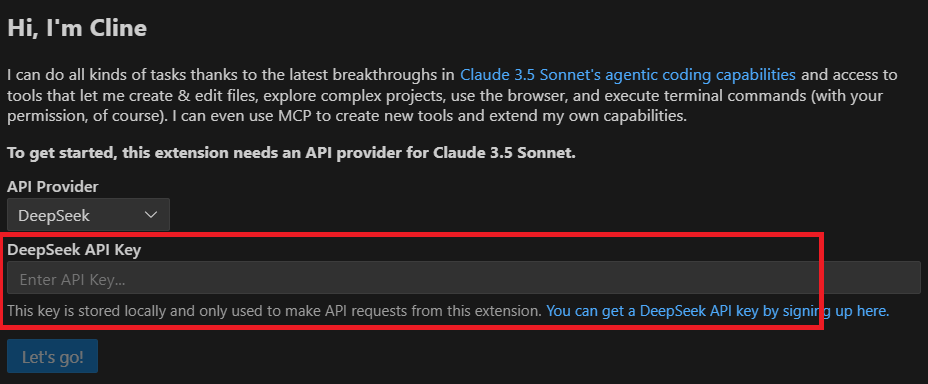
- STEP2設定画面でDeepSeekをプロバイダーとして選択
- STEP3APIキーを入力

- STEP4必要に応じてショートカットキーを設定
完了したら、通常通りプロンプトで質問を入力することで利用できます。
VScodeを使ったDeepSeek V3では、以下のような機能を利用できます。
| 機能 | 概要 |
|---|---|
| コード補完 | リアルタイムでのコード提案 |
| エラー解析 | コードの問題点を指摘 |
| ドキュメント生成 | 自動的にドキュメントを作成 |
| リファクタリング支援 | コードの最適化を提案 |
使い方④:ローカル環境での実行方法
ローカル環境でDeepSeek V3を実行する場合、Ollamaを使用する方法が推奨されています。
- STEP1Ollamaのインストール
# Ollamaをインストール(公式サイトからダウンロード) brew install ollama # macOSの場合 - STEP2モデルのダウンロードと設定
# DeepSeek V3モデルの取得 ollama create deepseek-33b -f ./modelfile - STEP3モデルの起動と実行
# モデルの起動 ollama run deepseek-33b必要システム要件を確認しておきましょう。
- ・RAM:最低32GB(推奨64GB以上)
- ・ストレージ:100GB以上の空き容量
- ・GPU:NVIDIA GPU(VRAM 24GB以上推奨)
このように、DeepSeek V3は様々な方法で利用できます。用途や環境に応じて最適な方法を選択することで、効率的にAIの能力を活用することができます。初めて使用する場合は、まずWeb版から試してみることをお勧めします。
DeepSeek V3の活用事例と実践的なタスク例
DeepSeek V3は、その高い性能と柔軟性により、様々な分野で実践的に活用されています。
以下では、主要な活用領域とその具体的な使用例を紹介します。
例①:プログラミング支援
DeepSeek V3は、特にプログラミング分野で高い評価を得ています。HumanEvalで82.6%という高いスコアを記録し、実践的なコーディングタスクで優れた支援能力を発揮します。
| タスク | 具体例 | 成功率 |
|---|---|---|
| バグ修正 | エラーメッセージの解析と修正提案 | 90%以上 |
| コード最適化 | パフォーマンス改善のための提案 | 85%以上 |
| ドキュメント生成 | 自動的なコメント付与とドキュメント作成 | 95%以上 |
| アルゴリズム実装 | 効率的なアルゴリズムの提案と実装 | 80%以上 |
例えば、以下のようなコード生成が可能です。
# 入力: "Pythonでロジスティック回帰を実装してください"
# 出力: scikit-learnを使用した実装例とカスタム実装の両方を提供
from sklearn.linear_model import LogisticRegression
import numpy as np
class CustomLogisticRegression:
def __init__(self, learning_rate=0.01, iterations=1000):
self.learning_rate = learning_rate
self.iterations = iterations
def fit(self, X, y):
# 実装詳細...例②:数学問題の解決
数学分野では、MATH-500テストで90.2%という驚異的な正解率を達成しています。複雑な数学的概念の説明から、具体的な問題解決まで幅広く対応します。
★対応可能な数学分野
- 微分積分学
- 線形代数
- 統計学
- 離散数学
- 最適化問題
特に、段階的な解法の説明と視覚的な補助を組み合わせた回答が特徴的です。
例③:多言語対応・翻訳
DeepSeek V3は、英語と中国語を中心に、日本語を含む多言語で高い精度を発揮します。
翻訳性能の比較は、以下の通りです。
| 言語ペア | BLEU スコア | 人間評価スコア |
