
Stable Diffusion Web UIを使っていますか?
これ一つで色々な画像を生成することができますよね。
でも、「なんでこんなことができるのかな?」って不思議に思ったことはありませんか?
今回はそんな疑問を解消する為に、Stable Diffusion の仕組みについて解説していきます。
内容をまとめると…
Stable Diffusionは潜在拡散モデル(Latent Diffusion Model)を採用し、ノイズ画像から徐々にノイズを除去して画像を生成する仕組み
構成要素はテキストをベクトルに変換するCLIP、ノイズ除去を行うU-Net、潜在空間と画像を変換するVAEの3つ
画像の潜在表現(低次元ベクトル)上で拡散処理を行うことで、個人のPC環境でも実行可能な計算効率を実現している
同じプロンプトでも異なる画像が生成されるのは、推論過程が確率分布的な値に基づいているため
プロンプト・導入・制作フローをまとめて学びたい方向けに、AI制作に役立つ無料資料を用意しています。
画像生成だけでなく、AIに作業を任せるためのエージェント活用資料もあわせて受け取れます。

「Stable Diffusion」の概要
Stable Diffusion は入力されたテキスト(プロンプト)から高品質な画像を生成するAIモデルです。
2022年8月にGitHub上にオープンソースとして公開され、Web上に構築された環境で動作させたり、ローカル環境で独自に動かしたりすることが可能です。
「Stable Diffusion」の特徴
GitHubからダウンロードすることで無料、かつ無制限で使用できます。モデルの更新や商用利用も可能で、HuggingFaceやCIVITAIを通じて学習済みモデルを利用できます。
Stable Diffusionは潜在拡散モデルというアルゴリズムが使われています。これは後述する拡散モデルを高速処理するために進化させたアルゴリズムです。
「Stable Diffusion」のリファレンス
①論文 – CVPR 2022で発表されたStable Diffusionの元論文です。詳しく知りたい方はこちらからダウンロードしてください。

②GitHubリポジトリ- 開発者や提供会社ごとに複数存在します。数が多いので有名どころのみ紹介します。
- diffusers – https://github.com/huggingface/diffusers
- latent-diffusion – https://github.com/huggingface/diffusers
- CompVis – https://github.com/CompVis/stable-diffusion
- Stability-AI – https://github.com/Stability-AI/stablediffusion
- AUTOMATIC1111 – https://github.com/AUTOMATIC1111/stable-diffusion-webui
- stochaiticai – https://github.com/stochasticai/x-stable-diffusion
たくさんの資料もありますので、Stable Diffusion で困ったときは各リポジトリーを覗いてみると、何かヒントがあるかもしれません。
「Stable Diffusion」の学習データとは
元々学習に使用されたデータは、LAIONと呼ばれる非政府団体が提供しているデータセットを使い、様々な画像とそれに紐付くCaption(テキスト)データが大量に提供されています。
さらに今ではオープンソースとしてコードも公開されており、checkpoint(モデル)やLora(Low-Rank Adaptation)などの学習データを、ユーザー自身が作ることもできます。
※「Lora」や「モデル」についてさらに詳しく知りたい方は、以下の記事を参考にしてください。


「Stable Diffusion」のインストール方法・使い方
本題に入る前に、Stable Diffusionの使用環境は整っていますか?
※「Stable Diffusion」の詳しい使い方については、以下の記事を参考にしてください。


