
みなさんは、2023年11月28日に発表され、生成AIの界隈の中で大きな注目を集めている新技術「Animate Anyone」についてご存知でしょうか?
今回は、この新技術「Animate Anyone」について解説していきたいと思います。
「Animate Anyone」という言葉を聞いたことはあるけど詳しくは知らないという方や、1つの記事で「Animate Anyone」について現状わかっていることを全て知りたいという方向けに詳しく解説していきたいと思いますので、ぜひ最後までご覧ください!
内容をまとめると…
Animate Anyoneは1枚の静止画にボーン動画で動きを指定するだけで、なめらかな動画を生成できる技術
アニメ・実写・3Dキャラなどあらゆる人物画像に対応し、カクつきやチラつきが極めて少ない高品質な動画が作れる
ReferenceNetが画像の特徴を詳細に保持し、ポーズガイダーが指定した動きに正確に制御する仕組み
アリババグループが発表した技術で、現時点ではコードとモデルは未公開のためダウンロードして使うことはできない
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

Animate Anyoneとは?
まずは、「Animate Anyone」とは一体どのような技術なのか、概要的な部分を解説していきたいと思います。
「Animate Anyone」とは、一言で言うと、1枚の画像に動き方を指定することで、とてもなめらかな動画を作成することができるようになる技術のことです。
1枚の画像に対して、自分の好きなように動き方をボーン動画として学習させることで、その画像がボーン動画と全く同じような動きをしてくれるようになります。
つまり、静止画にモーションを付け加えることで、静止画を動画化することができてしまうということです。
また、「Animate Anyone」は中国のアリババグループというグループのメンバーが発表した技術です。
Animate Anyoneの特徴
ここからは、「Animate Aynone」の特徴について解説していきたいと思います。
「Animate Anyone」は最新の生成AIとして、とても優れた特徴を持っているので、それらの特徴を一挙にご紹介していきます。
①ハイクオリティな動画が生成できる
まず、「Animate Anyone」には、とても高いクオリティの動画を生成することができるという特徴があります。
画像を動画化する際に大きな問題点となるカクつきたチラつきがほとんどなく、とてもなめらかで自然な動きをしてくれます。
「Animate Anyone」を使用した際の動きのなめらかさは他の技術と比較してみてもとてもクオリティが高いものとなっています。
②どんな人物・キャラクターでも対応可能
また、「Animate Anyone」には、どんな人物やキャラクターの画像でも対応可能で、しっかりと動画化することができるという特徴もあります。
アニメ風の画像から、リアルな人物の画像、3Dのキャラクター画像など基本的に全ての人物やキャラクターの画像を動画にすることができてしまいます。
https://arxiv.org/pdf/2311.17117.pdf%EF%BC%89

③トレーニングプロセスの向上
そして、「Animate Anyone」はトレーニングプロセスも他の技術と比べて向上されたものとなっています。
「Animate Anyone」はたった2段階のトレーニングプロセスによって学習が実施されています。
また、学習プロセスを2段階に分けることで、2段階目において時間特徴量の残差接続が効果を発揮してくれるようになるようです。
④ベンチマークでの評価が高い
そして、最後の特徴として、「Animate Anyone」はベンチマークでの評価が非常に高いという点が挙げられます。
前述したとおり、「Animate Anyone」を使えば、どのような人物の画像やキャラクターの画像であっても、非常に高いクオリティで動画化することができます。
また、それだけでなく、トレーニングプロセスも向上されているので、ベンチマークでの評価も必然的にとても高いものとなっているわけです。
Animate Anyoneの仕組み
①拡散モデルを使用している
まず、「Animate Anyone」では、システムに拡散モデルが使用されています。