|---|---|---|
| 英語 ↔ 中国語 | 42.5 | 4.2/5.0 |
| 英語 ↔ 日本語 | 38.7 | 4.0/5.0 |
| 中国語 ↔ 日本語 | 37.8 | 3.9/5.0 |
特筆すべき点として、文脈を理解した自然な翻訳と、専門用語の適切な変換が挙げられます。
例④:ビジネス文書作成
ビジネス文書の作成支援では、フォーマルな文体と適切な構造化を重視した出力が可能です。
★対応可能な文書タイプ
- ビジネスメール
- 商談の依頼
- 見積もり案内
- 契約書の送付
- レポート・企画書
- マーケット分析
- 事業計画書
- 進捗報告書
- プレゼンテーション資料
- 企画提案
- 市場動向分析
- 商品説明
例えば、「取引先へのアポイント調整メール」の作成では、以下のような要素を適切に含めた文書を生成します。
- 適切な敬語と丁寧表現
- 要件の明確な提示
- 日時の候補提案
- フォローアップの方法
これらの実践的なタスクにおいて、DeepSeek V3は高い精度と自然な出力を維持しながら、ユーザーの意図を適切に理解し、目的に沿った結果を提供します。特に、文脈理解と専門知識の適用において優れた性能を示しています。
DeepSeek V3を利用する際の注意点とリスク
DeepSeek V3を利用する際には、いくつかの重要な注意点とリスクを理解しておく必要があります。特に企業での利用を検討する場合は、以下の点について慎重な評価が求められます。
DeepSeek V3の利用規約と制限事項
DeepSeekの利用規約には、ユーザーにとって重要な制限事項が含まれています。
★主な法的枠組み
| 項目 | 内容 | 影響 |
|---|---|---|
| 準拠法 | 中華人民共和国の法律 | 日本の法律が適用されない |
| 管轄裁判所 | 中国・杭州市の裁判所 | 国際的な紛争解決が複雑化 |
| 知的財産権 | 生成物の権利に制限あり | 商用利用時に追加許可が必要な場合あり |
特に注意が必要な点として、紛争が発生した場合、中国の法律に基づいて中国の裁判所で手続きを行う必要があります。このため、日本国内のユーザーにとっては、言語面や手続き面で大きな負担となる可能性があります。
DeepSeek V3のデータの取り扱いについて
DeepSeek V3におけるデータの取り扱いには、以下のような重要な考慮点があります。
★データ利用ポリシー
- 入力されたデータは学習用データとして使用される可能性
- データの保持期間が明確でない
- ユーザーデータの削除手順が不明確
| データ種類 | 保持期間 | 削除可否 |
|---|---|---|
| チャット履歴 | 未定 | 要問い合わせ |
| API入力データ | 未定 | 要問い合わせ |
| 生成コンテンツ | 未定 | 要問い合わせ |
まとめ
DeepSeek V3は、6,710億という膨大なパラメータ数と革新的な技術アプローチにより、GPT-4oやClaude 3.5 Sonnetに匹敵する性能を実現しながら、驚異的な低コスト開発を達成した注目のAIモデルです。特に数学やプログラミング分野での高い性能と、競合サービスの約10分の1という破格の料金設定は、AI活用の新たな可能性を示しています。
一方で、中国企業が開発したモデルであることによる法的リスクや、データセキュリティ、政治的バイアスの可能性など、導入に際して慎重な検討が必要な課題も存在します。
DeepSeek V3の登場は、オープンソースAIモデルの新たな基準となり得るものであり、今後のAI業界に大きな影響を与えることが予想されます。企業や開発者は、これらのメリットとリスクを十分に評価した上で、自身のニーズに合わせた活用方法を検討することが重要です!
romptn ai厳選のおすすめ無料AIセミナーでは、AIの勉強法に不安を感じている方に向けた内容でオンラインセミナーを開催しています。
AIを使った副業の始め方や、収入を得るまでのロードマップについて解説しているほか、受講者の方には、ここでしか手に入らないおすすめのプロンプト集などの特典もプレゼント中です。
AIについて効率的に学ぶ方法や、業務での活用に関心がある方は、ぜひご参加ください。
\累計受講者10万人突破/