「Stable Diffusion」の仕組みをわかりやすく解説!
さて、本題に入りますが、色々な用語が出てきます。が、それぞれを極めて難解です。それをわかりやすいようになるべく難しい言葉は使わずに解説していきます。
Stable Diffusionの仕組みを図にしてみました
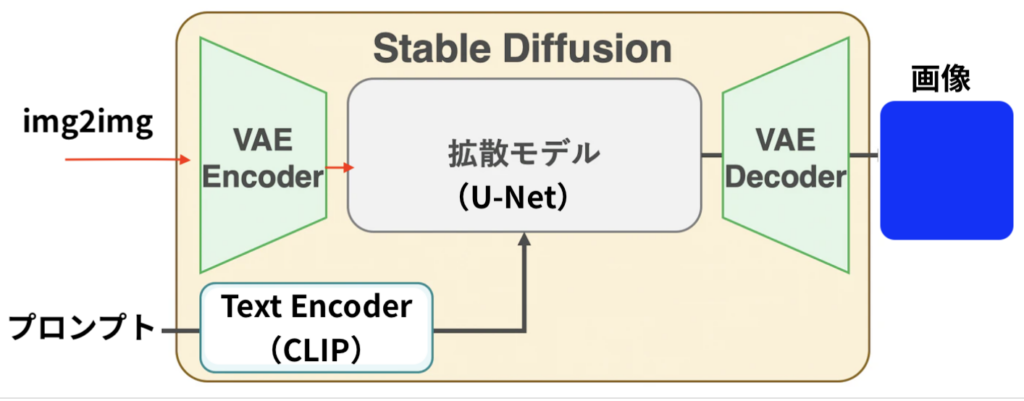
細かいところは抜きにして、あくまでわかりやすいように作った物です。でもこんな感じと思っていただいて大丈夫です。
「Stable Diffusion」の構成
まずは上の図の各用語の解説から
- VAE -(Variational Auto-Encoder; 変分オートエンコーダー)潜在空間と画像を変換するアルゴリズムです。確率分布的なデータ処理で大規模データをコンパクトに処理できます。Stable Diffusionではimg2imgでの入力画像データの変換と、最後にデコーダーが画像の最終的な仕上げをしています。
- Text Encoder – Stable Diffusion はText(プロンプト)をユーザーから受け取り、それを元に絵を描きます。しかしStable Diffusion 自身が理解できるのはベクトル(数字の羅列)のみなので、Text(プロンプト)をベクトルに翻訳するText Encoderが必要になります。その機能をCLIPから借りています。
- CLIP – 与えられた画像にテキストラベルをつけてクラス分けするために作られたモデルです。ChatGPTで有名なOpenAI社が2021年に発表しました。画像エンコーダーとテキストエンコーダーを事前学習して、データセット内のどの画像がどのテキストとペアになっているかを予測します。
- 拡散モデル(モデル: U-Net) – U-Netはエンコーダとデコーダから成る、画像のピクセル(画素)1つひとつに対してラベル付けしていく手法のモデルです。ノイズ画像から少しずつノイズを取り除くことでキレイな画像を生成しています。
基本的な流れとしては [ プロンプト→ CLIP → U-Net → VAE Decoder → 画像] と思ってください。
拡散モデルについては以下で解説します。
「Stable Diffusion」の拡散モデル
図をご覧ください。
X0で与えられた画像に t 回の計算されたノイズを加えてノイズだらけ画像を作るのが拡散過程(拡散モデル)です。
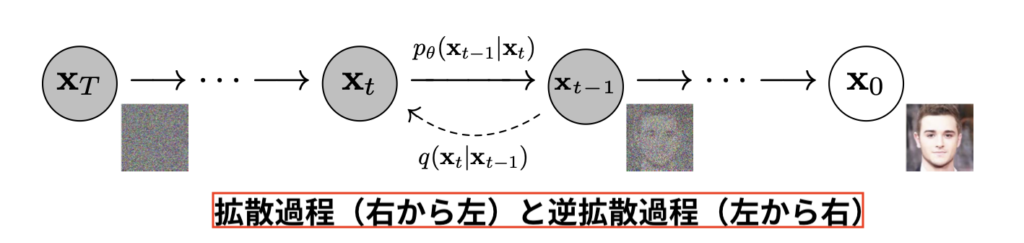
「ノイズだらけにしてどうすんの?」って思いますよね。でもこの拡散モデルが重要なのです。
すごく簡単にいうと、この工程を逆回し(逆拡散過程)にしてノイズから画像を生成しているのが、Stable Diffusion です。
学習データやプロンプトから与えられた計算されたノイズを、ノイズ画像から取り除く工程を経て、最終的に画像を作っています。
「Stable Diffusion」の学習の流れ
Stable Diffusionは「不思議な箱」であって、それだけ用意していきなり「舌を出した犬」と言われても描けません。「学習」が必要です。
その為に、先ほどの図の
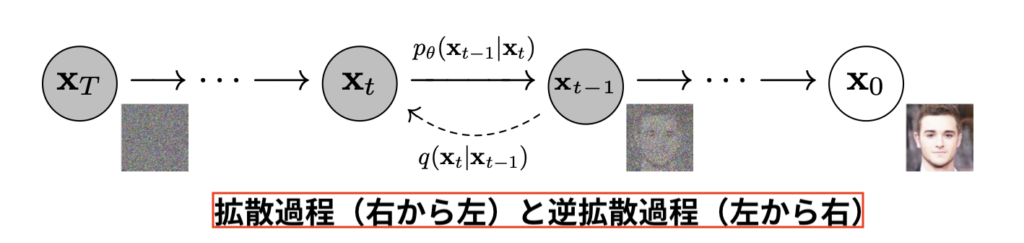
拡散過程前と逆拡散過程後の画像の誤差が最小となるように学習していきます。その総数は画像数十億枚分だそうです。
「Stable Diffusion」の推論の流れ
さて、ノイズいっぱいの画像から少しづつノイズを除いていきます。
どのくらい除くかは、学習の成果としてかなり良い精度でInference(推論)できるようになります。
「舌を出した犬」とプロンプトを送ると、「舌を出した犬」を生成するためのデノイズ具合をInference(推論)し、結果として

