
Stable Diffusion で画像を生成する際に、色々な学習データのお世話になりますよね。
「モデル」や「lora」などはAI画像生成に欠かさないものとなっています。
そんな学習データを自作できるとしたら、どうでしょうか?
「DreamArtist」を使えばあなたもオリジナルの学習データが作成できますよ。
内容をまとめると…
DreamArtistはたった1枚の画像からembeddingを作成できるStable Diffusionの拡張機能
embeddingとネガティブembeddingの両方が同時に生成され、特定キャラの再現やネガティブプロンプトとして活用できる
エラーが頻発しやすく、公式推奨モデル(SD v1.4/v1.5等)から始めるのが安全
学習ステップ数を追加すれば精度を上げられるが、やりすぎると過学習になる点に注意
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

拡張機能「DreamArtist」とは?
1枚の画像からでも「embedding」を作成できる拡張機能です。
「embedding」はloraのように特定のキャラクターを再現したり、また「easy-negative」のようにネガティブプロンプトとして使うことで画像の生成を助けてくれる学習データです。

たった一枚の画像から、自分オリジナルの学習データを作成できるのはとっても魅力的ですね。
この記事を読んであなたもぜひ挑戦してみて下さい。
拡張機能「DreamArtist」の導入方法
その前に、
起こるエラーは、VRAM不足から浮動小数点やらファイルが空とか色々ありますが、調べれば何とかなります。
実行する前に「失敗は成功のもと」と気楽に構えておくほうが良いでしょう。
では導入方法ですが、「Stable diffusion」を起動し、「Extensions」→「Install from URL」へ移動し、「URL for extension’s git repository」に以下をコピー&ペーストして下さい。
https://github.com/7eu7d7/DreamArtist-sd-webui-extension.gitそしてInstallを押せばOKです。
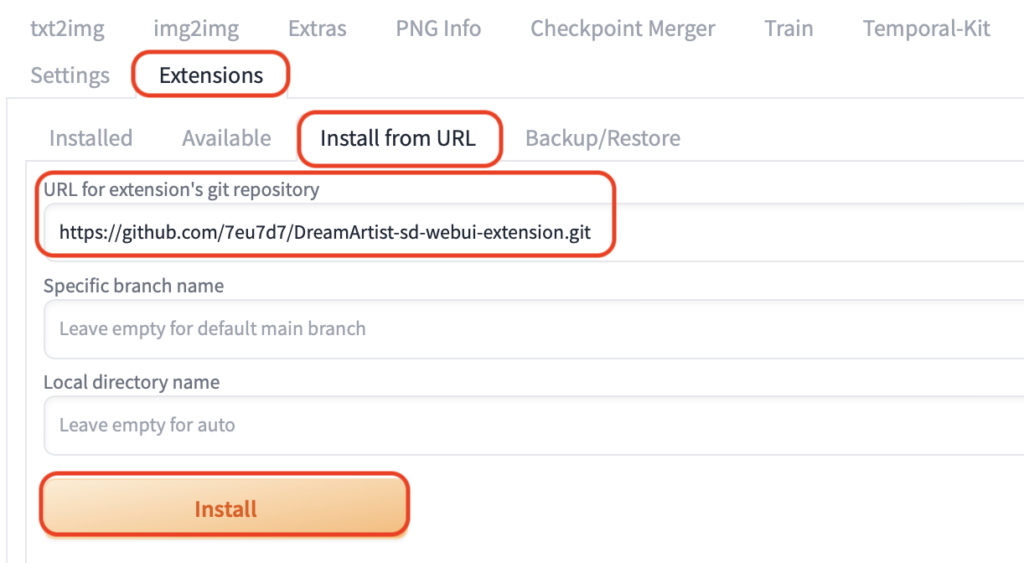
1度リロードすれば導入完了です。
拡張機能「DreamArtist」の使い方
その前に、trainの環境について
MACをお使いの方は浮動小数点の処理でエラーが起こりますので、Stable Diffusion web ui を起動するコマンドに「–no-half」を足して下さい。
./webui.sh --no-halfこれをコピーして使用して下さい。
では、「DreamArtist」を使って「embedding」を作っていきましょう。
下準備
1、使用モデルの選定
使用するモデルで公式に動作が確認されているものは以下のとおりです。
Stable Diffusion v1.4
Stable Diffusion v1.5
animefull-latest
Anything v3.0
momoko-e
初めて動かす場合はこれらのモデルから選んで使用する事をお勧めします。これら以外のものでも基本的には問題なく使えると思いますが、とにかくエラーが多いので慣れるまでは公式見解に従いましょう。
モデルを決めたら「Stable Diffusion checkpoint」に設定して下さい。
この記事では「anythingelseV4_v45」を使っています。このモデルでも問題なく作れました。