拡散モデルとは、生成AIモデルの1つであり、画像を生成するためのAIを中心に採用されているモデルです。
主に画像生成において高い精度を誇っており、Stable Diffusionをはじめとしたさまざまなサービスに導入されています。
そして、「Animate Anyone」にもこの拡散モデルが使用されているというわけです。
②『ReferenceNet』が導入されている
また、「Animate Anyone」には、「ReferenceNet」も導入されております。
「ReferenceNet」とは、「U-Net」のうちの1つです。
特徴としては、Stable Diffusionの「ReferenceOnly」に近いです。
元の人物やキャラクターの画像からその画像の特徴を非常に詳しく読み込み、ノイズを除去してくれる別の「U-Net」へと送信してくれる機能を持っています。
従来、画像を動画に変換する際は、「テキストエンコーダ」の代わりとして「CLIPエンコーダ」という機能が用いられてきましたが、この機能だと画像の詳細部分に関する特徴が大幅に失われてしまうという問題点がありました。
ところが、「Animate Anyone」では、「ReferenceNet」という機能の導入に成功したことで、この問題点を解消することができています。
https://arxiv.org/pdf/2311.17117.pdf%EF%BC%89
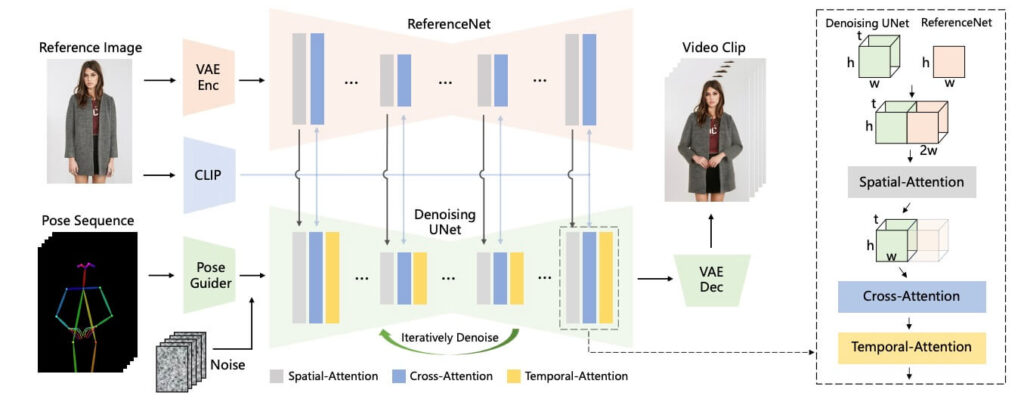
③『ポーズガイダー』が導入されている
そして、「Animate Anyone」には、「ポーズガイダー」という機能も搭載されています。
「ポーズガイダー」とは、自分で指定したポーズにきちんと沿って画像が動いてくれるように、制御をしてくれる機能のことです。
特徴としては、Stable Diffusionの「ControlNet」に近いものとなっています。
動きを指定するためのボーン動画から、その動画の特徴を読み込むことで動きの制御ができるようになっています。
「ポーズガイダー」はたった4つの畳み込み層によって構成されているため、計算量をあまり増やすことなく、上記のような機能を果たすことができます。
④テンポラルレイヤーを使用している
さらに、「Animate Anyone」では、テンポラルレイヤーも使用されています。
テンポラルレイヤーとは、時間的特徴を抽出し、複数のビデオフレーム同士の時間依存性を認識することで、フレームとフレームの間の動きを極力ナチュラルに補完してくれる機能のことです。
前提として、マルチフレームの導入に成功しているため、複数のフレーム間の動きをナチュラルに補完することができるようになっています。
つまり、テンポラルレイヤーがあることで、なめらかな動画を生成することができるというわけです。
テンポラルレイヤーに近い機能としては、「AnimateDiff」が挙げられます。
まとめ
いかがでしたでしょうか?
今回は、1枚の画像に動き方を指定することで、とてもなめらかな動画を作成することができるようになる新技術「Animate Anyone」について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 「Animate Anyone」とは、1枚の画像をとてもなめらかな動画に変換することができる新技術である
- 「Animate Anyone」の特徴は、【ハイクオリティな動画を生成できる】、【どんな人物・キャラクターでも対応可能】、【トレーニングプロセスの向上】、【ベンチマークでの評価が高い】である
- 「Animate Anyone」の仕組みは、【拡散モデルを使用している】、【『ReferenceNet』が導入されている】、【『ポーズガイダー』が導入されている】、【テンポラルレイヤーを使用している】である
現在、「Animate Anyone」はコードとモデルが公開されていないので、ダウンロードして使用することはできません。
しかし、とても画期的な技術であることに変わりはないので、モデルとして公開されましたら、また詳しいダウンロード方法や使い方などを追記していきたいと思います!
最後までご覧いただき、ありがとうございました!
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