「舌を出した犬」が出てきます。
同じプロンプトでも違う絵になるのはこのInference(推論)が確率分布的に存在する値だからです。
「Stable Diffusion」の基本的なコンセプト
論文より: Latent Diffusion Model(潜在拡散モデル) をベースにしており、拡散モデルを潜在空間で利用することで効率的に学習できます。そのおかげでユーザー環境でも実行が可能となっています。
元論文はこちら
「Stable Diffusion」における“U-Net”
U-Netは前述の通りエンコーダとデコーダから成る、画像のピクセル(画素)1つひとつに対してラベル付けしていく手法のモデルです。
U-Netのエンコーダは、入力された画像を何度か畳み込み、その画像の特徴を抽出します。
U-Netのデコーダは、エンコーダによって抽出された特徴を受け取り、deconvolution(逆畳み込み)と呼ばれる通常の畳み込みと逆の処理を行い、入力画像と同じサイズの確率マップを出力します。
※U-Net の構成図
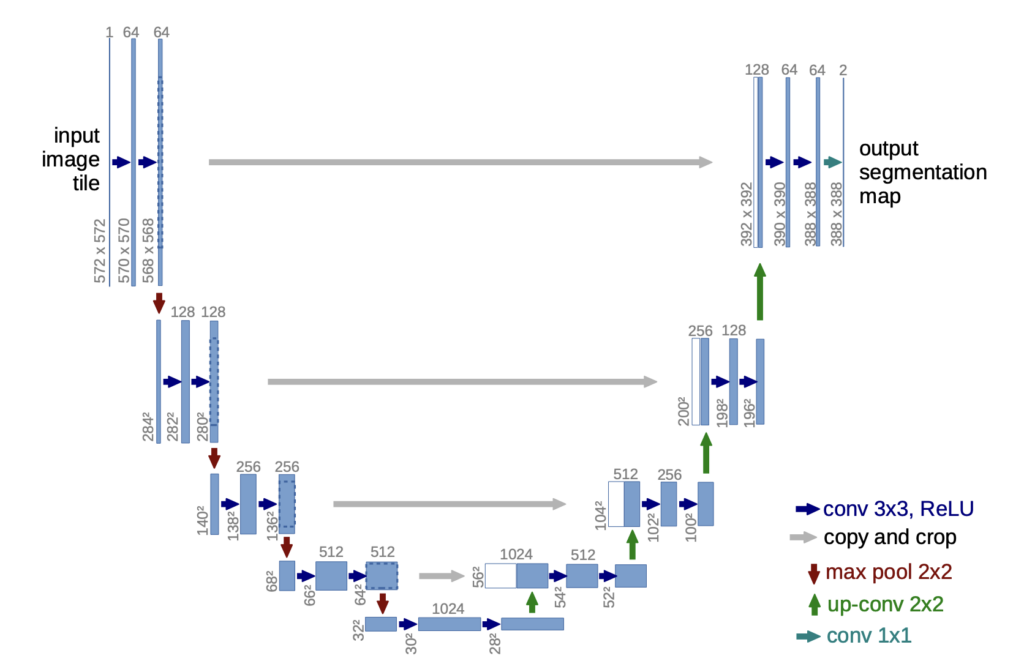
物体の局所的特徴と全体的位置情報の両方を統合して学習させるために開発されたのがU-Netです。
下向きパスは、「畳み込み+プーリング」により、深い層ほど特徴が局所的で位置情報が曖昧に、浅い層ほど、特徴はざっくりで位置情報は正確になります。
上向きパスは、「畳み込み+upサンプリング」により、特徴を保持したまま、画像を大きく復元することができます。
画像サイズが同じものを深い層から段階的に統合することによって、局所的特徴を保持したまま全体的位置情報の復元を行うことができます。
まとめ
いかがでしたでしょうか?
画像生成AI「Stable Diffusion」の仕組みについて解説してきました。
今回のポイントをまとめると、以下のようになります。
- Stable Diffusion は人間が描くようには描いてはいない
- ノイズだらけのキャンパスに推論消しゴムで[ 消す=描く ]をしている
今回はわかりやすさに重きを置き解説しましたが、Stable Diffusionの仕組みを説明する上で、ここでは書ききれなかった深層学習のテクノロジーがたくさんありました。
もし興味があればそのような部分も調べてみてください。
画像生成AIを使いこなすには、ツールの使い方だけでなく、プロンプト改善・環境導入・モデル選定・作業フローの理解が重要です。制作に役立つAI資料をまとめて受け取れます。
クリエイター向け資料を受け取る