2、画像の選定
今回使用する画像はこちらのサイトから調達しました。

研究目的で使用する機械学習用のデータを公開してくれています。

最近人気の「ずんだもん」の画像を1枚を使ってみます。
新規フォルダを作成して、選んだ1枚の[.png]ファイルを入れておいて下さい。
3、テキストファイル作成
画像と一緒に学習するテキストファイルを作成します。
ファイル名は「subject.txt」として下さい。
キャラクターの「embedding」を作成するときは、ファイル名「subject.txt」
スタイル(負のembedding等)を作成するときは、ファイル名「style.txt」を使って下さい。
テキストファイルの中身は1行に文字列1つを[ ] で括って入れて下さい。
今回使用するものはシンプルに

これを使用します。
こちらは特に置き場所はどこでも問題ないです。
カラの「embedding」を作る
では「DreamArtist」のダブを開いて「embedding」を作成します。
最初は学習データが無い外枠のみの「embedding」と負の「embedding」が作成されます。
「DreamArtist Create embedding」を開いて以下のように入力します。
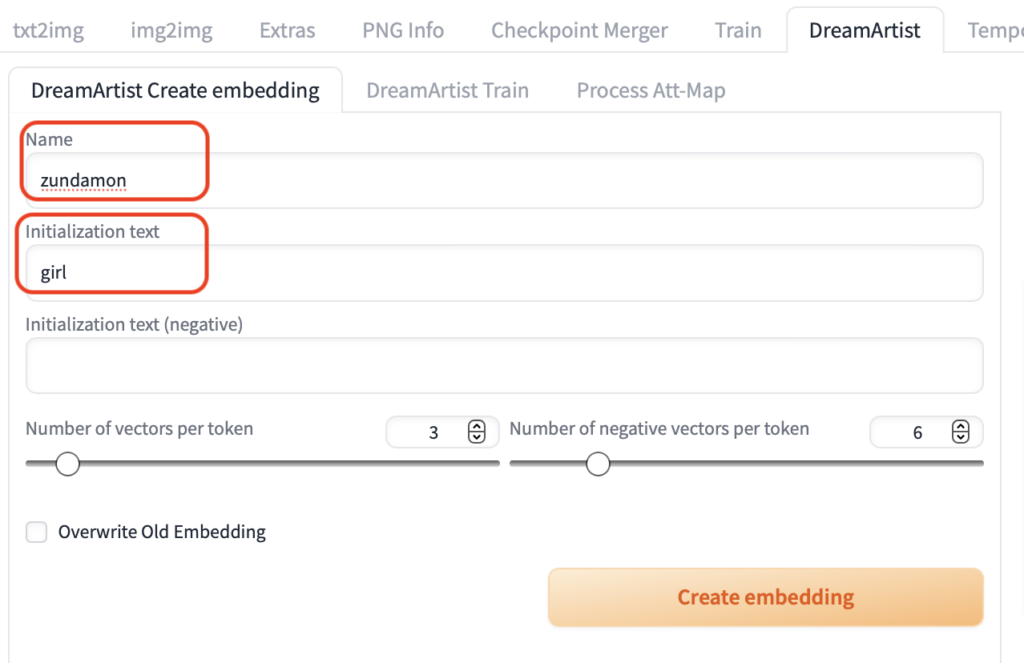
「Name」は最終的な「embedding」の名前になるのでわかりやすいものをつけるのが良いでしょう。
「Initialization text」はおそらく初期化に使っているだけだと思われますので、何でもOKです。
「Crete embedding」を押すと「embedding」の枠が作成されます。
txt2imgの設定
txt2imgへ移動し、「embedding」を開いてみましょう。

