 AIニュース
AIニュース 教えて.AI、ChatGPTの新機能「GPTs」に対応開始
GMOインターネットグループのGMO教えてAI株式会社が運営する「教えて.AI byGMO」は、ChatGPTの新機能「GPTs」の共有機能を搭載し、AI技術の進化に対応する新たなステップを踏み出しました。
AIニュース  AIニュース
AIニュース  AIニュース
AIニュース  AIニュース
AIニュース  AIニュース
AIニュース  AIニュース
AIニュース 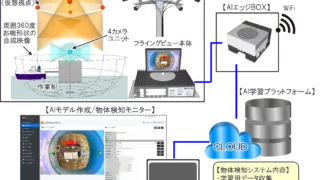 AIニュース
AIニュース 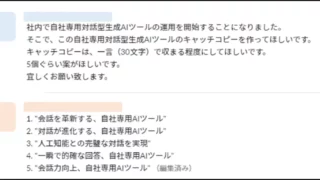 AIニュース
AIニュース 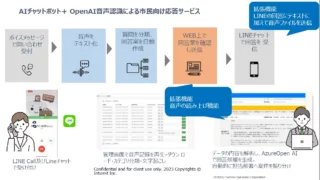 AIニュース
AIニュース  AIニュース
AIニュース