このように新しく「embedding」と「embedding-neg」が作成されています。
これをそれぞれプロンプトとネガティブプロンプトに入れて画像を1枚生成しておきます。
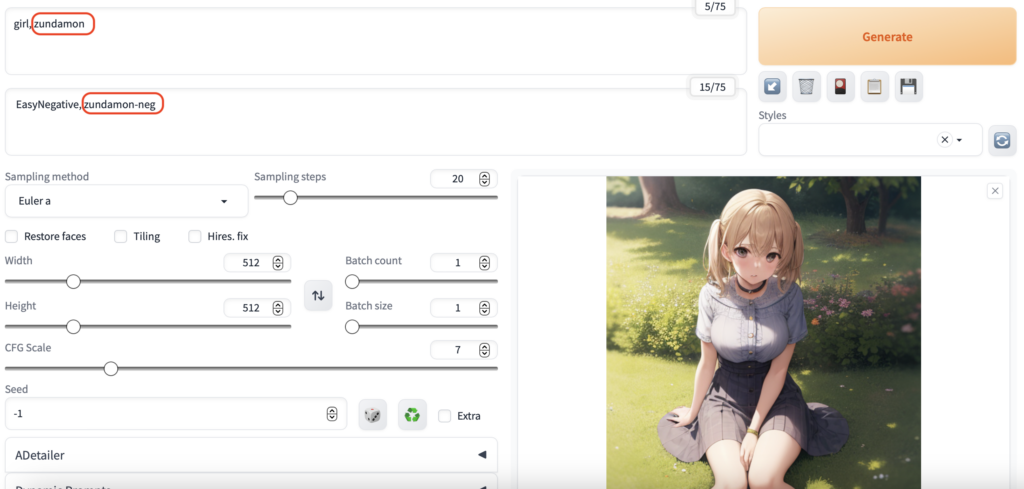
当然まだ「ずんだもん」の学習はしていないので、出てきません。
ただ、「embedding」を学習中にこのプロンプトで画像を生成して途中経過を見せてくれますので、このままの設定で次工程に進んでください。
「embedding」をTrain
「DreamArtist」のダブから「DreamArtist Train」 を選択し、各パラメータ等を入力していきます。
・「Embedding」にzundamon を選択
・Dataset directory に画像データの入っているフォルダのパスを入力
・Prompt template file にテキストファイル「subject.txt」のパスを入力
・Max steps は今回3000で作成します。
・Read parameters (prompt, etc…) from txt2img tab when making previewsを有効化
それら以外のパラメーターは全部デフォルト値でいきます。
生成環境によっては結構な時間がかかります。ちゃんと動いていれば大丈夫なので気長に待ちましょう。

作成中に100stepsごとに画像を生成してくれます。
「stable diffusion web ui」→「dream_artist」の中にまとまって保存されていますので、確認してみて下さい。
作成した「embedding」の確認
作成した「embedding」で画像を生成してみましょう。txt2imgで生成してみます。






もしも画像がいまいちな出来でしたら、追加で学習させることも可能です。
先ほどと同じ設定値でstaps数だけ増やしてあげると、追加分のみを学習してくれます(でもやり過ぎると過学習になります)。
今回の「embedding」はこれで完成として他のプロンプトを足して、画像が作れるかもやってみます。



それぞれプロンプトはバラバラですが、どれもいい感じで生成できています。
この様に拡張機能「DreamArtist」を使うことでたった1枚の画像からでも「embedding」を作る事ができました。
ただ、この機能はエラーが頻発します。
そんなときは「ターミナル」の確認&下記のサイトを巡って、ヒントを探してみて下さい。
公式ページ

公式推薦のページ
また、今回は「ずんだもん」の「embedding」でしたが、負の「embedding」も同じように学習させて作る事ができますので、興味のある方はチャレンジしてみて下さい。
まとめ
いかがでしたでしょうか?
Stable Diffusionで1枚の追加学習で高品質な画像が生成できる拡張機能『DreamArtist』の使い方!について解説してきました。
今回のポイントをまとめると、以下のようになります。
- 「DreamArtist」を使えば1枚の画像からでも「embedding」を生成できる
- エラーが起こっても一つずつ解決いていけば大丈夫です
今回1枚の「ずんだもん」の画像から「embedding」を作成してみましたが、複数枚からでもできるようです。
ただ今回この拡張機能を動かせるまでに3日もかかってしまったために(何となくでやってみるとエラー三昧です)細かい部分まで理解しきれませんでした。
そして学習に結構な時間がかかるので、trainは夜中にしか回せません。
でもそんな苦労を乗り越えれば、皆さんにもオリジナルの学習データを作成することができます。
ぜひとも挑戦してみて下さい。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

